

Què fer si la potència d'un servidor no és suficient per processar totes les sol·licituds i el fabricant del programari no proporciona equilibri de càrrega? Hi ha moltes opcions, des de comprar un equilibrador de càrrega fins a limitar el nombre de sol·licituds. Quina és la correcta s'ha de determinar segons la situació, tenint en compte les condicions existents. En aquest article us explicarem què podeu fer si el vostre pressupost és limitat i teniu un servidor gratuït.
Com a sistema per al qual calia reduir la càrrega en un dels servidors, vam triar DLP (sistema de prevenció de fuites d'informació) d'InfoWatch. Una característica de la implementació va ser la col·locació de la funció d'equilibri en un dels servidors de "combat".
Un dels problemes que vam trobar va ser la incapacitat d'utilitzar Source NAT (SNAT). Per què era necessari i com es va resoldre el problema, descriurem més endavant.
Per tant, inicialment el diagrama lògic del sistema existent tenia aquest aspecte:
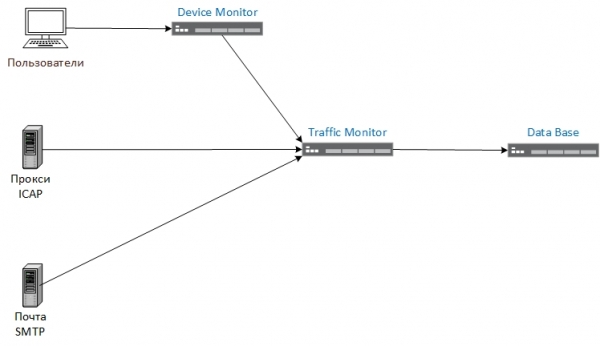
El trànsit ICAP, SMTP i esdeveniments dels ordinadors dels usuaris es van processar al servidor Traffic Monitor (TM). Al mateix temps, el servidor de bases de dades va fer front fàcilment a la càrrega després de processar esdeveniments a la TM, però la càrrega a la TM en si era pesada. Això era evident a partir de l'aparició d'una cua de missatges al servidor Device Monitor (DM), així com de la CPU i la càrrega de memòria del TM.
A primera vista, si afegim un altre servidor de TM a aquest esquema, llavors ICAP o DM es podrien canviar, però vam decidir no utilitzar aquest mètode, ja que la tolerància a errors es va reduir.
Descripció de la solució
En el procés de recerca d'una solució adequada, ens vam optar per un programari de distribució lliure juntament amb . Perquè keepalived resol el problema de crear un clúster de migració per error i també pot gestionar l'equilibrador LVS.
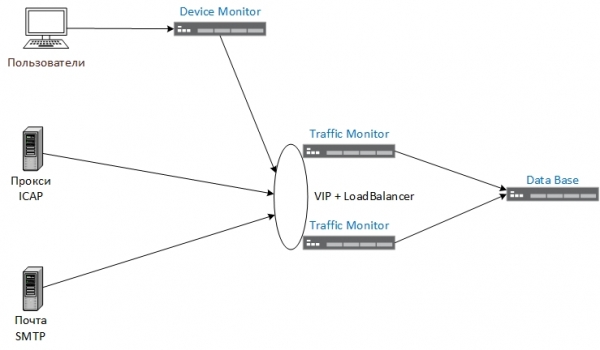
El que volíem aconseguir (reduir la càrrega de la TM i mantenir el nivell actual de tolerància a fallades) hauria d'haver funcionat segons l'esquema següent:
En comprovar la funcionalitat, va resultar que el conjunt de RedHat personalitzat instal·lat als servidors no és compatible amb SNAT. En el nostre cas, teníem previst utilitzar SNAT per assegurar-nos que els paquets entrants i les respostes a ells s'enviïn des de la mateixa adreça IP, en cas contrari obtindríem la següent imatge:
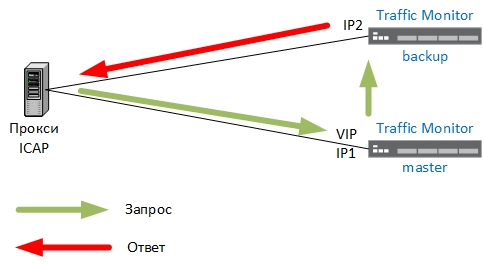
Això és inacceptable. Per exemple, un servidor intermediari, després d'haver enviat paquets a una adreça IP virtual (VIP), esperarà una resposta de VIP, però en aquest cas vindrà d'IP2 per a les sessions enviades a còpia de seguretat. Es va trobar una solució: calia crear una altra taula d'encaminament a la còpia de seguretat i connectar dos servidors de TM amb una xarxa separada, tal com es mostra a continuació:
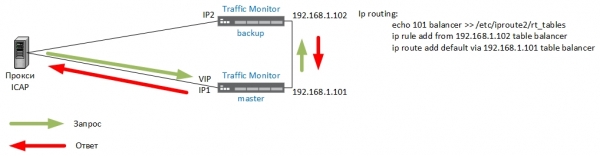
ajustos
Implementarem un esquema de dos servidors amb serveis ICAP, SMTP, TCP 9100 i un equilibrador de càrrega instal·lat en un d'ells.
Tenim dos servidors RHEL6, dels quals s'han eliminat els repositoris estàndard i alguns paquets.
Serveis que necessitem equilibrar:
• ICAP – tcp 1344;
• SMTP – tcp 25.
Servei de transmissió de trànsit des de DM – tcp 9100.
En primer lloc, hem de planificar la xarxa.
Adreça IP virtual (VIP):
• IP: 10.20.20.105.
Servidor TM6_1:
• IP externa: 10.20.20.101;
• IP interna: 192.168.1.101.
Servidor TM6_2:
• IP externa: 10.20.20.102;
• IP interna: 192.168.1.102.
A continuació, habilitem el reenviament IP en dos servidors de TM. Com fer-ho es descriu a RedHat .
Decidim quin dels servidors que tindrem és el principal i quin serà el de còpia de seguretat. Deixeu que el mestre sigui TM6_1, la còpia de seguretat sigui TM6_2.
A la còpia de seguretat, creem una nova taula d'encaminament de l'equilibrador i regles d'encaminament:
[root@tm6_2 ~]echo 101 balancer >> /etc/iproute2/rt_tables
[root@tm6_2 ~]ip rule add from 192.168.1.102 table balancer
[root@tm6_2 ~]ip route add default via 192.168.1.101 table balancerLes ordres anteriors funcionen fins que es reinicia el sistema. Per assegurar-vos que les rutes es conserven després d'un reinici, podeu introduir-les /etc/rc.d/rc.local, però millor mitjançant el fitxer de configuració /etc/sysconfig/network-scripts/route-eth1 (nota: aquí s'utilitza una sintaxi diferent).
Instal·leu keepalived als dos servidors de TM. Hem utilitzat rpmfind.net com a font de distribució:
[root@tm6_1 ~]#yum install https://rpmfind.net/linux/centos/6.10/os/x86_64/Packages/keepalived-1.2.13-5.el6_6.x86_64.rpmA la configuració de keepalived, assignem un dels servidors com a mestre i l'altre com a còpia de seguretat. A continuació, configurem VIP i serveis per a l'equilibri de càrrega. El fitxer de configuració normalment es troba aquí: /etc/keepalived/keepalived.conf.
Configuració del servidor TM1
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state MASTER
interface eth0
lvs_sync_daemon_inteface eth0
virtual_router_id 51
priority 151
advert_int 1
authentication {
auth_type PASS
auth_pass example
}
virtual_ipaddress {
10.20.20.105
}
}
virtual_server 10.20.20.105 1344 {
delay_loop 6
lb_algo wrr
lb_kind NAT
protocol TCP
real_server 192.168.1.101 1344 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 1344
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.1.102 1344 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 1344
nb_get_retry 3
delay_before_retry 3
}
}
}
virtual_server 10.20.20.105 25 {
delay_loop 6
lb_algo wrr
lb_kind NAT
protocol TCP
real_server 192.168.1.101 25 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 25
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.1.102 25 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 25
nb_get_retry 3
delay_before_retry 3
}
}
}
virtual_server 10.20.20.105 9100 {
delay_loop 6
lb_algo wrr
lb_kind NAT
protocol TCP
real_server 192.168.1.101 9100 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 9100
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.1.102 9100 {
weight 1
TCP_CHECK {
connect_timeout 3
connect_port 9100
nb_get_retry 3
delay_before_retry 3
}
}
}Configuració del servidor TM2
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
lvs_sync_daemon_inteface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass example
}
virtual_ipaddress {
10.20.20.105
}
}Instal·lem LVS al mestre, que equilibrarà el trànsit. No té sentit instal·lar un equilibrador per al segon servidor, ja que en la configuració només tenim dos servidors.
[root@tm6_1 ~]##yum install https://rpmfind.net/linux/centos/6.10/os/x86_64/Packages/ipvsadm-1.26-4.el6.x86_64.rpmL'equilibrador serà gestionat per keepalived, que ja hem configurat.
Per completar la imatge, afegim keepalived a l'inici automàtic als dos servidors:
[root@tm6_1 ~]#chkconfig keepalived onConclusió
Comprovació dels resultats
Executem keepalived als dos servidors:
service keepalived startComprovació de la disponibilitat d'una adreça virtual VRRP
Assegurem-nos que el VIP estigui al màster:
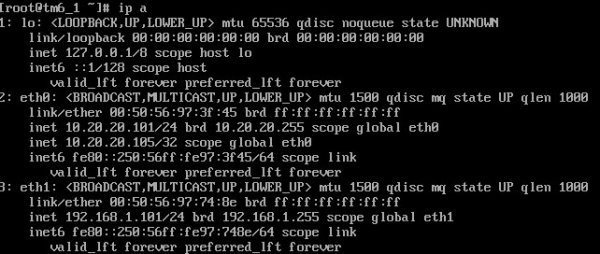
I no hi ha cap VIP a la còpia de seguretat:
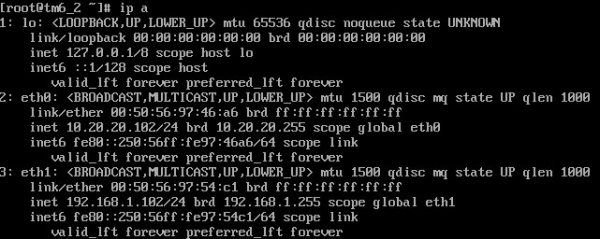
Mitjançant l'ordre ping, comprovarem la disponibilitat del VIP:
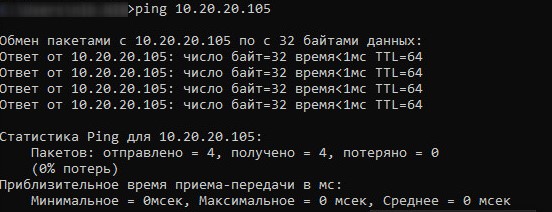
Ara podeu tancar el master i tornar a executar l'ordre ping.
El resultat hauria de seguir sent el mateix, i a la còpia de seguretat veurem VIP:
Comprovació de l'equilibri del servei
Prenem per exemple SMTP. Llançarem dues connexions a 10.20.20.105 simultàniament:
telnet 10.20.20.105 25A master hauríem de veure que ambdues connexions estan actives i connectades a diferents servidors:
[root@tm6_1 ~]#watch ipvsadm –Ln 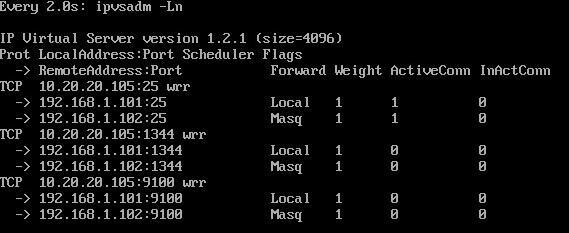
Així, hem implementat una configuració tolerant a errors dels serveis de TM instal·lant un equilibrador en un dels servidors de TM. Per al nostre sistema, això va reduir la càrrega de la TM a la meitat, cosa que va permetre resoldre el problema de la manca d'escala horitzontal mitjançant el sistema.
En la majoria dels casos, aquesta solució s'implementa ràpidament i sense costos addicionals, però de vegades hi ha una sèrie de limitacions i dificultats en la configuració, per exemple, quan s'equilibra el trànsit UDP.
Font: www.habr.com
