

Компания Google представила аудиокодек Lyra V2, использующий методы машинного обучения для достижения максимального качества передачи речи при использовании очень медленных каналов связи. Новая версия отличается переходом на новую архитектуру нейронной сети, поддержкой дополнительных платформ, расширенными возможностями управления битрейтом, повышением производительности и достижением более высокого качества звука. Эталонная реализация кода написана на C++ и распространяется под лицензией Apache 2.0.
По качеству передаваемых голосовых данных на низких скоростях Lyra существенно превосходит традиционные кодеки, в которых используются методы цифровой обработки сигналов. Для достижения высокого качества передачи голоса в условиях ограниченного объёма передаваемой информации, помимо обычных методов сжатия звука и преобразования сигналов, в Lyra применяется речевая модель на базе системы машинного обучения, позволяющая воссоздать недостающую информацию на основе типовых характеристик речи.
Кодек включает в себя кодировщик и декодировщик. Алгоритм работы кодировщика сводится к извлечению параметров голосовых данных каждые 20 миллисекунд, их сжатию и передаче получателю по сети c битрейтом от 3.2kbps до 9.2kbps. На стороне получателя декодировщик использует генеративную модель для воссоздания исходного речевого сигнала на основе переданных звуковых параметров, которые включают в себя логарифмические мел-спектрограммы, учитывающие характеристики энергии речи в различных частотных диапазонах и подготовленные с учётом модели человеческого слухового восприятия.
В Lyra V2 использована новая генеративная модель на основе свёрточной нейронной сети SoundStream, отличающейся низкими требованиями в вычислительным ресурсам, что позволяет выполнять декодирование в режиме реального времени даже на маломощных системах. Задействованная для генерации звука модель обучена с использованием нескольких тысяч часов с записями голосов на более чем 90 языках. Для выполнения модели используется TensorFlow Lite. Производительности предложенной реализации достаточно для кодирования и декодирования речи на смартфонах нижнего ценового диапазона.
Кроме использования иной генеративной модели новая версия также примечательна включением в архитектуру кодека звеньев с квантователем RVQ (Residual Vector Quantizer), выполняемым на стороне отправителя перед передачей данных, а на стороне получателя после приёма данных. Квантователь преобразует выдаваемые кодеком параметры в наборы пакетов, кодируя информацию в привязке к выбранному битрейту. Для обеспечения разного уровня качестве предусмотрены квантователи для трёх битрейтов (3.2 kps, 6 kbps и 9.2 kbps), чем выше битрейт, тем лучше качество, но более высокие требования к пропускной способности.
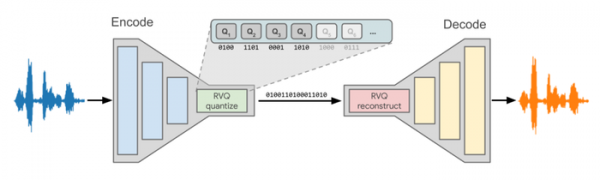
Новая архитектура позволила снизить задержки передачи сигнала со 100 до 20 миллисекунд. Для сравнения кодек Opus для WebRTC продемонстрировал на протестированных битрейтах задержки в 26.5мс, 46.5мс и 66.5мс. Также значительно выросла производительность кодировщика и декодировщика — по сравнению с прошлой версией отмечается ускорение до 5 раз. Например, на смартфоне Pixel 6 Pro новый кодек выполняет кодировние и декодирование 20-миллисекундной выборки за 0.57 мс, что в 35 раз быстрее, чем необходимо для передачи в режиме реального времени.
Кроме производительности удалось добиться и повышение качества восстановления звука — по шкале MUSHRA качество речи на битрейтах 3.2 kbps, 6 kbps и 9.2 kbps при использовании кодека Lyra V2 соответствует битрейтам 10 kbps, 13 kbps и 14 kbps при использовании кодека Opus.
Fonte: opennet.ru
