

Pozdravujem a najprv nejaké texty. Občas závidím kolegom, ktorí pracujú na diaľku – je skvelé mať možnosť pracovať z akéhokoľvek konca sveta pripojeného na internet, dovolenka kedykoľvek, zodpovednosť za projekty a termíny a nebyť v kancelárii od 8 do 17. pozícia a pracovné povinnosti prakticky vylučujú možnosť dlhodobej neprítomnosti v dátovom centre. Občas sa však stanú zaujímavé prípady, ako je ten popísaný nižšie, a chápem, že je len málo pozícií, kde je taký priestor na kreatívne vyjadrenie vnútorného odstraňovača problémov.
Malé upozornenie - v čase písania tohto článku nebol prípad úplne vyriešený, ale vzhľadom na rýchlosť reakcie predajcov môže úplné vyriešenie trvať mesiace, ale rád by som sa teraz podelil o svoje zistenia. Dúfam, milí čitatelia, že mi odpustíte tento zhon. Ale dosť vody – čo je na puzdre?
Najprv poznámka na úvod: existuje spoločnosť (v ktorej pracujem ako sieťový inžinier), ktorá hosťuje klientske riešenia v privátnom cloude VMWare. Väčšina nových riešení sa pripája k segmentom VXLAN, ktoré spravuje NSX-V – nebudem odhadovať, koľko času mi toto riešenie dalo, skrátka – veľa. Dokonca sa mi podarilo zaškoliť kolegov v nastavovaní NSX ESG a riešenia pre malých klientov sa nasadzujú bez mojej účasti. Dôležitá poznámka: máme riadiacu rovinu s replikáciou unicast. Hypervízory sú redundantne pripojené dvoma rozhraniami k rôznym fyzickým prepínačom Juniper QFX5100 (zostaveným vo virtuálnom šasi) a trasou založenou na pôvodnej politike časovania virtuálnych portov - to je len pre úplnosť.
Riešenia pre klientov sú veľmi rozmanité: od Windows IIS, kde sú všetky komponenty webového servera nainštalované na jednom počítači, siaha až po pomerne veľké – napríklad webové frontendy Apache s vyváženou záťažou + LB MariaDB v Galere + zdieľané servery synchronizované pomocou GlusterFS. Takmer každý server je potrebné monitorovať samostatne a nie všetky komponenty majú verejné adresy. Ak ste sa s týmto problémom stretli a máte elegantnejšie riešenie, ocenil by som vašu radu.
Moje monitorovacie riešenie spočíva v „pripojení“ firewallu (Fortigate) ku každej internej klientskej sieti (+SNAT a samozrejme prísne obmedzenia typu povolenej prevádzky) a monitorovaní interných adries – tým dochádza k určitému zjednoteniu a zjednodušeniu monitoringu. dosiahnuté. Samotné monitorovanie prebieha zo serverového klastra PRTG. Schéma monitorovania je asi takáto:
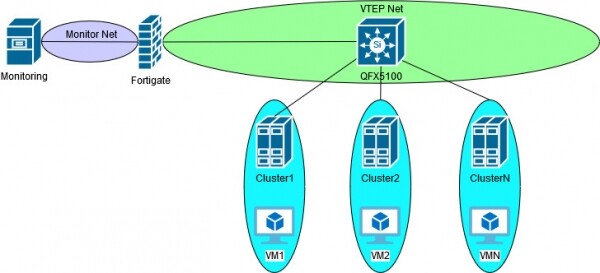
Zatiaľ čo sme fungovali iba s VLAN, všetko bolo celkom normálne a fungovalo predvídateľne, ako hodinky. Po predstavení NSX-V a VXLAN sme stáli pred otázkou: je možné pokračovať v monitorovaní po starom? V čase tejto otázky bolo „najrýchlejším“ riešením nasadenie NSX ESG a pripojenie rozhrania VXLAN trunk do siete VTEP. Rýchlo v úvodzovkách – keďže používanie GUI na konfiguráciu klientskych sietí, SNAT a pravidlá firewallu môžu a budú zjednocovať správu v jedinom rozhraní vSphere, ale podľa mňa je to dosť ťažkopádne a okrem iného to obmedzuje sadu nástrojov na riešenie problémov. Myslím, že tí, ktorí používali NSX ESG ako náhradu za „skutočný“ firewall, budú súhlasiť. Aj keď pravdepodobne by takéto riešenie bolo stabilnejšie - všetko sa napokon deje v rámci jedného predajcu.
Ďalším riešením je použitie NSX DLR v režime mosta medzi VLAN a VXLAN. Tu je myslím všetko jasné – výhoda z používania VXLAN sa jednoducho stratí – pretože v tomto prípade stále musíte pripojiť VLAN k monitorovacej inštalácii. Mimochodom, v procese vypracúvania tohto riešenia som narazil na problém, keď most DLR neposielal pakety na virtuálny stroj, s ktorým bol umiestnený na rovnakom hostiteľovi. Viem, viem - v knihách a sprievodcoch na NSX-V je priamo uvedené, že pre NSX Edge by mal byť vyčlenený samostatný klaster, ale toto je v knihách... Tak či onak, po pár mesiacoch s podporu, problém sme nevyriešili. V zásade som pochopil logiku akcie - modul jadra hypervízora zodpovedný za zapuzdrenie VXLAN sa nepoužil, ak boli DLR a monitorovaný server na rovnakom hostiteľovi, pretože prevádzka neopúšťa hostiteľa a logicky by mala byť prepojená do segmentu VXLAN - zapuzdrenie nie je potrebné. S podporou sme sa usadili na virtuálnom rozhraní vdrPort, ktoré logicky spája uplinky a vykonáva aj premostenie/zapuzdrenie – práve tu bol zaznamenaný nesúlad v prichádzajúcej prevádzke, na ktorom som v aktuálnom prípade pracoval. Ale ako bolo povedané, tento prípad som nedokončil, keďže som bol preradený do iného projektu a pobočka bola spočiatku slepou uličkou a nebola žiadna osobitná túžba ju rozvíjať. Ak sa nemýlim, problém bol pozorovaný vo verziách NSX a 6.1.4 a 6.2.
A potom - bingo! Fortinet oznamuje rodák . A nielen point-to-point alebo VXLAN-over-IPSec, nie softvérové premostenie VLAN-VXLAN – to všetko sa začalo implementovať už vo verzii 5.4 (a prezentované v iných ), ale skutočná podpora riadiacej roviny unicast. Pri implementácii riešenia som narazil na ďalší problém - pravidelne kontrolované servery „mizli“ a potom sa objavovali v monitorovaní, hoci samotný virtuálny stroj bol nažive. Dôvodom, ako sa ukázalo, bolo, že som zabudol povoliť Ping na rozhraní VXLAN. Počas procesu opätovného vyváženia klastrov boli virtuálne stroje presunuté a pomocou Ping bol dokončený vMotion, ktorý označil nového hostiteľa ESXI, do ktorého sa stroj presunul. Moja hlúposť, ale tento problém opäť raz podkopal dôveru v podporu poskytovanú výrobcom – v tomto prípade Fortinetom. Nehovorím, že každý prípad súvisiaci s VXLAN začína otázkou „kde je softswitch VLAN-VXLAN vo vašich nastaveniach?“ Tentokrát mi bolo odporučené zmeniť MTU - to je pre Ping, čo je 32 bajtov. Potom sa „pohrajte“ s tcp-send-mss a tcp-receive-mss v politike - pre VXLAN, ktorá je zapuzdrená v UDP. Fíha, prepáč - vrie to. Vo všeobecnosti som tento problém vyriešil sám.
Po úspešnom spustení testovacej prevádzky bolo rozhodnuté implementovať toto riešenie. A vo výrobe sa ukázalo, že po dni alebo dvoch postupne odpadávalo všetko, čo sa monitorovalo cez VXLAN. Deaktivácia/aktivácia rozhrania pomohla, ale len dočasne. Vzhľadom na pomalosť poskytovanej podpory som začal s odstraňovaním problémov z mojej strany - koniec koncov, moja spoločnosť, moja sieť je moja zodpovednosť.
Priebeh riešenia problémov je pod spojlerom. Pre tých, ktorí sú unavení z listov a chvastania sa, preskočte to a prejdite na post-analýzu.
Riešenie problémov s pokrokomĎakujeme za pokračovanie v čítaní – pokračujme!
Monitorovanie teda nejaký čas funguje a potom samo od seba spadne. To znamená, že s pravidlami brány firewall s najväčšou pravdepodobnosťou nie sú žiadne problémy. Keďže som sa však stretol s problémom visiacich systémových procesov vo verziách Fortigate 5.6+, najprv sa pozrieme na „diagnostický tok ladenia“ - podľa očakávania je prevádzka povolená a opúšťa rozhranie a podľa očakávania nič nereaguje. Kopeme teda ďalej v stohu. Bohužiaľ, adresy budeme musieť skryť, aj keď sú RFC1918, ale dúfam, že poskytnem procesu dostatočný popis na pochopenie. Server vo VXLAN má adresu x.x.x.15, rozhranie Fortigate x.x.x.254, všetky ostatné adresy patria do siete VTEP.
Úspešný prenos paketov zapuzdrených VXLAN vyžaduje správne informácie v niekoľkých tabuľkách. Pre prekrytie sú to ARP a OVSDB, pre prekrytie sú to ARP a CAM. V prípade Fortigate VXLAN FDB je OVSDB. Začnime tam:
fortigate (root) #diag sys vxlan fdb list vxlan-LS
mac=00:50:56:8f:3f:5a state=0x0002 flags=0x00 remote_ip=у.у.у.47 port=4789 vni=5008 ifindex=7
Všetko je tu celkom jednoduché - MAC adresa virtuálneho počítača musí byť na VTEP s adresou u.u.u.47. Keď som sa pozrel na obsah a nastavenia klastra ESXI, zistil som, že MAC virtuálneho počítača je správna, rovnako ako adresa VTEP. Kontrolujem tabuľku CAM/ARP na fortiku - opäť všetko zodpovedá nastaveniam hostiteľa ESXI:
fortigate (root) #get sys arp | grep у.у.у.47
у.у.у.47 0 00:50:56:65:f6:2c dmz
Tabuľky sú správne a premávka odchádza - možno problém nie je vo Fortigate? Zámerne som preskočil analýzu prepínania prevádzky na Juniper - logicky by sa mal ďalší krok odstraňovania problémov vykonať na ňom, ale moja sieť je jednoduchá - stačí jedna VLAN pre VTEP a všetky komponenty sú pripojené priamo. Navyše si pamätám prípad s mostom DLR, VDR a stratenou premávkou – idem očuchať hostiteľa ESXI a zároveň vytvorím prípad pre VMWare. Pod MAC "97:6e" patrí fortiku, vmnic1 je rozhranie, ktoré má VTEP s adresou u.u.u.47 snifim v oboch smeroch "--dir 2":
pktcap-uw --uplink vmnic1 --vni 5008 --mac 90:6c:ac:a9:97:6e --dir 2 -o /tmp/monitor.pcap
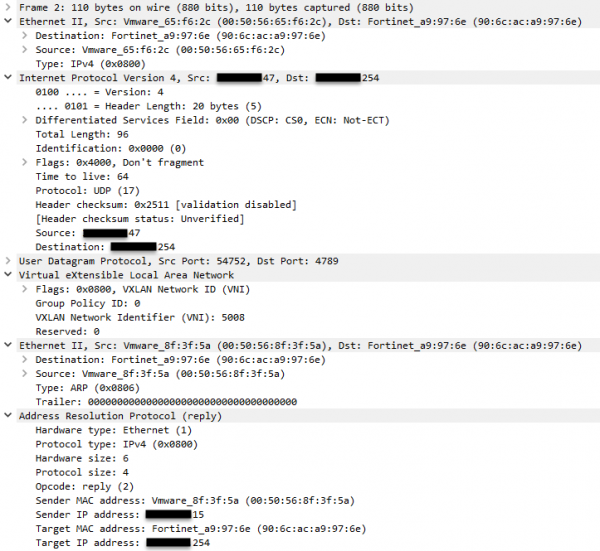
Progress - v sniffe vidím požiadavku ARP a prichádzajúcu odpoveď. Poskytujem iba odpoveď ARP a tam je všetko správne. Nespomenul som to, ale po celú dobu monitorovací server pinguje na adresu x.x.x.15 - kde je prevádzka ICMP? Pamätám si, že mám dva uplinky. Tu môžete argumentovať a povedať, že zdrojový virtuálny port je rovnaký (moja tímová politika), to znamená, že pre rovnaký vNIC by sa mal vybrať rovnaký uplink, ale keďže som na hostiteľovi, kontrola iného uplinku nie je problém:
pktcap-uw --uplink vmnic4 --vni 5008 --mac 90:6c:ac:a9:97:6e --dir 2 -o /tmp/monitor.pcap
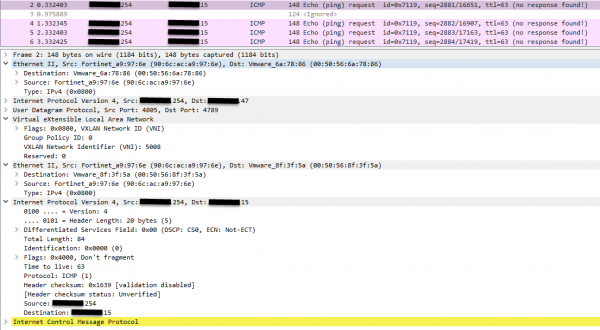
Žiadosti prichádzajú od Fortigate, ale žiadna odpoveď. To znamená, že problém nie je vo Fortigate. No a to je - myslím - opäť ten istý problém s chýbajúcou premávkou na VDR, opäť to bude trvať pár mesiacov, kým sa prípad nasmeruje správnym smerom. Po niekoľkých dňoch, keď som vychladol a nechcel som sa zmieriť s visením, rozhodol som sa vykopať ďalšie šnuchy na podporu, aby som proces urýchlil. A potom „náhodou“ môj pohľad padne na zapuzdrenie pod ethernetom. Cár nie je skutočný a MAC adresa VTEP nezodpovedá jeho IP. Nastavím sa na nulu, čucham, kopám - je to pravda, nie je to pravda. Uvediem tabuľku ARP vedľa vás, aby ste ju mohli ľahšie porovnávať. Všimnite si prvé zapuzdrenie Ethernetu na obrázku vyššie:
fortigate (root) #get sys arp | grep у.у.у.47
у.у.у.47 0 00:50:56:65:f6:2c dmz
fortigate (root) #get sys arp | grep у.у.у.42
у.у.у.42 0 00:50:56:6a:78:86 dmz
Takže skončíme s tým, že po migrácii virtuálneho stroja sa Fortigate pokúsi poslať prenos do VTEP zo (správnej) VXLAN FDB, ale použije nesprávny DST MAC a prenos sa očakáva, že rozhranie hypervízora ho prijíma. Navyše v jednom zo štyroch prípadov tento MAC patril pôvodnému hypervízoru, z ktorého migrácia stroja začala.
Včera som dostal list z technickej podpory Fortinet - v mojom prípade bola objavená chyba 615586. Naozaj neviem, či sa tešiť alebo smútiť: na jednej strane problém nie je v nastaveniach, na druhej oprava príde iba s aktualizáciou firmvéru alebo v najlepšom prípade s ďalšou. ChSV je tiež poháňaný ďalšou chybou, ktorú som objavil minulý mesiac, hoci vtedy v HTML5 GUI vSphere. No, len miestne oddelenie QA predajcov...
Dovolil by som si tipnúť nasledovné:
1 - ovládacia rovina multicast s najväčšou pravdepodobnosťou nebude podliehať opísanému problému - napokon MAC adresy VTEP sa získavajú z IP adresy skupiny, do ktorej je rozhranie prihlásené.
2 - s najväčšou pravdepodobnosťou ide o fortik problém pri vyťažení relácií na sieťovom procesore (približne analogický s CEF) - ak prejdete každý paket cez CPU, použijú sa tabuľky obsahujúce správne - aspoň vizuálne - informácie. Tento predpoklad podporuje fakt, že pomáha zatvoriť/otvoriť rozhranie alebo počkať nejaký čas – viac ako 5 minút.
3 - zmena tímovej politiky, napríklad na explicitné prepnutie pri zlyhaní, alebo zavedenie LAG problém nevyrieši, pretože MAC zdrojového hypervízora bolo pozorované ako „zaseknuté“ v zapuzdrených paketoch.
Vo svetle toho sa môžem podeliť o to, čo som nedávno objavil , kde sa v jednom z článkov uvádzalo, že stetfull firewally a metódy prenosu dát vo vyrovnávacej pamäti sú barličkami. No, nie som dosť skúsený v IT, aby som to povedal, a okrem toho okamžite nesúhlasím so všetkými tvrdeniami v článkoch na blogu. Niečo mi však hovorí, že v Ivanových slovách je niečo pravdy.
Ďakujem za pozornosť! Rád odpoviem na otázky a vypočujem si konštruktívnu kritiku.
Zdroj: hab.com
