

Un enginyer de Clyso va resumir l'experiència de crear un clúster d'emmagatzematge basat en un sistema Ceph distribuït tolerant a errors amb un rendiment superior als tebibytes per segon. Cal assenyalar que aquest és el primer clúster basat en Ceph que va poder aconseguir aquest indicador, però abans d'obtenir el resultat presentat, els enginyers van haver de superar una sèrie d'errors no evidents.
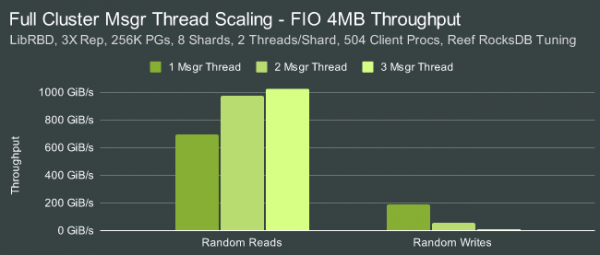
Per exemple, per augmentar el rendiment entre un 10 i un 20%, n'hi havia prou amb activar només el mode de rendiment màxim a la configuració d'estalvi d'energia de la BIOS als servidors i desactivar c-state (c-state canvia els paràmetres d'estalvi d'energia en funció de la càrrega, cosa que afecta Ceph). També va resultar que, en utilitzar unitats NVMe, el nucli... Linux Es dedica una quantitat significativa de temps a processar els spinlocks durant el procés d'actualització del mapatge IOMMU. La desactivació de l'IOMMU al nucli va provocar un augment notable del rendiment en les proves d'escriptura i lectura de blocs de 4 MB.
Tanmateix, desactivar l'IOMMU no va solucionar la caiguda de rendiment en escriure blocs aleatoris de 4KB. Mentre investigaven el problema, els enginyers van trobar correccions als scripts de compilació de Ceph de Gentoo i Ubuntu, que incloïa la compilació amb l'opció RelWithDebInfo, ja que habilitava el mode d'optimització "-O2" a GCC, cosa que augmentava significativament el rendiment de Ceph. La compilació amb la biblioteca TCMalloc també va comportar una penalització de rendiment. Canviar els indicadors de compilació i eliminar l'ús de TCMalloc va resultar en una reducció del triple del temps de compactació i un augment del doble del rendiment d'escriptura aleatòria de 4K. Finalment, es van fer optimitzacions addicionals a la configuració i als grups de col·locació (PG) de Reef RocksDB.
El clúster està format per 68 nodes basats en servidors Dell PowerEdge R6615 amb CPU AMD EPYC 9454P 48C/96T. Cada node conté 10 unitats Dell NVMe de 15.36 TB, dos adaptadors Ethernet Mellanox ConnectX-6 de 100 GbE i 192 GB de RAM. El programari es basa en Ubuntu 20.04.6 i Ceph 17.2.7. El clúster, que executa 63 nodes, té 630 OSD (Object Storage Daemon, un procés en segon pla que gestiona l'emmagatzematge de dades a l'emmagatzematge local, un OSD per unitat NVMe), tres processos MON (monitor, controla l'estat del clúster) i un procés MGR (Manager, un servei de gestió). La mida d'emmagatzematge és de 8.2 PB.
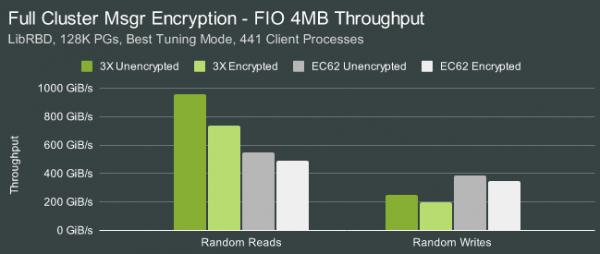
El rendiment per a les operacions de lectura seqüencial de blocs 4M va ser de 1025 GiB/s, escriptura - 270 GiB/s. En llegir blocs de 4 KB de manera aleatòria, el rendiment era de 25.5 milions d'operacions de lectura per segon i 4.9 milions d'operacions d'escriptura. L'habilitació del xifratge va reduir el rendiment de lectura a aproximadament 750 GiB/s. Quan es van activar els codis de correcció d'errors EC62, el rendiment era de 547 GiB/s en llegir i 387 GiB/s en escriure (la velocitat d'escriptura era més alta que sense codis de correcció), i amb accés aleatori 3.4 M IOPS en llegir i 936 K IOPS en escriure .
A més, es pot assenyalar que al setembre es va aconseguir una fita de rendiment similar de tebibytes per segon al clúster d'emmagatzematge d'exabytes CERN, implementat sobre la base de l'emmagatzematge distribuït obert EOS basat en el protocol XRootD.
Font: opennet.ru
