

Parfois, pour résoudre un problème, il suffit de le regarder sous un angle différent. Même si au cours des dix dernières années des problèmes similaires ont été résolus de la même manière avec des effets différents, ce n’est pas un fait que cette méthode soit la seule.
Il existe un sujet tel que le taux de désabonnement des clients. La chose est inévitable, car les clients de toute entreprise peuvent, pour de nombreuses raisons, cesser d’utiliser ses produits ou services. Bien sûr, pour une entreprise, le taux de désabonnement est une action naturelle, mais pas la plus souhaitable, donc chacun essaie de minimiser ce taux de désabonnement. Mieux encore, prédisez la probabilité de désabonnement pour une catégorie particulière d'utilisateurs, ou un utilisateur spécifique, et suggérez quelques étapes pour les fidéliser.
Il faut analyser et essayer de fidéliser le client, si possible, pour au moins les raisons suivantes :
- attirer de nouveaux clients coûte plus cher que les procédures de fidélisation. En règle générale, pour attirer de nouveaux clients, vous devez dépenser de l'argent (publicité), tandis que les clients existants peuvent être activés avec une offre spéciale avec des conditions spéciales ;
- Comprendre les raisons pour lesquelles les clients partent est la clé pour améliorer les produits et services.
Il existe des approches standard pour prédire le taux de désabonnement. Mais lors de l'un des championnats d'IA, nous avons décidé d'essayer la distribution Weibull pour cela. Il est le plus souvent utilisé pour l’analyse de la capacité de survie, les prévisions météorologiques, l’analyse des catastrophes naturelles, l’ingénierie industrielle, etc. La distribution de Weibull est une fonction de distribution spéciale paramétrée par deux paramètres  и
и  .
.
Wikipedia
En général, c’est une chose intéressante, mais pour prévoir les sorties de capitaux, et dans la fintech en général, ce n’est pas très souvent utilisé. Sous la coupe, nous vous expliquerons comment nous (Data Mining Laboratory) avons fait cela, remportant simultanément l'or au championnat d'intelligence artificielle dans la catégorie « IA dans les banques ».
À propos du taux de désabonnement en général
Comprenons un peu ce qu'est le taux de désabonnement des clients et pourquoi il est si important. Une clientèle est importante pour une entreprise. De nouveaux clients arrivent sur cette base, par exemple après avoir découvert un produit ou un service grâce à une publicité, vivent pendant un certain temps (utilisent activement les produits) et après un certain temps, cessent de l'utiliser. Cette période est appelée « Cycle de vie du client » - un terme qui décrit les étapes par lesquelles passe un client lorsqu'il découvre un produit, prend une décision d'achat, paie, utilise et devient un consommateur fidèle, et finalement cesse d'utiliser le produit. pour une raison ou une autre. En conséquence, le taux de désabonnement est la dernière étape du cycle de vie du client, lorsque le client cesse d'utiliser les services, et pour une entreprise, cela signifie que le client a cessé de générer des bénéfices ou tout avantage.
Chaque client bancaire est une personne spécifique qui choisit l'une ou l'autre carte bancaire spécifiquement pour ses besoins. Si vous voyagez souvent, une carte avec des miles vous sera utile. Achète beaucoup - bonjour, carte de cashback. Il achète beaucoup dans des magasins spécifiques - et il existe déjà un partenaire plastique spécial pour cela. Bien entendu, il arrive parfois qu'une carte soit sélectionnée sur la base du critère « Service le moins cher ». En général, il y a suffisamment de variables ici.
Et c'est aussi une personne qui choisit elle-même sa banque - à quoi ça sert de choisir une carte d'une banque dont les succursales se trouvent uniquement à Moscou et dans la région, quand on vient de Khabarovsk ? Même si une carte d'une telle banque est au moins 2 fois plus rentable, la présence d'agences bancaires à proximité reste un critère important. Oui, 2019 est déjà là et le numérique est notre tout, mais un certain nombre de problèmes avec certaines banques ne peuvent être résolus qu'en agence. De plus, encore une fois, une partie de la population fait bien plus confiance à une banque physique qu’à une application sur smartphone, il faut également en tenir compte.
En conséquence, une personne peut avoir de nombreuses raisons de refuser les produits bancaires (ou la banque elle-même). J'ai changé de travail et le tarif de la carte est passé de salaire à « Pour simples mortels », ce qui est moins rentable. J'ai déménagé dans une autre ville où il n'y a pas d'agences bancaires. Je n’ai pas aimé l’interaction avec l’opérateur non qualifié de l’agence. Autrement dit, il peut y avoir encore plus de raisons de fermer un compte que d'utiliser le produit.
Et le client peut non seulement exprimer clairement son intention - venir à la banque et rédiger une déclaration, mais simplement cesser d'utiliser les produits sans résilier le contrat. Il a été décidé d’utiliser l’apprentissage automatique et l’IA pour comprendre ces problèmes.
De plus, le désabonnement des clients peut survenir dans n’importe quel secteur (télécommunications, fournisseurs d’accès Internet, compagnies d’assurance, en général, partout où il existe une clientèle et des transactions périodiques).
Qu'avons-nous fait
Tout d'abord, il était nécessaire de décrire une limite claire - à partir de quel moment nous commençons à considérer que le client est parti. Du point de vue de la banque qui nous a fourni les données pour notre travail, le statut d'activité du client était binaire : il est actif ou non. Il y avait un indicateur ACTIVE_FLAG dans la table "Activité", dont la valeur pouvait être "0" ou "1" ("Inactif" et "Actif" respectivement). Et tout irait bien, mais une personne est telle qu'elle peut l'utiliser activement pendant un certain temps, puis sortir de la liste active pendant un mois - elle est tombée malade, est partie en vacances dans un autre pays ou est même allée tester un carte d'une autre banque. Ou peut-être qu’après une longue période d’inactivité, recommencez à utiliser les services de la banque
Par conséquent, nous avons décidé d'appeler une période d'inactivité une certaine période de temps continue pendant laquelle le drapeau correspondant était mis à « 0 ».
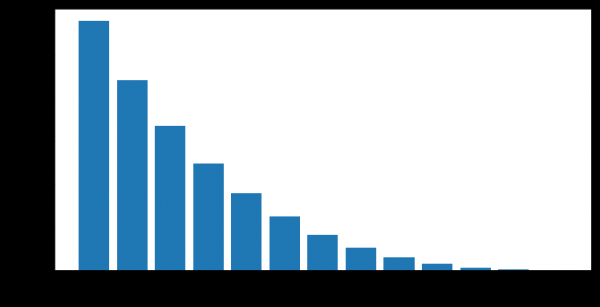
Les clients passent d’inactifs à actifs après des périodes d’inactivité de durée variable. Nous avons la possibilité de calculer le degré de valeur empirique de la « fiabilité des périodes d'inactivité » - c'est-à-dire la probabilité qu'une personne recommence à utiliser les produits bancaires après une inactivité temporaire.
Par exemple, ce graphique montre la reprise d'activité (ACTIVE_FLAG=1) des clients après plusieurs mois d'inactivité (ACTIVE_FLAG=0).
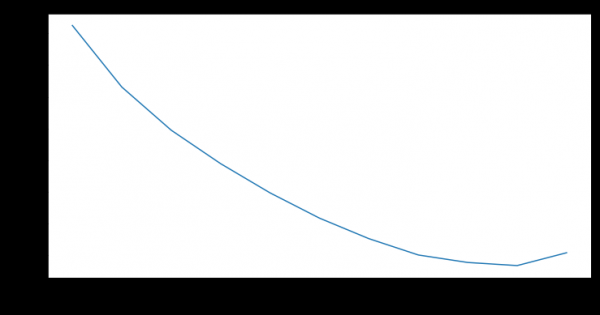
Nous allons ici clarifier un peu l'ensemble de données avec lequel nous avons commencé à travailler. Ainsi, la banque a fourni des informations agrégées sur 19 mois dans les tableaux suivants :
- « Activité » - transactions mensuelles des clients (par cartes, banque en ligne et banque mobile), y compris la paie et les informations sur le chiffre d'affaires.
- "Cartes" - données sur toutes les cartes dont dispose le client, avec une grille tarifaire détaillée.
- « Accords » - informations sur les accords du client (ouverts et fermés) : prêts, dépôts, etc., indiquant les paramètres de chacun.
- « Clients » - un ensemble de données démographiques (sexe et âge) et la disponibilité des informations de contact.
Pour le travail, nous avions besoin de toutes les tables à l'exception de la « Carte ».
Il y avait ici une autre difficulté: dans ces données, la banque n'indiquait pas quel type d'activité avait lieu sur les cartes. Autrement dit, nous pouvions comprendre s'il y avait des transactions ou non, mais nous ne pouvions plus déterminer leur type. Par conséquent, il n’était pas clair si le client retirait de l’argent, recevait un salaire ou dépensait l’argent pour des achats. Nous n'avions pas non plus de données sur les soldes des comptes, ce qui aurait été utile.
L'échantillon lui-même était impartial : dans cet échantillon, sur 19 mois, la banque n'a fait aucune tentative pour fidéliser les clients et minimiser les sorties.
Donc, à propos des périodes d'inactivité.
Pour formuler une définition du churn, une période d’inactivité doit être sélectionnée. Pour créer une prévision de désabonnement à un moment donné  , vous devez avoir un historique client d'au moins 3 mois à intervalle
, vous devez avoir un historique client d'au moins 3 mois à intervalle  . Notre historique étant limité à 19 mois, nous avons décidé de prendre une période d'inactivité de 6 mois, si disponible. Et pour le délai minimum pour une prévision de qualité, nous avons pris 3 mois. Nous avons pris les chiffres sur 3 et 6 mois de manière empirique en nous basant sur une analyse du comportement des données clients.
. Notre historique étant limité à 19 mois, nous avons décidé de prendre une période d'inactivité de 6 mois, si disponible. Et pour le délai minimum pour une prévision de qualité, nous avons pris 3 mois. Nous avons pris les chiffres sur 3 et 6 mois de manière empirique en nous basant sur une analyse du comportement des données clients.
Nous avons formulé la définition du churn comme suit : mois de désabonnement des clients  il s'agit du premier mois avec ACTIVE_FLAG=0, à partir duquel à partir de ce mois il y a au moins six zéros consécutifs dans le champ ACTIVE_FLAG, c'est-à-dire le mois à partir duquel le client a été inactif pendant 6 mois.
il s'agit du premier mois avec ACTIVE_FLAG=0, à partir duquel à partir de ce mois il y a au moins six zéros consécutifs dans le champ ACTIVE_FLAG, c'est-à-dire le mois à partir duquel le client a été inactif pendant 6 mois.
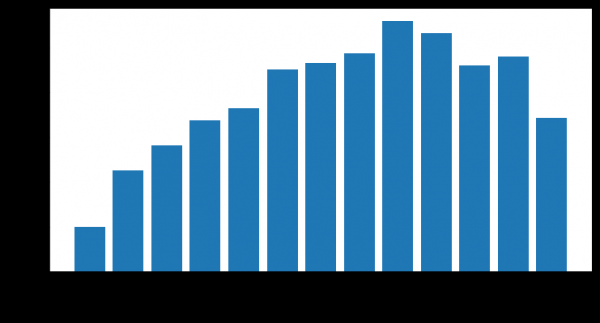
Nombre de clients partis
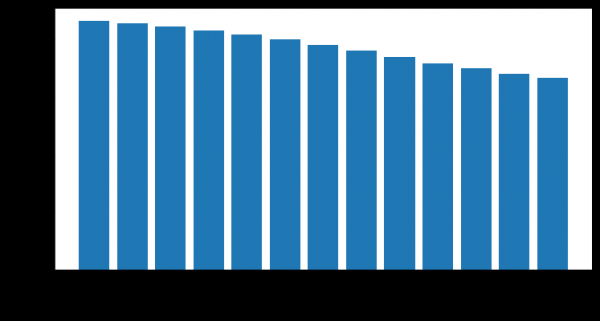
Nombre de clients restants
Comment est calculé le taux de désabonnement ?
Dans de telles compétitions, et dans la pratique en général, les sorties sont souvent prédites de cette manière. Le client utilise des produits et services à différentes périodes de temps, les données sur l'interaction avec lui sont représentées comme un vecteur de caractéristiques d'une longueur fixe n. Le plus souvent, ces informations comprennent :
- Données caractérisant l'utilisateur (données démographiques, segment marketing).
- Historique d'utilisation des produits et services bancaires (il s'agit d'actions de clients qui sont toujours liées à une heure ou une période précise de l'intervalle dont nous avons besoin).
- Données externes, s'il était possible de les obtenir - par exemple, des avis sur les réseaux sociaux.
Et après cela, ils en dérivent une définition du taux de désabonnement, différente pour chaque tâche. Ensuite, ils utilisent un algorithme d'apprentissage automatique, qui prédit la probabilité qu'un client quitte l'entreprise.  basé sur un vecteur de facteurs
basé sur un vecteur de facteurs  . Pour entraîner l'algorithme, l'un des cadres bien connus pour construire des ensembles d'arbres de décision est utilisé, , , ou des modifications de celui-ci.
. Pour entraîner l'algorithme, l'un des cadres bien connus pour construire des ensembles d'arbres de décision est utilisé, , , ou des modifications de celui-ci.
L’algorithme en lui-même n’est pas mauvais, mais il présente plusieurs inconvénients sérieux lorsqu’il s’agit de prédire le taux de désabonnement.
- Il n’a pas de soi-disant « mémoire ». L'entrée du modèle est un nombre spécifié d'entités qui correspondent au moment actuel. Afin de stocker des informations sur l'historique des modifications des paramètres, il est nécessaire de calculer des caractéristiques spéciales qui caractérisent les modifications des paramètres au fil du temps, par exemple le nombre ou le montant des transactions bancaires au cours des 1,2,3, XNUMX, XNUMX derniers mois. Cette approche ne peut refléter que partiellement la nature des changements temporaires.
- Horizon de prévision fixe. Le modèle n'est capable de prédire l'attrition des clients que sur une période de temps prédéfinie, par exemple une prévision un mois à l'avance. Si une prévision est requise pour une période de temps différente, par exemple trois mois, vous devez alors reconstruire l'ensemble de formation et recycler un nouveau modèle.
Notre approche
Nous avons immédiatement décidé de ne pas utiliser d'approches standards. En plus de nous, 497 autres personnes se sont inscrites au championnat, chacune ayant derrière elle une expérience considérable. Donc essayer de faire quelque chose selon un schéma standard dans de telles conditions n’est pas une bonne idée.
Et nous avons commencé à résoudre les problèmes rencontrés par le modèle de classification binaire en prédisant la distribution de probabilité des délais de désabonnement des clients. Une approche similaire peut être observée , elle vous permet de prédire le taux de désabonnement de manière plus flexible et de tester des hypothèses plus complexes que dans l'approche classique. En tant que famille de distributions modélisant le temps de sortie, nous avons choisi la distribution pour son utilisation généralisée dans l’analyse de survie. Le comportement du client peut être considéré comme une sorte de survie.
Voici des exemples de distributions de densité de probabilité de Weibull en fonction des paramètres  и
и  :
:
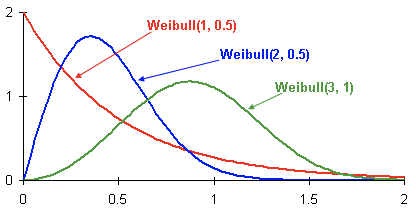
Il s’agit de la fonction de densité de probabilité de trois clients différents au fil du temps. Le temps est présenté en mois. En d'autres termes, ce graphique montre quand un client est le plus susceptible de se désinscrire au cours des deux prochains mois. Comme vous pouvez le constater, un client avec une distribution a un plus grand potentiel de partir plus tôt que les clients avec le Weibull (2, 0.5) et le Weibull. (3,1) distributions.
Le résultat est un modèle qui, pour chaque client, pour chaque
Le mois prédit les paramètres de la distribution de Weibull, qui reflète le mieux l'occurrence de la probabilité de sortie au fil du temps. Plus en détail:
- Les fonctionnalités cibles de l'ensemble de formation sont le temps restant jusqu'au désabonnement au cours d'un mois spécifique pour un client spécifique.
- S'il n'y a pas de taux de désabonnement pour un client, nous supposons que le temps de désabonnement est supérieur au nombre de mois entre le mois en cours et la fin de l'historique dont nous disposons.
- Modèle utilisé : réseau de neurones récurrent avec couche LSTM.
- Comme fonction de perte, nous utilisons la fonction de log-vraisemblance négative pour la distribution de Weibull.
Voici les avantages de cette méthode :
- La distribution de probabilité, en plus de la possibilité évidente de classification binaire, permet de prédire de manière flexible divers événements, par exemple si un client cessera d'utiliser les services de la banque dans les 3 mois. De plus, si nécessaire, diverses mesures peuvent être moyennées sur cette distribution.
- Le réseau neuronal récurrent LSTM dispose de mémoire et utilise efficacement tout l'historique disponible. À mesure que l’histoire s’étoffe ou s’affine, la précision augmente.
- L'approche peut être facilement adaptée lors de la division de périodes en périodes plus petites (par exemple, lors de la division des mois en semaines).
Mais il ne suffit pas de créer un bon modèle, il faut aussi bien évaluer sa qualité.
Comment la qualité a-t-elle été évaluée ?
Nous avons choisi Lift Curve comme métrique. Il est utilisé en entreprise pour de tels cas en raison de son interprétation claire, il est bien décrit и . Si vous décrivez la signification de cette métrique en une phrase, ce serait « Combien de fois l'algorithme fait-il la meilleure prédiction au cours de la première ?  % que de manière aléatoire."
% que de manière aléatoire."
Modèles de formation
Les conditions du concours n’ont pas établi de mesure de qualité spécifique permettant de comparer différents modèles et approches. De plus, la définition du taux de désabonnement peut être différente et dépendre de l'énoncé du problème, qui, à son tour, est déterminé par les objectifs commerciaux. Par conséquent, afin de comprendre quelle méthode est la meilleure, nous avons formé deux modèles :
- Une approche de classification binaire couramment utilisée utilisant un algorithme d'apprentissage automatique d'arbre de décision d'ensemble ();
- Modèle Weibull-LSTM
L'ensemble de tests était composé de 500 clients présélectionnés qui ne faisaient pas partie de l'ensemble de formation. Les hyper-paramètres ont été sélectionnés pour le modèle par validation croisée, ventilés par client. Les mêmes ensembles de fonctionnalités ont été utilisés pour entraîner chaque modèle.
En raison du fait que le modèle n'a pas de mémoire, des fonctionnalités spéciales ont été adoptées, montrant le rapport entre les modifications des paramètres sur un mois et la valeur moyenne des paramètres au cours des trois derniers mois. Ce qui a caractérisé le taux de variation des valeurs au cours de la dernière période de trois mois. Sans cela, le modèle basé sur Random Forest serait désavantagé par rapport à Weibull-LSTM.
Pourquoi LSTM avec distribution de Weibull est meilleur qu'une approche d'arbre de décision d'ensemble
Tout est clair ici en seulement quelques images.
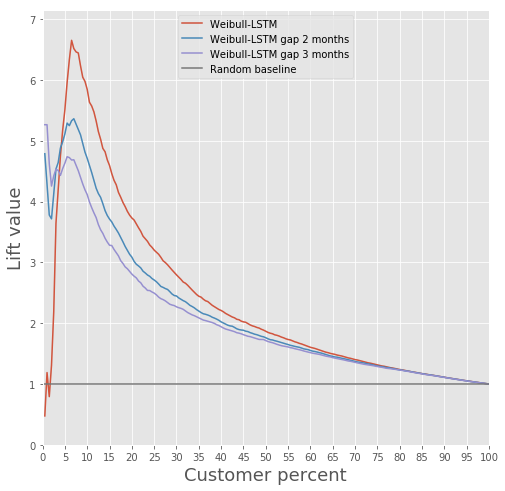
Comparaison de la courbe de levage pour l'algorithme classique et Weibull-LSTM
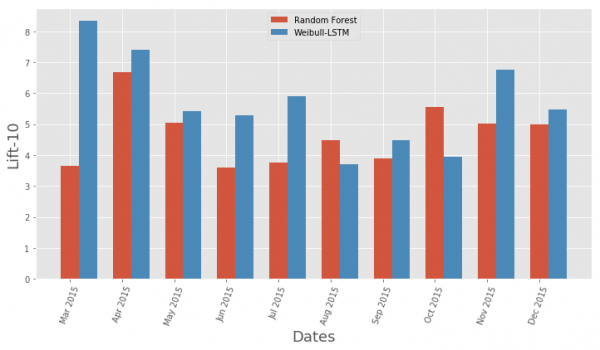
Comparaison de la métrique Lift Curve par mois pour l'algorithme classique et Weibull-LSTM
En général, LSTM est supérieur à l’algorithme classique dans presque tous les cas.
Prédiction du taux de désabonnement
Un modèle basé sur un réseau neuronal récurrent avec des cellules LSTM avec une distribution de Weibull peut prédire l'attrition à l'avance, par exemple prédire l'attrition des clients dans les n prochains mois. Considérons le cas pour n = 3. Dans ce cas, pour chaque mois, le réseau de neurones doit déterminer correctement si le client va partir, à partir du mois suivant et jusqu'au nième mois. En d’autres termes, il doit déterminer correctement si le client restera après n mois. Cela peut être considéré comme une prévision à l'avance : prédire le moment où le client commençait tout juste à penser à partir.
Comparons la courbe de levage pour Weibull-LSTM 1, 2 et 3 mois avant la sortie :
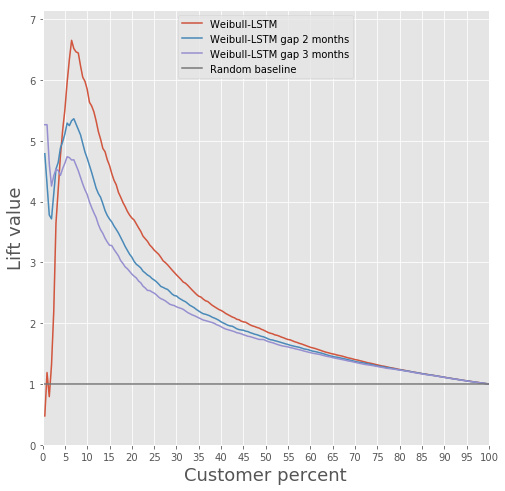
Nous avons déjà écrit plus haut que les prévisions faites pour les clients qui ne sont plus actifs depuis un certain temps sont également importantes. Par conséquent, nous ajouterons ici à l'échantillon les cas où le client parti est déjà inactif depuis un ou deux mois et vérifierons que Weibull-LSTM classe correctement ces cas comme désabonnement. Puisque de tels cas étaient présents dans l’échantillon, nous nous attendons à ce que le réseau les gère correctement :
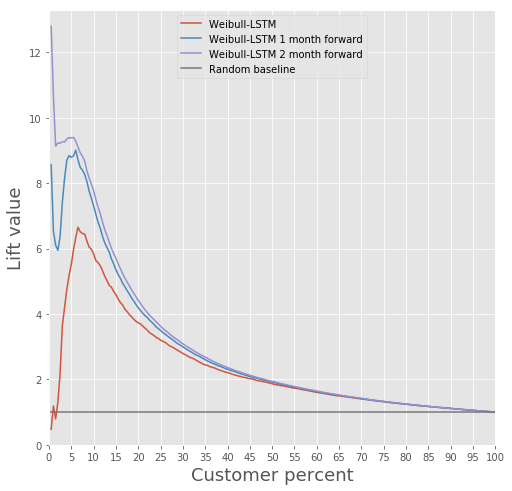
Fidélisation de la clientèle
En fait, c'est la principale chose à faire, avoir en main l'information que tel ou tel client s'apprête à arrêter d'utiliser le produit. En parlant de construire un modèle qui pourrait offrir quelque chose d'utile aux clients afin de les fidéliser, cela ne peut pas être fait si vous n'avez pas un historique de tentatives similaires qui se termineraient bien.
Nous n’avions pas une telle histoire, alors nous l’avons décidé de cette façon.
- Nous construisons un modèle qui identifie les produits intéressants pour chaque client.
- Chaque mois, nous exécutons le classificateur et identifions les clients potentiels.
- Nous proposons le produit à certains clients, selon le modèle du point 1, et mémorisons nos actions.
- Après quelques mois, nous examinons lesquels de ces clients potentiellement partants sont partis et lesquels sont restés. Ainsi, nous formons un échantillon de formation.
- Nous entraînons le modèle en utilisant l'historique obtenu à l'étape 4.
- Eventuellement, nous répétons la procédure en remplaçant le modèle de l'étape 1 par le modèle obtenu à l'étape 5.
Un test de la qualité d'une telle rétention peut être effectué par des tests A/B réguliers - nous divisons les clients qui quittent potentiellement en deux groupes. Nous proposons à l’un des produits basés sur notre modèle de rétention, et à l’autre nous n’offrons rien. Nous avons décidé de former un modèle qui pourrait être utile déjà au point 1 de notre exemple.
Nous voulions rendre la segmentation aussi interprétable que possible. Pour ce faire, nous avons choisi plusieurs caractéristiques facilement interprétables : le nombre total de transactions, les salaires, la rotation totale des comptes, l'âge, le sexe. Les fonctionnalités du tableau « Cartes » n'ont pas été prises en compte comme non informatives, et les fonctionnalités du tableau 3 « Contrats » n'ont pas été prises en compte en raison de la complexité du traitement afin d'éviter les fuites de données entre l'ensemble de validation et l'ensemble de formation.
Le clustering a été réalisé à l'aide de modèles de mélange gaussiens. Le critère d'information d'Akaike nous a permis de déterminer 2 optima. Le premier optimum correspond à 1 cluster. Le deuxième optimum, moins prononcé, correspond à 80 clusters. Sur la base de ce résultat, nous pouvons tirer la conclusion suivante : il est extrêmement difficile de diviser des données en clusters sans information a priori donnée. Pour un meilleur clustering, vous avez besoin de données décrivant chaque client en détail.
Par conséquent, le problème de l’apprentissage supervisé a été envisagé afin d’offrir à chaque client un produit différent. Les produits suivants ont été considérés : « Dépôt à terme », « Carte de crédit », « Découvert », « Prêt à la consommation », « Prêt automobile », « Hypothèque ».
Les données incluaient un autre type de produit : le « Compte courant ». Mais nous ne l'avons pas considéré en raison de son faible contenu informatif. Pour les utilisateurs clients d'une banque, c'est-à-dire n'a pas arrêté d'utiliser ses produits, un modèle a été construit pour prédire quel produit pourrait les intéresser. La régression logistique a été choisie comme modèle et la valeur Lift pour les 10 premiers percentiles a été utilisée comme mesure d'évaluation de la qualité.
La qualité du modèle peut être évaluée sur la figure.
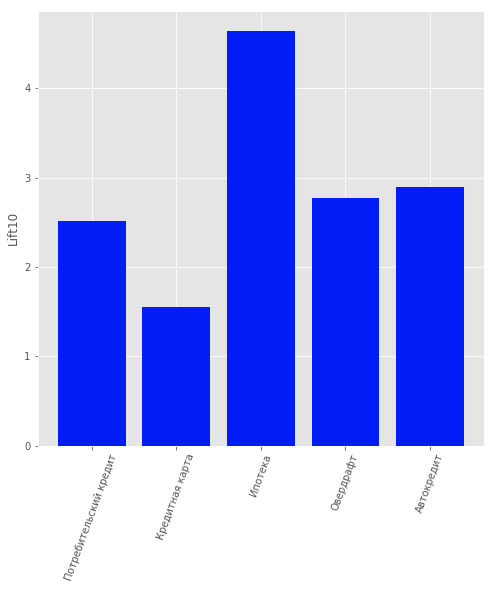
Résultats du modèle de recommandation de produits pour les clients
Total
Cette approche nous a valu la première place dans la catégorie « IA dans les banques » du Championnat d'IA RAIF-Challenge 2017.

Apparemment, l’essentiel était d’aborder le problème sous un angle non conventionnel et d’utiliser une méthode habituellement utilisée pour d’autres situations.
Même si un exode massif d’utilisateurs pourrait bien constituer une catastrophe naturelle pour les services.
Cette méthode peut être prise en compte pour tout autre domaine où il est important de prendre en compte les sorties, et pas seulement les banques. Par exemple, nous l'avons utilisé pour calculer nos propres sorties - dans les succursales de Rostelecom en Sibérie et à Saint-Pétersbourg.
Société "Data Mining Laboratory" "Portail de recherche "Sputnik"
Source: habr.com
