


SRE (Site Reliability Engineering) és un enfocament per garantir la disponibilitat de projectes web. Es considera un marc per a DevOps i parla sobre com aconseguir l'èxit en l'aplicació de les pràctiques de DevOps. Traducció en aquest article llibres de Google. Vaig preparar aquesta traducció jo mateix i em vaig basar en la meva pròpia experiència en la comprensió dels processos de seguiment. Al canal de Telegram и També vaig publicar una traducció del capítol 6 del mateix llibre sobre els objectius del nivell de servei.
Traducció per cat. Gaudeix de la lectura!
És impossible gestionar un servei si no s'entén quins indicadors són realment importants i com mesurar-los i avaluar-los. Amb aquesta finalitat, definim i oferim un cert nivell de servei als nostres usuaris, independentment de si utilitzen una de les nostres API internes o un producte públic.
Utilitzem la nostra intuïció, experiència i comprensió del desig dels usuaris d'entendre els indicadors de nivell de servei (SLI), els objectius de nivell de servei (SLO) i els acords de nivell de servei (SLA). Aquestes dimensions descriuen les principals mètriques que volem controlar i davant les quals reaccionarem si no podem oferir la qualitat de servei esperada. En última instància, escollir les mètriques adequades ajuda a guiar les accions correctes si alguna cosa va malament i també dóna confiança a l'equip SRE en la salut del servei.
Aquest capítol descriu l'enfocament que fem servir per combatre els problemes de modelització mètrica, selecció de mètriques i anàlisi de mètriques. La major part de l'explicació serà sense exemples, de manera que utilitzarem el servei Shakespeare descrit en el seu exemple d'implementació (cerca d'obres de Shakespeare) per il·lustrar els punts principals.
Terminologia del nivell de servei
És probable que molts lectors estiguin familiaritzats amb el concepte de SLA, però els termes SLI i SLO mereixen una definició acurada perquè, en general, el terme SLA està sobrecarregat i té diversos significats segons el context. Per a més claredat, volem separar aquests valors.
Indicadors
El SLI és un indicador de nivell de servei: una mesura quantitativa acuradament definida d'un aspecte del nivell de servei prestat.
Per a la majoria de serveis, l'SLI clau es considera la latència de la sol·licitud: el temps que triga a tornar una resposta a una sol·licitud. Altres SLI comuns inclouen la taxa d'error, sovint expressada com una fracció de totes les sol·licituds rebudes, i el rendiment del sistema, mesurat normalment en sol·licituds per segon. Les mesures sovint s'agreguen: primer es recullen les dades en brut i després es converteixen en una taxa de canvi, mitjana o percentil.
Idealment, SLI mesura directament el nivell de servei d'interès, però de vegades només hi ha disponible una mètrica relacionada per mesurar-la perquè l'original és difícil d'obtenir o interpretar. Per exemple, la latència del client és sovint una mètrica més adequada, però hi ha moments en què la latència només es pot mesurar al servidor.
Un altre tipus de SLI que és important per als SRE és la disponibilitat, o la part de temps durant la qual es pot utilitzar un servei. Sovint es defineix com la taxa de sol·licituds reeixides, de vegades anomenada rendiment. (La durada de la vida (la probabilitat que les dades es retinguin durant un període de temps prolongat) també és important per als sistemes d'emmagatzematge de dades.) Tot i que no és possible la disponibilitat del 100%, sovint s'expressen valors de disponibilitat propers al 100%; el nombre de "nous" » percentatge de disponibilitat. Per exemple, la disponibilitat del 99% i del 99,999% es podria etiquetar com a "2 nou" i "5 nou". L'objectiu actual de disponibilitat de Google Compute Engine és "tres nou i mig" o el 99,95%.
Objectius
Un SLO és un objectiu de nivell de servei: un valor objectiu o rang de valors per a un nivell de servei que es mesura pel SLI. Un valor normal per a SLO és "SLI ≤ Target" o "Lower Limit ≤ SLI ≤ Upper Limit". Per exemple, podríem decidir que tornarem els resultats de la cerca de Shakespeare "ràpidment" establint l'SLO en una latència mitjana de la consulta de cerca de menys de 100 mil·lisegons.
Escollir el SLO adequat és un procés complex. En primer lloc, no sempre podeu triar un valor específic. Per a les sol·licituds HTTP entrants externes al vostre servei, la mètrica de consulta per segon (QPS) es determina principalment pel desig dels usuaris de visitar el vostre servei i no podeu establir un SLO per a això.
D'altra banda, podeu dir que voleu que la latència mitjana de cada sol·licitud sigui inferior a 100 mil·lisegons. Establir aquest objectiu pot obligar-vos a escriure la vostra interfície amb una latència baixa o comprar equips que proporcionin aquesta latència. (100 mil·lisegons és, òbviament, un nombre arbitrari, però és millor tenir números de latència encara més baixos. Hi ha proves que suggereixen que les velocitats ràpides són millors que les velocitats lentes i que la latència en el processament de les sol·licituds dels usuaris per sobre de determinats valors obliga a la gent a mantenir-se allunyada). del vostre servei.)
De nou, això és més ambigu del que podria semblar a primera vista: no hauríeu d'excloure completament QPS del càlcul. El fet és que el QPS i la latència estan fortament relacionats entre ells: un QPS més alt sovint comporta latències més altes i els serveis solen experimentar una forta disminució del rendiment quan arriben a un determinat llindar de càrrega.
La selecció i la publicació d'un SLO estableix les expectatives dels usuaris sobre com funcionarà el servei. Aquesta estratègia pot reduir les queixes infundades contra el propietari del servei, com ara un rendiment lent. Sense un SLO explícit, els usuaris sovint creen les seves pròpies expectatives sobre el rendiment desitjat, que potser no tenen res a veure amb les opinions de les persones que dissenyen i gestionen el servei. Aquesta situació pot provocar un augment de les expectatives del servei, quan els usuaris creuen erròniament que el servei serà més accessible del que és realment, i provocar desconfiança quan els usuaris creuen que el sistema és menys fiable del que realment és.
Acords
Un acord de nivell de servei és un contracte explícit o implícit amb els vostres usuaris que inclou les conseqüències de complir (o no complir) els SLO que contenen. Les conseqüències es reconeixen més fàcilment quan són econòmiques (un descompte o una multa), però poden adoptar altres formes. Una manera fàcil de parlar de la diferència entre els SLO i els SLA és preguntar-se "què passa si no es compleixen els SLO?" Si no hi ha conseqüències clares, gairebé segur que esteu mirant un SLO.
L'SRE normalment no participa en la creació de SLA perquè els SLA estan estretament lligats a les decisions empresarials i de producte. L'SRE, però, contribueix a mitigar les conseqüències dels SLO fallits. També poden ajudar a determinar l'SLI: òbviament, hi ha d'haver una manera objectiva de mesurar l'SLO a l'acord o hi haurà desacord.
La Cerca de Google és un exemple d'un servei important que no té un SLA públic: volem que tothom faci servir la Cerca de la manera més eficient possible, però no hem signat cap contracte amb el món. Tanmateix, encara hi ha conseqüències si la cerca no està disponible: la indisponibilitat provoca una caiguda de la nostra reputació i una reducció dels ingressos publicitaris. Molts altres serveis de Google, com ara Google for Work, tenen acords de nivell de servei explícits amb els usuaris. Independentment de si un servei concret té un SLA, és important definir l'SLI i l'SLO i utilitzar-los per gestionar el servei.
Tanta teoria, ara per experimentar.
Indicadors a la pràctica
Tenint en compte que hem conclòs que és important seleccionar mètriques adequades per mesurar el nivell de servei, com sabeu ara quines mètriques són importants per a un servei o sistema?
Què t'importa a tu i als teus usuaris?
No cal que utilitzeu totes les mètriques com a SLI que podeu fer el seguiment en un sistema de monitorització; Entendre què volen els usuaris d'un sistema us ajudarà a seleccionar diverses mètriques. Escollir massa indicadors fa que sigui difícil centrar-se en indicadors importants, mentre que escollir un nombre petit pot deixar grans blocs del vostre sistema sense vigilància. Normalment fem servir diversos indicadors clau per avaluar i comprendre la salut d'un sistema.
Els serveis generalment es poden desglossar en diverses parts en termes d'SLI que són rellevants per a ells:
- Sistemes frontals personalitzats, com ara les interfícies de cerca per al servei Shakespeare del nostre exemple. Han d'estar disponibles, no tenir retards i tenir prou amplada de banda. En conseqüència, es poden fer preguntes: podem respondre a la petició? Quant de temps va trigar a respondre a la sol·licitud? Quantes peticions es poden tramitar?
- Sistemes d'emmagatzematge. Valoren la baixa latència de resposta, la disponibilitat i la durabilitat. Preguntes relacionades: quant de temps triguen a llegir o escriure dades? Podem accedir a les dades a petició? Les dades estan disponibles quan les necessitem? Vegeu el capítol 26 Integritat de les dades: el que llegiu és el que escriu per a una discussió detallada d'aquests problemes.
- Els sistemes de grans dades, com ara les canalitzacions de processament de dades, es basen en el rendiment i la latència de processament de consultes. Preguntes relacionades: Quantes dades es tracten? Quant de temps triguen les dades a viatjar des de rebre una sol·licitud fins a emetre una resposta? (Algunes parts del sistema també poden tenir retards en determinades etapes.)
Recollida d'indicadors
Molts indicadors de nivell de servei es recullen de manera més natural al costat del servidor, utilitzant un sistema de monitorització com Borgmon (vegeu més avall). ) o Prometheus, o simplement analitzant periòdicament els registres, identificant les respostes HTTP amb l'estat 500. No obstant això, alguns sistemes haurien d'estar equipats amb la recollida de mètriques del costat del client, ja que la manca de monitorització del costat del client pot provocar que es perdin una sèrie de problemes que afecten usuaris, però no afecten les mètriques del servidor. Per exemple, centrar-se en la latència de resposta de fons de la nostra aplicació de prova de cerca de Shakespeare pot provocar latència per part de l'usuari a causa de problemes de JavaScript: en aquest cas, mesurar el temps que triga el navegador a processar la pàgina és una mètrica millor.
Agregació
Per senzillesa i facilitat d'ús, sovint agrupem mesures en brut. Això s'ha de fer amb cura.
Algunes mètriques semblen senzilles, com les sol·licituds per segon, però fins i tot aquesta mesura aparentment senzilla agrega implícitament les dades al llarg del temps. La mesura es rep específicament una vegada per segon o es fa una mitjana sobre el nombre de sol·licituds per minut? Aquesta darrera opció pot amagar un nombre instantani molt més alt de sol·licituds que només duren uns segons. Penseu en un sistema que serveix 200 sol·licituds per segon amb nombres parells i 0 la resta del temps. No és el mateix una constant en forma de valor mitjà de 100 peticions per segon i el doble de la càrrega instantània. De la mateixa manera, la mitjana de latències de consultes pot semblar atractiu, però amaga un detall important: és possible que la majoria de consultes siguin ràpides, però hi haurà moltes consultes que siguin lentes.
La majoria dels indicadors es veuen millor com a distribucions que no pas com a mitjanes. Per exemple, per a la latència SLI, algunes sol·licituds es processaran ràpidament, mentre que algunes sempre trigaran més, de vegades molt més. Una mitjana simple pot amagar aquests llargs retards. La figura mostra un exemple: encara que una sol·licitud típica triga uns 50 ms a servir, el 5% de les sol·licituds són 20 vegades més lentes! El seguiment i l'alerte basat només en la latència mitjana no mostra canvis de comportament al llarg del dia, quan de fet hi ha canvis notables en el temps de processament d'algunes sol·licituds (línia superior).
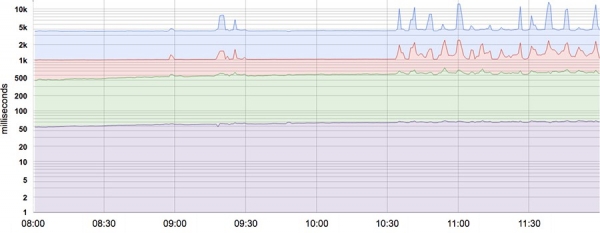
Latència del sistema de percentils 50, 85, 95 i 99. L'eix Y està en format logarítmic.
L'ús de percentils per als indicadors permet veure la forma de la distribució i les seves característiques: un percentil alt, com el 99 o el 99,9, mostra el pitjor valor, mentre que el percentil 50 (també conegut com a mediana) mostra l'estat més freqüent de la mètrica. Com més gran sigui la dispersió del temps de resposta, més les sol·licituds de llarga durada afecten l'experiència de l'usuari. L'efecte es millora amb una càrrega elevada i en presència de cues. La investigació sobre l'experiència de l'usuari ha demostrat que la gent en general prefereix un sistema més lent amb una gran variació del temps de resposta, de manera que alguns equips SRE se centren només en puntuacions percentils altes, sobre la base que si el comportament d'una mètrica al percentil 99,9 és bo, la majoria dels usuaris no experimentaran problemes. .
Nota sobre errors estadístics
En general, preferim treballar amb percentils en lloc de la mitjana (mitjana aritmètica) d'un conjunt de valors. Això ens permet considerar valors més dispersos, que sovint tenen característiques significativament diferents (i més interessants) que la mitjana. A causa de la naturalesa artificial dels sistemes informàtics, els valors mètrics sovint estan esbiaixats, de manera que cap sol·licitud pot rebre una resposta en menys de 0 ms, i un temps d'espera de 1000 ms significa que no hi ha respostes reeixides amb valors superiors a el temps d'espera. Com a resultat, no podem acceptar que la mitjana i la mediana puguin ser iguals o properes l'una a l'altra!
Sense proves prèvies, i tret que es compleixin determinades hipòtesis i aproximacions estàndard, tenim cura de no concloure que les nostres dades es distribueixen normalment. Si la distribució no és l'esperada, el procés d'automatització que soluciona el problema (per exemple, quan veu valors atípics, reinicia el servidor amb altes latències de processament de sol·licituds) pot estar fent-ho massa sovint o no amb prou freqüència (ambdós no ho són. molt bé).
Estandarditzar els indicadors
Recomanem estandarditzar les característiques generals de l'SLI perquè no hagis d'especular-ne cada vegada. Qualsevol característica que compleixi els patrons estàndard es pot excloure de l'especificació d'un SLI individual, per exemple:
- Intervals d'agregació: "mitjana superior a 1 minut"
- Àrees d'agregació: "Totes les tasques del clúster"
- Amb quina freqüència es prenen les mesures: "Cada 10 segons"
- Quines sol·licituds s'inclouen: "HTTP GET de treballs de monitoratge de caixa negra"
- Com s'obtenen les dades: "Gràcies al nostre seguiment mesurat al servidor"
- Latència d'accés a les dades: "Temps fins al darrer byte"
Per estalviar esforç, creeu un conjunt de plantilles SLI reutilitzables per a cada mètrica comuna; també faciliten que tothom entengui què significa un determinat SLI.
Objectius a la pràctica
Comenceu per pensar (o esbrinar!) què els importa als vostres usuaris, no què podeu mesurar. Sovint, el que interessa als teus usuaris és difícil o impossible de mesurar, de manera que t'acabes acostant a les seves necessitats. Tanmateix, si només comenceu amb allò que és fàcil de mesurar, acabareu amb SLO menys útils. Com a resultat, de vegades hem trobat que identificar inicialment els objectius desitjats i després treballar amb indicadors específics funciona millor que triar indicadors i després assolir els objectius.
Definiu els vostres objectius
Per a la màxima claredat, s'hauria de definir com es mesuren els SLO i les condicions en què són vàlids. Per exemple, podríem dir el següent (la segona línia és la mateixa que la primera, però utilitza els valors predeterminats de l'SLI):
- El 99% (de mitjana més d'1 minut) de les trucades Get RPC es completaran en menys de 100 ms (mesurades a tots els servidors de fons).
- El 99% de les trucades Get RPC es completaran en menys de 100 ms.
Si la forma de les corbes de rendiment és important, podeu especificar diversos SLO:
- El 90% de les trucades Obteniu RPC s'han completat en menys d'1 ms.
- El 99% de les trucades Obteniu RPC s'han completat en menys d'10 ms.
- 99.9% Aconsegueix que les trucades RPC es completin en menys de 100 ms.
Si els usuaris generen càrregues de treball heterogènies: processament massiu (per al qual el rendiment és important) i processament interactiu (per al qual la latència és important), pot ser que valgui la pena definir objectius separats per a cada classe de càrrega:
- El 95% de les sol·licituds dels clients requereixen un rendiment. Estableix el recompte de trucades RPC executades <1 s.
- El 99% dels clients es preocupa per la latència. Estableix el recompte de trucades RPC amb trànsit <1 KB i corrent <10 ms.
No és realista i no desitjable insistir que els SLO es compliran el 100% del temps: això pot reduir el ritme d'introducció de noves funcionalitats i desplegament i requerir solucions cares. En canvi, és millor permetre un pressupost d'error (el percentatge de temps d'inactivitat del sistema permès) i controlar aquest valor diàriament o setmanalment. L'alta direcció pot desitjar avaluacions mensuals o trimestrals. (El pressupost d'error és simplement un SLO per comparar-lo amb un altre SLO.)
El percentatge d'infraccions de SLO es pot comparar amb el pressupost d'errors (vegeu el capítol 3 i la secció ), amb el valor de diferència utilitzat com a entrada al procés que decideix quan desplegar les noves versions.
Selecció de valors objectiu
La selecció de valors de planificació (SLO) no és una activitat purament tècnica a causa dels interessos del producte i del negoci que s'han de reflectir en els SLI, SLO (i possiblement SLA) seleccionats. De la mateixa manera, és possible que s'hagi d'intercanviar informació sobre qüestions relacionades amb la dotació de personal, el temps de llançament al mercat, la disponibilitat d'equips i el finançament. SRE hauria de formar part d'aquesta conversa i ajudar a entendre els riscos i la viabilitat de les diferents opcions. Hem plantejat algunes preguntes que poden ajudar a garantir una discussió més productiva:
No trieu un objectiu en funció del rendiment actual.
Tot i que entendre els punts forts i els límits d'un sistema és important, l'adaptació de mètriques sense raonament us pot impedir mantenir el sistema: caldrà esforços heroics per assolir objectius que no es poden assolir sense un redisseny significatiu.
Fes-ho simple
Els càlculs SLI complexos poden amagar els canvis en el rendiment del sistema i fer que sigui més difícil trobar la causa del problema.
Evita els absoluts
Tot i que és temptador tenir un sistema que pugui gestionar una càrrega que creixi indefinidament sense augmentar la latència, aquest requisit no és realista. Un sistema que s'apropi a aquests ideals probablement requerirà molt de temps per dissenyar-lo i construir-lo, serà car d'operar i serà massa bo per a les expectatives dels usuaris que farien res menys.
Utilitzeu el mínim SLO possible
Seleccioneu un nombre suficient de SLO per garantir una bona cobertura dels atributs del sistema. Protegiu els SLO que trieu: si mai podeu guanyar un argument sobre les prioritats especificant un SLO específic, probablement no val la pena considerar-lo. Tanmateix, no tots els atributs del sistema són susceptibles de SLO: és difícil calcular el nivell de satisfacció de l'usuari mitjançant SLO.
No perseguiu la perfecció
Sempre podeu afinar les definicions i els objectius dels SLO al llarg del temps a mesura que apreneu més sobre el comportament del sistema sota càrrega. És millor començar amb un objectiu flotant que aniràs perfeccionant amb el temps que no pas triar un objectiu massa estricte que s'ha de relaxar quan trobis que és inassolible.
Els SLO poden i han de ser un motor clau per prioritzar el treball dels SRE i els desenvolupadors de productes perquè reflecteixen una preocupació per als usuaris. Un bon SLO és una eina d'aplicació útil per a un equip de desenvolupament. Però un SLO mal dissenyat pot comportar un malbaratament de treball si l'equip fa esforços heroics per aconseguir un SLO massa agressiu, o un producte deficient si l'SLO és massa baix. SLO és una palanca potent, utilitzeu-la amb prudència.
Controla les teves mesures
SLI i SLO són elements clau que s'utilitzen per gestionar sistemes:
- Monitoritzar i mesurar sistemes SLI.
- Compareu SLI amb SLO i decidiu si cal acció.
- Si cal acció, esbrineu què ha de passar per assolir l'objectiu.
- Completa aquesta acció.
Per exemple, si el pas 2 mostra que la sol·licitud s'esgota i trencarà el SLO en unes poques hores si no es fa res, el pas 3 podria implicar provar la hipòtesi que els servidors estan vinculats a la CPU i afegir més servidors distribuirà la càrrega . Sense un SLO, no sabríeu si (ni quan) prendre mesures.
Estableix SLO: llavors s'establiran les expectatives de l'usuari
La publicació d'un SLO estableix les expectatives dels usuaris pel que fa al comportament del sistema. Els usuaris (i usuaris potencials) sovint volen saber què esperar d'un servei per entendre si és adequat per al seu ús. Per exemple, les persones que vulguin utilitzar un lloc web per compartir fotos poden voler evitar utilitzar un servei que promet longevitat i baix cost a canvi d'una disponibilitat lleugerament menor, tot i que el mateix servei pot ser ideal per a un sistema de gestió de registres d'arxiu.
Per establir expectatives realistes per als usuaris, utilitzeu una o les dues tàctiques següents:
- Mantenir un marge de seguretat. Utilitzeu un SLO intern més estricte que el que s'anuncia als usuaris. Això us donarà l'oportunitat de reaccionar als problemes abans que es facin visibles externament. El buffer SLO també us permet tenir un marge de seguretat en instal·lar versions que afecten el rendiment del sistema i assegurar-vos que el sistema és fàcil de mantenir sense haver de frustrar els usuaris amb temps d'inactivitat.
- No supereu les expectatives dels usuaris. Els usuaris es basen en el que ofereixes, no en el que dius. Si el rendiment real del vostre servei és molt millor que el SLO indicat, els usuaris confiaran en el rendiment actual. Podeu evitar la sobredependència apagant intencionadament el sistema o limitant el rendiment amb càrregues lleugeres.
Entendre fins a quin punt un sistema compleix les expectatives ajuda a decidir si s'inverteix en accelerar el sistema i fer-lo més accessible i resilient. Alternativament, si un servei funciona massa bé, s'hauria de dedicar part del temps del personal a altres prioritats, com ara pagar el deute tècnic, afegir noves funcions o introduir nous productes.
Acords a la pràctica
La creació d'un SLA requereix que els equips empresarials i legals defineixin les conseqüències i les sancions per violar-lo. El paper de l'SRE és ajudar-los a entendre els possibles reptes a l'hora de complir els SLO continguts a l'SLA. La majoria de les recomanacions per crear SLO també s'apliquen als SLA. És prudent ser conservador en allò que promet als usuaris perquè com més en tinguis, més difícil serà canviar o eliminar els SLA que semblen poc raonables o difícils de complir.
Gràcies per llegir la traducció fins al final. Subscriu-te al meu canal de Telegram sobre monitoratge и .
Font: www.habr.com
