

Dieser Hinweis wird für diejenigen von Interesse sein, die die tabellarische Datenverarbeitungsbibliothek für R – data.table – verwenden und sich möglicherweise über die Flexibilität ihrer Verwendung in verschiedenen Beispielen freuen.
Inspiriert durch ein gutes Beispiel , und in der Hoffnung, dass Sie seinen Artikel bereits gelesen haben, schlage ich vor, tiefer in die Codeoptimierung und Leistung basierend darauf einzusteigen Datentabelle.
Einführung: Woher kommt data.table?
Es ist am besten, sich mit der Bibliothek aus der Ferne vertraut zu machen, nämlich mit den Datenstrukturen, aus denen das data.table-Objekt (im Folgenden als DT bezeichnet) abgerufen werden kann.
Array
Code
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Eine solche Struktur ist ein Array (?base::array). Wie in anderen Sprachen sind Arrays hier mehrdimensional. Das Interessante ist jedoch, dass beispielsweise ein zweidimensionales Array beginnt, Eigenschaften von der Matrixklasse zu erben (?base::matrix), und ein eindimensionales Array, was ebenfalls wichtig ist, erbt nicht von einem Vektor (?base::vector).
Es versteht sich, dass die Art der in jedem Objekt enthaltenen Daten mithilfe der Funktion überprüft werden sollte base::typeof, das die interne Typbeschreibung gemäß zurückgibt R-Interna - das allgemeine Protokoll der Sprache, die dem Original zugeordnet ist C.
Ein weiterer Befehl zum Bestimmen der Klasse eines Objekts ist base::class, im Fall von Vektoren, gibt den Vektortyp zurück (er unterscheidet sich im Namen vom internen, ermöglicht aber auch das Verständnis des Datentyps).
Liste
Von einem zweidimensionalen Array, auch Matrix genannt, können Sie zur Liste gehen (?base::list).
Code
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Es passieren mehrere Dinge gleichzeitig:
- Die zweite Dimension der Matrix kollabiert, das heißt, wir erhalten gleichzeitig eine Liste und einen Vektor.
- Die Liste erbt somit von diesen Klassen. Es ist zu beachten, dass ein Listenelement einem (skalaren) Wert aus einer Zelle der Array-Matrix entspricht.
Da eine Liste auch ein Vektor ist, können einige Vektorfunktionen auf sie angewendet werden.
Datenrahmen
Sie können von einer Liste, einer Matrix oder einem Vektor zu einem Datenrahmen wechseln (?base::data.frame).
Code
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Das Interessante daran: Der Datenrahmen erbt von der Liste! Datenrahmenspalten sind Listenzellen. Dies wird später wichtig sein, wenn wir Funktionen verwenden, die auf Listen angewendet werden.
Datentabelle
Holen Sie sich DT (?data.table::data.table) kann von sein Datenrahmen, Liste, Vektor oder Matrix. Zum Beispiel so (an Ort und Stelle).
Code
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Es ist nützlich, dass ein DT wie ein Datenrahmen die Eigenschaften einer Liste erbt.
DT und Gedächtnis
Im Gegensatz zu allen anderen Objekten in R-Base werden DTs als Referenz übergeben. Wenn Sie eine Kopie in einen neuen Speicherbereich erstellen müssen, benötigen Sie eine Funktion data.table::copy oder Sie müssen eine Auswahl aus dem alten Objekt treffen.
Code
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Damit ist die Einleitung abgeschlossen. DT ist eine Fortsetzung der Entwicklung von Datenstrukturen in R, die hauptsächlich auf die Erweiterung und Beschleunigung von Operationen zurückzuführen ist, die an Objekten der Datenrahmenklasse ausgeführt werden. Gleichzeitig bleibt die Vererbung von anderen Primitiven erhalten.
Einige Beispiele für die Verwendung von data.table-Eigenschaften
Wie eine Liste...
Das Durchlaufen der Zeilen eines Datenrahmens oder DT ist keine gute Idee, da der Schleifencode in der Sprache liegt R viel langsamer C, aber es ist durchaus möglich, die Spalten zu durchlaufen, die normalerweise viel kleiner sind. Denken Sie beim Durchgehen der Spalten daran, dass jede Spalte ein Element einer Liste ist und normalerweise einen Vektor enthält. Und Operationen auf Vektoren sind in den Grundfunktionen der Sprache gut vektorisiert. Sie können auch Auswahloperatoren verwenden, die für Listen und Vektoren üblich sind: `[[`, `$`.
Code
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorisierung
Wenn die Linien eines großen DT durchgegangen werden müssen, besteht die beste Lösung darin, eine Funktion mit Vektorisierung zu schreiben. Wenn dies jedoch nicht funktioniert, sollten Sie sich an den Zyklus erinnern innen DT ist immer noch schneller als der Zyklus R, da es am durchgeführt wird C.
Versuchen wir es an einem größeren Beispiel mit 100 Zeilen. Wir extrahieren den ersten Buchstaben aus den in der Vektorspalte enthaltenen Wörtern w.
Aktualisiert
Code
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Erster Durchlauf über Zeilen:
Einheit: Millisekunden
Ausdruck min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", Fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq Mittelwert Median uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Der zweite Lauf, bei dem die Vektorisierung erfolgt, indem die Liste in eine Matrix umgewandelt wird und Elemente auf dem Slice mit Index 1 übernommen werden (letzterer ist die Vektorisierung selbst). Korrektur: Vektorisierung auf Funktionsebene strsplit, das einen Vektor als Eingabe akzeptieren kann. Es stellt sich heraus, dass das Verfahren zum Umwandeln einer Liste in eine Matrix viel schwieriger ist als die Vektorisierung selbst, in diesem Fall jedoch viel schneller als die nicht vektorisierte Version.
Einheit: Millisekunden
expr min lq Mittelwert Median uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Beschleunigung durch Median in 3 mal.
Der dritte Lauf, bei dem das Transformationsschema in die Matrix geändert wurde.
Einheit: Millisekunden
expr min lq Mittelwert Median uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Beschleunigung durch Median in 13 mal.
Sie müssen mit dieser Angelegenheit experimentieren, je mehr, desto besser wird es sein.
Ein weiteres Beispiel mit Vektorisierung, bei der es auch Text gibt, der aber den realen Bedingungen nahekommt: unterschiedliche Längen von Wörtern, unterschiedliche Anzahl von Wörtern. Sie müssen die ersten drei Wörter verstehen. So was:
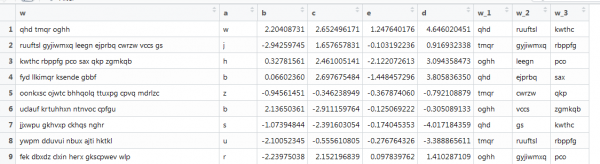
Hier funktioniert die vorherige Funktion nicht, da die Vektoren unterschiedlich lang sind und wir die Matrixgröße festlegen. Lassen Sie uns dies wiederholen, indem wir im Internet herumstöbern.
Code
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Einheit: Millisekunden
Ausdruck min lq Mittelwert Median
{ dt[, `:=`((paste0(“w_”, 1:3)), strsplit(w, split = " ", fixiert = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Das Skript lief mit einer Durchschnittsgeschwindigkeit von 1 Sekunde. Nicht schlecht.
Verbunden durch eine Kette...
Mithilfe der Verkettung können Sie mit DT-Objekten arbeiten. Es sieht so aus, als würde man rechts eine Klammersyntax anhängen, im Wesentlichen Zucker.
Code
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Durch die Rohre fließen...
Die gleichen Vorgänge können über Piping ausgeführt werden. Es sieht ähnlich aus, ist jedoch funktionsreicher, da Sie beliebige Methoden verwenden können, nicht nur DT. Lassen Sie uns logistische Regressionskoeffizienten für unsere synthetischen Daten mit einer Reihe von Filtern für DT ableiten.
Code
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistiken, maschinelles Lernen und mehr innerhalb von DT
Sie können Lambda-Funktionen verwenden, aber manchmal ist es besser, sie separat zu erstellen, die gesamte Datenanalyse-Pipeline zu schreiben und fortzufahren – sie funktionieren innerhalb des DT. Das Beispiel ist mit allen oben genannten Funktionen sowie einigen nützlichen Dingen aus dem DT-Arsenal angereichert (z. B. der Zugriff auf den DT selbst innerhalb des DT über einen Link, der manchmal nicht sequentiell, sondern so eingefügt wird, dass er so ist).
Code
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
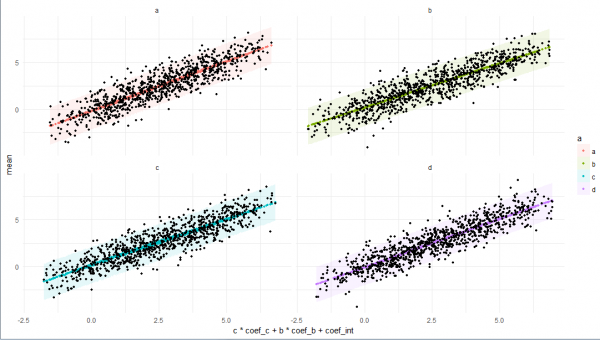
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Fazit
Ich hoffe, dass es mir gelungen ist, ein vollständiges, aber natürlich nicht vollständiges Bild eines solchen Objekts wie data.table zu erstellen, angefangen bei seinen Eigenschaften, die mit der Vererbung von R-Klassen verbunden sind, bis hin zu seinen eigenen Funktionen und seiner Umgebung aus Tidyverse-Elementen . Ich hoffe, dass dies Ihnen dabei hilft, diese Bibliothek besser kennenzulernen und für Ihre Arbeit zu nutzen Unterhaltung.
Vielen Dank!
Vollständiger Code
Code
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Source: habr.com
