

Del ett:
Vad? En videokodek är en programvara/hårdvara som komprimerar och/eller dekomprimerar digital video.
För vad? Trots vissa begränsningar både vad gäller bandbredd och
och när det gäller lagringsutrymme kräver marknaden alltmer högkvalitativ video. Kommer du ihåg hur vi i förra inlägget beräknade det nödvändiga minimumet för 30 bilder per sekund, 24 bitar per pixel, med en upplösning på 480×240? Vi fick 82,944 Mbps utan komprimering. Komprimering är för närvarande det enda sättet att överföra HD/FullHD/4K till TV-skärmar och internet. Hur uppnås detta? Låt oss nu kortfattat titta på de viktigaste metoderna.
Översättningen gjordes med stöd av EDISON Software.Vi är engagerade i Och .
Codec vs. behållare
Ett vanligt misstag nybörjare gör är att förväxla en digital videokodek med en digital videobehållare. En behållare är ett format. Ett omslag som innehåller videometadata (och eventuellt ljud). Den komprimerade videon kan betraktas som behållarens nyttolast.
Vanligtvis anger en videofils filändelse dess containertyp. Till exempel är en video.mp4-fil sannolikt en container MPEG-4 del 14, och filen med namnet video.mkv är troligtvis För att vara helt säker på kodeken och containerformatet kan du använda eller .
Lite historia
Innan vi går vidare till Hur?, låt oss dyka ner i lite historia för att förstå några av de äldre codecs lite bättre.
Video codec H.261 dök upp 1990 (tekniskt sett 1988) och var utformad för att fungera med en dataöverföringshastighet på 64 kbps. Den använde redan idéer som färgsubsampling, makroblock etc. År 1995 publicerades videokodekstandarden H.263, som utvecklades fram till 2001.
Den första versionen färdigställdes 2003. H.264 / AVCSamma år släppte TrueMotion sin gratis förlustbringande videokodek som heter VP3År 2008 köpte Google företaget och släppte VP8 samma år. I december 2012 släppte Google VP9, och den stöds av ungefär ¾ av webbläsarmarknaden (inklusive mobila enheter).
AV1 är en ny gratis och öppen källkodsbaserad videokodek utvecklad av Alliansen för öppna medier (Aomedia), vilket inkluderar så välkända företag som Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel och Cisco. Den första versionen av kodeken 0.1.0 publicerades den 7 april 2016.
AV1:s födelse
I början av 2015 arbetade Google med VP10, Xiph (som ägs av Mozilla) arbetade på daala, och Cisco skapade sin egen gratis videokodek som heter Thor.
därefter MPEG LA först tillkännagivna årliga gränser för HEVC (H.265) och en avgift 8 gånger högre än för H.264, men snart ändrade de reglerna igen:
ingen årlig gräns,
innehållsavgift (0,5 % av intäkterna) och
Kostnaden per enhet är ungefär 10 gånger högre än för H.264.
Alliansen för öppna medier skapades av företag från olika områden: utrustningstillverkare (Intel, AMD, ARM, Nvidia, Cisco), innehållsleverantörer (Google, Netflix, Amazon), webbläsarskapare (Google, Mozilla) och andra.
Företagen hade ett gemensamt mål: en royaltyfri videokodek. Sedan kom det AV1 med en mycket enklare patentlicens. Timothy B. Terryberry höll en fantastisk presentation som blev källan till det nuvarande AV1-konceptet och dess licensmodell.
Du kommer att bli förvånad över att du kan analysera AV1-kodeken via en webbläsare (de som är intresserade kan gå till).

Universell kodek
Låt oss titta på de grundläggande mekanismerna som ligger till grund för en universell videokodek. De flesta av dessa koncept är användbara och används i moderna kodekar som VP9, AV1 и HEVCVar medveten om att många saker som förklaras kommer att förenklas. Ibland kommer verkliga exempel att användas (som i fallet med H.264) för att demonstrera tekniker.
Steg 1 - Dela bilden
Det första steget är att dela upp ramen i flera sektioner, underavsnitt och så vidare.

Varför? Det finns många anledningar. När vi delar upp bilden kan vi mer exakt förutsäga rörelsevektorn genom att använda små sektioner för små rörliga delar. Medan vi för en statisk bakgrund kan begränsa oss till större sektioner.
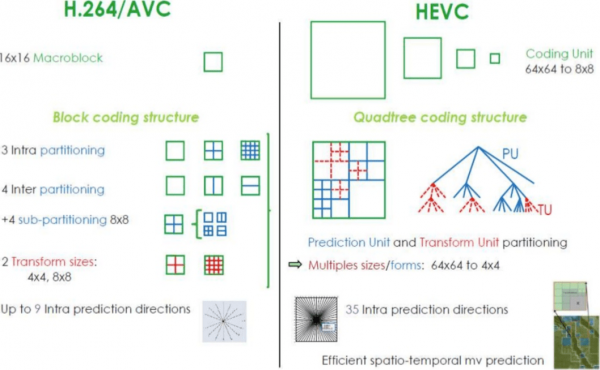
Codecs organiserar vanligtvis dessa avsnitt i sektioner (eller fragment), makroblock (eller kodningsträdblock) och flera underavsnitt. Den maximala storleken på dessa avsnitt varierar, där HEVC ställer in den på 64x64 medan AVC använder 16x16, och underavsnitt kan vara så små som 4x4.
Kommer ni ihåg ramtyperna från föregående artikel?! Detta kan också tillämpas på block, så vi kan ha ett I-fragment, ett B-block, ett P-makroblock, etc.
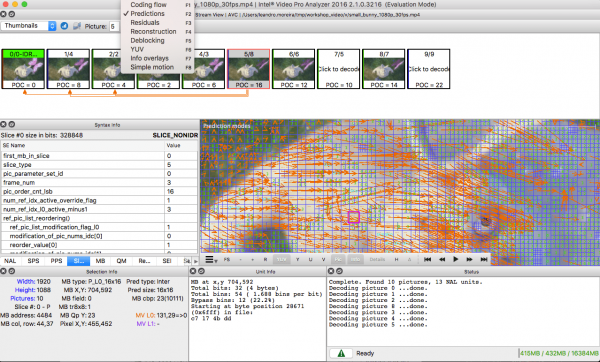
För er som vill öva, se hur bilden är uppdelad i sektioner och underavsnitt. För detta kan ni använda den som redan nämnts i föregående artikel. (den som är betald, men som har en gratis provversion som har en begränsning på de första 10 bildrutorna). Här är de analyserade avsnitten. VP9:

Steg 2 - Prognoser
När vi har sektioner kan vi göra astrologiska prognoser för dem. INTER-prognoser det är nödvändigt att överföra rörelsevektorer och resten, och för INTRA-prognoser överförs den prognosriktning och resten.
Steg 3 - Transformation
När vi väl har det kvarvarande blocket (förutspådd partition → verklig partition) är det möjligt att transformera det på ett sådant sätt att vi vet vilka pixlar som kan tas bort samtidigt som den övergripande kvaliteten bibehålls. Det finns vissa transformationer som säkerställer exakt beteende.
Även om det finns andra metoder, låt oss titta på dem mer i detalj. diskret cosinustransform (DCT - från diskret cosinustransform). DCT:s huvudfunktioner:
- Konverterar block av pixlar till lika stora block med frekvenskoefficienter.
- Komprimerar kraften och hjälper till att eliminera rumslig redundans.
- Ger reversibilitet.
Den 2 februari 2017 publicerade Cintra, RJ och Bayer, FM en artikel om en DCT-liknande transformation för bildkomprimering som endast kräver 14 utfyllnader.
Oroa dig inte om du inte förstår fördelarna med varje punkt. Nu ska vi se deras verkliga värde med några konkreta exempel.
Låt oss ta ett block med pixlar 8x8 så här:
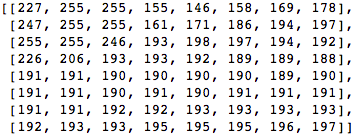
Detta block renderas till följande 8x8 pixlars bild:
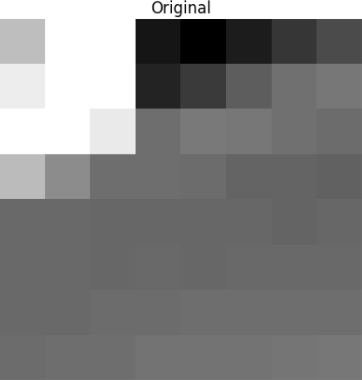
Vi tillämpar DCT på detta block av pixlar och får ett block av koefficienter av storleken 8×8:

Och om vi renderar detta koefficientblock får vi följande bild:
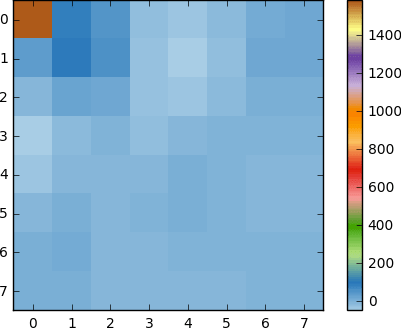
Som du kan se ser detta inte ut som originalbilden. Du kan se att den första koefficienten skiljer sig mycket från alla de andra. Denna första koefficient kallas DC-koefficienten, som representerar alla samplingar i inmatningsmatrisen, ungefär som ett medelvärde.
Detta koefficientblock har en intressant egenskap: det separerar högfrekventa komponenter från lågfrekventa.
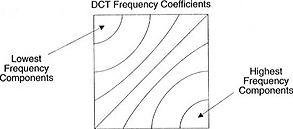
I en bild är det mesta av effekten koncentrerad till lägre frekvenser, så genom att konvertera bilden till dess frekvenskomponenter och ignorera de högre frekvenskoefficienterna kan man minska mängden data som behövs för att beskriva bilden utan att offra för mycket bildkvalitet.
Frekvens avser hur snabbt signalen förändras.
Låt oss försöka tillämpa kunskapen från testexemplet genom att omvandla originalbilden till dess frekvens (koefficientblock) med hjälp av DCT och sedan ignorera några av de minst viktiga koefficienterna.
Först omvandlar vi det till frekvensdomänen.

Därefter ignorerar vi en del (67 %) av koefficienterna, främst den nedre högra delen.

Slutligen rekonstruerar vi bilden från detta kasserade koefficientblock (kom ihåg att den måste vara inverterbar) och jämför den med originalet.
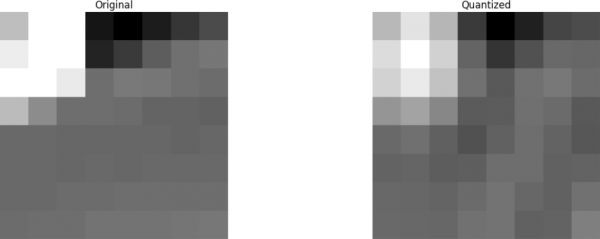
Vi ser att den liknar originalbilden, men det finns många skillnader från originalet. Vi kastade bort 67,1875 % och fick fortfarande något som liknade originalet. Vi kunde ha kastat bort koefficienterna mer genomtänkt för att få en ännu bättre bild, men det är en annan sak.
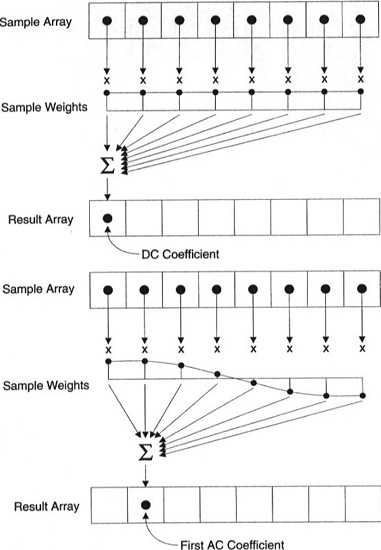
Varje koefficient bildas med hjälp av alla pixlar.
Viktigt: Varje koefficient är inte direkt mappad till en enda pixel, utan är en viktad summa av alla pixlar. Denna fantastiska graf visar hur den första och andra koefficienten beräknas med hjälp av vikter som är unika för varje index.
Du kan också försöka visualisera DCT genom att titta på en enkel bildformation baserad på den. Till exempel, här är en symbol A som bildas med hjälp av varje koefficientvikt:

Steg 4 - Kvantisering
Efter att vi i föregående steg har tagit bort några koefficienter, utför vi i det sista steget (transformation), en speciell form av kvantisering. I detta skede är det acceptabelt att förlora information. Eller, enklare sagt, kvantiserar vi koefficienterna för att uppnå kompression.
Hur kan man kvantisera ett block av koefficienter? En av de enklaste metoderna är likformig kvantisering, där man tar ett block, dividerar det med ett värde (med 10) och avrundar resultatet.
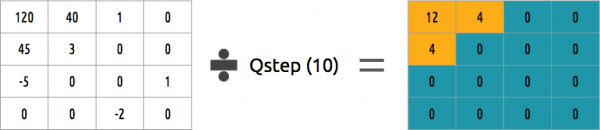
Kan vi invertera detta koefficientblock? Ja, det kan vi, genom att multiplicera med samma värde som vi dividerade med.

Denna metod är inte den bästa eftersom den inte tar hänsyn till vikten av varje koefficient. Man skulle kunna använda en matris av kvantiserare istället för ett enda värde, och denna matris kan använda egenskapen hos den dubbla koefficienten (DCT), vilket kvantiserar majoriteten av det nedre högra partiet och minoriteten av det övre vänstra partiet.
Steg 5 - Entropikodning
När vi väl har kvantiserat data (bildblock, bitar, bildrutor) kan vi fortfarande komprimera den förlustfritt. Det finns många algoritmiska sätt att komprimera data. Vi kommer kortfattat att presentera några av dem. För en djupare förståelse kan du läsa boken "Understanding Compression: Data Compression for Modern Developers" (").
Koda videor med VLC
Låt oss anta att vi har en ström av tecken: a, e, r и tSannolikheten (mellan 0 och 1) för hur ofta varje symbol förekommer i strömmen presenteras i den här tabellen.
| a | e | r | t | |
|---|---|---|---|---|
| sannolikhet | 0,3 | 0,3 | 0,2 | 0,2 |
Vi kan tilldela unika binära koder (helst små) till de mest sannolika, och större koder till de mindre sannolika.
| a | e | r | t | |
|---|---|---|---|---|
| sannolikhet | 0,3 | 0,3 | 0,2 | 0,2 |
| Binär kod | 0 | 10 | 110 | 1110 |
Vi komprimerar strömmen, förutsatt att vi i slutändan kommer att spendera 8 bitar på varje symbol. Utan komprimering skulle det behövas 24 bitar per symbol. Om varje symbol ersätts med sin kod får vi besparingar!
Det första steget är att koda symbolen e, vilket är 10, och den andra symbolen är a, vilket läggs till (inte matematiskt): [10] [0], och slutligen det tredje tecknet t, vilket gör vår slutliga komprimerade bitström lika med [10] [0] [1110] eller 1001110, vilket bara kräver 7 bitar (3,4 gånger mindre utrymme än originalet).
Observera att varje kod måste vara en unik kod med ett prefix. hjälper dig att hitta dessa siffror. Även om den här metoden inte är utan sina brister, finns det videokodekar som fortfarande erbjuder denna algoritmiska metod för komprimering.
Både kodaren och avkodaren måste ha tillgång till symboltabellen med sina binära koder. Därför måste tabellen också skickas med i indata.
Aritmetisk kodning
Låt oss anta att vi har en ström av tecken: a, e, r, s и t, och deras sannolikhet presenteras i denna tabell.
| a | e | r | s | t | |
|---|---|---|---|---|---|
| sannolikhet | 0,3 | 0,3 | 0,15 | 0,05 | 0,2 |
Med den här tabellen konstruerar vi intervall som innehåller alla möjliga symboler, sorterade efter största tal.

Nu ska vi koda en ström av tre symboler: ät.
Välj först det första tecknet e, vilket ligger i delintervallet från 0,3 till 0,6 (exklusive). Vi tar detta delintervall och delar det igen i samma proportioner som tidigare, men för detta nya intervall.

Låt oss fortsätta koda vår ström ätNu tar vi den andra symbolen a, vilket ligger i det nya delområdet från 0,3 till 0,39, och sedan tar vi vår sista symbol t och genom att upprepa samma process igen får vi det sista delområdet från 0,354 till 0,372.
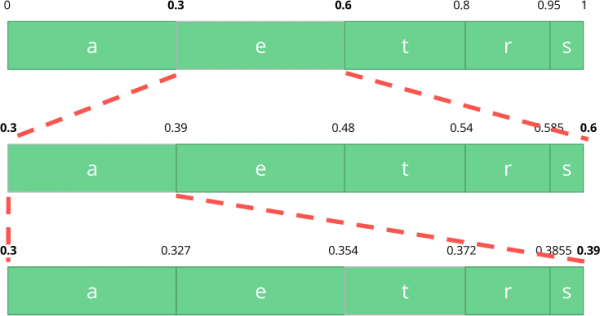
Vi behöver bara välja ett tal i det sista delområdet från 0,354 till 0,372. Låt oss välja 0,36 (men du kan välja vilket annat tal som helst i detta delområde). Endast med detta tal kan vi rekonstruera vår ursprungliga ström. Det är som om vi ritade en linje inom intervallen för att koda vår ström.
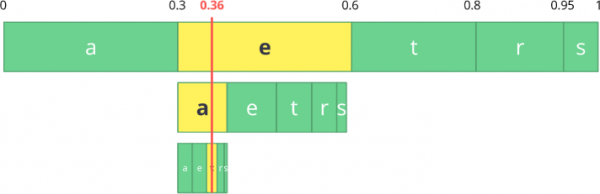
Den omvända operationen (dvs. avkodning) är lika enkelt: med vårt tal 0,36 och vårt initiala intervall kan vi köra samma process. Men nu, med hjälp av detta tal, upptäcker vi flödet som kodas av detta tal.
Med det första intervallet märker vi att vårt tal motsvarar segmentet, därför är detta vår första symbol. Nu dividerar vi detta delintervall igen, enligt samma process som tidigare. Här kan vi se att 0,36 motsvarar symbolen a, och efter att ha upprepat processen kom vi till den sista symbolen t (bildar vår ursprungliga kodade ström ät).
Både kodaren och avkodaren måste ha en tabell över symbolsannolikheter, så den måste skickas in som indata.
Ganska elegant, eller hur? Den som kom på den här lösningen var riktigt smart. Vissa videokodekar använder den här tekniken (eller erbjuder den åtminstone som ett alternativ).
Tanken är att komprimera en kvantiserad bitström utan förlust. Jag är säker på att det saknas massor av detaljer, anledningar, avvägningar etc. i den här artikeln. Men om du är utvecklare borde du veta mer. Nya codecs försöker använda olika entropikodningsalgoritmer, som till exempel ANS.
Steg 6 - Bitströmsformat
När allt detta är klart återstår bara att dekomprimera de komprimerade bildrutorna i samband med de vidtagna stegen. Avkodaren måste uttryckligen informeras om de beslut som fattas av kodaren. Avkodaren måste förses med all nödvändig information: bitdjup, färgrymd, upplösning, prediktionsinformation (rörelsevektorer, riktningsbaserad INTER-prediktion), profil, nivå, bildhastighet, bildtyp, bildnummer och mycket mer.
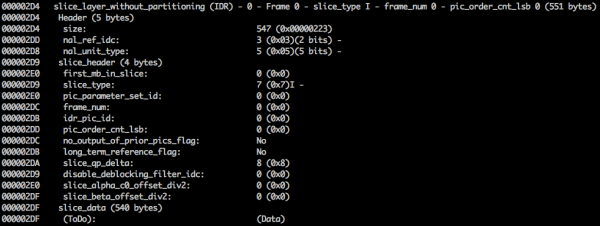
Vi ska ta en ytlig titt på bitströmmen. H.264Vårt första steg är att skapa en minimal H.264-bitström (FFmpeg lägger som standard till alla kodningsalternativ som SEI NAL — vi får reda på vad det är lite längre fram). Vi kan göra detta med hjälp av vårt eget repository och FFmpeg.
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264
Det här kommandot genererar en rå bitström. H.264 med en enda bildruta, 64x64 upplösning, med färgrymd YUV420Följande bild används som ram.

H.264 Bitström
Standard AVC (H.264) anger att informationen kommer att skickas i makroramar (i nätverksmekanism), kallade nal (detta är ett nätverksabstraktionslager). Huvudmålet med NAL är att tillhandahålla en "nätverksvänlig" representation av video. Denna standard bör fungera på TV-apparater (strömbaserat) och på internet (paketbaserat).
![]()
Det finns en synkroniseringsmarkör för att definiera gränserna för NAL-element. Varje synkroniseringsmarkör innehåller ett värde. 0x00 0x00 0x01, förutom den allra första, som är lika med 0x00 0x00 0x00 0x01. Om vi lanserar hexdump För den genererade H.264-bitströmmen identifierar vi minst tre NAL-mönster i början av filen.
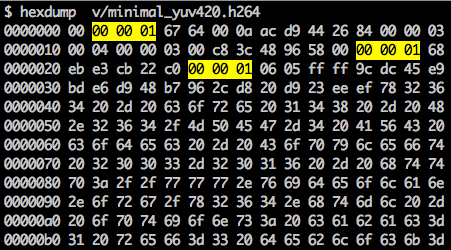
Som nämnts måste avkodaren inte bara känna till bilddata, utan även videodetaljer, bildrutedetaljer, färger, parametrar som används med mera. Den första byten i varje NAL definierar dess kategori och typ.
| NAL-typidentifierare | beskrivning |
|---|---|
| 0 | Okänd typ |
| 1 | Kodat bildfragment utan IDR |
| 2 | Kodad datasegmentsektion A |
| 3 | Kodad datasegmentsektion B |
| 4 | Kodad datasegmentsektion C |
| 5 | Kodat IDR-fragment av IDR-bild |
| 6 | Ytterligare information om SEI-förlängningen |
| 7 | SPS-sekvensparameteruppsättning |
| 8 | PPS-bildparameteruppsättning |
| 9 | Åtkomstavskiljare |
| 10 | Slut på sekvensen |
| 11 | Slutet av strömmen |
| . | . |
Vanligtvis är den första NAL:en i en bitström SPSDenna NAL-typ ansvarar för att kommunicera vanliga kodningsvariabler som profil, nivå, upplösning etc.
Om vi hoppar över den första synkroniseringsmarkören kan vi avkoda den första byten för att ta reda på vilken NAL-typ som är först.
Till exempel är den första byten efter synkroniseringsmarkören 01100111, där den första biten (0) är i f-fältetorbid_zero_bitDe kommande 2 bitarna (11) berättar för oss fältet nal_ref_idc, vilket anger om denna NAL är ett referensfält eller inte. Och de återstående 5 bitarna (00111) berättar för oss fältet nal_enhetstyp, i det här fallet är det SPS-blocket (7) NAL.
Andra byten (binär=01100100, hex=0x64, december=100) i SPS NAL är ett fält profil_idc, vilket visar den profil som kodaren använde. I det här fallet användes den begränsade höga profilen (dvs. höga profilen utan stöd för dubbelriktat B-segment).

Om du tittar på bitströmsspecifikationen H.264 För SPS NAL hittar vi många värden för parameternamn, kategori och beskrivning. Låt oss till exempel titta på fälten pic_width_in_mbs_minus_1 и pic_height_in_map_units_minus_1.
| Parameternamn | kategori | beskrivning |
|---|---|---|
| pic_width_in_mbs_minus_1 | 0 | ue(v) |
| pic_height_in_map_units_minus_1 | 0 | ue(v) |
Om du räknar lite på värdena i dessa fält får du upplösningen. Du kan representera 1920 x 1080 med hjälp av pic_width_in_mbs_minus_1 med värdet 119 ((119 + 1) * macroblock_size = 120 * 16 = 1920). Återigen, för att spara utrymme, istället för att koda 1920, gjorde vi det med 119.
Om vi fortsätter att kontrollera vår skapade video i binär form (till exempel: xxd -b -c 11 v/minimal_yuv420.h264), sedan kan vi gå vidare till den sista NAL, vilket är själva ramen.

Här ser vi dess första 6 byte-värden: 01100101 10001000 10000100 00000000 00100001 11111111Eftersom det är känt att den första byten anger NAL-typen, i detta fall (00101) detta är IDR-fragmentet (5), och sedan kommer det att vara möjligt att utforska det ytterligare:
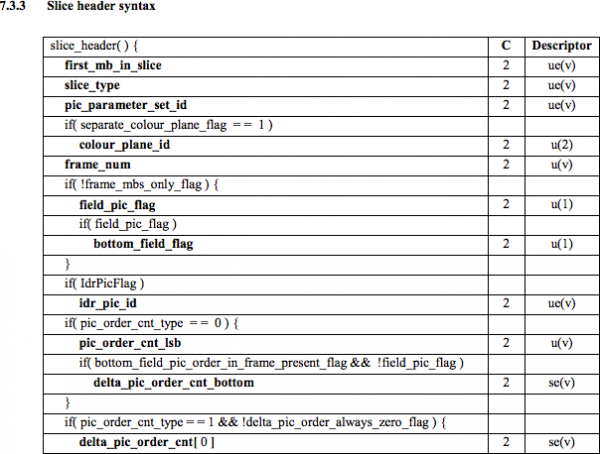
Med hjälp av specifikationsinformationen kommer det att vara möjligt att avkoda fragmenttypen (skivtyp) och bildrutenummer (bildnummer) bland andra viktiga områden.
För att få värdena för vissa fält (ue(v), me(v), se(v) eller te(v)), vi behöver avkoda fragmentet med hjälp av en speciell avkodare baserad på Den här metoden är mycket effektiv för att koda variabelvärden, särskilt när det finns många standardvärden.
innebörd skivtyp и bildnummer i den här videon är 7 (I-fragment) och 0 (första bildrutan).
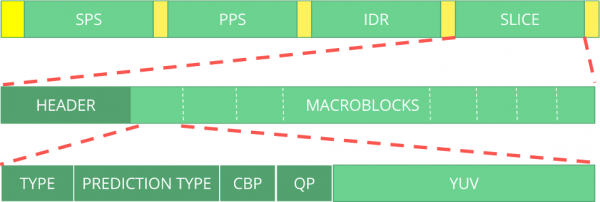
Bitströmmen kan betraktas som ett protokoll. Om du vill veta mer om bitströmmen bör du se specifikationen ITU H.264Här är ett makrodiagram som visar var bilddata finns (YUV i komprimerad form).
Andra bitströmmar kan också utforskas, såsom VP9, H.265 (HEVC) eller till och med vår nya bästa bitstream AV1Är de alla lika? Nej, men när du väl förstår minst en är det mycket lättare att förstå resten.
Vill du öva? Utforska H.264-bitströmmen
Du kan generera en video med en enda bildruta och använda MediaInfo för att undersöka bitströmmen. H.264Faktum är att ingenting hindrar dig från att ens titta på källkoden som analyserar bitströmmen. H.264 (AVC).
För övning kan du använda Intel Video Pro Analyzer (jag har redan sagt att programmet är betalt, men finns det en gratis testversion med en gräns på 10 bildrutor?).
Обзор
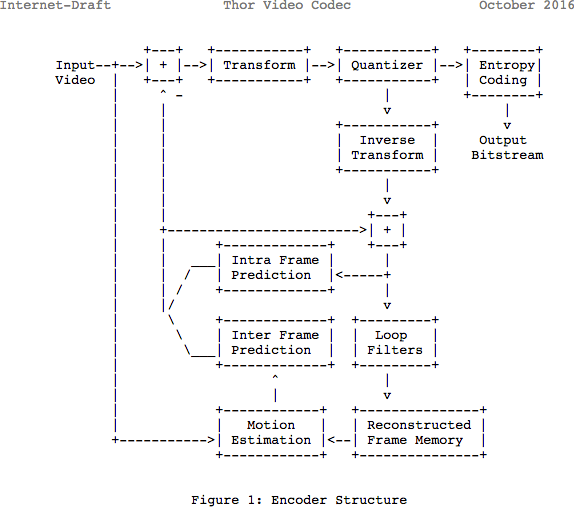
Observera att många moderna codecs använder samma modell som vi just studerade. Här ska vi titta på blockschemat för en videocodec. ThorDen innehåller alla steg vi har tagit. Hela poängen med det här inlägget är att åtminstone ge dig en bättre förståelse för innovationerna och dokumentationen inom detta område.
Tidigare beräknade vi att 139 GB diskutrymme skulle krävas för att lagra en videofil som varar i en timme med 720p-kvalitet och 30 fps. Om vi använder metoderna som vi diskuterade i den här artikeln (prediktioner mellan och mellan bildrutor, transformation, kvantisering, entropikodning etc.) kan vi (förutsatt att vi använder 0,031 bitar per pixel) uppnå en video av ganska tillfredsställande kvalitet som bara tar upp 367,82 MB, inte 139 GB minne.
Hur uppnår H.265 bättre komprimering än H.264?
Nu när vi vet mer om hur codecs fungerar är det lättare att förstå hur nya codecs kan leverera högre upplösning med färre bitar.
Om du jämför AVC и HEVC, är det värt att komma ihåg att detta nästan alltid är ett val mellan högre CPU-belastning och komprimeringsgraden.
HEVC har fler alternativ för avsnitt (och underavsnitt) än AVC, fler riktningar för intern prediktion, förbättrad entropikodning och mer. Alla dessa förbättringar har gjort H.265 kapabel att komprimera 50 % mer än H.264.
Del ett:
Källa: will.com
