

Halo semua. Di bawah ini adalah transkripnya .
– sistem pemantauan untuk berbagai sistem dan layanan, yang dengannya administrator sistem dapat mengumpulkan informasi tentang parameter sistem saat ini dan mengatur peringatan untuk menerima pemberitahuan tentang penyimpangan dalam pengoperasian sistem.
Laporan tersebut akan menyertakan perbandingan и — proyek untuk penyimpanan metrik Prometheus jangka panjang.



Pertama, saya akan bercerita tentang Prometheus. Ini adalah sistem pemantauan yang mengumpulkan metrik dari target tertentu dan menyimpannya ke penyimpanan lokal. Prometheus dapat merekam metrik ke penyimpanan jarak jauh dan dapat menghasilkan peringatan serta aturan pencatatan.

Keterbatasan Prometheus:
- Itu tidak memiliki tampilan kueri global. Ini adalah saat Anda memiliki beberapa contoh prometheus yang independen. Mereka mengumpulkan metrik. Dan Anda ingin membuat kueri di atas semua metrik yang dikumpulkan dari berbagai instance prometheus. Prometheus tidak mengizinkan ini.
- Dengan prometheus, kinerja dibatasi hanya pada satu server. Prometheus tidak secara otomatis melakukan penskalaan di beberapa server. Anda hanya dapat membagi target secara manual ke beberapa Prometheus.
- Cakupan metrik di Prometheus dibatasi hanya pada satu server karena alasan yang sama yaitu tidak dapat secara otomatis menskalakan ke beberapa server.
- Tidak mudah mengatur keamanan data di Prometheus.

Solusi terhadap permasalahan/tantangan tersebut?
Solusinya adalah:
Semua solusi ini ditujukan untuk penyimpanan jarak jauh atas data yang dikumpulkan oleh Prometheus. Mereka memecahkan masalah penyimpanan jarak jauh dari slide sebelumnya dengan cara yang berbeda. Dalam presentasi ini saya hanya akan membahas dua solusi pertama: и .
Untuk pertama kalinya informasi tentang muncul oleh . Arsitekturnya dijelaskan di sana dan cara kerjanya.

Thanos mengambil data yang disimpan Prometheus ke disk lokal dan menyalinnya ke S3 atau ke objek penyimpanan lain.

Jadi Thanos memberikan tampilan kueri global. Anda dapat menanyakan data yang disimpan di penyimpanan objek dari beberapa instans Prometheus.

Thanos mendukung PromQL dan .

Thanos menggunakan kode Prometheus untuk menyimpan data.

Thanos dikembangkan oleh pengembang yang sama dengan Prometheus.
Tentang . Di sini , tempat kita pertama kali membicarakannya .
VictoriaMetrics menerima data dari beberapa prometheus protokol yang didukung oleh Prometheus.
VictoriaMetrics menyediakan tampilan kueri global, karena beberapa instans Prometheus dapat menulis data ke satu VictoriaMetrics. Oleh karena itu, Anda dapat membuat pertanyaan tentang semua data ini.

VictoriaMetrics juga mendukung, seperti API kueri Thanos, PromQL dan Prometheus.

Berbeda dengan Thanos, kode sumber VictoriaMetrics ditulis dari awal dan dioptimalkan untuk kecepatan dan konsumsi sumber daya.

VictoriaMetrics, tidak seperti Thanos, menskalakan baik secara vertikal maupun horizontal. Makan , yang berskala vertikal. Anda dapat memulai dengan satu prosesor dan memori 1 GB dan secara bertahap berkembang hingga ratusan prosesor dan memori 1 TB. VictoriaMetrics dapat menggunakan semua sumber daya ini. Performanya akan meningkat sekitar 100 kali lipat dibandingkan sistem 1 inti.

Sejarah Thanos dimulai pada November 2017, ketika komitmen publik pertama kali muncul. Sebelumnya, Thanos dikembangkan secara internal .

Pada bulan Juni 2019 ada rilis penting 0.5.0, di mana protokol. Dia dikeluarkan dari Thanos karena performanya tidak bagus. Seringkali cluster Thanos tidak berfungsi dengan benar, node yang terhubung secara tidak benar karena protokol gosip. Oleh karena itu, kami memutuskan untuk mengeluarkannya dari sana. Saya pikir ini adalah keputusan yang tepat.

Pada bulan Juni 2019 yang sama, mereka mengirimkan nomor lamaran в .

Dan setelah beberapa bulan Thanos diterima , yang mencakup Prometheus, Kubernetes, dan proyek populer lainnya.

Pada bulan Januari 2018, pengembangan VictoriaMetrics dimulai.

Pada bulan September 2018, saya menyebutkan VictoriaMetrics secara publik untuk pertama kalinya.

Pada bulan Desember 2018, versi Single-node diterbitkan.

Pada bulan Mei 2019 sumber versi Single-node dan cluster.

Pada bulan Juni 2019, sama seperti Thanos, kami mengajukan permohonan ke yayasan CNCF dengan nomor . Kami melamar satu hari sebelum Thanos melamar.

Tapi sayangnya kami masih belum diterima di sana. Dibutuhkan bantuan masyarakat.

Mari kita lihat slide terpenting yang menunjukkan arsitektur Thanos dan VictoriaMetrics.
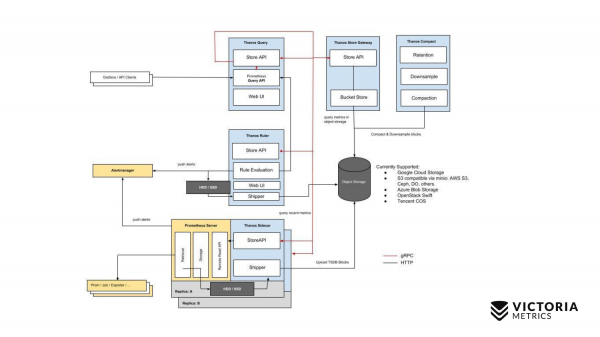
Mari kita mulai dengan Thanos. Komponen kuning adalah komponen Prometheus. Yang lainnya adalah komponen Thanos. Mari kita mulai dengan komponen yang paling penting. Thanos Sidecar adalah komponen yang dipasang di sebelah setiap Prometheus. Ini memuat data Prometheus dari penyimpanan lokal ke S3 atau Object Storage lainnya.
Ada juga komponen yang disebut Thanos Store Gateway, yang dapat membaca data ini dari Object Storage atas permintaan masuk dari Thanos Query. Thanos Query mengimplementasikan PromQL dan Prometheus API. Artinya, dari luar tampak seperti Prometheus. Menerima pertanyaan PromQL, mengirimkannya ke Thanos Store Gateway, Thanos Store Gateway mengambil data yang diperlukan dari Object Storage, mengirimkannya kembali.
Namun kami menyimpan data di Object Storage tanpa dua jam terakhir karena fitur implementasi Thanos Sidecar, yang tidak dapat mengunggah dua jam terakhir ke Object Storage S3, karena Prometheus belum membuat file selama dua jam ini di penyimpanan lokal.
Bagaimana Anda memutuskan untuk menyiasatinya? Thanos Query, selain permintaan ke Thanos Store Gateway, mengirimkan permintaan paralel ke setiap Thanos Sidecar, yang terletak di sebelah Prometheus.
Dan Thanos Sidecar, pada gilirannya, memproksi permintaan lebih lanjut ke Prometheus, dan mengambil data selama dua jam terakhir.
Selain komponen tersebut, ada juga komponen opsional yang tanpanya Thanos tidak akan bisa bekerja dengan baik. Ini adalah Thanos Compact, yang bertanggung jawab untuk menggabungkan file kecil di Object Storage menjadi file lebih besar yang diunggah ke sini oleh Thanos Sidecars. Thanos Sidecar mengunggah file data di sana dalam dua jam. File-file ini, jika tidak digabungkan menjadi file yang lebih besar, maka jumlahnya bisa bertambah sangat signifikan. Semakin banyak file tersebut, semakin banyak memori yang dibutuhkan untuk Thanos Store Gateway, semakin banyak pula sumber daya yang dibutuhkan untuk mentransfer data melalui jaringan dan metadata. Thanos Store Gateway menjadi tidak efektif. Oleh karena itu, Thanos Compact perlu dijalankan, yang menggabungkan file kecil menjadi file yang lebih besar, sehingga jumlah file tersebut lebih sedikit dan untuk mengurangi overhead pada Thanos Store Gateway.
Ada juga komponen seperti Thanos Ruler. Ini mengeksekusi aturan peringatan Prometheus dan dapat mengevaluasi aturan perekaman Prometheus untuk menulis data kembali ke Object Storage. Namun komponen ini tidak disarankan untuk digunakan, karena... Dia .
Ini adalah skema sederhana Thanos.
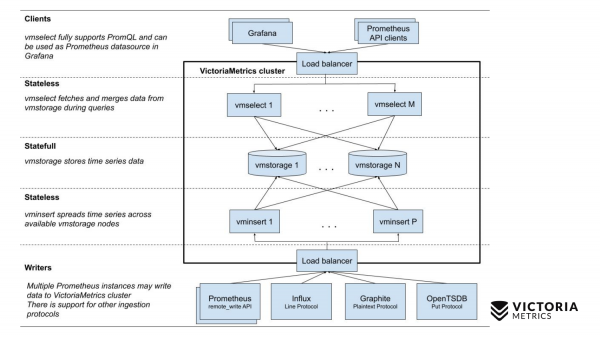
Sekarang mari kita bandingkan dengan skema VictoriaMetrics.
VictoriaMetrics memiliki 2 versi: versi node tunggal dan cluster. Node tunggal berjalan pada satu komputer. Node tunggal tidak memiliki komponen ini, hanya satu biner. Biner pada slide ini terlihat seperti persegi ini. Segala sesuatu yang ada di dalam kotak adalah isi file biner untuk versi Single-node. Anda tidak perlu tahu tentang dia. Anda cukup menjalankan biner dan semuanya berfungsi untuk kami.
Versi cluster lebih rumit. Di dalamnya ada tiga komponen berbeda: vmselect, vminsert dan vmstorage. Dari namanya sudah jelas apa yang mereka lakukan masing-masing. Komponen Sisipkan menerima data dalam format berbeda: dari API penulisan jarak jauh Prometheus, protokol jalur Influx, protokol Grafit, dan protokol OpenTSDB. Komponen Sisipkan menerimanya, menguraikannya, dan mendistribusikannya di antara komponen penyimpanan yang ada, tempat data sudah disimpan. Komponen Select, pada gilirannya, menerima kueri PromQL. Dia menerapkan , serta API kueri Prometheus, dan dapat digunakan sebagai pengganti Prometheus di Grafana atau klien API Prometheus lainnya. Pilih menerima permintaan promql, menguraikannya, membaca data yang diperlukan untuk menjalankan permintaan ini dari node penyimpanan, memproses data ini dan mengembalikan respons.

Mari kita bandingkan kerumitan instalasi Thanos dan VictoriaMetrics.

Mari kita mulai dengan Thanos. Sebelum mulai bekerja dengan Thanos, Anda perlu membuat bucket di Object Storage, seperti S3 atau GCS, agar Thanos Sidecar dapat menulis data ke dalamnya.

Kemudian untuk setiap Prometheus Anda perlu menginstal Thanos Sidecar. Sebelum ini, Anda harus ingat untuk menonaktifkan pemadatan data di Prometheus. Pemadatan data secara berkala memampatkan data di penyimpanan Prometheus lokal untuk mengurangi konsumsi sumber daya.
Saat Anda menginstal Thanos Sidecar di Prometheus, Anda harus menonaktifkan pemadatan data ini, karena Thanos Sidecar tidak berfungsi dengan baik saat pemadatan data diaktifkan. Ini berarti Prometheus Anda mulai menyimpan data dalam blok dua jam dan berhenti menggabungkan blok tersebut menjadi blok yang lebih besar. Oleh karena itu, jika Anda membuat kueri yang melebihi durasi dua jam terakhir, maka kueri tersebut tidak akan bekerja seefisien jika pemadatan data diaktifkan.

Oleh karena itu, Thanos merekomendasikan untuk mengurangi waktu penyimpanan data di penyimpanan lokal menjadi 6-8 jam untuk mengurangi overhead sejumlah besar blok kecil.
Setelah Anda menginstal Thanos Sidecar, Anda harus menginstal dua komponen untuk setiap Object Storage Bucket. Ini adalah Thanos Compactor dan Thanos Store Gateway.

Setelah itu, Anda perlu menginstal Thanos Query dan mengkonfigurasinya agar dapat terhubung ke semua Thanos Store Gateways yang Anda miliki, dan juga dapat terhubung ke semua Thanos Sidecars.
Mungkin ada sedikit masalah di sini.

Anda perlu mengonfigurasi koneksi yang andal dan aman dari Thanos Query ke komponen ini. Dan jika Prometheus Anda berlokasi di pusat data yang berbeda, atau di VPC yang berbeda, maka koneksi ke pusat data tersebut dari luar dilarang. Namun agar Thanos Query berfungsi, Anda perlu mengonfigurasi koneksi di sana, dan Anda harus mencari cara.
Jika Anda memiliki banyak pusat data seperti itu, maka keandalan seluruh sistem akan menurun. Karena Thanos Query harus terus menjaga koneksi ke semua Thanos Sidecars yang berlokasi di pusat data berbeda. Untuk setiap permintaan masuk, itu akan mengarahkan permintaan ke semua Thanos Sidecars. Jika koneksi terputus, Anda akan menerima kumpulan data yang tidak lengkap, atau Anda akan menerima respons “cluster down”.

Di VictoriaMetrics, segalanya menjadi lebih sederhana. Untuk versi Single-node, Anda hanya perlu menjalankan satu biner dan semuanya berfungsi.

Pada versi cluster, cukup menjalankan ketiga jenis komponen di atas dalam jumlah berapa pun yang Anda perlukan, atau gunakan untuk mengotomatiskan peluncuran komponen di Kubernetes. Kami juga berencana membuat operator Kubernetes. Bagan Helm tidak mencakup beberapa kasus dan memungkinkan Anda menyalahkan diri sendiri. Misalnya, ini memungkinkan Anda mengurangi jumlah node penyimpanan, yang akan menyebabkan hilangnya data.

Setelah Anda meluncurkan satu versi biner atau berkerumun, Anda hanya perlu menambahkan Prometheus ke konfigurasi sehingga mulai menulis data secara paralel ke penyimpanan lokal dan penyimpanan jarak jauh. Seperti yang Anda lihat, konfigurasi ini seharusnya memiliki kinerja yang jauh lebih andal dibandingkan dengan konfigurasi Thanos. Kita tidak perlu menjaga koneksi dari VictoriaMetrics ke semua Prometheus, karena Prometheus sendiri terhubung ke VictoriaMetrics dan mengirimkan data.

Mari pertimbangkan dukungan Thanos dan VictoriaMetrics.

Thanos perlu memantau Sidecar untuk memastikan mereka tidak berhenti memuat data ke dalam Object Storage. Mereka mungkin menghentikan pengunduhan data ini karena kesalahan pengunduhan, misalnya koneksi jaringan Anda ke Object Storage untuk sementara terganggu, atau Object Storage untuk sementara tidak tersedia. Thanos Sidecar akan menyadarinya saat ini, melaporkan kesalahan, mungkin mogok dan kemudian berhenti bekerja. Jika Anda tidak memantaunya, maka Anda akan berhenti mentransfer data ke Object Storage. Jika waktu retensi terlewati (disarankan 6-8 jam), maka Anda akan kehilangan data yang tidak masuk ke Object Storage.

Pemadat Thanos mungkin berhenti bekerja karena . Compactor mengambil data dari Object Storage dan menggabungkannya menjadi data yang lebih besar. Karena compactor tidak disinkronkan dengan Sidecars, hal berikut dapat terjadi: Sidecar belum sempat menyelesaikan blok, Compactor memutuskan bahwa blok ini telah selesai ditulis. Compactor mulai membacanya. Itu tidak membaca blok secara penuh dan berhenti bekerja. Lihat detailnya .

Store Gateway mungkin mengembalikan data yang tidak konsisten karena balapan antara Compactor dan Sidecars. Hal yang sama terjadi di sini, karena Store Gateway tidak disinkronkan dengan Compactor dan Sidecar dengan cara apa pun. Oleh karena itu, kondisi balapan dapat terjadi ketika Store Gateway tidak melihat sebagian data atau melihat data yang tidak diperlukan.

Komponen Query di Thanos secara default mengembalikan sebagian hasil jika beberapa Sidecars atau Store Gateway tidak tersedia saat ini. Anda akan menerima sebagian data, dan Anda bahkan tidak akan tahu bahwa Anda tidak menerima semua data. Ini adalah cara kerjanya secara default. Dalam situasi serupa, VictoriaMetrics mengembalikan data yang ditandai sebagai sebagian.

Berbeda dengan Thanos, VictoriaMetrics jarang kehilangan data. Sekalipun koneksi dari Prometheus ke VictoriaMetrics terputus, hal ini tidak menjadi masalah, karena Prometheus terus mencatat data baru yang masuk di Write Ahead Log yang durasinya 2 jam. Jika Anda memulihkan koneksi ke VictoriaMetrics dalam waktu dua jam, data Anda tidak akan hilang. Prometheus .

Berbeda dengan Thanos, yang menulis data ke penyimpanan objek hanya setelah dua jam, Prometheus secara otomatis mereplikasi data menggunakan protokol penulisan jarak jauh ke penyimpanan jarak jauh, seperti VictoriaMetrics. Anda tidak takut kehilangan penyimpanan lokal di Prometheus. Jika dia tiba-tiba kehilangan penyimpanan lokal, maka dalam kasus terburuk Anda akan kehilangan detik-detik terakhir data yang tidak sempat direkam di penyimpanan jarak jauh.

Kubernetes secara otomatis mengelola cluster, tidak seperti Thanos. Sulit untuk menempatkan semua komponen Thanos ke dalam satu cluster Kubernetes, tidak seperti komponen cluster VictoriaMetrics.

VictoriaMetrics memiliki pembaruan yang sangat sederhana ke versi baru. Hentikan saja VictoriaMetrics, perbarui binernya dan luncurkan. Saat dihentikan melalui sinyal SIGINT, semua biner VictoriaMetrics melakukan penghentian dengan baik. Mereka menyimpan data yang diperlukan dengan benar, menutup koneksi masuk dengan benar agar tidak kehilangan apa pun. Jadi Anda tidak akan kehilangan apa pun saat melakukan upgrade.

VictoriaMetrics mempermudah perluasan klaster. Cukup tambahkan komponen yang diperlukan dan lanjutkan bekerja.

Tentang jebakan di Thanos dan VictoriaMetrics.

Thanos memiliki kendala berikut. Prometheus harus menyimpan data selama dua jam terakhir. Jika hilang, Anda akan kehilangan semuanya karena belum ditulis ke Object Storage seperti S3.

Komponen Store Gateway dan komponen pemadat dapat memerlukan banyak memori untuk bekerja dengan Object Storage yang besar jika ada banyak file kecil yang disimpan di sana. Semakin besar jumlah dan ukuran file, semakin banyak Store Gateway dan RAM pemadat yang dibutuhkan untuk menyimpan metainformasi. Thanos punya banyak masalah terkait fakta itu .

Thanos diiklankan untuk berkembang tanpa batas waktu dengan jumlah Prometheus yang Anda miliki. Hal ini sebenarnya tidak benar. Karena semua permintaan melewati komponen Query, yang harus secara bersamaan melakukan polling pada semua komponen Store Gateway dan semua komponen Sidecar, tarik data dari sana lalu proses terlebih dahulu. Tentu saja, kecepatan permintaan dibatasi oleh tautan lemah paling lambat, Store Gateway paling lambat, atau Sidecar paling lambat.
Komponen-komponen ini mungkin dimuat secara tidak merata. Misalnya, Anda memiliki Prometheus, yang mengumpulkan jutaan metrik per detik. Dan ada Prometheus, yang mengumpulkan ribuan metrik per detik. Prometheus, yang mengumpulkan jutaan metrik per detik, memberikan beban yang jauh lebih tinggi pada server yang dijalankannya. Oleh karena itu, Sidecar bekerja lebih lambat di sana. Dan secara umum semuanya berjalan lambat di sana. Dan komponen Query akan menarik data dari sana dengan sangat lambat. Oleh karena itu, kinerja seluruh cluster Anda akan dibatasi oleh Sidecar yang lambat ini.

Secara default, Thanos memberikan sebagian data jika beberapa Sidecar dan Store Gateway tidak tersedia. Misalnya, jika Sidecar Anda tersebar di seluruh dunia di pusat data yang berbeda, kemungkinan kegagalan koneksi dan tidak tersedianya komponen akan sangat meningkat. Oleh karena itu, dalam banyak kasus, Anda akan menerima sebagian data tanpa menyadarinya.
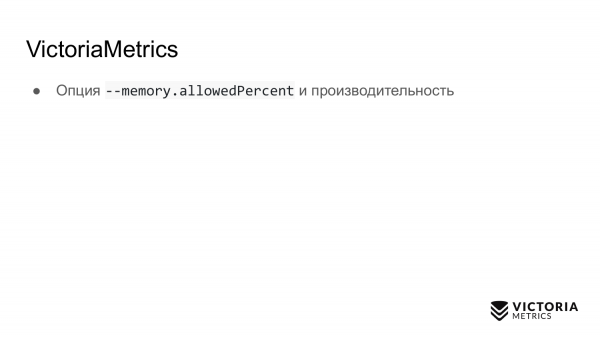
VictoriaMetrics juga memiliki kendala. Jebakan pertama adalah opsi yang membatasi jumlah RAM yang digunakan untuk cache VictoriaMetrics. Secara default, ini sama dengan 60% dari RAM pada mesin yang menjalankan VictoriaMetrics atau 60% dari RAM pod VictoriaMetrics di Kubernetes.
Jika Anda salah mengubah nilai ini, Anda dapat merusak kinerja VictoriaMetrics. Misalnya, jika Anda menetapkan nilai terlalu rendah, data mungkin tidak lagi masuk ke dalam cache VictoriaMetrics. Karena itu, ia harus melakukan pekerjaan ekstra dan memuat prosesor dan disk. Jika Anda membuat opsi ini terlalu besar, hal ini meningkatkan, pertama, kemungkinan VictoriaMetrics akan crash karena kesalahan memori habis, dan kedua, hal ini akan menyebabkan fakta bahwa hanya ada sedikit RAM yang tersisa di memori sistem operasi untuk cache berkas. Dan VictoriaMetrics mengandalkan cache file untuk kinerja. Jika tidak cukup, beban pada disk bisa meningkat secara signifikan. Oleh karena itu, sarannya: jangan mengubah parameter kecuali benar-benar diperlukan.
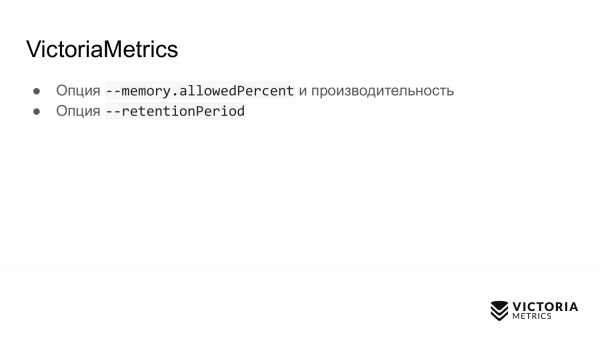
Pilihan kedua. Ini adalah periode retensi - periode yang diatur ke 1 bulan secara default. Ini adalah lamanya waktu VictoriaMetrics menyimpan data. Setelah periode ini, VictoriaMetrics menghapus data.
Banyak orang menjalankan VictoriaMetrics tanpa parameter ini dan mencatat data selama sebulan. Lalu mereka bertanya: kenapa data bulan sebelumnya hilang? Karena periode retensi default adalah 1 bulan. Oleh karena itu, Anda perlu mengetahui dan mengatur Periode Retensi yang benar.

Mari kita lihat fitur uniknya.

Thanos memiliki fitur yang disebut downsampling: interval 5 menit dan setiap jam, yang sering kali terjadi . Jika Anda mencari di Google dan melihat masalahnya di github, ada banyak masalah terkait downsampling ini, yang terkadang tidak berfungsi dengan benar, atau tidak berfungsi seperti yang diharapkan pengguna.

Thanos memiliki deduplikasi data untuk pasangan Prometheus HA. Ketika dua Prometheus mengumpulkan metrik yang sama dari target yang sama dan Thanos menyimpannya di Object Storage. Thanos dapat menghapus duplikat data ini dengan benar, tidak seperti VictoriaMetrics.

Thanos memiliki komponen peringatan yang ada dalam skema Thanos. Tapi dia .

Thanos mempunyai kelebihan karena Thanos dan Prometheus berbagi kode yang sama. Thanos dan Prometheus dikembangkan oleh pengembang yang sama. Dengan peningkatan pada Thanos atau Prometheus, pihak lain menang.

Fitur utama VictoriaMetrics adalah MetricsQL. Ini adalah ekstensi VictoriaMetrics untuk PromQL, yang saya bicarakan pada pertemuan pemantauan besar sebelumnya.

VictoriaMetrics mendukung pemuatan data menggunakan banyak protokol berbeda. VictoriaMetrics tidak hanya dapat menerima data dari Prometheus, tetapi juga melalui protokol Influx, OpenTSDB, dan Graphite.

Data VictoriaMetrics memakan lebih sedikit ruang dibandingkan dengan Thanos dan Prometheus.
Jika Anda merekam data nyata, pengguna berbicara tentang pengurangan 2-5 kali lipat dalam ukuran data pada disk dibandingkan dengan Prometheus dan Thanos.

Keuntungan lain dari VictoriaMetrics adalah kecepatannya dioptimalkan.

Mari kita lihat biaya infrastruktur.

Salah satu kelebihan Thanos adalah menyimpan data di objek penyimpanan yang harganya relatif murah.
Saat menyimpan data dalam penyimpanan objek, Anda harus membayar operasi penulisan dan pembacaan data ($10 per juta operasi). Saat Anda menulis data ke penyimpanan objek, Anda membayar biaya hosting untuk mengunggah data ke Internet; jika klaster Anda tidak ada di AWS, maka di sana gratis. Saat Anda membaca data, Anda membayar antara $10 dan $230 per 1TB. Ini bisa menjadi penting jika Anda sering menanyakan data historis dari cluster Thanos.

Untuk cluster Thanos, Anda perlu membayar server untuk Compact, Store Gateway, komponen Query yang memerlukan banyak memori, dan CPU untuk data dalam jumlah besar.

VictoriaMetrics memiliki biaya berikut. Jika Anda menyimpan data di drive GCE HDD, biayanya adalah $40 untuk 1TB. Untuk VictoriaMetrics, drive HDD biasa sudah cukup; tidak diperlukan SSD, yang harganya lima kali lebih mahal. VictoriaMetrics dioptimalkan untuk HDD.

VictoriaMetrics memerlukan server untuk komponen: baik komponen Single-nod atau clustered, yang, tidak seperti komponen Thanos, memerlukan lebih sedikit CPU dan RAM - dan karenanya akan lebih murah.

Contoh implementasi.

Thanos memiliki contoh implementasi di Gitlab. Gitlab sepenuhnya berjalan di Thanos. Tapi tidak semuanya lancar di sana. Jika Anda melihatnya , maka Anda dapat melihat bahwa mereka selalu memilikinya : Tidak ada cukup memori untuk komponen Store Gateway atau Query. Mereka terus-menerus harus menambah jumlah memori.
Oleh karena itu, biaya untuk menyelesaikan permasalahan ini meningkat.
Implementasi kedua yang mungkin lebih berhasil adalah perusahaan Improbable yang mulai mengembangkan Thanos. Mereka menerbitkan kode sumber Thanos. Improbable adalah perusahaan yang mengembangkan mesin game.

VictoriaMetrics memiliki contoh penerapan publik:
- pembuat situs web wix.com
- Adidas menerapkan VictoriaMetrics dan bahkan melakukan presentasi di PromCon 2019 lalu
- TrafficStars - jaringan iklan
- Seznam.cz adalah mesin pencari Ceko yang populer.
Dan kemudian ada perusahaan tanpa nama yang tidak dapat saya sebutkan sekarang. Mereka tidak menyetujuinya.
- Salah satu pengembang game besar. Lebih besar dari saya Mustahil.
- Pengembang perangkat lunak grafis utama.
- Bank besar Rusia.
- Produsen turbin angin asal Eropa yang berhasil menguji VictoriaMetrics. Pabrikan ini menerapkan VictoriaMetrics untuk memantau data yang dikumpulkan dari turbin angin dengan kecepatan 50 sampel per detik per sensor. Setiap turbin angin memiliki beberapa ratus sensor. Mereka memiliki beberapa ratus turbin angin.
- Maskapai penerbangan Rusia ingin menerapkan VictoriaMetrics, tetapi tetap tidak bisa. Kami sedang dalam tahap kontrak dengan mereka.
 Kesimpulan.
Kesimpulan.
VictoriaMetrics dan Thanos menyelesaikan masalah serupa, tetapi dengan cara berbeda:
- Tampilan kueri global
- penskalaan horizontal
- retensi sewenang-wenang

Terima kasih.
Kami menunggu Anda di kami .

Hanya pengguna terdaftar yang dapat berpartisipasi dalam survei. , silakan.
Apa yang Anda gunakan sebagai penyimpanan jangka panjang untuk Prometheus?
35,3%Thanos6
0,0%Korteks0
0,0%M3DB0
41,2%VictoriaMetrik7
23,5%lainnya4
17 pengguna memilih. 16 pengguna abstain.
Sumber: www.habr.com
