

Magiging interesado ang post na ito sa mga gumagamit ng R table data processing library data.table at maaaring ikalulugod na makita ang flexibility ng aplikasyon nito sa iba't ibang halimbawa.
May inspirasyon ng isang magandang halimbawa , at umaasa na nabasa mo na ang kanyang artikulo, iminumungkahi kong maghukay ng mas malalim sa pag-optimize ng code at pagganap batay sa talaan ng mga impormasyon.
Panimula: Saan nagmula ang data.table?
Pinakamainam na magsimulang makilala ang aklatan mula sa malayo, ibig sabihin, sa mga istruktura ng data kung saan maaaring makuha ang data.table object (simula dito, DT).
Array
Kodigo
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Ang isa sa gayong mga istruktura ay isang array (?base::array). Tulad ng sa ibang mga wika, ang mga arrays dito ay multidimensional. Gayunpaman, ang kawili-wili ay, halimbawa, ang isang two-dimensional na array ay nagsisimulang magmana ng mga katangian mula sa klase ng matrix. (?base::matrix), at isang one-dimensional array, na mahalaga rin, ay hindi namamana mula sa isang vector (?base::vector).
Mahalagang maunawaan na ang uri ng data na nakapaloob sa anumang bagay ay dapat suriin ng function base::typeof, na nagbabalik ng panloob na paglalarawan ng uri ayon sa R Mga panloob — isang karaniwang protocol ng wika na nauugnay sa orihinal C.
Ang isa pang utos upang matukoy ang klase ng isang bagay, base::klase, sa kaso ng mga vector, ibinabalik ang uri ng vector (ito ay may ibang pangalan mula sa panloob, ngunit nagbibigay-daan din sa iyo na maunawaan ang uri ng data).
Listahan
Mula sa isang two-dimensional array, na kilala rin bilang isang matrix, maaari kang pumunta sa isang listahan (?base::listahan).
Kodigo
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Maraming bagay ang nangyayari nang sabay-sabay:
- Ang pangalawang dimensyon ng matrix ay bumagsak, iyon ay, nakakakuha kami ng parehong listahan at isang vector sa parehong oras.
- Ang isang listahan ay nagmana mula sa mga klase na ito. Tandaan na ang bawat elemento ng listahan ay tumutugma sa isang solong (scalar) na halaga mula sa isang cell ng matrix array.
Dahil ang isang listahan ay isa ring vector, maaaring ilapat dito ang ilang function ng vector.
Dataframe
Mula sa isang listahan, matrix o vector maaari kang pumunta sa isang data frame (?base::data.frame).
Kodigo
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Ano ang kawili-wili tungkol dito ay ang dataframe ay nagmamana mula sa isang listahan! Ang mga column ng dataframe ay ang mga cell ng listahan. Magiging mahalaga ito sa ibang pagkakataon kapag gumamit kami ng mga function na nalalapat sa mga listahan.
talaan ng mga impormasyon
Kumuha ng DT (?data.table::data.table) ay maaaring mula sa frame ng data, listahan, vector, o matrix. Halimbawa, tulad nito (sa lugar).
Kodigo
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Ano ang kapaki-pakinabang na, tulad ng isang dataframe, ang isang DT ay nagmamana ng mga katangian ng isang listahan.
DT at memorya
Hindi tulad ng lahat ng iba pang mga bagay sa R base, ang mga DT ay ipinasa sa pamamagitan ng sanggunian. Kung kailangan mong kopyahin ang mga ito sa isang bagong lokasyon ng memorya, kailangan mo ng isang function data.table::kopya o kailangan mong pumili mula sa lumang bagay.
Kodigo
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Ito ay nagtatapos sa pagpapakilala. Ang DT ay isang pagpapatuloy ng pag-unlad ng mga istruktura ng data sa R, pangunahin sa pamamagitan ng pagpapalawak at pagpapabilis ng mga operasyong isinagawa sa mga object ng dataframe. Habang pinapanatili ang mana mula sa iba pang primitives.
Ilang halimbawa ng paggamit ng data.table properties
Bilang isang listahan…
Ang pag-ulit sa mga hilera ng isang dataframe o DT ay hindi ang pinakamagandang ideya, dahil ang loop code ay nasa wika R mas mabagal C, ngunit ang pag-loop sa mga column, na kadalasang mas kaunti, ay ganap na posible. Kapag naglo-loop sa mga column, tandaan na ang bawat column ay isang elemento ng listahan, karaniwang naglalaman ng vector. At ang mga operasyon sa mga vector ay mahusay na na-vector sa mga pangunahing function ng wika. Maaari mo ring gamitin ang mga operator ng pagpili na likas sa mga listahan at vector: `[[`, `$`.
Kodigo
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vectorization
Kung kailangan mong umulit sa mga hilera ng isang malaking DT, ang pinakamahusay na solusyon ay ang magsulat ng isang vectorized function. Ngunit kung hindi iyon gumana, tandaan na ang loop sa loob Mas mabilis pa rin ang DT kaysa sa cycle in R, dahil ito ay ginanap sa C.
Subukan natin ito sa mas malaking halimbawa na may 100K row. Kukunin namin ang unang titik mula sa mga salitang kasama sa column vector. w.
Na-update
Kodigo
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Unang tumakbo na may pag-ulit sa mga hilera:
Yunit: millisecond
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
Ang ibig sabihin ng lq median uq max neval
+451.9998 460.1593 456.2505 460.9147 621.4042 100
Ang pangalawang run, kung saan ang vectorization ay nangyayari sa pamamagitan ng pag-convert ng listahan sa isang matrix at pagkuha ng mga elemento ng slice na may index 1 (ang huli ay ang aktwal na vectorization). Pagwawasto: vectorization sa antas ng function. strsplit, na maaaring tumanggap ng vector bilang input. Lumalabas na ang pamamaraan para sa pag-convert ng isang listahan sa isang matrix ay mas kumplikado kaysa sa vectorization mismo, ngunit kahit na sa kasong ito, ito ay mas mabilis kaysa sa hindi-vectorized na bersyon.
Yunit: millisecond
expr min lq mean median uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 +185.9893 442.5199 100
Pagpapabilis ng median sa 3 beses.
Ang ikatlong run, kung saan binago ang matrix conversion scheme.
Yunit: millisecond
expr min lq mean median uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 +42.11975 222.972 100
Pagpapabilis ng median sa 13 beses.
Kailangan mong mag-eksperimento sa bagay na ito, mas marami ang mas mahusay.
Narito ang isa pang halimbawa ng vectorization, kasama rin ang text, ngunit mas malapit sa mga totoong kondisyon: iba't ibang haba ng salita at iba't ibang bilang ng salita. Ang layunin ay kunin ang unang tatlong salita. ganito:
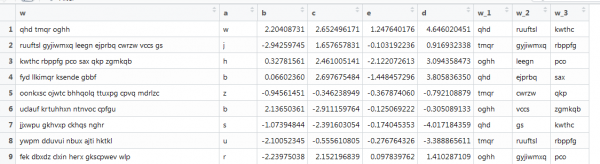
Ang nakaraang function ay hindi gumagana dito dahil ang mga vector ay magkaiba ang haba, at tinukoy namin ang laki ng matrix. Gawin nating muli ito sa pamamagitan ng paghuhukay online.
Kodigo
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Yunit: millisecond
expr min lq ibig sabihin median
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fixed = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
+1178.738 1356.816 100
Tumakbo ang script sa average na bilis na 1 segundo. Hindi masama.
Na-link ng isang chain…
Maaari kang magtrabaho sa mga bagay na DT gamit ang chaining. Ito ay mukhang pag-chain sa mga panaklong syntax sa kanan, mahalagang isang sugar coating.
Kodigo
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Tumutulo ito sa mga tubo...
Ang parehong mga operasyon ay maaaring isagawa gamit ang piping; ito ay mukhang katulad, ngunit mas mayaman sa pagganap, dahil ang anumang mga pamamaraan ay maaaring gamitin, hindi lamang DT. Kunin natin ang mga logistic regression coefficient para sa ating sintetikong data na may bilang ng mga filter ng DT.
Kodigo
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Mga istatistika, machine learning, at higit pa sa loob ng DT
Maaaring gamitin ang mga function ng Lambda, ngunit kung minsan ay mas mahusay na gawin ang mga ito nang hiwalay, isulat ang buong pipeline ng pagsusuri ng data, at umalis ka na—gumagana ang mga ito sa loob ng DT. Ang halimbawa ay pinayaman ng lahat ng mga tampok na binanggit sa itaas, kasama ang ilang mga kapaki-pakinabang na bagay mula sa DT arsenal (tulad ng pag-access sa DT mismo sa loob ng DT sa pamamagitan ng isang link, kung minsan ay ipinasok sa labas ng pagkakasunud-sunod, ngunit para lamang makatiyak).
Kodigo
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
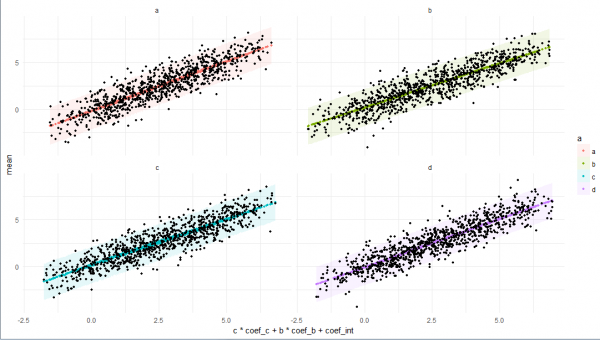
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Konklusyon
Umaasa ako na nakagawa ako ng isang komprehensibo, bagama't tiyak na hindi kumpleto, larawan ng object ng data.table, mula sa mga katangian nito na nauugnay sa pamana mula sa mga klase ng R hanggang sa sarili nitong mga tampok at kapaligiran ng mga tidyverse na elemento. Umaasa ako na makakatulong ito sa iyo na mas maunawaan at mailapat ang aklatang ito sa iyong trabaho. aliwan.
Salamat sa iyo!
Buong code
Kodigo
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Pinagmulan: www.habr.com
