

Cel mai probabil, astăzi nimeni nu întreabă de ce este necesar să se colecteze valorile de serviciu. Următorul pas logic este să configurați o alertă pentru valorile colectate, care va notifica despre orice abateri ale datelor în canalele convenabile pentru dvs. (mail, Slack, Telegram). În serviciul online de rezervări hoteliere toate valorile serviciilor noastre sunt turnate în InfluxDB și afișate în Grafana, iar alertele de bază sunt, de asemenea, configurate acolo. Pentru sarcini precum „trebuie să calculați ceva și să comparați cu el”, folosim Kapacitor.

Kapacitor face parte din stiva TICK care poate procesa valorile din InfluxDB. Poate conecta mai multe măsurători împreună (ună), poate calcula ceva util din datele primite, poate scrie rezultatul înapoi în InfluxDB, poate trimite o alertă către Slack/Telegram/mail.
Întreaga stivă este cool și detaliată , dar vor exista întotdeauna lucruri utile care nu sunt indicate în mod explicit în manuale. În acest articol, am decis să adun o serie de astfel de sfaturi utile, neevidente (sintaxa de bază a TICKscipt este descrisă ) și arată cum pot fi aplicate folosind un exemplu de rezolvare a uneia dintre problemele noastre.
Să mergem!
float & int, erori de calcul
O problemă absolut standard, rezolvată prin caste:
var alert_float = 5.0
var alert_int = 10
data|eval(lambda: float("value") > alert_float OR float("value") < float("alert_int"))
Folosind default()
Dacă o etichetă/câmp nu este completat, vor apărea erori de calcul:
|default()
.tag('status', 'empty')
.field('value', 0)
completați alăturarea (internă vs exterioară)
În mod implicit, join va elimina punctele în care nu există date (interne).
Cu fill('null'), va fi efectuată o îmbinare exterioară, după care trebuie să faceți un default() și să completați valorile goale:
var data = res1
|join(res2)
.as('res1', 'res2)
.fill('null')
|default()
.field('res1.value', 0.0)
.field('res2.value', 100.0)
Există încă o nuanță aici. În exemplul de mai sus, dacă una dintre serii (res1 sau res2) este goală, seria (datele) rezultată va fi, de asemenea, goală. Există mai multe bilete pe acest subiect pe Github (, , ) – așteptăm remedieri și suferim puțin.
Utilizarea condițiilor în calcule (dacă este în lambda)
|eval(lambda: if("value" > 0, true, false)
Ultimele cinci minute de la conductă pentru perioada respectivă
De exemplu, trebuie să comparați valorile ultimelor cinci minute cu săptămâna anterioară. Puteți lua două loturi de date în două loturi separate sau puteți extrage o parte din date dintr-o perioadă mai mare:
|where(lambda: duration((unixNano(now()) - unixNano("time"))/1000, 1u) < 5m)
O alternativă pentru ultimele cinci minute ar fi utilizarea unui BarrierNode, care întrerupe datele înainte de ora specificată:
|barrier()
.period(5m)
Exemple de utilizare a șabloanelor Go în mesaj
Șabloanele corespund formatului din pachet Mai jos sunt câteva puzzle-uri întâlnite frecvent.
dacă-altfel
Punem lucrurile în ordine și nu declanșăm oamenii cu text din nou:
|alert()
...
.message(
'{{ if eq .Level "OK" }}It is ok now{{ else }}Chief, everything is broken{{end}}'
)
Două cifre după punctul zecimal din mesaj
Îmbunătățirea lizibilității mesajului:
|alert()
...
.message(
'now value is {{ index .Fields "value" | printf "%0.2f" }}'
)
Extinderea variabilelor în mesaj
Afișăm mai multe informații în mesaj pentru a răspunde la întrebarea „De ce țipă”?
var warnAlert = 10
|alert()
...
.message(
'Today value less then '+string(warnAlert)+'%'
)
Identificator unic de alertă
Acesta este un lucru necesar atunci când există mai multe grupuri în date, altfel va fi generată o singură alertă:
|alert()
...
.id('{{ index .Tags "myname" }}/{{ index .Tags "myfield" }}')
Handler personalizat
Lista mare de handlere include exec, care vă permite să executați scriptul cu parametrii trecuți (stdin) - creativitate și nimic mai mult!
Una dintre obiceiurile noastre este un mic script Python pentru trimiterea notificărilor către slack.
La început, am vrut să trimitem o poză grafana protejată de autorizare într-un mesaj. După aceea, scrieți OK în firul de avertizare anterioară din același grup și nu ca mesaj separat. Puțin mai târziu - adăugați la mesaj cea mai frecventă greșeală din ultimele X minute.
Un subiect separat este comunicarea cu alte servicii și orice acțiuni inițiate printr-o alertă (doar dacă monitorizarea dumneavoastră funcționează suficient de bine).
Un exemplu de descriere a unui handler, unde slack_handler.py este scriptul nostru auto-scris:
topic: slack_graph
id: slack_graph.alert
match: level() != INFO AND changed() == TRUE
kind: exec
options:
prog: /sbin/slack_handler.py
args: ["-c", "CHANNELID", "--graph", "--search"]
Cum se depanează?
Opțiune cu ieșire de jurnal
|log()
.level("error")
.prefix("something")
Watch (cli): kapacitor -url :9092 logs lvl=error
Opțiune cu httpOut
Afișează datele din conducta curentă:
|httpOut('something')
Urmăriți (obțineți): :9092/kapacitor/v1/tasks/task_name/something
Diagrama de execuție
- Fiecare sarcină returnează un arbore de execuție cu numere utile în format .
- Ia un bloc .
- Lipiți-l în vizualizator, .
De unde mai poți obține o greblă?
marca temporală în influxdb la writeback
De exemplu, am configurat o alertă pentru suma solicitărilor pe oră (groupBy(1h)) și dorim să înregistrăm alerta care a apărut în influxdb (pentru a arăta frumos faptul problemei pe graficul din grafana).
influxDBOut() va scrie valoarea timpului din alertă în marcajul de timp în consecință, punctul de pe diagramă va fi scris mai devreme/mai târziu decât a sosit alerta;
Când este necesară acuratețea: rezolvăm această problemă apelând un handler personalizat, care va scrie date în influxdb cu marcajul de timp actual.
docker, construirea și implementarea
La pornire, kapacitor poate încărca sarcini, șabloane și handlere din directorul specificat în configurația din blocul [încărcare].
Pentru a crea corect o sarcină, aveți nevoie de următoarele lucruri:
- Nume fișier – extins în script id/name
- Tip – flux/lot
- dbrp – cuvânt cheie pentru a indica în ce bază de date + politică rulează scriptul (dbrp „furnizor.” „autogen”)
Dacă o sarcină batch nu conține o linie cu dbrp, întregul serviciu va refuza să pornească și va scrie sincer despre el în jurnal.
În cronograf, dimpotrivă, această linie nu ar trebui să existe, nu este acceptată prin interfață și generează o eroare.
Hack atunci când construiți un container: Dockerfile iese cu -1 dacă există linii cu //.+dbrp, ceea ce vă va permite să înțelegeți imediat motivul eșecului la asamblarea build-ului.
alăturați-vă unul la mulți
Exemplu de sarcină: trebuie să luați percentila 95 din timpul de funcționare al serviciului pentru o săptămână, să comparați fiecare minut din ultimele 10 cu această valoare.
Nu puteți face o unire unu-la-mai multe, ultima/media/mediana peste un grup de puncte transformă nodul într-un flux, va fi returnată eroarea „nu se pot adăuga margini nepotrivite copii: lot -> flux”.
De asemenea, rezultatul unui lot, ca variabilă într-o expresie lambda, nu este înlocuit.
Există o opțiune de a salva numerele necesare din primul lot într-un fișier prin udf și de a încărca acest fișier prin sideload.
Ce am rezolvat cu asta?
Avem aproximativ 100 de furnizori hotelieri, fiecare dintre ei poate avea mai multe conexiuni, să-i spunem canal. Există aproximativ 300 dintre aceste canale, fiecare dintre canale se poate desprinde. Dintre toate valorile înregistrate, vom monitoriza rata de eroare (cereri și erori).
De ce nu grafana?
Alertele de eroare configurate în Grafana au mai multe dezavantaje. Unele sunt critice, altele la care poți închide ochii, în funcție de situație.
Grafana nu stie sa calculeze intre masuratori + alertare, dar avem nevoie de o rata (cereri-erori)/cereri.
Erorile par urâte:
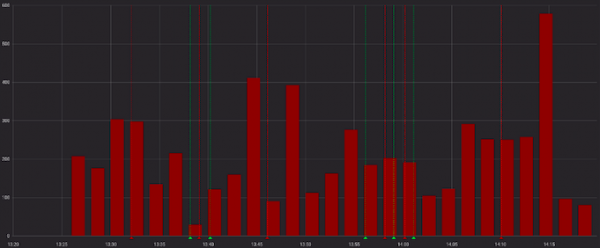
Și mai puțin rău atunci când sunt privite cu cereri de succes:
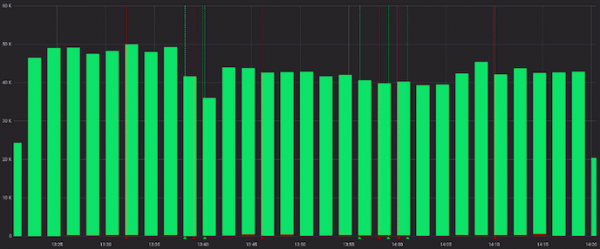
Bine, putem precalcula tariful în serviciu înainte de grafana, iar în unele cazuri acest lucru va funcționa. Dar nu la noi, pentru că... pentru fiecare canal propriul său raport este considerat „normal”, iar alertele funcționează în funcție de valori statice (le căutăm cu ochii, le schimbăm dacă există alerte frecvente).
Acestea sunt exemple de „normal” pentru diferite canale:


Ignorăm punctul anterior și presupunem că imaginea „normală” este similară pentru toți furnizorii. Acum totul este în regulă și ne putem descurca cu alerte în grafana?
Putem, dar chiar nu vrem, pentru că trebuie să alegem una dintre opțiuni:
a) faceți o mulțime de grafice pentru fiecare canal separat (și însoțiți-le dureros)
b) lăsați o diagramă cu toate canalele (și pierdeți-vă în liniile colorate și alertele personalizate)

Cum ai făcut-o?
Din nou, există un exemplu bun de pornire în documentație (), pot fi privite sau luate ca bază în probleme similare.
Ce am facut pana la urma:
- alăturați două serii în câteva ore, grupând pe canale;
- completați seria pe grupe dacă nu au existat date;
- comparați mediana ultimelor 10 minute cu datele anterioare;
- strigăm dacă găsim ceva;
- scriem ratele calculate și alertele care au apărut în influxdb;
- trimite un mesaj util lui Slack.
După părerea mea, am reușit să realizăm cât mai frumos tot ce ne-am dorit la final (și chiar puțin mai mult cu handlere personalizate).
Te poți uita pe github.com и scenariul rezultat.
Un exemplu de cod rezultat:
dbrp "supplier"."autogen"
var name = 'requests.rate'
var grafana_dash = 'pczpmYZWU/mydashboard'
var grafana_panel = '26'
var period = 8h
var todayPeriod = 10m
var every = 1m
var warnAlert = 15
var warnReset = 5
var reqQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."requests"'
var errQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."errors"'
var prevErr = batch
|query(errQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var prevReq = batch
|query(reqQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var rates = prevReq
|join(prevErr)
.as('req', 'err')
.tolerance(1m)
.fill('null')
// заполняем значения нулями, если их не было
|default()
.field('err.value', 0.0)
.field('req.value', 0.0)
// if в lambda: считаем рейт, только если ошибки были
|eval(lambda: if("err.value" > 0, 100.0 * (float("req.value") - float("err.value")) / float("req.value"), 100.0))
.as('rate')
// записываем посчитанные значения в инфлюкс
rates
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('rates')
// выбираем данные за последние 10 минут, считаем медиану
var todayRate = rates
|where(lambda: duration((unixNano(now()) - unixNano("time")) / 1000, 1u) < todayPeriod)
|median('rate')
.as('median')
var prevRate = rates
|median('rate')
.as('median')
var joined = todayRate
|join(prevRate)
.as('today', 'prev')
|httpOut('join')
var trigger = joined
|alert()
.warn(lambda: ("prev.median" - "today.median") > warnAlert)
.warnReset(lambda: ("prev.median" - "today.median") < warnReset)
.flapping(0.25, 0.5)
.stateChangesOnly()
// собираем в message ссылку на график дашборда графаны
.message(
'{{ .Level }}: {{ index .Tags "channel" }} err/req ratio ({{ index .Tags "supplier" }})
{{ if eq .Level "OK" }}It is ok now{{ else }}
'+string(todayPeriod)+' median is {{ index .Fields "today.median" | printf "%0.2f" }}%, by previous '+string(period)+' is {{ index .Fields "prev.median" | printf "%0.2f" }}%{{ end }}
http://grafana.ostrovok.in/d/'+string(grafana_dash)+
'?var-supplier={{ index .Tags "supplier" }}&var-channel={{ index .Tags "channel" }}&panelId='+string(grafana_panel)+'&fullscreen&tz=UTC%2B03%3A00'
)
.id('{{ index .Tags "name" }}/{{ index .Tags "channel" }}')
.levelTag('level')
.messageField('message')
.durationField('duration')
.topic('slack_graph')
// "today.median" дублируем как "value", также пишем в инфлюкс остальные филды алерта (keep)
trigger
|eval(lambda: "today.median")
.as('value')
.keep()
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('alerts')
.tag('alertName', name)
Care este concluzia?
Kapacitor este grozav la efectuarea de alerte de monitorizare cu o grămadă de grupări, efectuarea de calcule suplimentare bazate pe valori deja înregistrate, efectuarea de acțiuni personalizate și executarea de scripturi (udf).
Bariera de intrare nu este foarte mare - încercați dacă grafana sau alte instrumente nu vă satisfac pe deplin dorințele.
Sursa: www.habr.com
