

JetBrains ha aperto un modello Mellum2, progettato per l'uso in strumenti di IA per lo sviluppo di software. Il modello è pubblicato sotto una licenza Apache 2.0I pesi sono disponibili su Hugging Face. JetBrains sottolinea che Mellum2 è stato addestrato da zero ed è progettato non per attività multimodali, ma per lavorare con testo e codice: instradamento delle richieste, pipeline RAG, riassunto, agenti ausiliari e implementazione privata nell'infrastruttura aziendale.
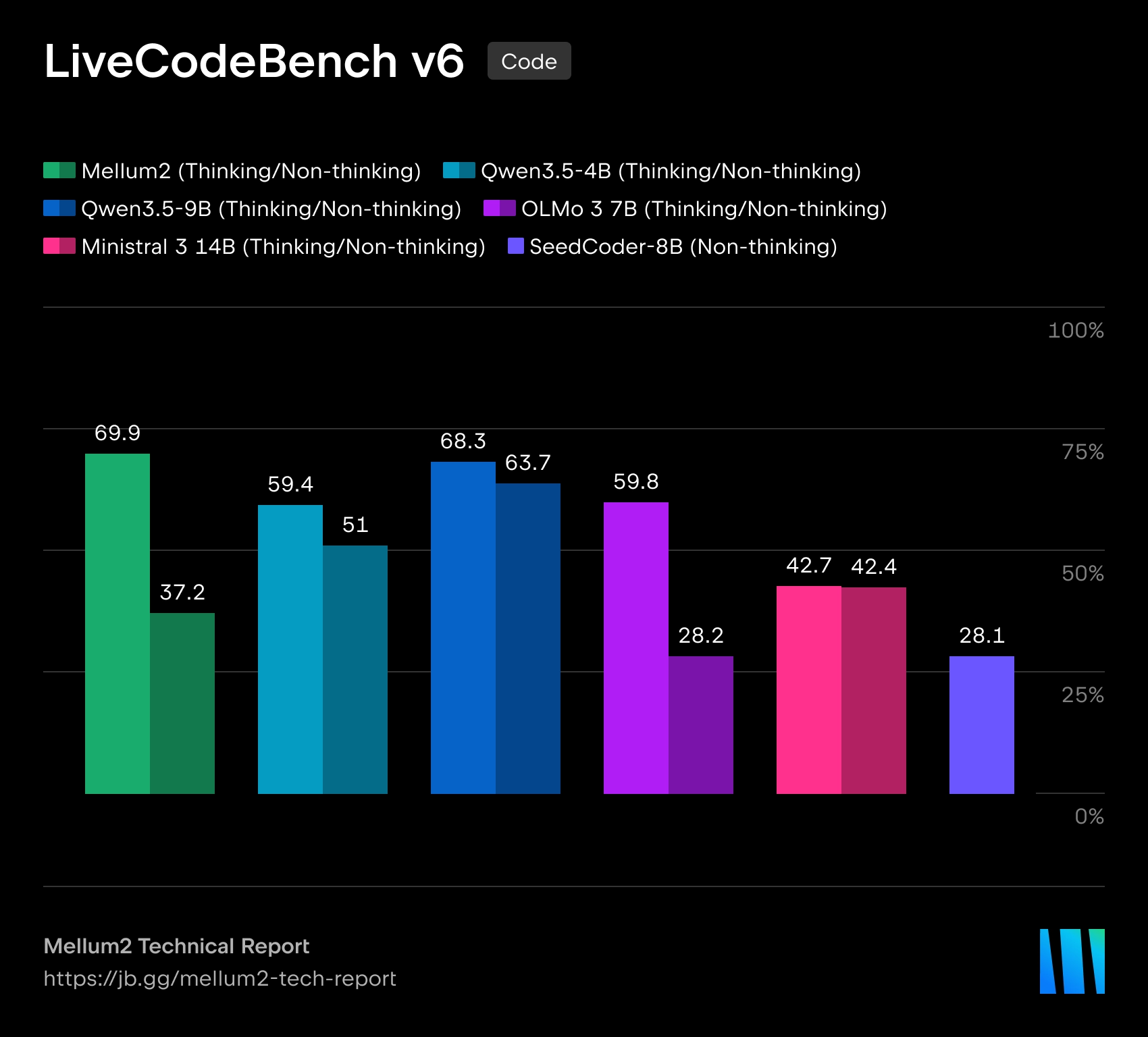
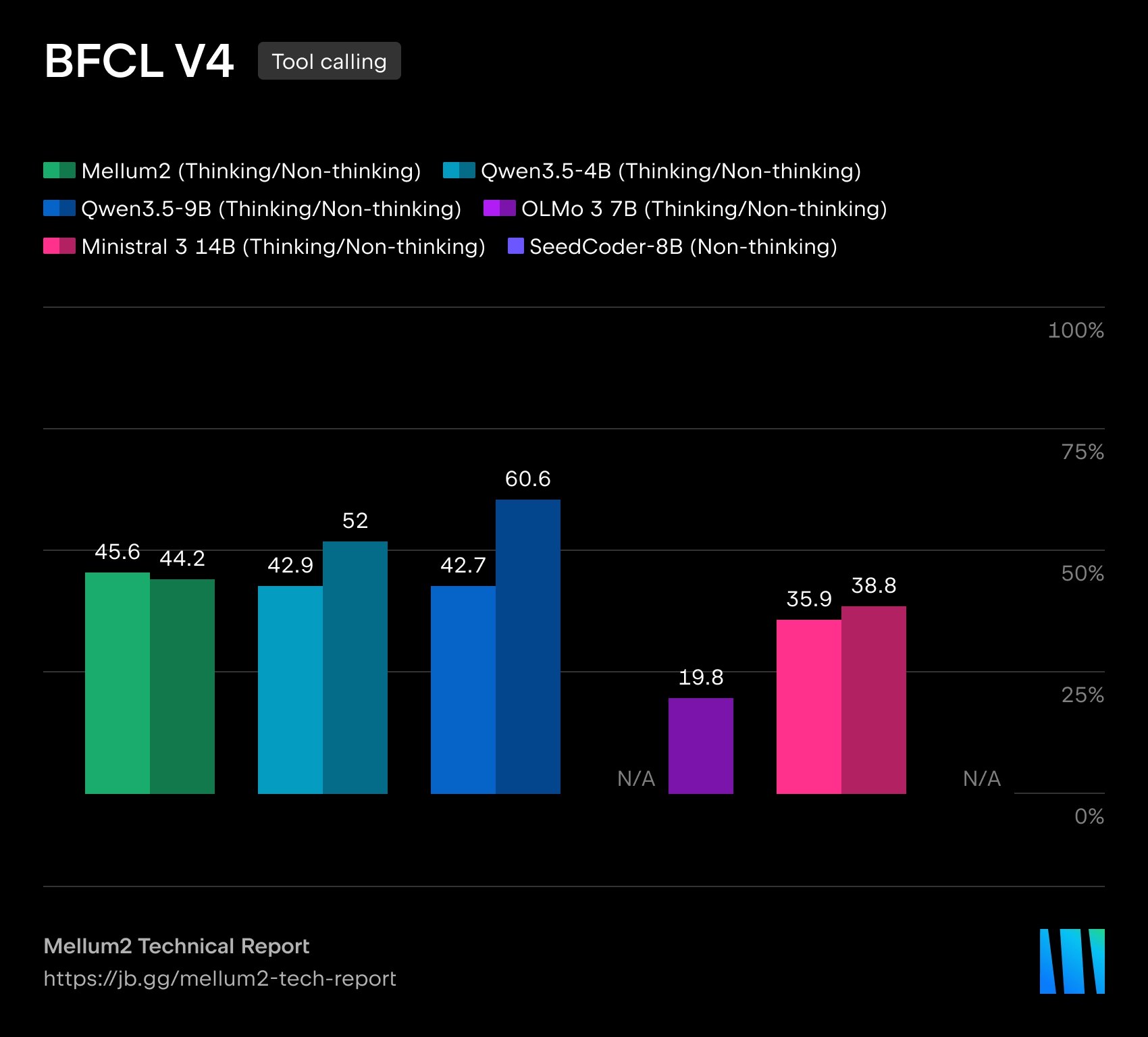
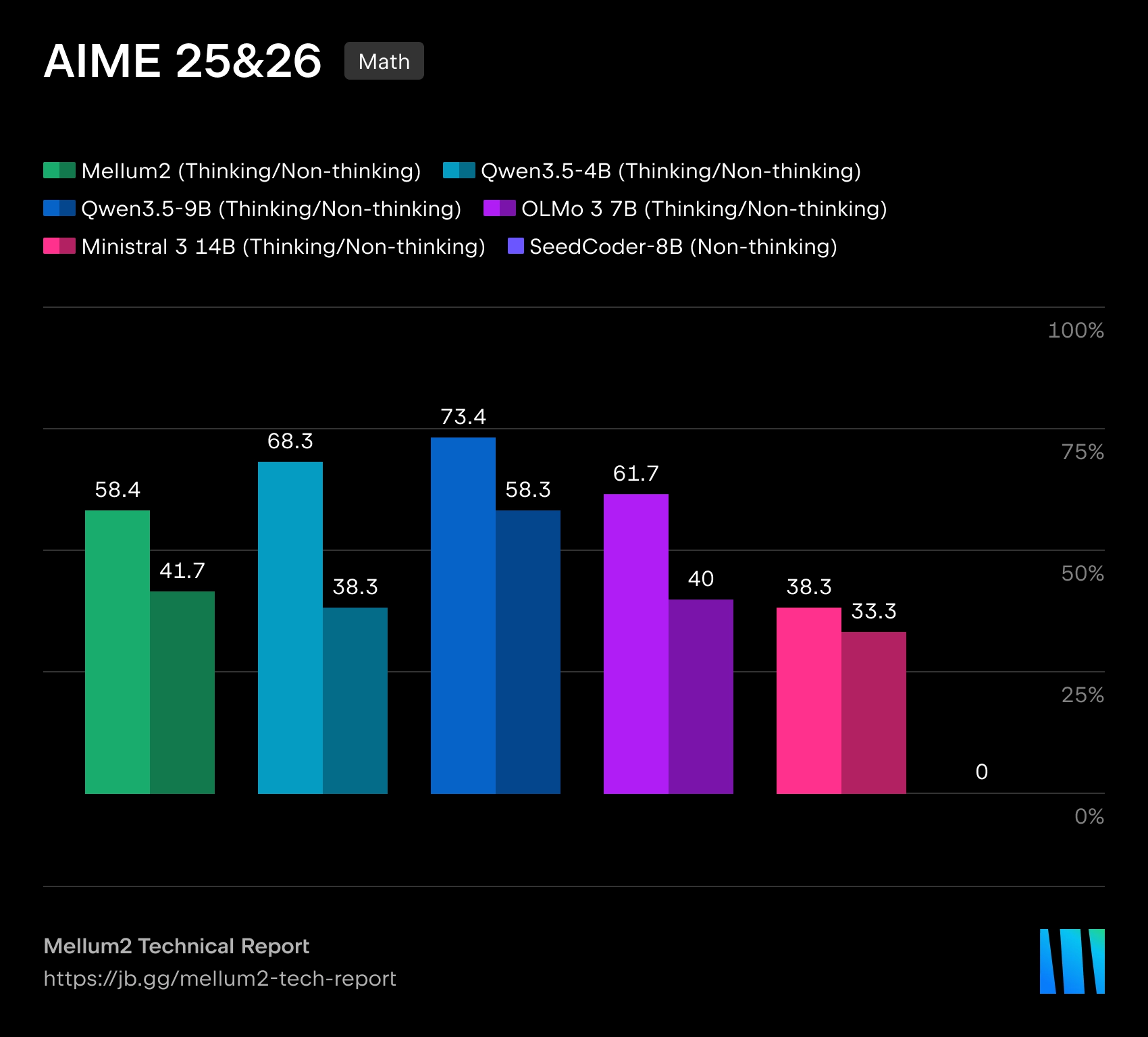
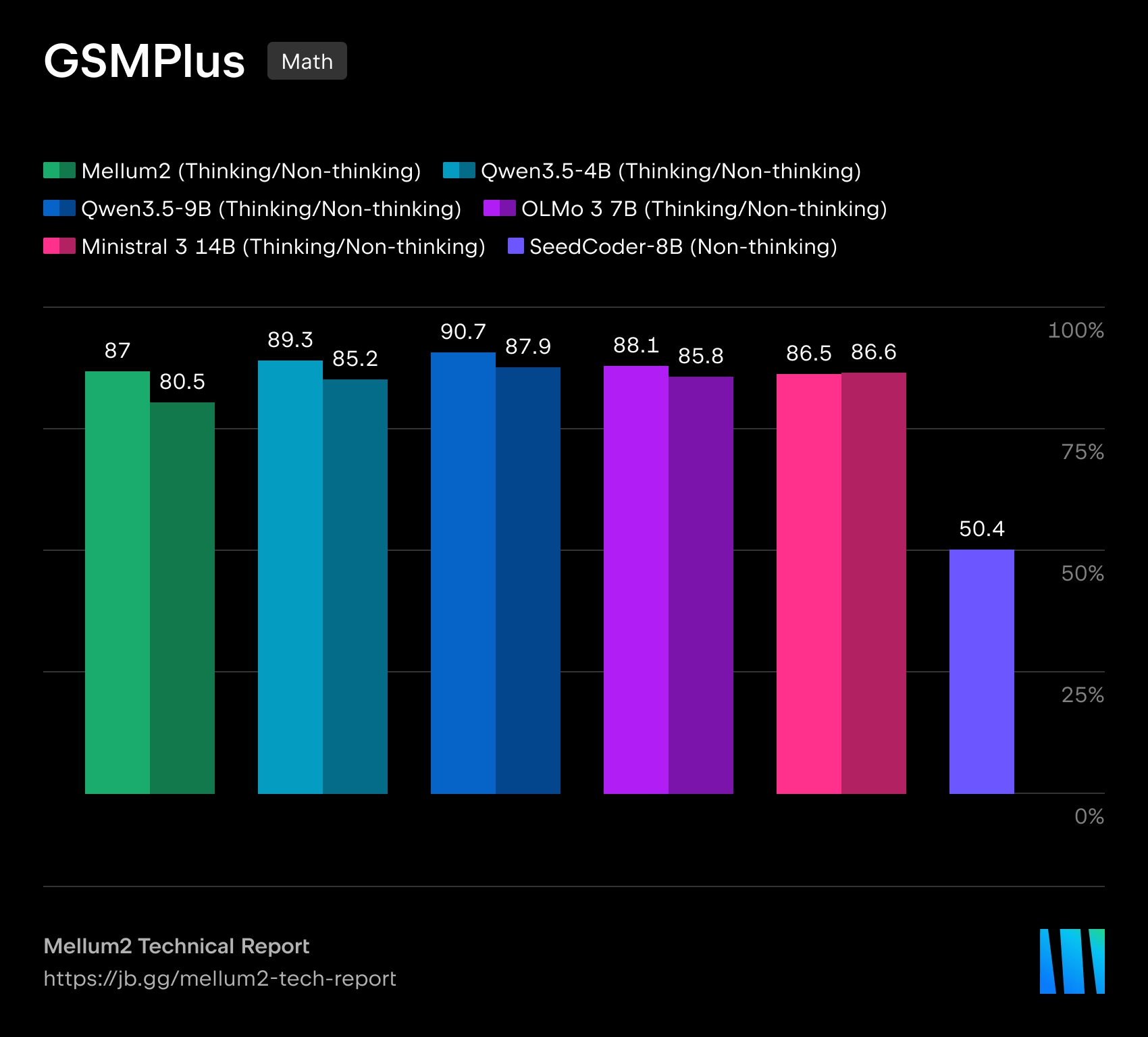
Mellum2 è costruito sull'architettura Miscela di espertiCon una dimensione totale di 12 miliardi di parametri Solo circa 1000 vengono attivati per ogni token 2.5 miliardi di parametri, il che dovrebbe ridurre i costi computazionali e la latenza durante l'inferenza. Secondo JetBrains, le prestazioni di riferimento del modello sono paragonabili a quelle di modelli open-source di dimensioni simili, ma offrono un'accelerazione dell'inferenza più che doppia.
JetBrains descrive Mellum2 come un'evoluzione del modello Mellum originale, inizialmente creato per il completamento automatico del codice. La nuova versione si estende a una classe più ampia di attività che richiedono di lavorare sia con il codice di programma che con il linguaggio naturale. L'azienda posiziona Mellum2 come un modello "focalizzato", non un sostituto dei grandi modelli di apprendimento per il linguaggio naturale di uso generale, ma un componente veloce e specializzato per operazioni intermedie frequenti all'interno di sistemi di intelligenza artificiale complessi.
Tra i casi d'uso proposti ci sono sono chiamati Classificazione e instradamento delle richieste tra modelli e strumenti, compressione ed elaborazione del contesto nei sistemi RAG, preparazione dei dati per gli agenti, pianificazione, validazione dei risultati intermedi ed esecuzione locale in ambienti in cui non è possibile inviare codice sorgente o dati interni ad API esterne.
Sul viso abbracciato pubblicato коллекция Mellum 2che include diverse varianti del modello: Thinking, Instruct, Thinking-SFT, Instruct-SFT, Base e Base-Pretrain. I modelli sono distribuiti nel formato Safetensors sotto licenza Apache 2.0.
Vengono forniti esempi di utilizzo tramite Transformers, vLLM, SGLang e Docker Model Runner per l'avvio.
Dal punto di vista tecnico, l'aspetto più interessante non è tanto la nascita dell'ennesimo modello open source, quanto la nicchia di mercato scelta da JetBrains. L'azienda non si concentra sulla competizione con i modelli generalisti più diffusi, bensì su componenti veloci ed economici che possono essere integrati direttamente in IDE, assistenti interni, sistemi RAG aziendali e pipeline di agenti. Per sviluppatori e aziende, questo si traduce nella possibilità di eseguire parte della logica di intelligenza artificiale in locale o sui propri server, mantenendo al contempo il controllo su codice, dati e costi di inferenza.
Fonte: linux.org.ru
