

El principi d'incertesa de Heisenberg estableix que no es pot mesurar la posició d'un objecte i la seva velocitat alhora. Si un objecte es mou, no té cap ubicació. I si hi ha una ubicació, vol dir que no té velocitat.

Pel que fa als microserveis de la plataforma Red Hat OpenShift (i amb Kubernetes), gràcies al programari de codi obert adequat, poden informar simultàniament del seu rendiment i salut. Això, per descomptat, no refuta l'antic Heisenberg, però elimina la incertesa quan es treballa amb aplicacions al núvol. Istio facilita el seguiment i el seguiment d'aquestes aplicacions per mantenir-ho tot sota control.
Decidir la terminologia
Sota traçat (Rastreig) entenem el registre de l'activitat del sistema. Això sona força general, però de fet una de les regles bàsiques aquí és bolcar les dades de traça a l'emmagatzematge adequat sense preocupar-se de formatar-les. I tota la feina de cercar i analitzar dades recau en el consumidor. Istio utilitza el sistema de traça Jaeger, que implementa el model de dades OpenTracing.
A les pistes (Traces, i la paraula "traces" s'utilitza aquí en el sentit de "traces", com per exemple, en l'examen balístic) anomenarem dades que descriuen completament el pas d'una sol·licitud o una unitat de treball, com diuen, "des i cap a". Per exemple, tot el que passa des que un usuari fa clic en un botó d'una pàgina web fins que es retornen les dades, inclosos tots els microserveis implicats. Podem dir que un rastre descriu completament (o modela) el viatge d'anada i tornada d'una sol·licitud. A la interfície de Jaeger, les traces es descomponen en components al llarg de l'eix del temps, de manera similar a com es pot descompondre una cadena en enllaços individuals. Només en lloc d'enllaços, el recorregut consta dels anomenats trams.
Lapse és l'interval des de l'inici d'una unitat de treball fins a la seva finalització. Continuant amb l'analogia, podem dir que cada tram representa una baula separada de la cadena. Un span pot tenir (o no) un o més spans secundaris. Com a conseqüència, l'extensió superior (span de l'arrel) tindrà la mateixa durada total que la traça a la qual pertany.
Seguiment - aquesta és, de fet, la mateixa observació del vostre sistema - amb els vostres ulls, a través de la interfície d'usuari o eines d'automatització. El seguiment es basa en dades de traça. A Istio, el monitoratge s'implementa amb Prometheus i té una interfície d'usuari adequada. Prometheus admet la supervisió automatitzada mitjançant alertes i gestors d'alertes.
Deixem marques
Perquè el traçat sigui possible, l'aplicació ha de crear una col·lecció de trams. Aleshores s'han d'exportar a Jaeger, de manera que al seu torn creï una representació visual de la traça. Entre altres coses, aquests intervals marquen el nom de l'operació, així com les seves marques de temps d'inici i finalització. La transmissió dels intervals s'aconsegueix enviant les capçaleres de sol·licitud HTTP específiques de Jaeger des de les sol·licituds entrants a les sol·licituds sortints. Depenent del llenguatge de programació utilitzat, això pot requerir modificacions menors al codi font de l'aplicació. A continuació es mostra el codi d'exemple en Java (utilitzant el marc Spring Boot) que afegeix capçaleres B3 (a l'estil Zipkin) a la vostra sol·licitud a la classe de configuració de Spring:

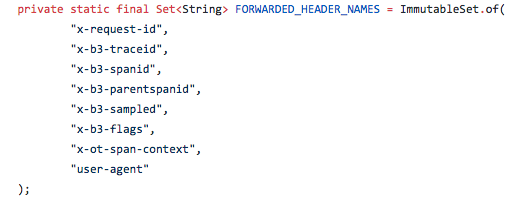
S'utilitzen els paràmetres de capçalera següents:
Si utilitzeu Java, podeu deixar el codi sol i afegir unes quantes línies al fitxer POM de Maven i establir les variables d'entorn. Aquí teniu les línies que heu d'afegir al vostre fitxer POM.XML per implementar Jaeger Tracer Resolver:

I les variables d'entorn corresponents s'estableixen al Dockerfile:

Això és tot, ara tot està configurat i els nostres microserveis començaran a generar dades de traça.
Mirem en termes generals
Istio inclou un panell de control senzill basat en Grafana. Un cop tot està configurat i executat a la plataforma Red Hat OpenShift PaaS (en el nostre exemple, Red Hat OpenShift i Kubernetes es despleguen en minishift), aquest tauler s'inicia amb l'ordre següent:
open "$(minishift openshift service grafana -u)/d/1/istio-dashboard?refresh=5⩝Id=1"
El panell Grafana us permet avaluar ràpidament el rendiment del sistema. Un fragment d'aquest panell es mostra a la figura següent:
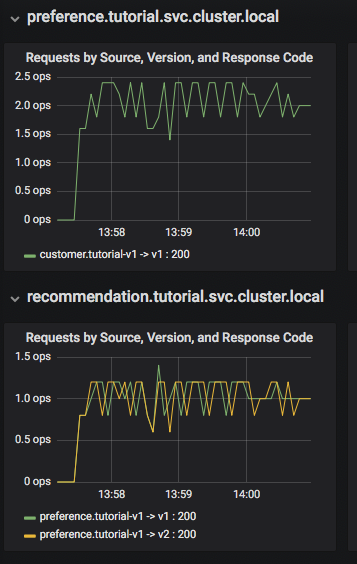
Aquí podeu veure que el microservei del client truca al microservei de preferència v1, que al seu torn crida als microserveis de recomanació v1 i v2. El tauler Grafana té un bloc de fila del tauler per a mètriques d'alt nivell, com ara el nombre total de sol·licituds (volum de sol·licituds global), percentatges d'èxit, errors 4xx. A més, hi ha una vista de malla de servidor amb gràfics per a cada servei i un bloc de fila de serveis per veure informació detallada sobre cada contenidor per a cada servei.
Ara aprofundim
Amb el traçat correctament configurat, Istio, com diuen, de seguida us permet aprofundir en l'anàlisi del rendiment del sistema. A la interfície d'usuari de Jaeger, podeu veure les traces i veure fins a quin punt i fins a quin punt arriben, així com localitzar visualment els colls d'ampolla de rendiment. Quan utilitzeu Red Hat OpenShift a la plataforma minishift, inicieu Jaeger UI amb l'ordre següent:
minishift openshift service jaeger-query --in-browser
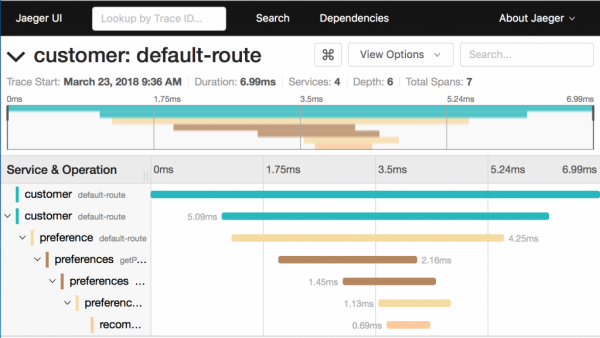
Què pots dir sobre el traçat en aquesta pantalla:
- Està dividit en 7 trams.
- El temps total d'execució és de 6.99 ms.
- El microservei de recomanació, que és l'últim de la cadena, gasta 0.69 ms.
Els diagrames d'aquest tipus permeten entendre ràpidament la situació en què, a causa d'un servei deficient, el rendiment de tot el sistema es ressent.
Ara compliquem la tasca i iniciem dues instàncies del microservei recomanació:v2 amb l'ordre oc scale —replicas=2 deployment/recommendation-v2. Aquí teniu les beines que tindrem després d'això:
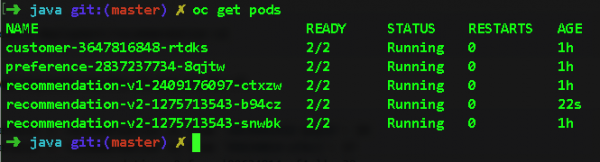
Si ara tornem a Jaeger i ampliem l'abast del servei de recomanació, podrem veure a quin pod s'envien les sol·licituds. Així, podem localitzar fàcilment els frens al nivell d'un pod específic. En aquest cas, heu de mirar el camp node_id:

On i com va tot
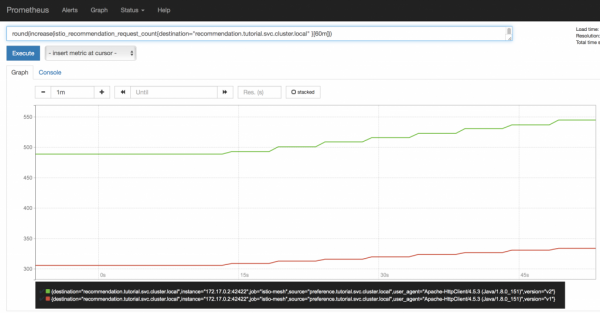
Ara anem a la interfície de Prometheus i, de manera força esperada, veiem allà que les sol·licituds entre la segona i la primera versió del servei de recomanació es divideixen en una proporció de 2:1, estrictament segons el nombre de pods que funcionen. A més, aquest gràfic canviarà dinàmicament a mesura que els pods augmentin i baixin, cosa que serà especialment útil per a Canary Deployment (la propera vegada mirarem més de prop aquest esquema de desplegament).
Només està començant
De fet, avui, com diuen, només hem ratllat la superfície de la gran quantitat d'informació útil sobre Jaeger, Grafana i Prometeu. En general, aquest era el nostre objectiu: indicar-vos la direcció correcta i obrir les perspectives per a Istio.
I recordeu, tot això ja està integrat a Istio. Quan s'utilitzen determinats llenguatges de programació (per exemple, Java) i marcs (per exemple, Spring Boot), tot això es pot implementar sense tocar en absolut el codi de l'aplicació. Sí, el codi s'haurà de modificar lleugerament si utilitzeu altres idiomes, principalment Nodejs o C#. Però com que la traçabilitat (llegiu: "traça") és un dels requisits previs per crear sistemes de núvol fiables, haureu d'editar el codi de totes maneres, tant si teniu Istio com si no. Llavors, per què no aprofitar millor els vostres esforços?
Almenys per respondre sempre les preguntes "on?" i "A quina velocitat?" amb 100% de seguretat.
Enginyeria del caos a Istio: havia de ser
La capacitat de trencar coses ajuda a evitar que es trenquin.
Les proves de programari no només són difícils, sinó també importants. Al mateix temps, provar la correcció (per exemple, si una funció retorna el resultat correcte) és una cosa, però provar en una xarxa poc fiable és una tasca completament diferent (sovint se suposa que la xarxa sempre funciona sense errors, i això és la primera de les vuit idees errònies sobre els càlculs distribuïts). Una de les dificultats per resoldre aquest problema és com simular fallades en el sistema o introduir-les de manera intencionada, realitzant l'anomenada injecció de falla. Això es pot fer modificant el codi font de la pròpia aplicació. Però aleshores ja no provareu el vostre codi original, sinó una versió que simula específicament errors. Com a resultat, corre el risc de caure en l'abraçada mortal de la injecció d'errors i trobar-se amb Heisenbugs, fallades que desapareixen quan intenteu detectar-les.
Ara us mostrarem com Istio us ajuda a fer front a aquestes complexitats d'una vegada.
Com es veu tot quan tot és genial?
Considereu el següent escenari: tenim dos pods per al nostre microservei de recomanació, que vam extreure del tutorial d'Istio. Un pod té l'etiqueta v1 i l'altre s'etiqueta v2. Com podeu veure, fins ara tot funciona bé:
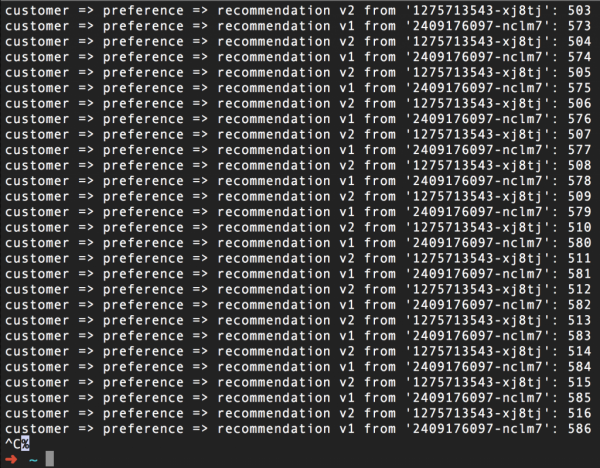
(Per cert, el número de la dreta és només el comptador de trucades de cada pod)
Però això no és el que necessitem, oi? Bé, intentem trencar-ho tot sense tocar en absolut el codi font.
Organitzem interrupcions en el funcionament d'un microservei
A continuació es mostra el fitxer yaml d'una regla d'encaminament d'Istio que fallarà (s'errorarà) la meitat de les vegades. servidor 503):
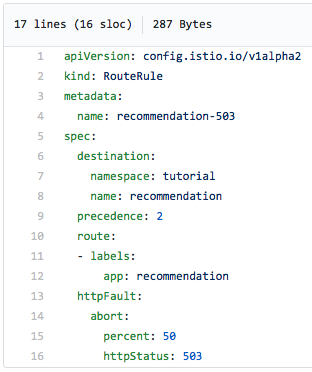
Tingueu en compte que indiquem explícitament que s'ha de retornar un error 503 en la meitat dels casos.
I aquí és com serà una captura de pantalla d'una ordre curl que s'executa en bucle després d'activar aquesta regla per simular errors. Com podeu veure, la meitat de les sol·licituds retornen l'error 503, independentment de quin pod (v1 o v2) van a:
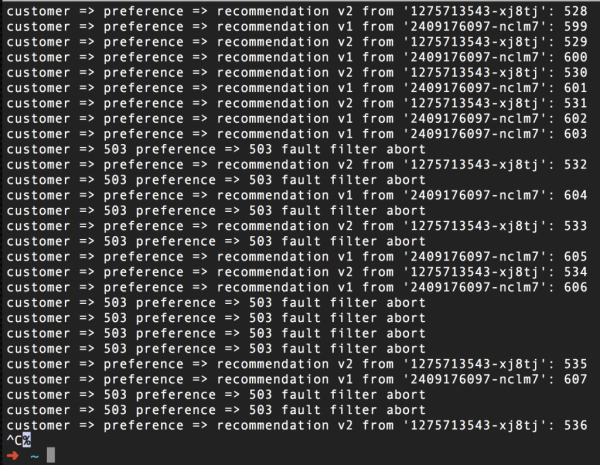
Per restablir el funcionament normal, n'hi ha prou amb eliminar aquesta regla, en el nostre cas amb l'ordre del tutorial istioctl delete routerule recommendation-503 -n. Aquí, Tutorial és el nom del projecte Red Hat OpenShift que executa el nostre tutorial Istio.
Introducció de retards artificials
Els errors 503 falsos ajuden a provar la resistència d'un sistema a la fallada, però la capacitat de predir i gestionar retards us hauria d'impressionar encara més. I els retards a la vida real passen més sovint que els fracassos. Un microservei lent és un verí que afecta tot el sistema. Amb Istio, podeu provar el vostre codi relacionat amb el retard sense canviar-lo de cap manera. En primer lloc, mostrarem com fer-ho en el cas de retards de xarxa introduïts artificialment.
Tingueu en compte que després de provar d'aquesta manera, és possible que hàgiu (o vulgueu) modificar el vostre codi. La bona notícia aquí és que en aquest cas seràs proactiu en lloc de reactiu. Així és exactament com s'ha d'estructurar el cicle de desenvolupament: codificació-prova-retroalimentació-codificació-test...
Així es veu la regla... Encara que saps què? Istio és tan senzill i aquest fitxer yaml és tan clar que tot en aquest exemple parla per si sol, només cal que mireu:
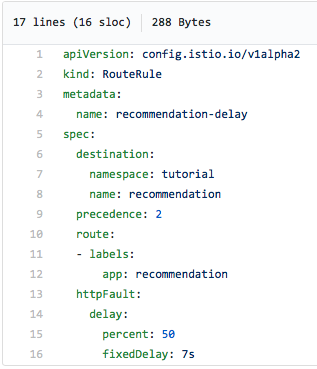
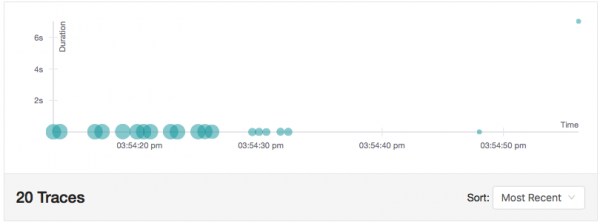
La meitat del temps experimentarem un retard de 7 segons. I això no és gens el mateix que si haguéssim inserit una ordre de son al codi font, ja que Istio en realitat retarda la sol·licitud 7 segons. Com que Istio admet el rastreig de Jaeger, aquest retard es nota a la interfície d'usuari de Jaeger, tal com es mostra a la captura de pantalla següent. Preste atenció a la sol·licitud llarga a la cantonada superior dreta del diagrama: la seva durada és de 7.02 segons:
Aquest script us permet provar el vostre codi en condicions de latència de xarxa. I és evident que eliminant aquesta norma, eliminarem el retard artificial. Repetim, però de nou vam fer tot això sense tocar el codi font de cap manera.
No et retiris i no et rendis
Una altra característica útil d'Istio per a l'enginyeria del caos són les trucades repetides al servei un nombre determinat de vegades. El punt aquí és seguir intentant-ho quan la primera sol·licitud acabi amb un error 503, i potser l'onzena vegada que tindrem sort. Potser el servei va caure una estona per un motiu o un altre. Sí, aquest motiu s'hauria d'excavar i eliminar. Però això arribarà més tard, però de moment intentarem assegurar-nos que el sistema segueixi funcionant.
Per tant, volem que el servei llanci un error 503 de tant en tant i, aleshores, Istio intentarà contactar-hi de nou. I aquí necessitem clarament una manera de generar un error 503 sense tocar el codi en si...
Atura, espera! Ho acabem de fer.
Aquest fitxer farà que el servei de recomanació-v2 emeti un error 503 la meitat del temps:
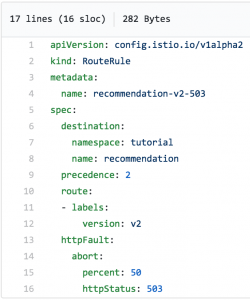
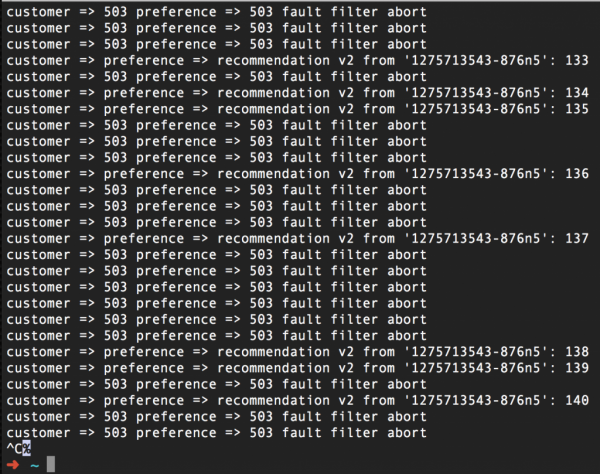
Evidentment, algunes sol·licituds fallaran:
Ara fem servir la funció Istio Retry:
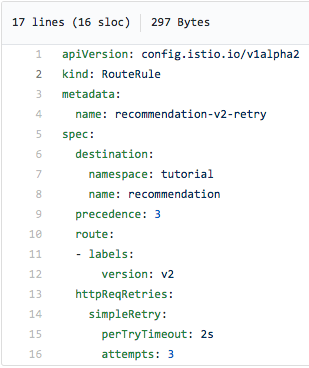
Aquesta regla d'encaminament es repeteix tres vegades a intervals de dos segons i hauria de reduir (i, idealment, eliminar del radar) els errors 503:
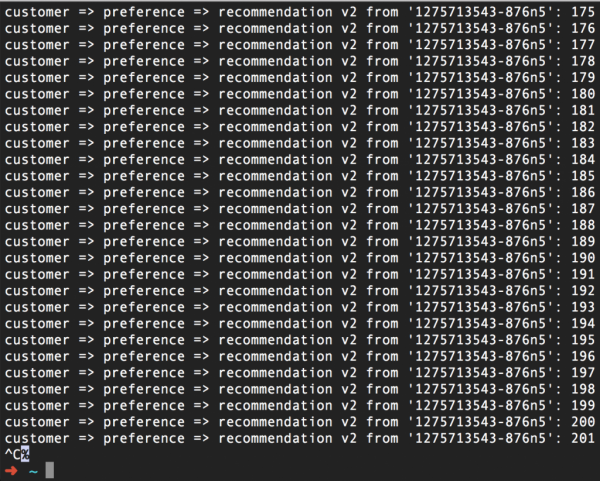
En resum: vam fer que Istio, en primer lloc, generi un error 503 per a la meitat de les sol·licituds. I en segon lloc, el mateix Istio fa tres intents per tornar a contactar amb el servei quan es produeix un error 503. Com a resultat, tot funciona bé. Així, amb la funció Reintentar, hem complert la nostra promesa de no rendir-nos i no rendir-nos.
I sí, ho vam tornar a fer sense tocar gens el codi. Tot el que necessitàvem eren dues regles d'encaminament d'Istio:

Com no defraudar l'usuari o set no n'espereu un
Ara donem la volta a la situació i considerem un escenari en què l'únic que cal fer és no retirar-se o rendir-se durant un període de temps determinat. I després només cal que deixeu d'intentar processar la sol·licitud, per no obligar a tothom a esperar un servei lent. En altres paraules, no defensarem una posició perduda, sinó que ens retirarem a una línia de reserva per no defraudar l'usuari del lloc i no obligar-lo a languir en la ignorància.
A Istio, podeu establir un temps d'espera d'execució de la consulta. Si el servei supera aquest temps d'espera, es retorna un error 504 (Gateway Timeout) - de nou, tot es fa mitjançant la configuració d'Istio. Però haurem d'afegir una ordre de son al codi font del servei (i després, per descomptat, realitzar una reconstrucció i tornar a desplegar) per simular el funcionament lent del servei. Per desgràcia, no funcionarà d'una altra manera.
Així doncs, hem inserit una repòs de tres segons al codi de servei de recomanació v2, hem reconstruït la imatge corresponent i hem tornat a desplegar el contenidor, i ara afegirem un temps d'espera utilitzant la següent regla d'encaminament d'Istio:
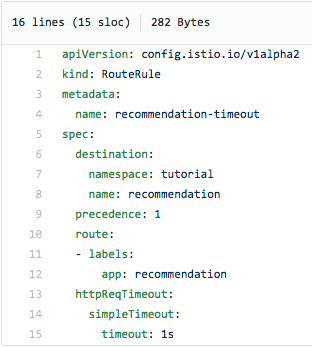
A la captura de pantalla de dalt podeu veure que renunciem a intentar contactar amb el servei de recomanacions si no rebem resposta en un segon, és a dir, abans que es produeixi l'error 504. Després d'aplicar aquesta regla d'encaminament (i d'afegir un son de tres segons). al codi de servei de recomanació :v2), obtenim això:
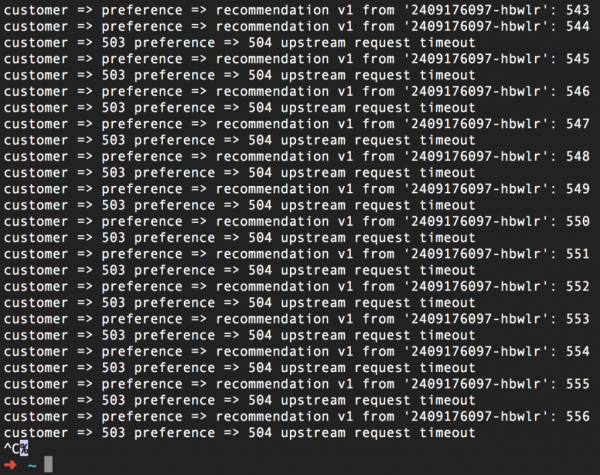
Repetim de nou, però el temps d'espera es pot configurar sense tocar el codi font de cap manera. I l'avantatge afegit aquí és que ara podeu modificar el vostre codi per respondre al temps d'espera i provar fàcilment aquestes modificacions amb Istio.
I ara està tot junt
Injectar una mica de caos amb Istio és una bona manera de provar el vostre codi i la fiabilitat del vostre sistema en conjunt. Els patrons de reserva, mampares i disjuntors, mecanismes per crear errors i retards artificials, així com trucades de reintentar i temps d'espera seran molt útils a l'hora de crear sistemes de núvol tolerants a errors. Combinades amb Kubernetes i Red Hat OpenShift, aquestes eines us ajudaran a afrontar el futur amb confiança.
Font: www.habr.com
