

Tento příspěvek bude zajímavý pro ty, kteří používají knihovnu pro zpracování dat v tabulkách jazyka R data.table a mohli by je potěšit flexibilita jejího použití v různých příkladech.
Inspirováno dobrým příkladem a doufám, že jste si jeho článek již přečetli, doporučuji vám hlouběji se ponořit do optimalizace kódu a výkonu na základě datová tabulka.
Úvod: Odkud pochází soubor data.table?
Nejlepší je začít se seznamovat s knihovnou trochu dál, a to s datovými strukturami, ze kterých lze získat objekt data.table (dále jen DT).
Array
Kód
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Jednou z takových struktur je pole (?základ::pole). Stejně jako v jiných jazycích jsou i zde pole vícerozměrná. Zajímavé však je, že například dvourozměrné pole začíná dědit vlastnosti z třídy matice. (?základní::matice) a jednorozměrné pole, což je také důležité, nedědí z vektoru (?základ::vektor).
Je důležité si uvědomit, že typ dat obsažených v jakémkoli objektu by měl být kontrolován funkcí. base::typeof, který vrací interní popis typu podle Interní prvky R — protokol společného jazyka spojený s originálem C.
Další příkaz pro určení třídy objektu, base::classV případě vektorů vrací vektorový typ (má jiný název než interní, ale také umožňuje pochopit datový typ).
seznam
Z dvourozměrného pole, známého také jako matice, můžete přejít na seznam (?base::list).
Kód
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Děje se několik věcí najednou:
- Druhý rozměr matice se zhroutí, to znamená, že dostaneme zároveň seznam i vektor.
- Seznam tedy dědí z těchto tříd. Mějte na paměti, že každý prvek seznamu bude odpovídat jedné (skalární) hodnotě z buňky maticového pole.
Protože seznam je také vektor, lze na něj aplikovat některé vektorové funkce.
Datový rámec
Ze seznamu, matice nebo vektoru můžete přejít do datového rámce (?base::data.frame).
Kód
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Zajímavé na tom je, že datový rámec dědí ze seznamu! Sloupce datového rámce jsou buňky seznamu. To bude důležité později, až budeme používat funkce, které se vztahují k seznamům.
datová tabulka
Získat DT (?data.table::data.table) může být z datový rámec, seznam, vektor nebo matice. Například takto (na místě).
Kód
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Užitečné je, že stejně jako datový rámec dědí i datový typ (DT) vlastnosti seznamu.
DT a paměť
Na rozdíl od všech ostatních objektů v R base se DT předávají odkazem. Pokud je potřebujete zkopírovat do nového umístění v paměti, potřebujete funkci. data.table::copy nebo potřebujete provést výběr ze starého objektu.
Kód
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Tímto úvod končí. DT je pokračováním vývoje datových struktur v R, primárně prostřednictvím rozšíření a zrychlení operací prováděných s objekty datových rámců. Při zachování dědičnosti z jiných primitiv.
Některé příklady použití vlastností data.table
Jako seznam…
Iterování přes řádky datového rámce nebo DT není nejlepší nápad, protože kód smyčky je v jazyce R mnohem pomalejší C, ale procházení sloupců, kterých je obvykle mnohem méně, je zcela možné. Při procházení sloupců nezapomeňte, že každý sloupec je prvkem seznamu, obvykle obsahujícím vektor. A operace s vektory jsou dobře vektorizovány v základních jazykových funkcích. Můžete také použít operátory výběru, které jsou vlastní seznamům a vektorům: `[[`, `$`.
Kód
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorizace
Pokud potřebujete iterovat rozsáhlým DT, nejlepším řešením je napsat vektorizovanou funkci. Pokud to ale nefunguje, pamatujte, že smyčka uvnitř DT je stále rychlejší než cyklus v R, protože se provádí na C.
Zkusme to na větším příkladu se 100 tisíci řádky. Vybereme první písmeno ze slov obsažených ve sloupcovém vektoru. w.
aktualizováno
Kód
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
První spuštění s iterací přes řádky:
Jednotka: milisekundy
výraz min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
průměr lq střední hodnota uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Druhý běh, kde vektorizace probíhá převodem seznamu do matice a výběrem prvků řezu s indexem 1 (ten druhý je skutečná vektorizace). Oprava: vektorizace na úrovni funkcí. strsplit, který může jako vstup přijímat vektor. Ukazuje se, že postup pro převod seznamu do matice je mnohem složitější než samotná vektorizace, ale i v tomto případě je mnohem rychlejší než nevektorizovaná verze.
Jednotka: milisekundy
expr min lq střední medián uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Zrychlení podle středního bodu v 3 krát.
Třetí běh, kde bylo změněno schéma konverze matic.
Jednotka: milisekundy
expr min lq střední medián uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Zrychlení podle středního bodu v 13 krát.
S touto záležitostí je třeba experimentovat, čím více, tím lépe.
Zde je další příklad vektorizace, také s textem, ale blíže reálným podmínkám: různé délky slov a různý počet slov. Cílem je extrahovat první tři slova. Takto:
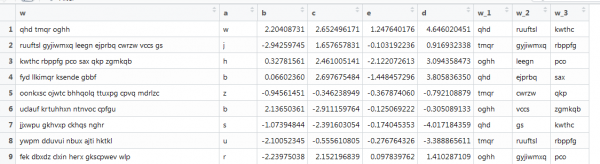
Předchozí funkce zde nefunguje, protože vektory mají různou délku a my jsme zadali velikost matice. Zkusme to přepracovat hledáním na internetu.
Kód
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Jednotka: milisekundy
expr min lq průměr medián
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fixed = T))] } 851.7623 916.071 1054.5 1035.199
UQ Max Neval
1178.738 1356.816 100
Skript běžel průměrnou rychlostí 1 sekundy. Není to špatné.
Spojeni jedním řetězem…
S objekty DT můžete pracovat pomocí řetězení. Vypadá to jako řetězení závorek vpravo, v podstatě jako cukrový povlak.
Kód
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Protéká to potrubím...
Stejné operace lze provádět pomocí pipingu; vypadá to podobně, ale je to funkčně bohatší, protože lze použít jakékoli metody, nejen DT. Odvodme koeficienty logistické regrese pro naše syntetická data s řadou DT filtrů.
Kód
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistika, strojové učení a další v rámci DT
Lambda funkce lze použít, ale někdy je lepší je vytvořit samostatně, napsat celý proces analýzy dat a je to – fungují v rámci DT. Příklad je obohacen o všechny výše zmíněné funkce a navíc o několik užitečných věcí z arzenálu DT (například přístup k samotnému DT v rámci DT pomocí odkazu, někdy vloženého mimo pořadí, ale jen pro jistotu).
Kód
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
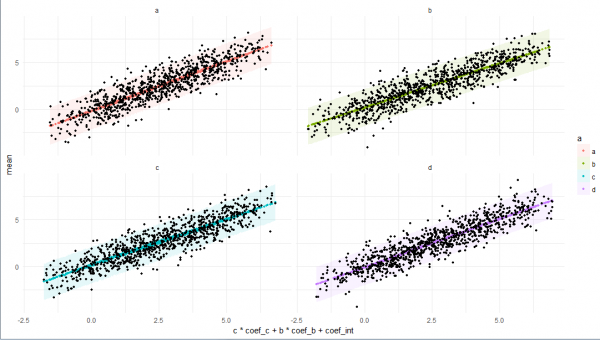
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Závěr
Doufám, že se mi podařilo vytvořit komplexní, i když rozhodně ne úplný, obraz objektu data.table, od jeho vlastností souvisejících s děděním z tříd R až po jeho vlastní funkce a prostředí elementů tidyverse. Doufám, že vám to pomůže lépe porozumět této knihovně a aplikovat ji ve vaší práci. zábava.
Děkujeme!
Celý kód
Kód
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Zdroj: www.habr.com
