

Le principe d’incertitude de Heisenberg stipule qu’on ne peut pas mesurer simultanément la position d’un objet et sa vitesse. Si un objet bouge, alors il n’a aucun emplacement. Et s’il y a un emplacement, c’est qu’il n’a pas de vitesse.

Quant aux microservices sur la plateforme Red Hat OpenShift (et exécutant Kubernetes), grâce au logiciel open source approprié, ils peuvent rendre compte simultanément de leurs performances et de leur état de santé. Bien entendu, cela ne réfute pas le vieux Heisenberg, mais cela élimine l'incertitude liée au travail avec des applications cloud. Istio facilite le suivi et la surveillance de ces applications pour tout garder sous contrôle.
Décider de la terminologie
sous tracé (Traçage) nous comprenons la journalisation de l'activité du système. Cela semble assez général, mais en fait, l'une des règles de base ici est de vider les données de trace dans le stockage approprié sans se soucier de leur formatage. Et tout le travail de recherche et d’analyse des données incombe au consommateur. Istio utilise le système de traçage Jaeger, qui implémente le modèle de données OpenTracing.
Sur les sentiers (Traces, et le mot « traces » est utilisé ici dans le sens de « traces », comme par exemple dans l'examen balistique) nous appellerons des données qui décrivent complètement le passage d'une demande ou d'une unité de travail, comme on dit, «de et vers». Par exemple, tout ce qui se passe depuis le moment où un utilisateur clique sur un bouton d'une page Web jusqu'au retour des données, y compris tous les microservices impliqués. On peut dire qu'une trace décrit (ou modélise) complètement l'aller-retour d'une requête. Dans l'interface Jaeger, les traces sont décomposées en composants le long de l'axe du temps, de la même manière qu'une chaîne peut être décomposée en maillons individuels. Seulement, au lieu de liens, l'itinéraire est constitué de ce qu'on appelle des travées.
Envergure est l'intervalle entre le début d'une unité de travail et son achèvement. Poursuivant l'analogie, nous pouvons dire que chaque travée représente un maillon distinct de la chaîne. Un Span peut (ou non) avoir un ou plusieurs spans enfants. Par conséquent, le span le plus haut (span racine) aura la même durée totale que la trace à laquelle il appartient.
Surveillance - c'est en fait l'observation même de votre système - avec vos yeux, via l'interface utilisateur ou les outils d'automatisation. La surveillance est basée sur les données de trace. Dans Istio, la surveillance est implémentée à l'aide de Prometheus et dispose d'une interface utilisateur appropriée. Prometheus prend en charge la surveillance automatisée à l'aide d'alertes et de gestionnaires d'alertes.
Nous laissons des traces
Pour que le traçage soit possible, l'application doit créer une collection d'étendues. Ensuite, ils doivent être exportés vers Jaeger, afin que celui-ci crée à son tour une représentation visuelle de la trace. Entre autres choses, ces plages marquent le nom de l’opération, ainsi que ses horodatages de début et de fin. La transmission des spans s'effectue en transmettant les en-têtes de requête HTTP spécifiques à Jaeger des requêtes entrantes vers les requêtes sortantes. Selon le langage de programmation utilisé, cela peut nécessiter des modifications mineures du code source de l'application. Vous trouverez ci-dessous un exemple de code en Java (utilisant le framework Spring Boot) qui ajoute des en-têtes B3 (style Zipkin) à votre requête dans la classe de configuration Spring :

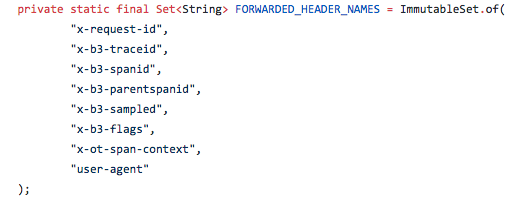
Les paramètres d'en-tête suivants sont utilisés :
Si vous utilisez Java, vous pouvez laisser le code seul et simplement ajouter quelques lignes au fichier Maven POM et définir les variables d'environnement. Voici les lignes que vous devez ajouter à votre fichier POM.XML pour implémenter Jaeger Tracer Resolver :

Et les variables d'environnement correspondantes sont définies dans le Dockerfile :

Voilà, maintenant tout est configuré et nos microservices vont commencer à générer des données de trace.
Voyons en termes généraux
Istio comprend un panneau de contrôle simple basé sur Grafana. Une fois que tout est configuré et exécuté sur la plateforme Red Hat OpenShift PaaS (dans notre exemple, Red Hat OpenShift et Kubernetes sont déployés sur minishift), ce panel est lancé avec la commande suivante :
open "$(minishift openshift service grafana -u)/d/1/istio-dashboard?refresh=5⩝Id=1"
Le panneau Grafana vous permet d'évaluer rapidement les performances du système. Un fragment de ce panneau est présenté dans la figure ci-dessous :
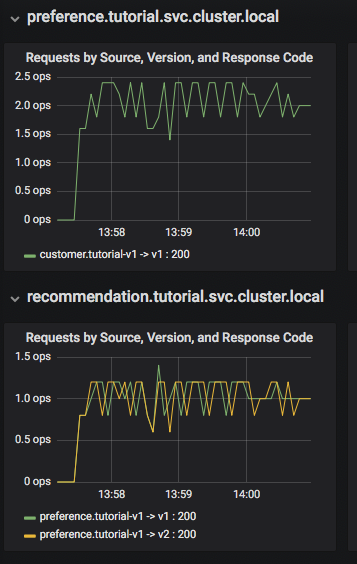
Ici, vous pouvez voir que le microservice client appelle le microservice de préférence v1, qui à son tour appelle les microservices de recommandation v1 et v2. Le panneau Grafana dispose d'un bloc Dashboard Row pour les métriques de haut niveau, telles que le nombre total de requêtes (volume global de requêtes), les taux de réussite et les erreurs 4xx. De plus, il existe une vue Server Mesh avec des graphiques pour chaque service et un bloc Services Row pour afficher des informations détaillées sur chaque conteneur pour chaque service.
Maintenant, creusons plus profondément
Avec un traçage correctement configuré, Istio, comme on dit, vous permet dès la sortie de la boîte d'approfondir l'analyse des performances du système. Dans l'interface utilisateur de Jaeger, vous pouvez visualiser les traces et voir jusqu'où elles vont, ainsi que localiser visuellement les goulots d'étranglement en matière de performances. Lorsque vous utilisez Red Hat OpenShift sur la plateforme minishift, lancez Jaeger UI avec la commande suivante :
minishift openshift service jaeger-query --in-browser
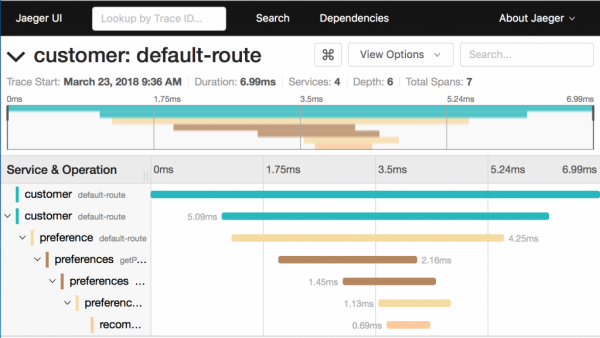
Que pouvez-vous dire du traçage sur cet écran :
- Il est divisé en 7 travées.
- Le temps d'exécution total est de 6.99 ms.
- Le microservice de recommandation, qui est le dernier de la chaîne, passe 0.69 ms.
Les diagrammes de ce type vous permettent de comprendre rapidement la situation où, en raison d'un mauvais fonctionnement d'un service, les performances de l'ensemble du système en souffrent.
Compliquons maintenant la tâche et lançons deux instances du microservice recommendation:v2 avec la commande oc scale —replicas=2 déployer/recommendation-v2. Voici les pods que nous aurons après cela :
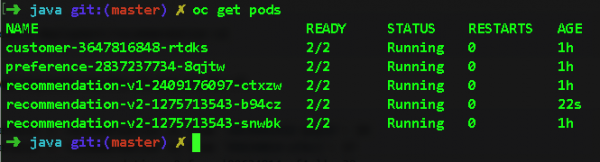
Si nous revenons maintenant à Jaeger et élargissons la portée du service de recommandation, nous pouvons voir vers quel pod les demandes sont acheminées. Ainsi, on peut facilement localiser les freins au niveau d'un pod spécifique. Dans ce cas, vous devez regarder le champ node_id :

Où et comment tout se passe
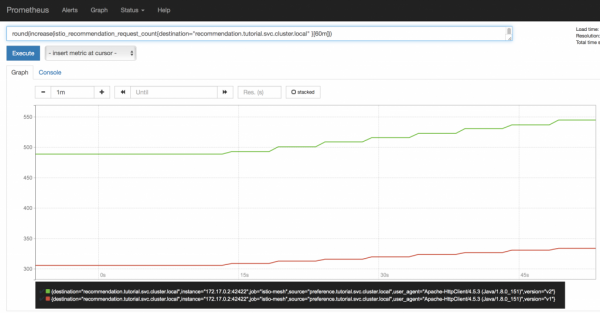
Passons maintenant à l'interface Prometheus et, comme on pouvait s'y attendre, nous y voyons que les requêtes entre la deuxième et la première version du service de recommandation sont divisées dans un rapport de 2:1, strictement en fonction du nombre de pods fonctionnels. De plus, ce graphique changera dynamiquement à mesure que les pods augmentent et diminuent, ce qui sera particulièrement utile pour le déploiement Canary (nous examinerons de plus près ce schéma de déploiement la prochaine fois).
Tout commence
En fait, aujourd’hui, comme on dit, nous n’avons fait qu’effleurer la richesse des informations utiles sur Jaeger, Grafana et Prometheus. En général, tel était notre objectif : vous orienter dans la bonne direction et ouvrir des perspectives pour Istio.
Et rappelez-vous, tout cela est déjà intégré à Istio. Lors de l'utilisation de certains langages de programmation (par exemple Java) et frameworks (par exemple Spring Boot), tout cela peut être implémenté sans toucher du tout au code de l'application lui-même. Oui, le code devra être légèrement modifié si vous utilisez d'autres langages, c'est-à-dire principalement Nodejs ou C#. Mais comme la traçabilité (lire : « tracing ») est l’une des conditions préalables à la création de systèmes cloud fiables, vous devrez quand même éditer le code, que vous ayez Istio ou non. Alors pourquoi ne pas mieux utiliser vos efforts ?
Au moins pour toujours répondre aux questions « où ? et "à quelle vitesse?" avec 100% de certitude.
Ingénierie du chaos dans Istio : c'est comme ça que cela était prévu
La capacité de casser des objets permet d’éviter qu’ils ne se brisent.
Les tests logiciels sont non seulement difficiles, mais aussi importants. Dans le même temps, tester l'exactitude (par exemple, si une fonction renvoie le résultat correct) est une chose, mais tester dans un réseau peu fiable est une tâche complètement différente (on suppose souvent que le réseau fonctionne toujours sans panne, et cela est la première des huit idées fausses sur les calculs distribués). L'une des difficultés pour résoudre ce problème est de savoir comment simuler des pannes dans le système ou les introduire intentionnellement, en effectuant ce que l'on appelle l'injection de fautes. Cela peut être fait en modifiant le code source de l'application elle-même. Mais vous ne testerez alors plus votre code original, mais une version de celui-ci qui simule spécifiquement les échecs. En conséquence, vous risquez de tomber dans l’étreinte mortelle de l’injection de fautes et de rencontrer des Heisenbugs – des pannes qui disparaissent lorsque vous essayez de les détecter.
Nous allons maintenant vous montrer comment Istio vous aide à gérer ces complexités en un seul morceau.
À quoi ressemble tout quand tout va bien ?
Considérez le scénario suivant : nous disposons de deux pods pour notre microservice de recommandation, que nous avons extraits du didacticiel Istio. Un pod est étiqueté v1 et l’autre est étiqueté v2. Comme vous pouvez le constater, tout fonctionne bien jusqu'à présent :
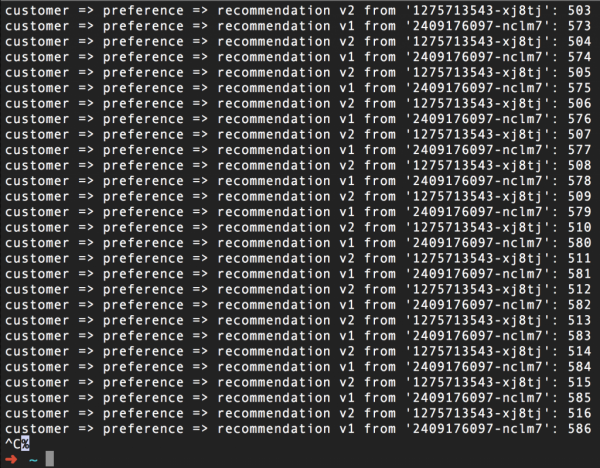
(D'ailleurs, le numéro à droite n'est que le compteur d'appels de chaque pod)
Mais ce n’est pas ce dont nous avons besoin, n’est-ce pas ? Eh bien, essayons de tout casser sans toucher du tout au code source.
Nous organisons des interruptions dans le fonctionnement du microservice
Ci-dessous se trouve le fichier yaml d'une règle de routage Istio qui échouera (erreur) la moitié du temps. serveur 503):
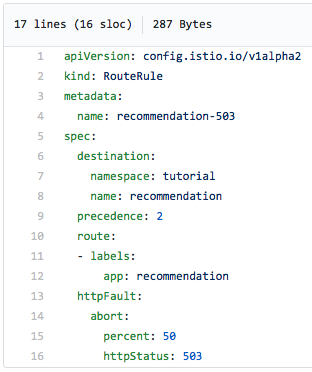
Veuillez noter que nous indiquons explicitement qu'une erreur 503 doit être renvoyée dans la moitié des cas.
Et voici à quoi ressemblera une capture d'écran d'une commande curl exécutée en boucle après avoir activé cette règle pour simuler des échecs. Comme vous pouvez le constater, la moitié des requêtes renvoient l'erreur 503, quel que soit le pod (v1 ou v2) auquel elles sont destinées :
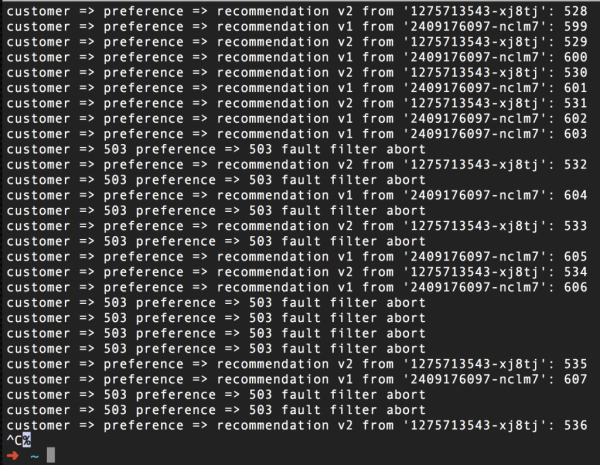
Pour rétablir un fonctionnement normal, il suffit de supprimer cette règle, dans notre cas avec la commande istioctl delete routerule recommendation-503 -n tutoriel. Ici, Tutorial est le nom du projet Red Hat OpenShift qui exécute notre didacticiel Istio.
Introduire des délais artificiels
Les fausses erreurs 503 aident à tester la résilience d'un système aux pannes, mais la capacité à prédire et à gérer les retards devrait vous impressionner encore plus. Et dans la vraie vie, les retards se produisent plus souvent que les échecs. Un microservice lent est un poison qui affecte l’ensemble du système. Avec Istio, vous pouvez tester votre code lié au délai sans le modifier d'aucune façon. Tout d’abord, nous montrerons comment procéder dans le cas de retards de réseau introduits artificiellement.
Veuillez noter qu'après avoir testé de cette façon, vous devrez peut-être (ou souhaiterez) modifier votre code. La bonne nouvelle ici est que dans ce cas, vous serez proactif plutôt que réactif. C'est exactement ainsi que le cycle de développement doit être structuré : codage-test-feedback-codage-test...
Voilà à quoi ressemble la règle... Mais vous savez quoi ? Istio est si simple et ce fichier yaml est si clair que tout dans cet exemple parle de lui-même, il suffit d'y jeter un œil :
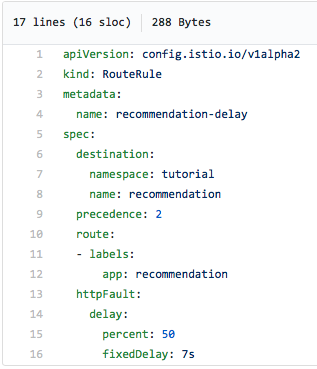
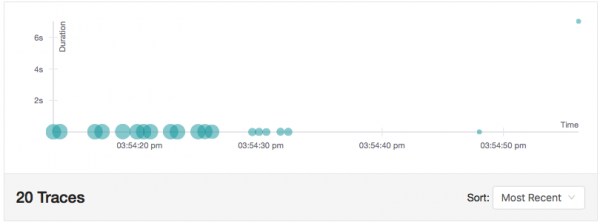
La moitié du temps, nous connaîtrons un retard de 7 secondes. Et ce n'est pas du tout la même chose que si l'on insérait une commande sleep dans le code source, puisqu'Istio retarde en réalité la requête de 7 secondes. Étant donné qu'Istio prend en charge le traçage Jaeger, ce retard est perceptible dans l'interface utilisateur de Jaeger, comme le montre la capture d'écran ci-dessous. Faites attention à la longue requête dans le coin supérieur droit du diagramme - sa durée est de 7.02 secondes :
Ce script vous permet de tester votre code dans des conditions de latence réseau. Et il est clair qu’en supprimant cette règle, on supprimera le délai artificiel. Nous le répétons, mais encore une fois, nous avons fait tout cela sans toucher en aucune façon au code source.
Ne recule pas et n'abandonne pas
Une autre fonctionnalité utile d'Istio pour l'ingénierie du chaos réside dans les appels répétés au service un nombre de fois spécifié. Le but ici est de continuer à essayer lorsque la première requête se termine par une erreur 503 - et peut-être que la N-onzième fois, nous aurons de la chance. Peut-être que le service a été interrompu pendant un certain temps pour une raison ou une autre. Oui, cette raison devrait être déterrée et éliminée. Mais cela viendra plus tard, mais pour l’instant nous allons essayer de nous assurer que le système continue de fonctionner.
Nous voulons donc que le service génère une erreur 503 de temps en temps, puis Istio essaiera de le contacter à nouveau. Et ici, nous avons clairement besoin d'un moyen de générer une erreur 503 sans toucher au code lui-même...
Arrêtez, attendez ! Nous venons de le faire.
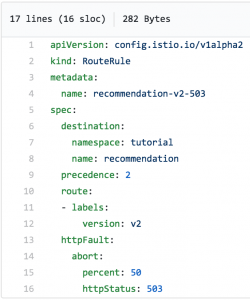
Ce fichier fera en sorte que le service recommendation-v2 émette une erreur 503 la moitié du temps :
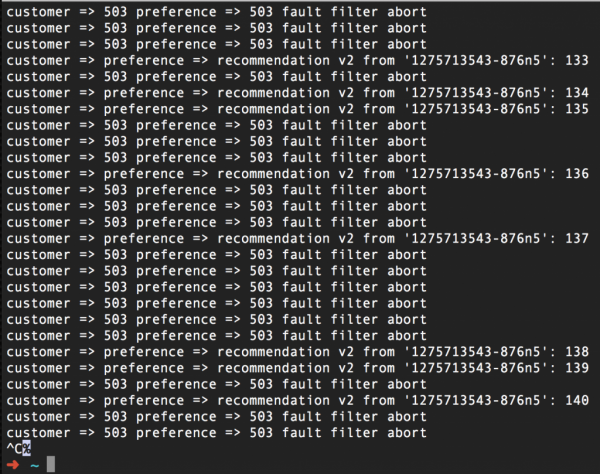
Évidemment, certaines requêtes échoueront :
Utilisons maintenant la fonction Istio Retry :
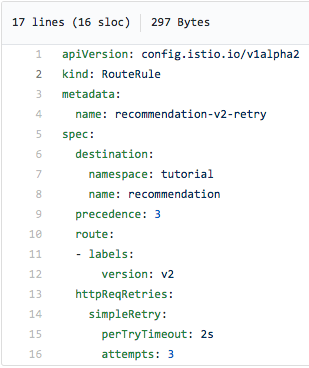
Cette règle de routage se répète trois fois à deux secondes d'intervalle et devrait réduire (et idéalement supprimer du radar) les erreurs 503 :
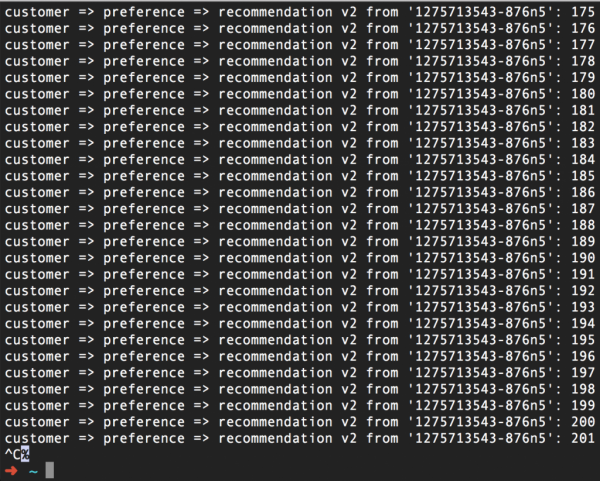
Pour résumer : nous avons fait en sorte qu'Istio, dans un premier temps, génère une erreur 503 pour la moitié des requêtes. Et deuxièmement, le même Istio fait trois tentatives pour recontacter le service lorsqu'une erreur 503 se produit. En conséquence, tout fonctionne parfaitement. Ainsi, en utilisant la fonction Réessayer, nous avons tenu notre promesse de ne pas abandonner et de ne pas abandonner.
Et oui, nous avons recommencé sans toucher du tout au code. Tout ce dont nous avions besoin, c'était de deux règles de routage Istio :

Comment ne pas décevoir l'utilisateur ou sept, n'en attendez pas un
Renversons maintenant la situation et envisageons un scénario dans lequel la seule chose que vous devez faire est de ne pas battre en retraite ou d’abandonner pendant une durée déterminée. Et puis il vous suffit d'arrêter d'essayer de traiter la demande, afin de ne pas forcer tout le monde à attendre un service lent. En d’autres termes, nous ne défendrons pas une position perdue, mais nous nous replierons sur une ligne de réserve afin de ne pas décevoir l’utilisateur du site et de ne pas le faire croupir dans l’ignorance.
Dans Istio, vous pouvez définir un délai d'expiration d'exécution des requêtes. Si le service dépasse ce délai, une erreur 504 (Gateway Timeout) est renvoyée. Encore une fois, tout cela se fait via la configuration d'Istio. Mais nous devrons ajouter une commande sleep au code source du service (puis, bien sûr, effectuer une reconstruction et un redéploiement) pour simuler le fonctionnement lent du service. Hélas, cela ne fonctionnera pas autrement.
Nous avons donc inséré une veille de trois secondes dans le code du service de recommandation v2, reconstruit l'image correspondante et redéployé le conteneur, et maintenant nous allons ajouter un délai d'attente en utilisant la règle de routage Istio suivante :
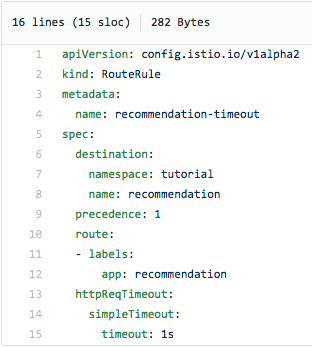
Dans la capture d'écran ci-dessus, vous pouvez voir que nous renonçons à essayer de contacter le service de recommandation si nous ne recevons pas de réponse dans la seconde, c'est-à-dire avant que l'erreur 504 ne se produise. Après avoir appliqué cette règle de routage (et ajouté un délai de veille de trois secondes au code du service de recommandation :v2), nous obtenons ceci :
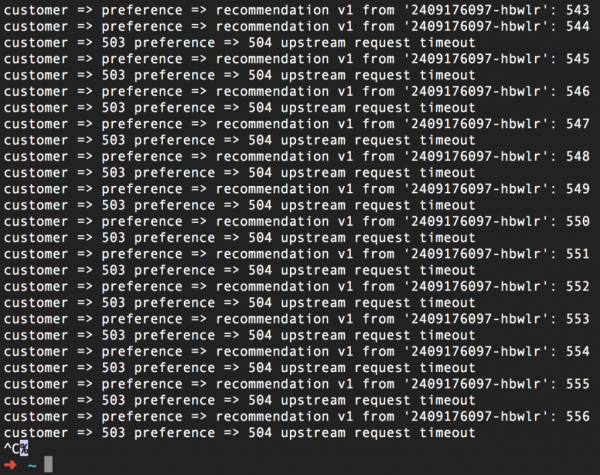
Nous répétons encore, mais le délai d'attente peut être défini sans toucher en aucune façon au code source. Et le bonus supplémentaire ici est que vous pouvez désormais modifier votre code pour répondre au délai d'attente et tester facilement ces modifications à l'aide d'Istio.
Et maintenant tout est ensemble
Injecter un peu de chaos avec Istio est un excellent moyen de tester votre code et la fiabilité de votre système dans son ensemble. Les modèles de repli, de cloison et de disjoncteur, les mécanismes permettant de créer des pannes et des retards artificiels, ainsi que les nouvelles tentatives d'appel et les délais d'attente seront très utiles lors de la création de systèmes cloud tolérants aux pannes. Associés à Kubernetes et Red Hat OpenShift, ces outils vous aideront à affronter l'avenir en toute confiance.
Source: habr.com
