

S největší pravděpodobností se dnes nikdo neptá, proč je nutné sbírat metriky služeb. Dalším logickým krokem je nastavení upozornění na shromážděné metriky, které bude upozorňovat na případné odchylky v datech v kanálech, které vám vyhovují (mail, Slack, Telegram). V online rezervační službě hotelu všechny metriky našich služeb se nalévají do InfluxDB a zobrazují se v Grafaně a také se zde konfiguruje základní upozornění. Pro úkoly typu „potřebujete něco spočítat a porovnat s tím“ používáme Kapacitor.

Kapacitor je součástí zásobníku TICK, který dokáže zpracovávat metriky z InfluxDB. Dokáže spojit několik měření dohromady (spojit), vypočítat něco užitečného z přijatých dat, zapsat výsledek zpět do InfluxDB, poslat upozornění na Slack/Telegram/mail.
Celý zásobník je cool a detailní , ale vždy se najdou užitečné věci, které nejsou v návodech výslovně uvedeny. V tomto článku jsem se rozhodl shromáždit řadu takových užitečných, nesrozumitelných tipů (základní syntaxe TICKsciptu je popsána ) a ukázat, jak je lze aplikovat na příkladu řešení jednoho z našich problémů.
Pojďme!
float & int, chyby ve výpočtu
Naprosto standardní problém, řešený prostřednictvím kast:
var alert_float = 5.0
var alert_int = 10
data|eval(lambda: float("value") > alert_float OR float("value") < float("alert_int"))
Použití default()
Pokud není značka/pole vyplněna, dojde k chybám ve výpočtu:
|default()
.tag('status', 'empty')
.field('value', 0)
vyplnit spojení (vnitřní vs. vnější)
Ve výchozím nastavení spojení zahodí body, kde nejsou žádná data (vnitřní).
Pomocí fill('null') se provede vnější spojení, po kterém musíte provést default() a vyplnit prázdné hodnoty:
var data = res1
|join(res2)
.as('res1', 'res2)
.fill('null')
|default()
.field('res1.value', 0.0)
.field('res2.value', 100.0)
Stále zde existuje nuance. Pokud je ve výše uvedeném příkladu jedna z řad (res1 nebo res2) prázdná, výsledná řada (data) bude také prázdná. Na Github existuje několik lístků na toto téma (, , ) – čekáme na opravy a trochu trpíme.
Použití podmínek ve výpočtech (pokud jsou v lambda)
|eval(lambda: if("value" > 0, true, false)
Posledních pět minut od potrubí pro dané období
Například musíte porovnat hodnoty za posledních pět minut s předchozím týdnem. Můžete vzít dvě dávky dat ve dvou samostatných dávkách nebo extrahovat část dat z většího období:
|where(lambda: duration((unixNano(now()) - unixNano("time"))/1000, 1u) < 5m)
Alternativou pro posledních pět minut by bylo použití BarrierNode, který odřízne data před určeným časem:
|barrier()
.period(5m)
Příklady použití šablon Go ve zprávě
Šablony odpovídají formátu z balíčku Níže jsou uvedeny některé často se vyskytující hádanky.
pokud-jinde
Dáváme věci do pořádku a nespouštíme lidi znovu textem:
|alert()
...
.message(
'{{ if eq .Level "OK" }}It is ok now{{ else }}Chief, everything is broken{{end}}'
)
Dvě číslice za desetinnou čárkou ve zprávě
Zlepšení čitelnosti zprávy:
|alert()
...
.message(
'now value is {{ index .Fields "value" | printf "%0.2f" }}'
)
Rozšíření proměnných ve zprávě
Ve zprávě zobrazujeme další informace, abychom odpověděli na otázku „Proč to křičí“?
var warnAlert = 10
|alert()
...
.message(
'Today value less then '+string(warnAlert)+'%'
)
Jedinečný identifikátor výstrahy
To je nezbytné, pokud je v datech více než jedna skupina, jinak bude generováno pouze jedno upozornění:
|alert()
...
.id('{{ index .Tags "myname" }}/{{ index .Tags "myfield" }}')
Vlastní manipulátor
Velký seznam obslužných rutin obsahuje exec, který vám umožní spouštět váš skript s předanými parametry (stdin) - kreativita a nic víc!
Jedním z našich zvyků je malý skript v Pythonu pro zasílání upozornění na slack.
Nejprve jsme chtěli poslat autorizační obrázek grafana ve zprávě. Poté napište OK do vlákna k předchozímu upozornění ze stejné skupiny, nikoli jako samostatnou zprávu. O něco později – přidejte do zprávy nejčastější chybu za posledních X minut.
Samostatným tématem je komunikace s ostatními službami a veškeré akce vyvolané upozorněním (pouze v případě, že váš monitoring funguje dostatečně dobře).
Příklad popisu obslužné rutiny, kde slack_handler.py je náš vlastní skript:
topic: slack_graph
id: slack_graph.alert
match: level() != INFO AND changed() == TRUE
kind: exec
options:
prog: /sbin/slack_handler.py
args: ["-c", "CHANNELID", "--graph", "--search"]
Jak ladit?
Možnost s výstupem protokolu
|log()
.level("error")
.prefix("something")
Sledujte (cli): kapacitor -url :9092 protokoly lvl=chyba
Možnost s httpOut
Zobrazuje data v aktuálním kanálu:
|httpOut('something')
Sledujte (získejte): :9092/kapacitor/v1/tasks/název_úlohy/něco
Prováděcí schéma
- Každá úloha vrací strom provedení s užitečnými čísly ve formátu .
- Vezměte blok .
- Vložte jej do prohlížeče, .
Kde jinde seženete hrábě?
časové razítko v influxdb při zpětném zápisu
Nastavíme například upozornění na součet požadavků za hodinu (groupBy(1h)) a chceme zaznamenat upozornění, které nastalo v influxdb (abychom krásně ukázali skutečnost problému na grafu v grafaně).
influxDBOut() zapíše časovou hodnotu z výstrahy do časové značky; podle toho bude bod na grafu zapsán dříve/později, než výstraha přišla.
Když je vyžadována přesnost: tento problém vyřešíme zavoláním vlastního handleru, který zapíše data do influxdb s aktuálním časovým razítkem.
docker, sestavení a nasazení
Při spuštění může kapacitor načítat úlohy, šablony a handlery z adresáře zadaného v config v bloku [load].
Pro správné vytvoření úkolu potřebujete následující věci:
- Název souboru – rozbalený na id/název skriptu
- Typ – stream/dávka
- dbrp – klíčové slovo označující, ve které databázi + zásadě se skript spouští (dbrp „dodavatel.“ „autogen“)
Pokud některá dávková úloha neobsahuje řádek s dbrp, celá služba se odmítne spustit a poctivě o tom zapíše do logu.
V chronografu by naopak tento řádek neměl existovat, není přes rozhraní akceptován a generuje chybu.
Hackování při sestavování kontejneru: Dockerfile se ukončí s -1, pokud existují řádky s //.+dbrp, což vám umožní okamžitě pochopit důvod selhání při sestavování sestavy.
připojit jeden k mnoha
Příklad úkolu: potřebujete vzít 95. percentil provozní doby služby za týden a porovnat každou minutu z posledních 10 s touto hodnotou.
Nemůžete provést spojení one-to-many, poslední/střední/medián nad skupinou bodů změní uzel na proud, vrátí se chyba „nelze přidat podřízené neshodné okraje: dávka -> proud“.
Výsledek dávky jako proměnná ve výrazu lambda také není nahrazen.
Je zde možnost uložit potřebná čísla z první dávky do souboru přes udf a načíst tento soubor přes sideload.
Co jsme tím vyřešili?
Máme asi 100 hotelových dodavatelů, každý z nich může mít několik připojení, říkejme tomu kanál. Těchto kanálů je přibližně 300, každý z kanálů může spadnout. Ze všech zaznamenaných metrik budeme sledovat chybovost (požadavky a chyby).
Proč ne grafana?
Chybová upozornění nakonfigurovaná v Grafaně mají několik nevýhod. Některé jsou kritické, před některými můžete zavřít oči, v závislosti na situaci.
Grafana neumí počítat mezi měřením + upozorněním, ale potřebujeme sazbu (požadavky-chyby)/požadavky.
Chyby vypadají ošklivě:
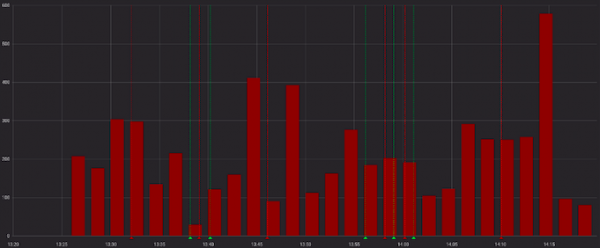
A menší zlo při pohledu na úspěšné požadavky:
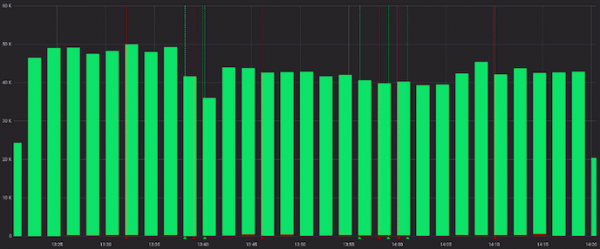
Dobře, můžeme si předem vypočítat sazbu ve službě před grafanou a v některých případech to bude fungovat. Ale ne u nás, protože... pro každý kanál je jeho vlastní poměr považován za „normální“ a výstrahy fungují podle statických hodnot (hledáme je očima, měníme je, pokud jsou výstrahy časté).
Toto jsou příklady „normálního“ pro různé kanály:


Ignorujeme předchozí bod a předpokládáme, že „normální“ obrázek je u všech dodavatelů podobný. Nyní je vše v pořádku a můžeme si vystačit s upozorněními v grafaně?
Můžeme, ale opravdu nechceme, protože si musíme vybrat jednu z možností:
a) udělat spoustu grafů pro každý kanál zvlášť (a bolestivě je doprovázet)
b) zanechte jeden graf se všemi kanály (a ztraťte se v barevných čarách a přizpůsobených upozorněních)

Jak jsi to udělal?
Opět je v dokumentaci dobrý výchozí příklad (), lze nakouknout nebo vzít jako základ v podobných problémech.
Co jsme nakonec udělali:
- připojte se ke dvěma sériím během několika hodin, seskupení podle kanálů;
- vyplňte řadu podle skupiny, pokud nebyly žádné údaje;
- porovnejte medián za posledních 10 minut s předchozími údaji;
- křičíme, pokud něco najdeme;
- zapisujeme vypočítané sazby a výstrahy, které se vyskytly v influxdb;
- poslat užitečnou zprávu slackovi.
Dle mého názoru se nám vše, co jsme chtěli na konci získat (a u custom handlerů ještě o něco více), podařilo docílit co nejkrásněji.
Můžete se podívat na github.com и výsledný skript.
Příklad výsledného kódu:
dbrp "supplier"."autogen"
var name = 'requests.rate'
var grafana_dash = 'pczpmYZWU/mydashboard'
var grafana_panel = '26'
var period = 8h
var todayPeriod = 10m
var every = 1m
var warnAlert = 15
var warnReset = 5
var reqQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."requests"'
var errQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."errors"'
var prevErr = batch
|query(errQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var prevReq = batch
|query(reqQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var rates = prevReq
|join(prevErr)
.as('req', 'err')
.tolerance(1m)
.fill('null')
// заполняем значения нулями, если их не было
|default()
.field('err.value', 0.0)
.field('req.value', 0.0)
// if в lambda: считаем рейт, только если ошибки были
|eval(lambda: if("err.value" > 0, 100.0 * (float("req.value") - float("err.value")) / float("req.value"), 100.0))
.as('rate')
// записываем посчитанные значения в инфлюкс
rates
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('rates')
// выбираем данные за последние 10 минут, считаем медиану
var todayRate = rates
|where(lambda: duration((unixNano(now()) - unixNano("time")) / 1000, 1u) < todayPeriod)
|median('rate')
.as('median')
var prevRate = rates
|median('rate')
.as('median')
var joined = todayRate
|join(prevRate)
.as('today', 'prev')
|httpOut('join')
var trigger = joined
|alert()
.warn(lambda: ("prev.median" - "today.median") > warnAlert)
.warnReset(lambda: ("prev.median" - "today.median") < warnReset)
.flapping(0.25, 0.5)
.stateChangesOnly()
// собираем в message ссылку на график дашборда графаны
.message(
'{{ .Level }}: {{ index .Tags "channel" }} err/req ratio ({{ index .Tags "supplier" }})
{{ if eq .Level "OK" }}It is ok now{{ else }}
'+string(todayPeriod)+' median is {{ index .Fields "today.median" | printf "%0.2f" }}%, by previous '+string(period)+' is {{ index .Fields "prev.median" | printf "%0.2f" }}%{{ end }}
http://grafana.ostrovok.in/d/'+string(grafana_dash)+
'?var-supplier={{ index .Tags "supplier" }}&var-channel={{ index .Tags "channel" }}&panelId='+string(grafana_panel)+'&fullscreen&tz=UTC%2B03%3A00'
)
.id('{{ index .Tags "name" }}/{{ index .Tags "channel" }}')
.levelTag('level')
.messageField('message')
.durationField('duration')
.topic('slack_graph')
// "today.median" дублируем как "value", также пишем в инфлюкс остальные филды алерта (keep)
trigger
|eval(lambda: "today.median")
.as('value')
.keep()
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('alerts')
.tag('alertName', name)
A jaký je závěr?
Kapacitor je skvělý při provádění monitorovacích výstrah se spoustou seskupení, provádění dalších výpočtů na základě již zaznamenaných metrik, provádění vlastních akcí a spouštění skriptů (udf).
Bariéra vstupu není příliš vysoká - zkuste to, pokud grafana nebo jiné nástroje plně neuspokojí vaše touhy.
Zdroj: www.habr.com
