

In diesem Jahr fand die wichtigste europäische Konferenz zu Kubernetes – KubeCon + CloudNativeCon Europe 2020 – virtuell statt. Diese Formatänderung hat jedoch unseren lang erwarteten Vortrag "Go? Bash! Meet the Shell-operator" über unser Open Source-Projekt nicht beeinträchtigt. .
In diesem Artikel, der auf dem Vortrag basiert, wird ein Ansatz zur Vereinfachung des Prozesses der Erstellung von Operatoren für Kubernetes vorgestellt und demonstriert, wie man mit minimalem Aufwand mithilfe des Shell-Operators seinen eigenen erstellen kann.

Wir präsentieren (~23 Minuten auf Englisch, deutlich informativer als der Artikel) und die Hauptpunkte in schriftlicher Form. Los geht's!
Bei "Flante" optimieren und automatisieren wir ständig alles. Heute geht es um ein weiteres spannendes Konzept. Lernen Sie kennen: cloud-natives Shell-Scripting!
Lassen Sie uns jedoch mit dem Kontext beginnen, in dem dies alles stattfindet – Kubernetes.
Kubernetes API und Controller
Die API in Kubernetes kann man sich wie einen Dateiserver vorstellen, der Verzeichnisse für jeden Objekttyp hat. Die Objekte (Ressourcen) auf diesem Server sind in YAML-Dateien dargestellt. Außerdem verfügt der Server über eine grundlegende API, die drei Dinge ermöglicht:
- abfragen eine Ressource nach ihrem Typ und Namen;
- ändern Die Ressource (dabei speichert der Server nur die „richtigen“ Objekte – alle fehlerhaft erstellten oder für andere Verzeichnisse bestimmten Objekte werden verworfen);
- seine Entwicklung. Besonders interessant fanden wir das Thema der Interaktion zwischen Kafka und auf die Ressource (in diesem Fall erhält der Benutzer sofort die aktuelle/aktualisierte Version davon).
So fungiert Kubernetes als eine Art Dateiserver (für YAML-Manifeste) mit drei grundlegenden Methoden (ja, es gibt tatsächlich noch andere, aber die lassen wir vorerst außen vor).

Das Problem ist, dass der Server lediglich Informationen speichern kann. Um diese zum Laufen zu bringen, ist erforderlich der Controller – das zweitwichtigste und grundlegendste Konzept in der Welt von Kubernetes.
Es gibt zwei Haupttypen von Controllern. Der erste entnimmt Informationen aus Kubernetes, verarbeitet diese gemäß der eingebetteten Logik und gibt sie an K8s zurück. Der zweite erhält Informationen aus Kubernetes, ändert jedoch, im Gegensatz zum ersten Typ, den Status bestimmter externer Ressourcen.
Lassen Sie uns den Prozess der Erstellung eines Deployments in Kubernetes näher betrachten:
- Der Deployment Controller (Teil von
kube-controller-manager) erhält Informationen über das Deployment und erstellt ein ReplicaSet. - Das ReplicaSet erstellt basierend auf diesen Informationen zwei Replikate (zwei Pods), diese Pods sind jedoch noch nicht geplant.
- Der Scheduler plant Pods und fügt ihren YAML-Dateien Informationen über die Knoten hinzu.
- Kubelets nehmen Änderungen an externen Ressourcen vor (zum Beispiel Docker).
Dann wird diese gesamte Abfolge in umgekehrter Reihenfolge wiederholt: Der Kubelet überprüft die Container, berechnet den Pod-Status und sendet diesen zurück. Der ReplicaSet-Controller erhält den Status und aktualisiert den Zustand des Replikatsatzes. Dasselbe geschieht mit dem Deployment-Controller, und schließlich erhält der Benutzer den aktualisierten (aktuellen) Status.
Shell-Operator
Es zeigt sich, dass Kubernetes auf der Zusammenarbeit verschiedener Controller basiert (Kubernetes-Operatoren sind ebenfalls Controller). Die Frage ist, wie man einen eigenen Operator mit minimalem Aufwand erstellen kann. Hier kommt unser entwickeltes Tool ins Spiel. Es ermöglicht Systemadministratoren, eigene Operatoren mit vertrauten Methoden zu erstellen.
Ein einfaches Beispiel: Kopieren von Secrets.
Lassen Sie uns ein einfaches Beispiel betrachten.
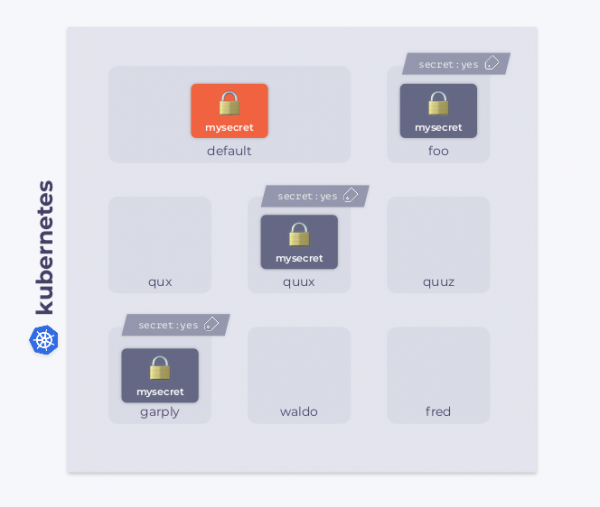
Angenommen, wir haben einen Kubernetes-Cluster. Er enthält einen Namensraum default mit einem bestimmten Secret mysecret.. Darüber hinaus gibt es im Cluster weitere Namespaces. Einige von ihnen haben ein bestimmtes Label. Unser Ziel ist es, das Secret in die Namespaces mit diesem Label zu kopieren.
Die Aufgabe wird dadurch erschwert, dass im Cluster neue Namespaces entstehen können, und einige von ihnen möglicherweise dieses Label haben. Zudem sollte das Secret gelöscht werden, wenn das Label entfernt wird. Darüber hinaus kann sich das Secret selbst ändern: In diesem Fall muss das neue Secret in alle Namespaces mit Labels kopiert werden. Sollte das Secret versehentlich in einem Namespace gelöscht werden, muss unser Operator es sofort wiederherstellen.
Jetzt, da die Aufgabe formuliert ist, ist es an der Zeit, mit der Umsetzung durch den shell-operator zu beginnen. Zunächst sollten wir jedoch einige Worte über den shell-operator verlieren.
Funktionsweise des shell-operators
Wie andere Workloads in Kubernetes funktioniert der shell-operator in seinem eigenen Pod. In diesem Pod im Verzeichnis /hooks werden die ausführbaren Dateien gespeichert. Das können Skripte in Bash, Python, Ruby usw. sein. Diese ausführbaren Dateien nennen wir Hooks (hooks).
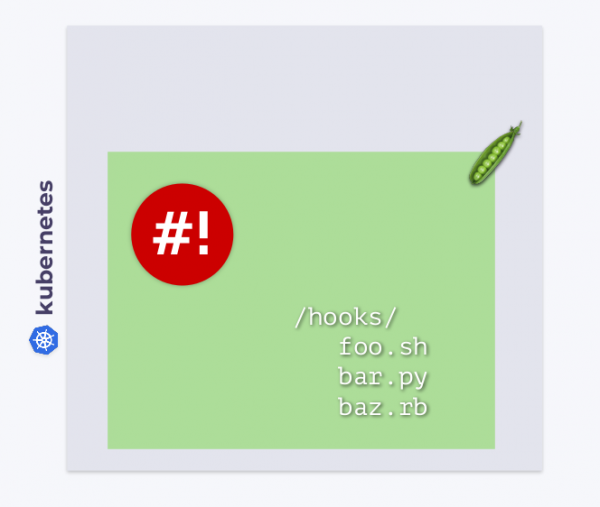
Der Shell-Operator abonniert Kubernetes-Ereignisse und führt diese Hooks als Reaktion auf die für uns relevanten Ereignisse aus.
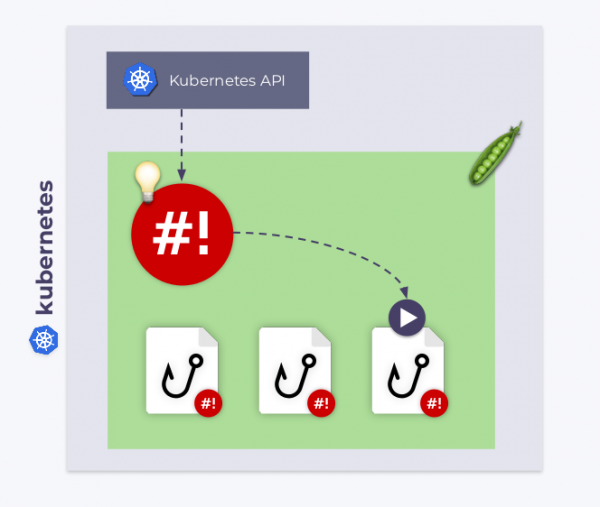
Wie erfährt der shell-operator, welcher Hook zu welchem Zeitpunkt ausgelöst werden soll? Jeder Hook hat zwei Phasen. Zu Beginn startet der shell-operator alle Hooks mit einem Argument --config — dies ist die Konfigurationsphase. Danach werden die Hooks normal ausgelöst — als Reaktion auf die Ereignisse, mit denen sie verknüpft sind. Im letzteren Fall erhält der Hook den Bindungskontext (binding context) — die Daten im JSON-Format, über die wir weiter unten sprechen werden.
Wir erstellen einen Operator in Bash
Nun sind wir bereit für die Implementierung. Dazu müssen wir zwei Funktionen schreiben (übrigens empfehlen wir die Bibliothek , die das Schreiben von Hooks in Bash erheblich vereinfacht):
- Die erste Funktion ist für die Konfigurationsphase notwendig — sie gibt den Bindungskontext aus;
- die zweite enthält die Hauptlogik des Hooks.
#!/bin/bash
source /shell_lib.sh
function __config__() {
cat << EOF
configVersion: v1
# BINDING CONFIGURATION
EOF
}
function __main__() {
# THE LOGIC
}
hook::run "$@"
Der nächste Schritt ist, festzulegen, welche Objekte wir benötigen. In unserem Fall müssen wir Folgendes überwachen:
- den Secret-Quell für Veränderungen;
- alle Namespaces im Cluster, um zu wissen, an welche der Label angehängt sind;
- Ziel-Secrets, um sicherzustellen, dass alle mit dem Secret-Quell synchronisiert sind.
Wir abonnieren den Secret-Quell
Die Binding-Konfiguration ist ziemlich einfach. Wir geben an, dass uns ein Secret mit dem Namen interessiert: mysecret. im Namespace default:
function __config__() {
cat << EOF
configVersion: v1
kubernetes:
- name: src_secret
apiVersion: v1
kind: Secret
nameSelector:
matchNames:
- mysecret
namespace:
nameSelector:
matchNames: ["default"]
group: main
EOF
Infolgedessen wird der Hook bei Änderungen des Quell-Secrets (src_secret) ausgelöst und erhält den folgenden Binding-Kontext:
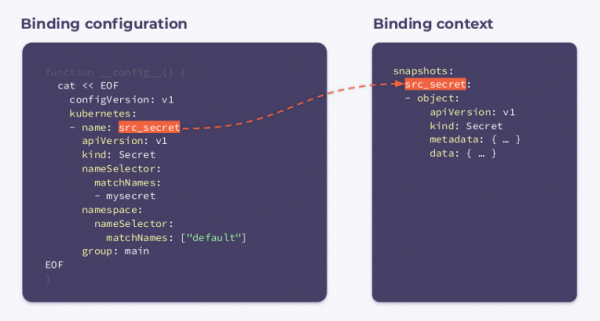
Wie Sie sehen, enthält er den Namen sowie das gesamte Objekt.
Wir beobachten die Namensräume.
Jetzt müssen wir uns für die Namensräume anmelden. Dazu geben wir die folgende Binding-Konfiguration an:
- name: namespaces
group: main
apiVersion: v1
kind: Namespace
jqFilter: |
{
namespace: .metadata.name,
hasLabel: (
.metadata.labels // {} |
contains({"secret": "yes"})
)
}
group: main
keepFullObjectsInMemory: false
Wie Sie sehen, gibt es in der Konfiguration ein neues Feld mit dem Namen jqFilter. Wie der Name schon andeutet, jqFilter filtert alle überflüssigen Informationen heraus und erstellt ein neues JSON-Objekt mit den für uns interessanten Feldern. Ein Hook mit einer solchen Konfiguration erhält den folgenden Binding-Kontext:
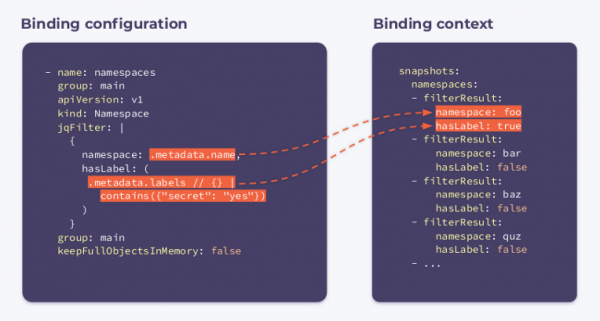
Es enthält ein Array filterResults für jeden Namensraum im Cluster. Die boolesche Variable hasLabel zeigt, ob das Label an diesem Namespace angeheftet ist. Selektor keepFullObjectsInMemory: false besagt, dass es nicht notwendig ist, vollständige Objekte im Speicher zu halten.
Verfolgen von Zielgeheimnissen
Wir abonnieren alle Geheimnisse, die mit einer Annotation versehen sind managed-secret: "yes" (das sind unsere Ziel- dst_secrets):
- name: dst_secrets
apiVersion: v1
kind: Secret
labelSelector:
matchLabels:
managed-secret: "yes"
jqFilter: |
{
"namespace":
.metadata.namespace,
"resourceVersion":
.metadata.annotations.resourceVersion
}
group: main
keepFullObjectsInMemory: false
In diesem Fall jqFilter filtert alle Informationen außer Namespace und Parameter heraus resourceVersion. Der letzte Parameter wurde bei der Erstellung des Geheimnisses als Annotation übergeben: er ermöglicht den Vergleich der Versionen von Geheimnissen und deren Aktualisierung.
Ein solcher Hook wird beim Ausführen drei oben beschriebene Bindungskontexte erhalten. Diese können als eine Art Snapshot (snapshot) des Clusters betrachtet werden.

Auf Grundlage all dieser Informationen kann ein grundlegender Algorithmus entwickelt werden. Er durchläuft alle Namespaces und:
- wenn
hasLabelBedeutungtruefür den aktuellen Namespace:- vergleicht das globale Geheimnis mit dem lokalen:
- wenn sie gleich sind — tut nichts;
- wenn sie unterschiedlich sind — führt es aus
kubectl ersetzenodercreate;
- vergleicht das globale Geheimnis mit dem lokalen:
- wenn
hasLabelBedeutungfalsefür den aktuellen Namespace:- stellt sicher, dass das Secret in diesem Namensraum nicht vorhanden ist:
- falls das lokale Secret vorhanden ist — entfernt es mit Hilfe von
kubectl delete; - falls das lokale Secret nicht gefunden wird — unternimmt es nichts.
- falls das lokale Secret vorhanden ist — entfernt es mit Hilfe von
- stellt sicher, dass das Secret in diesem Namensraum nicht vorhanden ist:

können Sie in unserem .
So konnten wir einen einfachen Kubernetes-Controller erstellen, indem wir 35 Zeilen YAML-Konfigurationen und etwa die gleiche Menge Code in Bash verwendeten! Die Aufgabe des Shell-Operators besteht darin, sie miteinander zu verbinden.
Das Kopieren von Secrets ist jedoch nicht der einzige Anwendungsbereich des Tools. Hier sind noch einige Beispiele, die zeigen, wozu es fähig ist.
Beispiel 1: Änderungen an ConfigMap vornehmen
Lassen Sie uns ein Deployment betrachten, das aus drei Pods besteht. Die Pods verwenden ConfigMap zur Speicherung bestimmter Konfigurationen. Während die Pods gestartet werden, befand sich die ConfigMap in einem bestimmten Zustand (nennen wir ihn v.1). Folglich verwenden alle Pods genau diese Version der ConfigMap.
Jetzt nehmen wir an, dass sich die ConfigMap geändert hat (v.2). Die Pods werden jedoch weiterhin die alte Version der ConfigMap (v.1) verwenden:
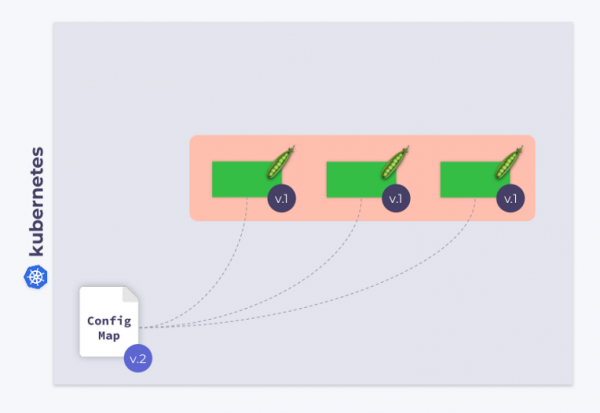
Wie kann man sicherstellen, dass sie auf die neue ConfigMap (v.2) umschalten? Die Antwort ist einfach: Verwenden Sie ein Template. Lassen Sie uns eine Annotation mit einer Prüfziffer im Abschnitt template der Deployment-Konfiguration hinzufügen:

Dadurch wird in allen Pods diese Prüfziffer festgelegt, und sie wird mit der des Deployments übereinstimmen. Jetzt müssen wir nur noch die Annotation bei Änderungen der ConfigMap aktualisieren. Der Shell-Operator ist in diesem Fall besonders hilfreich. Alles, was erforderlich ist, ist, einen Hook zu programmieren, der sich auf die ConfigMap registriert und die Prüfziffer aktualisiert..
Wenn der Benutzer Änderungen an der ConfigMap vornimmt, wird der Shell-Operator diese erkennen und die Prüfziffer neu berechnen. Dann wird die Magie von Kubernetes ins Spiel kommen: Der Orchestrator tötet den Pod, erstellt einen neuen, wartet, bis dieser bereit ist, Bereit, und wechselt dann zum nächsten. Infolgedessen wird das Deployment synchronisiert und auf die neue Version der ConfigMap umgestellt.
Beispiel 2: Arbeiten mit benutzerdefinierten Ressourcendefinitionen.
Wie bekannt, erlaubt Kubernetes das Erstellen von benutzerdefinierten Objekttypen (kinds). Zum Beispiel kann man einen Typ erstellen, MysqlDatabase. Nehmen wir an, dieser Typ hat zwei Metadata-Parameter: name und namespace.
apiVersion: example.com/v1alpha1
kind: MysqlDatabase
metadata:
name: foo
namespace: bar
Wir haben ein Kubernetes-Cluster mit verschiedenen Namespaces, in denen wir MySQL-Datenbanken erstellen können. In diesem Fall kann der Shell-Operator verwendet werden, um Ressourcen zu überwachen MysqlDatabase, deren Verbindungen zum MySQL-Server und die Synchronisierung des gewünschten und beobachteten Zustands des Clusters.
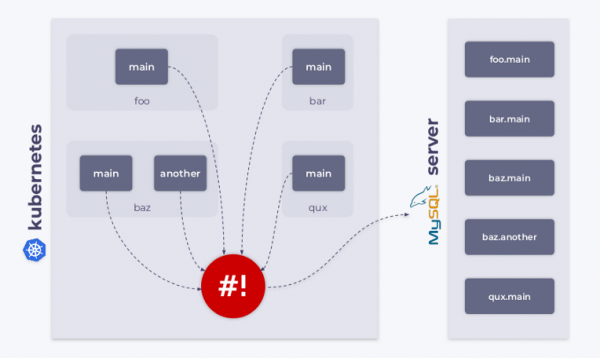
Beispiel 3: Überwachung des Cluster-Netzwerks
Wie bekannt ist, ist die Verwendung von Ping die einfachste Methode zur Netzwerküberwachung. In diesem Beispiel zeigen wir, wie man eine solche Überwachung mit dem Shell-Operator implementieren kann.
Zunächst müssen wir uns bei den Knoten anmelden. Der Shell-Operator benötigt den Namen und die IP-Adresse jedes Knotens. Mit diesen Informationen kann er diese Knoten pingen.
configVersion: v1
kubernetes:
- name: nodes
apiVersion: v1
kind: Node
jqFilter: |
{
name: .metadata.name,
ip: (
.status.addresses[] |
select(.type == "InternalIP") |
.address
)
}
group: main
keepFullObjectsInMemory: false
executeHookOnEvent: []
schedule:
- name: every_minute
group: main
crontab: "* * * * *"
Parameter executeHookOnEvent: [] verhindert die Ausführung des Hooks als Reaktion auf irgendwelche Ereignisse (d.h. als Reaktion auf Änderungen, Hinzufügen, Entfernen von Knoten). Allerdings wird er (und die Liste der Knoten aktualisieren) nach Zeitplan — jede Minute, wie im Feld schedule.
Jetzt stellt sich die Frage, wie wir genau von Problemen wie Paketverlust erfahren? Lassen Sie uns den Code ansehen:
function __main__() {
for i in $(seq 0 "$(context::jq -r '(.snapshots.nodes | length) - 1')"); do
node_name="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.name')"
node_ip="$(context::jq -r '.snapshots.nodes['"$i"'].filterResult.ip')"
packets_lost=0
if ! ping -c 1 "$node_ip" -t 1 ; then
packets_lost=1
fi
cat >> "$METRICS_PATH" <<END
{
"name": "node_packets_lost",
"add": $packets_lost,
"labels": {
"node": "$node_name"
}
}
END
done
}
Wir durchlaufen die Liste der Knoten, erhalten ihre Namen und IP-Adressen, pingen sie und senden die Ergebnisse an Prometheus. Der Shell-Operator kann Metriken an Prometheus exportieren, indem sie in einer Datei gespeichert werden, die gemäß dem in der Umgebungsvariable angegebenen Pfad gespeichert wird $METRICS_PATH.
kann man einen Operator für einfaches Netzwerkmonitoring im Cluster erstellen.
Das Warteschlangen-System
Dieser Artikel wäre unvollständig, ohne einen weiteren wichtigen Mechanismus zu beschreiben, der im Shell-Operator integriert ist. Stellen Sie sich vor, er führt einen bestimmten Hook als Antwort auf ein Ereignis im Cluster aus.
- Was passiert, wenn zur gleichen Zeit im Cluster ein weiteres Ereignis eintritt?
- Wird der Shell-Operator eine weitere Instanz des Hooks starten?
- Und was, wenn im Cluster gleichzeitig, sagen wir, fünf Ereignisse eintreten?
- Wird der Shell-Operator sie parallel verarbeiten?
- Wie sieht es mit den benötigten Ressourcen wie RAM und CPU aus?
Glücklicherweise verfügt der Shell-Operator über einen integrierten Warteschlangenmechanismus. Alle Ereignisse werden in eine Warteschlange gestellt und nacheinander verarbeitet.
Lassen Sie uns dies anhand von Beispielen veranschaulichen. Angenommen, wir haben zwei Hooks. Das erste Ereignis wird an den ersten Hook weitergeleitet. Nachdem dessen Verarbeitung abgeschlossen ist, rückt die Warteschlange nach. Die nächsten drei Ereignisse werden an den zweiten Hook weitergeleitet – sie werden als 'Batch' aus der Warteschlange entnommen und ihm zugeführt. Das bedeutet, dass der Hook ein Array von Ereignissen erhält oder, genauer gesagt, ein Array von Bindungskontexten.
Diese Ereignisse können auch in ein großeszusammengeführt werden. Dafür ist der Parameter group in der Bindungskonfiguration verantwortlich.

Es können beliebig viele Warteschlangen/Hooks und deren verschiedene Kombinationen erstellt werden. Beispielsweise kann eine Warteschlange mit zwei Hooks arbeiten oder umgekehrt.
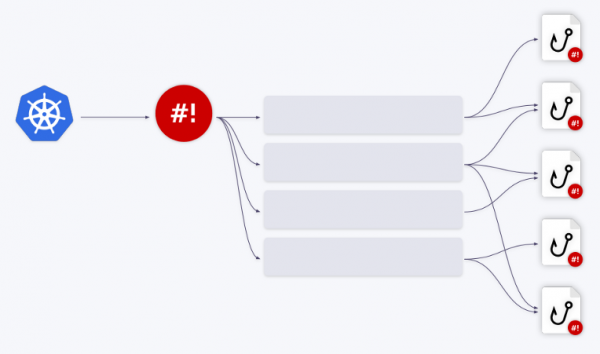
Alles, was Sie tun müssen, ist das Feld queue in der Bindungskonfiguration entsprechend einzustellen. Wenn kein Warteschname angegeben ist, wird der Hook in der Standardwarteschlange gestartet (default). Ein solches Warteschlangen-System löst alle Herausforderungen im Ressourcenmanagement bei der Nutzung von Hooks vollständig.
Fazit
Wir haben erklärt, was ein Shell-Operator ist, gezeigt, wie man damit schnell und mühelos Kubernetes-Operatoren erstellen kann, und einige Anwendungsbeispiele gebracht.
Detaillierte Informationen zum Shell-Operator sowie eine kurze Anleitung zu seiner Nutzung finden Sie im entsprechenden . Zögern Sie nicht, uns bei Fragen zu kontaktieren: Diese können wir in einer speziellen (auf Russisch) oder in (auf Englisch) besprechen.
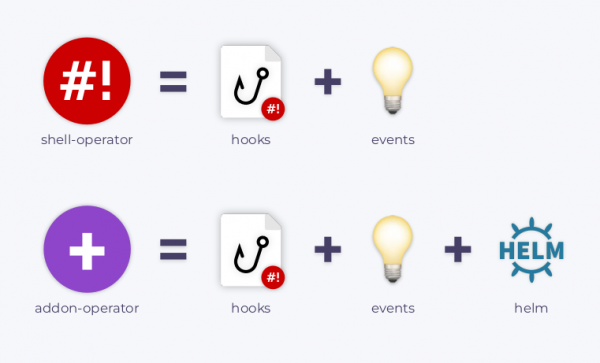
Wenn Ihnen unsere Arbeit gefällt, freuen wir uns immer über neue Issues/PRs und Sterne auf GitHub, wo Sie übrigens auch andere finden können. Unter ihnen sticht besonders hervor , das als großer Bruder des Shell-Operators fungiert.Dieses Tool nutzt Helm-Charts zur Installation von Erweiterungen, kann Updates bereitstellen und verschiedene Parameter/Werte der Charts überwachen, den Installationsprozess der Charts steuern und diese als Reaktion auf Ereignisse im Cluster modifizieren.
Videos und Folien
Video von der Präsentation (~23 Minuten):

Präsentation des Vortrags:
P.S.
Lesen Sie auch in unserem Blog:
- «»;
- «»;
- «»;
- «.
Quelle: habr.com
