

Aquest article és una traducció del meu article sobre mitjà - , que va resultar ser força popular, probablement per la seva senzillesa. Per tant, vaig decidir escriure-ho en rus i afegir-hi una mica per deixar clar a una persona normal que no és un especialista en dades què és un magatzem de dades (DW) i què és un llac de dades (Data Lake) i com ho fan. portar-se junts.
Per què volia escriure sobre el llac de dades? He estat treballant amb dades i anàlisi des de fa més de 10 anys, i ara definitivament estic treballant amb big data a Amazon Alexa AI a Cambridge, que és a Boston, encara que visc a Victòria a l'illa de Vancouver i visito sovint Boston, Seattle. , i a Vancouver, i de vegades fins i tot a Moscou, parlo en conferències. També escric de tant en tant, però escric sobretot en anglès, i ja ho he escrit , també tinc la necessitat de compartir tendències d'anàlisi d'Amèrica del Nord i, de vegades, escric .
Sempre he treballat amb magatzems de dades i des del 2015 vaig començar a treballar estretament amb Amazon Web Services i, en general, vaig passar a analítiques en núvol (AWS, Azure, GCP). He observat l'evolució de les solucions d'anàlisi des del 2007 i fins i tot he treballat per al proveïdor de magatzems de dades Teradata i el vaig implementar a Sberbank, i va ser llavors quan va aparèixer Big Data amb Hadoop. Tothom va començar a dir que l'era de l'emmagatzematge havia passat i ara tot estava a Hadoop, i després van començar a parlar de Data Lake, de nou, que ara definitivament havia arribat el final del magatzem de dades. Però, afortunadament (potser per desgràcia per a alguns que van guanyar molts diners configurant Hadoop), el magatzem de dades no va desaparèixer.
En aquest article veurem què és un llac de dades. Aquest article està pensat per a persones que tenen poca o cap experiència amb magatzems de dades.

A la imatge hi ha el llac Bled, aquest és un dels meus llacs preferits, tot i que només hi vaig estar una vegada, el vaig recordar tota la vida. Però parlarem d'un altre tipus de llac: un llac de dades. Potser molts de vosaltres ja heu sentit parlar d'aquest terme més d'una vegada, però una definició més no perjudicarà ningú.
En primer lloc, aquí teniu les definicions més populars d'un Data Lake:
"un fitxer d'emmagatzematge de tot tipus de dades en brut que està disponible per a l'anàlisi per part de qualsevol persona de l'organització" - Martin Fowler.
"Si penseu que un data mart és una ampolla d'aigua, purificada, envasada i envasada per a un consum convenient, aleshores un data llac és un enorme dipòsit d'aigua en la seva forma natural. Usuaris, puc recollir aigua per mi mateix, submergir-me a fons, explorar" - James Dixon.
Ara sabem del cert que un llac de dades tracta d'analítica, ens permet emmagatzemar grans quantitats de dades en la seva forma original i tenim l'accés necessari i còmode a les dades.
Sovint m'agrada simplificar les coses. Si puc explicar un terme complex en termes senzills, vol dir que he entès com funciona i per a què serveix. Una vegada, estava furgant per... iPhone a la galeria de fotos, i em vaig adonar que això és un veritable llac de dades, fins i tot vaig fer una diapositiva per a conferències:
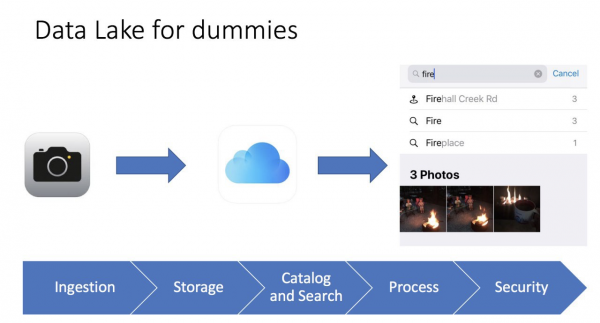
És molt senzill. Fem una foto amb el telèfon, la foto es desa al telèfon i es pot desar a l'iCloud (un servei d'emmagatzematge d'arxius basat en el núvol). El telèfon també recopila les metadades de la foto: què hi ha a la foto, la geoetiqueta i l'hora. Com a resultat, podem utilitzar una interfície fàcil d'utilitzar. iPhonePer trobar la nostra foto, fins i tot veiem les mètriques. Per exemple, quan busco fotos amb la paraula "foc", trobo tres fotos amb imatges d'una foguera. Per a mi, aquesta és una veritable eina d'intel·ligència empresarial que funciona de manera molt ràpida i eficient.
I per descomptat, no ens hem d'oblidar de la seguretat (autorització i autenticació), en cas contrari les nostres dades poden acabar fàcilment en el domini públic. Hi ha moltes notícies sobre grans corporacions i startups les dades de les quals van estar disponibles públicament a causa de la negligència dels desenvolupadors i la manca de seguir unes regles senzilles.
Fins i tot una imatge tan senzilla ens ajuda a imaginar què és un llac de dades, les seves diferències amb un magatzem de dades tradicional i els seus elements principals:
- Carregant dades (Ingestió) és un component clau del llac de dades. Les dades poden entrar al magatzem de dades de dues maneres: per lots (càrrega a intervals) i streaming (flux de dades).
- Emmagatzematge de fitxers (emmagatzematge) és el component principal del Data Lake. Necessitàvem que l'emmagatzematge fos fàcilment escalable, extremadament fiable i de baix cost. Per exemple, a AWS és S3.
- Catàleg i cerca (Catàleg i cerca): per evitar el pantà de dades (és quan aboquem totes les dades en una pila i, aleshores, és impossible treballar-hi), hem de crear una capa de metadades per classificar les dades. perquè els usuaris puguin trobar fàcilment les dades que necessiten per analitzar-les. A més, podeu utilitzar solucions de cerca addicionals com ElasticSearch. La cerca ajuda l'usuari a trobar les dades necessàries mitjançant una interfície fàcil d'utilitzar.
- Tractament (Procés): aquest pas és responsable de processar i transformar les dades. Podem transformar les dades, canviar-ne l'estructura, netejar-les i molt més.
- Безопасность (Seguretat) - És important dedicar temps al disseny de seguretat de la solució. Per exemple, el xifratge de dades durant l'emmagatzematge, el processament i la càrrega. És important utilitzar mètodes d'autenticació i autorització. Finalment, cal una eina d'auditoria.
Des d'un punt de vista pràctic, podem caracteritzar un llac de dades per tres atributs:
- Recull i emmagatzema qualsevol cosa — el llac de dades conté totes les dades, tant dades brutes no processades durant qualsevol període de temps com dades processades/netejades.
- Escaneig profund — un llac de dades permet als usuaris explorar i analitzar dades.
- Accés flexible — El llac de dades proporciona un accés flexible per a diferents dades i diferents escenaris.
Ara podem parlar de la diferència entre un magatzem de dades i un llac de dades. Normalment la gent pregunta:
- Què passa amb el magatzem de dades?
- Estem substituint el magatzem de dades per un llac de dades o l'ampliem?
- Encara és possible prescindir d'un llac de dades?
En resum, no hi ha una resposta clara. Tot depèn de la situació concreta, de les habilitats de l'equip i del pressupost. Per exemple, migrar un magatzem de dades a Oracle a AWS i crear un llac de dades per part d'una filial d'Amazon - Woot - .
D'altra banda, el proveïdor Snowflake diu que ja no cal pensar en un llac de dades, ja que la seva plataforma de dades (fins el 2020 era un magatzem de dades) permet combinar tant un llac de dades com un magatzem de dades. No he treballat gaire amb Snowflake, i és realment un producte únic que pot fer-ho. El preu del tema és una altra qüestió.
En conclusió, la meva opinió personal és que encara necessitem un magatzem de dades com a font principal de dades per als nostres informes, i el que no encaixa, emmagatzemem en un llac de dades. Tota la funció de l'anàlisi és proporcionar un accés fàcil a les empreses per prendre decisions. Sigui el que es digui, els usuaris empresarials treballen de manera més eficient amb un magatzem de dades que amb un llac de dades, per exemple a Amazon: hi ha Redshift (magatzem de dades analítiques) i hi ha Redshift Spectrum/Athena (interfície SQL per a un llac de dades a S3 basat en Rusc/Presto). El mateix s'aplica a altres magatzems de dades analítiques moderns.
Vegem una arquitectura típica de magatzem de dades:
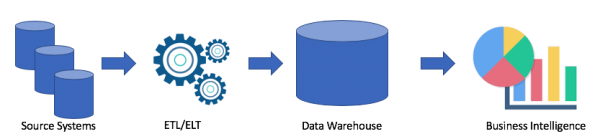
Aquesta és una solució clàssica. Tenim sistemes font, mitjançant ETL/ELT copiem dades a un magatzem de dades analítiques i les connectem a una solució d'intel·ligència empresarial (el meu preferit és Tableau, què passa amb el vostre?).
Aquesta solució té els següents desavantatges:
- Les operacions ETL/ELT requereixen temps i recursos.
- Per regla general, la memòria per emmagatzemar dades en un magatzem de dades analítiques no és barata (per exemple, Redshift, BigQuery, Teradata), ja que hem de comprar un clúster sencer.
- Els usuaris empresarials tenen accés a dades netes i sovint agregades i no tenen accés a dades en brut.
Per descomptat, tot depèn del teu cas. Si no teniu problemes amb el vostre magatzem de dades, no necessiteu cap data llac. Però quan sorgeixen problemes amb la manca d'espai, potència o preu tenen un paper clau, podeu considerar l'opció d'un llac de dades. És per això que el llac de dades és molt popular. Aquí teniu un exemple d'arquitectura de llac de dades:
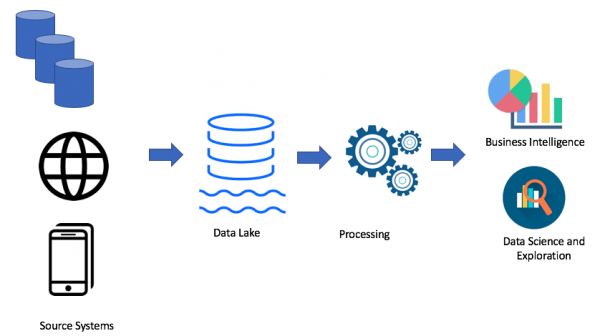
Utilitzant l'enfocament del llac de dades, carreguem dades en brut al nostre llac de dades (per lots o en streaming), i després processem les dades segons sigui necessari. El llac de dades permet als usuaris empresarials crear les seves pròpies transformacions de dades (ETL/ELT) o analitzar dades en solucions d'intel·ligència empresarial (si el controlador necessari està disponible).
L'objectiu de qualsevol solució d'anàlisi és servir als usuaris empresarials. Per tant, sempre hem de treballar segons els requisits empresarials. (A Amazon, aquest és un dels principis: treballar al revés).
Treballant tant amb un magatzem de dades com amb un llac de dades, podem comparar ambdues solucions:
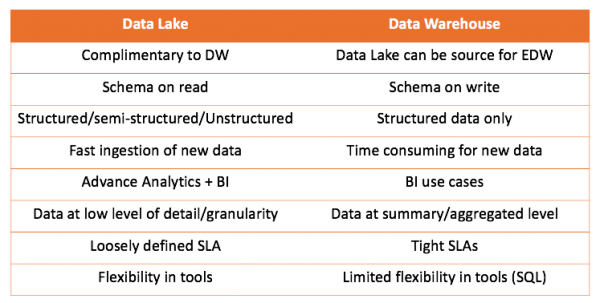
La principal conclusió que es pot extreure és que el data warehouse no competeix amb el data lake, sinó que el complementa. Però depèn de tu decidir què és adequat per al teu cas. Sempre és interessant provar-ho tu mateix i treure les conclusions correctes.
També m'agradaria explicar-vos un dels casos en què vaig començar a utilitzar l'enfocament del llac de dades. Tot és bastant trivial, vaig intentar utilitzar una eina ELT (teníem Matillion ETL) i Amazon Redshift, la meva solució va funcionar, però no s'adaptava als requisits.
Necessitava agafar registres web, transformar-los i agregar-los per proporcionar dades per a dos casos:
- L'equip de màrqueting volia analitzar l'activitat del bot per a SEO
- IT volia mirar les mètriques de rendiment del lloc web
Registres molt senzills, molt senzills. Aquí teniu un exemple:
https 2018-07-02T22:23:00.186641Z app/my-loadbalancer/50dc6c495c0c9188
192.168.131.39:2817 10.0.0.1:80 0.086 0.048 0.037 200 200 0 57
"GET https://www.example.com:443/ HTTP/1.1" "curl/7.46.0" ECDHE-RSA-AES128-GCM-SHA256 TLSv1.2
arn:aws:elasticloadbalancing:us-east-2:123456789012:targetgroup/my-targets/73e2d6bc24d8a067
"Root=1-58337281-1d84f3d73c47ec4e58577259" "www.example.com" "arn:aws:acm:us-east-2:123456789012:certificate/12345678-1234-1234-1234-123456789012"
1 2018-07-02T22:22:48.364000Z "authenticate,forward" "-" "-"Un fitxer pesava entre 1 i 4 megabytes.
Però hi havia una dificultat. Teníem 7 dominis arreu del món i es van crear 7000 mil fitxers en un dia. Això no és molt més volum, només 50 gigabytes. Però la mida del nostre clúster Redshift també era petita (4 nodes). La càrrega d'un fitxer de la manera tradicional va trigar aproximadament un minut. És a dir, el problema no es va resoldre frontalment. I aquest va ser el cas quan vaig decidir utilitzar l'enfocament del llac de dades. La solució semblava a això:
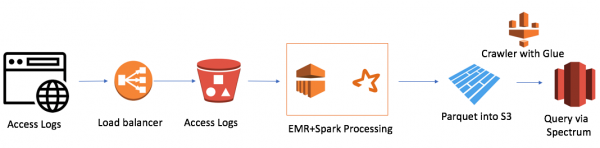
És bastant senzill (vull destacar que l'avantatge de treballar al núvol és la simplicitat). Jo solia:
- AWS Elastic Map Reduce (Hadoop) per a la potència de càlcul
- AWS S3 com a emmagatzematge de fitxers amb la capacitat de xifrar dades i limitar l'accés
- Spark com a potència informàtica InMemory i PySpark per a la transformació de la lògica i de les dades
- Parquet com a resultat de Spark
- AWS Glue Crawler com a recopilador de metadades sobre dades i particions noves
- Redshift Spectrum com a interfície SQL al llac de dades per als usuaris de Redshift existents
El clúster EMR+Spark més petit va processar tota la pila de fitxers en 30 minuts. Hi ha altres casos per a AWS, sobretot molts relacionats amb Alexa, on hi ha moltes dades.
Fa poc vaig saber que un dels desavantatges d'un llac de dades és el GDPR. El problema és quan el client demana que l'elimini i les dades es troben en un dels fitxers, no podem utilitzar el llenguatge de manipulació de dades i l'operació DELETE com en una base de dades.
Espero que aquest article hagi aclarit la diferència entre un magatzem de dades i un llac de dades. Si us interessava, puc traduir més dels meus articles o articles de professionals que he llegit. I també parlar de les solucions amb les quals treballo i de la seva arquitectura.
Font: www.habr.com
