

NeurIPS () è la conferenza più grande al mondo su machine learning e intelligenza artificiale, ed è l'evento principale nel campo del deep learning.
Nello prossimo decennio, noi ingegneri DS, ci cimenteremo anche in biologia, linguistica e psicologia? Racconteremo nel nostro resoconto.

Quest'anno la conferenza ha radunato oltre 13.500 persone provenienti da 80 paesi a Vancouver (Canada). Sberbank rappresenta la Russia a questa conferenza da diversi anni — il team DS ha parlato dell'implementazione di ML nei processi bancari, delle competizioni di ML e delle opportunità offerte dalla piattaforma Sberbank DS. Quali sono state le principali tendenze del 2019 nella comunità ML? A raccontarlo sono i partecipanti alla conferenza: e .
Quest'anno a NeurIPS sono state accettate oltre 1.400 articoli — algoritmi, nuovi modelli e nuove applicazioni a nuovi dati.
Contenuto:
- Tendenze
- Interpretabilità dei modelli
- Multidisciplinarità
- Ragionamento
- RL
- GAN
- Principali Invited Talks
- “Social Intelligence”, Blaise Aguera y Arcas (Google)
- “Veridical Data Science”, Bin Yu (Berkeley)
- “Human Behavior Modeling with Machine Learning: Opportunities and Challenges”, Nuria M Oliver, Albert Ali Salah
- “From System 1 to System 2 Deep Learning”, Yoshua Bengio
Tendenze del 2019
1. Interpretabilità dei modelli e nuova metodologia ML
Il tema principale della conferenza è l'interpretazione e le prove del perché otteniamo determinati risultati. Si può discutere a lungo sull'importanza filosofica dell'interpretazione del "black box", ma sono emerse più metodologie reali e sviluppi tecnici in questo campo.
La metodologia di riproducibilità dei modelli e l'estrazione delle conoscenze da essi è un nuovo strumento della scienza. I modelli possono fungere da strumenti per acquisire nuove conoscenze e verificarle, e ogni fase di preprocessing, apprendimento e applicazione del modello deve essere riproducibile.
Una parte significativa delle pubblicazioni è dedicata non alla costruzione di modelli e strumenti, ma ai problemi di sicurezza, trasparenza e verificabilità dei risultati. In particolare, è emersa una nuova sessione dedicata agli attacchi ai modelli (adversarial attacks), includendo non solo attacchi durante l'addestramento, ma anche attacchi durante l'applicazione.
Articoli:
- — articolo software sulla metodologia di verifica dei modelli. Include una panoramica degli strumenti moderni per l'interpretazione dei modelli, in particolare l'uso dell'attention e l'ottenimento della feature importance tramite la “distillazione” delle reti neurali con modelli lineari.
- Chaofan Chen, Oscar Li, Daniel Tao, Alina Barnett, Cynthia Rudin, Jonathan K. Su
- Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
- Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, Danilo Jimenez Rezende
- Xiao Li, Yu Wang, Sumanta Basu, Karl Kumbier, Bin Yu
- Jaemin Yoo, Minyong Cho, Taebum Kim, U Kang
- Edward Raff
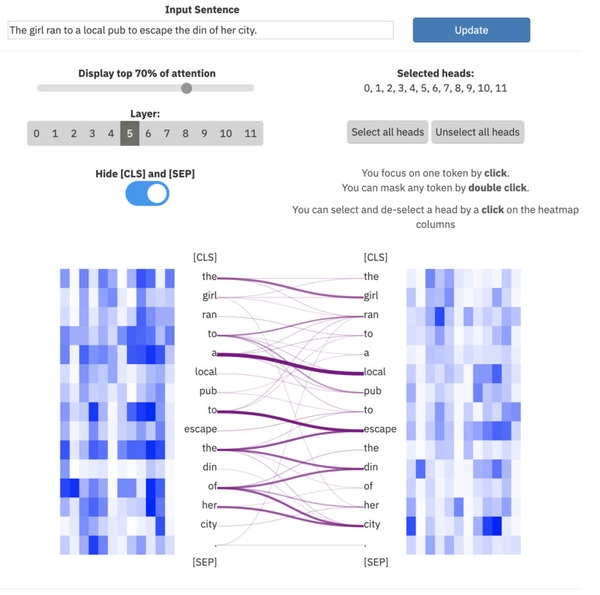
ExBert.net mostra l'interpretazione dei modelli per i compiti di elaborazione del testo
2. Multidisciplinarità
Per garantire una verifica affidabile e sviluppare meccanismi di controllo e aggiornamento delle conoscenze, sono necessari specialisti di settori correlati, dotati contemporaneamente di competenze in ML e nell'area di applicazione (medicina, linguistica, neuroscienze, educazione, ecc.). È particolarmente degno di nota il crescente numero di studi e presentazioni nel campo delle neuroscienze e delle scienze cognitive, con una convergenza tra specialisti e un interesse reciproco per le idee.
Oltre a questa convergenza, si preannuncia una multidisciplinarietà nella gestione congiunta di informazioni da diverse fonti: testo e foto, testo e giochi, database grafici + testo e foto.
Articoli:
- Neurobiologia + ML —
- VisualQA —
- RL + NLP —
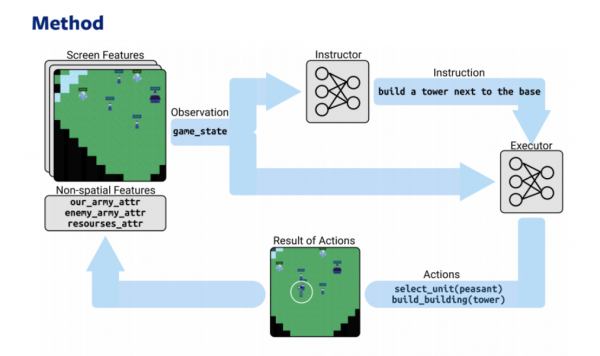
Due modelli — stratega e esecutore — sulla base di RL e NLP giocano a una strategia online
3. Ragionamento
L'ispirazione dell'intelligenza artificiale punta verso sistemi autoapprendenti, "consapevoli", capaci di ragionare e argomentare. In particolare, si sta sviluppando l'inferenza causale e il ragionamento di senso comune. Parte delle relazioni è dedicata al meta-apprendimento (su come imparare a imparare) e all'interconnessione delle tecnologie DL con la logica di primo e secondo ordine — il termine Intelligenza Artificiale Generale (AGI) sta diventando un termine comune negli interventi degli speaker.
Articoli:
- Weijiang Yu, Jingwen Zhou, Weihao Yu, Xiaodan Liang, Nong Xiao
- Wang-Zhou Dai, Qiuling Xu, Yang Yu, Zhi-Hua Zhou
- Vaishak Belle, Brendan Juba
- Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, Ross Girshick
- Dinesh Garg, Shajith Ikbal, Santosh K. Srivastava, Harit Vishwakarma, Hima Karanam, L Venkata Subramaniam
4. Apprendimento per Rinforzo
La maggior parte dei lavori continua a sviluppare le tradizionali direzioni dell'RL — DOTA2, Starcraft, l'integrazione delle architetture con la visione computerizzata, l'NLP, i database grafici.
Una giornata separata della conferenza è stata dedicata a un workshop sull'RL, dove è stata presentata l'architettura Optimistic Actor Critic Model, superiore a tutte le precedenti, in particolare la Soft Actor Critic.
Articoli:
- ; Kamil Ciosek, Quan Vuong, Robert Loftin, Katja Hofmann
- ; Yasuhiro Fujita (Preferred Networks, Inc.)*; Toshiki Kataoka (Preferred Networks, Inc.); Prabhat Nagarajan (Preferred Networks); Takahiro Ishikawa (Università di Tokyo) [external pdf link].
- ; Danijar Hafner (Google)*; Timothy Lillicrap (DeepMind); Jimmy Ba (Università di Toronto); Mohammad Norouzi (Google Brain)

I giocatori di StarCraft combattono contro il modello Alphastar (DeepMind)
5. GAN
Le reti generative rimangono ancora al centro dell'attenzione: molti lavori utilizzano i vanilla GAN per dimostrazioni matematiche, oltre a impiegarli in varianti nuove e insolite (modelli generativi basati su grafi, lavori con serie, applicazioni a relazioni causali nei dati, ecc.).
Articoli:
- Sangwoo Mo, Chiheon Kim, Sungwoong Kim, Minsu Cho, Jinwoo Shin
- Dan Zhang, Anna Khoreva
- Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, Kalyan Veeramachaneni
Poiché sono stati accettati più lavori qui di seguito parleremo delle presentazioni più importanti.
Talks Invitate
“Social Intelligence”, Blaise Aguera y Arcas (Google)
Il rapporto è dedicato alla metodologia generale del machine learning e alle prospettive che stanno cambiando il settore proprio ora: di fronte a quale bivio ci troviamo? Come funziona il cervello e l'evoluzione, e perché utilizziamo così poco ciò che già sappiamo sullo sviluppo dei sistemi naturali?
Lo sviluppo industriale del ML coincide in gran parte con le tappe evolutive della Google, che anno dopo anno pubblica le sue ricerche su NeurIPS:
- 1997 – avvio delle capacità di ricerca, primi server, potenza di calcolo limitata
- 2010 – Jeff Dean lancia il progetto Google Brain, l'inizio del boom delle reti neurali
- 2015 – implementazione industriale delle reti neurali, riconoscimento facciale rapido direttamente sul dispositivo locale, processori a basso livello progettati per calcoli tensoriali – TPU. Google lancia Coral ai – simile al raspberry pi, mini-computer per l'implementazione di reti neurali in installazioni sperimentali
- 2017 – Google inizia lo sviluppo dell'apprendimento decentralizzato e della fusione dei risultati dell'apprendimento delle reti neurali provenienti da diversi dispositivi in un unico modello – su Android
Oggi, un'intera industria si occupa della sicurezza dei dati, unendo e riproducendo i risultati dell'apprendimento sui dispositivi locali.
– il ramo del ML in cui singoli modelli apprendono in modo indipendente l'uno dall'altro, per poi essere uniti in un unico modello (senza centralizzare i dati originali), con aggiustamenti per eventi rari, anomalie, personalizzazione, ecc. Tutti i dispositivi Android fungono essenzialmente da un supercomputer di calcolo unico per Google.
I modelli generativi basati sul federated learning rappresentano, secondo Google, una direzione futura promettente che si trova "nella fase iniziale di crescita esponenziale". I GAN, secondo il relatore, sono capaci di apprendere a riprodurre il comportamento collettivo delle popolazioni di organismi viventi e algoritmi di pensiero.
L'esempio di due semplici architetture GAN dimostra che la ricerca del percorso di ottimizzazione gira in tondo, il che significa che non si verifica un'ottimizzazione vera e propria. Tuttavia, questi modelli simulano con successo esperimenti che i biologi conducono su popolazioni batteriche, costringendole ad apprendere nuove strategie comportamentali nella ricerca del cibo. Si può concludere che la vita funziona in modo diverso rispetto a una funzione di ottimizzazione.
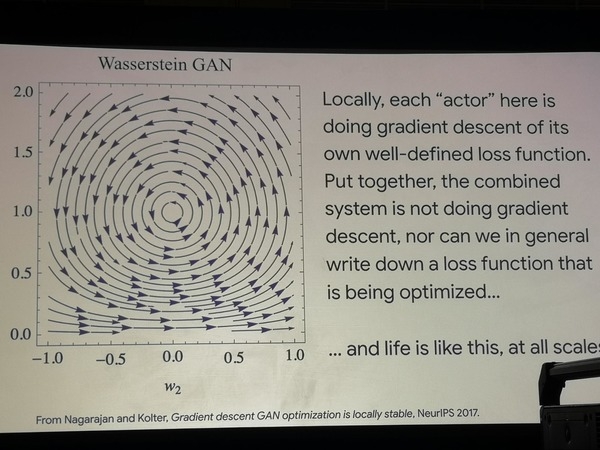
Ottimizzazione errante GAN
Tutto ciò che facciamo nell'ambito del machine learning attualmente sono compiti ristretti e altamente formalizzati, mentre queste formalizzazioni si generalizzano male e non corrispondono alla nostra conoscenza specialistica in settori come la neurofisiologia e la biologia.
Ciò che vale davvero la pena prendere in prestito dal campo della neurofisiologia nell'immediato futuro sono nuove architetture neuronali e una revisione dei meccanismi di retropropagazione dell'errore.
Il cervello umano stesso non apprende come una rete neurale:
- Non ha input primari casuali, inclusi quelli forniti tramite i sensi e durante l'infanzia.
- Ha una direzione innata di sviluppo istintivo (il desiderio di apprendere una lingua da parte del neonato, la postura eretta)
L'allenamento di un cervello individuale è un compito a basso livello; forse dovremmo considerare 'colonie' di individui in rapido cambiamento che si scambiano conoscenze per riprodurre i meccanismi dell'evoluzione di gruppo.
Cosa possiamo implementare negli algoritmi di ML già adesso:
- Applicare modelli di cell lineage che garantiscono l'apprendimento della popolazione, ma con una vita breve per l'individuo ('cervello individuale')
- Few-shot learning su un numero ridotto di esempi
- Strutture neuronali più complesse, funzioni di attivazione leggermente diverse
- Trasferire il 'genoma' alle generazioni successive – algoritmo di retropropagazione dell'errore
- Una volta che collegheremo neurofisiologia e reti neurali, impareremo a costruire un cervello multifunzionale da molteplici componenti.
Da questa prospettiva, la pratica delle soluzioni SOTA è dannosa e dovrebbe essere rivalutata in favore dello sviluppo di obiettivi comuni (benchmark).
“Veridical Data Science”, Bin Yu (Berkeley)
Il rapporto si concentra sul problema dell'interpretazione dei modelli di apprendimento automatico e sulla metodologia di verifica e validazione. Qualsiasi modello ML addestrato può essere visto come una fonte di conoscenza da cui è necessario estrarre informazioni.
In molti settori, specialmente in medicina, l'applicazione del modello è impossibile senza l'estrazione di queste conoscenze nascoste e l'interpretazione dei risultati del modello; altrimenti non saremo certi che i risultati siano stabili, non casuali, affidabili e non mettano a rischio la vita del paziente. Si sta sviluppando un'intera metodologia che opera all'interno della paradigma del deep learning e va oltre – la veridical data science. Di cosa si tratta?
Vogliamo raggiungere un tale livello di qualità nelle pubblicazioni scientifiche e nella riproducibilità dei modelli da garantire che siano:
- prevedibili
- calcolabili
- stabili
Questi tre principi costituiscono la base di una nuova metodologia. Come possiamo verificare i modelli ML rispetto a questi criteri? Il metodo più semplice è costruire modelli già interpretabili (regressioni, alberi decisionali). Tuttavia, desideriamo ottenere anche i benefici diretti del deep learning.
Alcuni metodi esistenti per affrontare il problema sono:
- interpretare il modello;
- utilizzare metodi basati sull'attenzione;
- utilizzare ensemble di algoritmi durante l'addestramento, e assicurarsi che i modelli lineari interpretabili apprendano a prevedere le stesse risposte delle reti neurali, interpretando le caratteristiche dalla linea del modello;
- modificare e aumentare i dati per l'addestramento. Questo include l'aggiunta di rumore, disturbi e data augmentation;
- qualsiasi metodo che consenta di verificare che i risultati del modello non siano casuali e non dipendano da lievi perturbazioni indesiderate (adversarial attacks);
- interpretare il modello post-fattum, dopo l'addestramento;
- esaminare i pesi delle caratteristiche in vari modi;
- esaminare le probabilità di tutte le ipotesi, la distribuzione delle classi.

Adversarial attack
Gli errori di modellazione costano caro a tutti: un chiaro esempio è il lavoro di Reinhart e Rogoff "" che ha influenzato la politica economica di molti paesi europei e costretto ad adottare politiche di austerità, ma un attento riesame dei dati e del loro trattamento anni dopo ha rivelato risultati opposti!
Ogni tecnologia di ML ha il proprio ciclo di vita, dall'implementazione al rilascio. L'obiettivo della nuova metodologia è quello di effettuare verifiche su tre principi fondamentali ad ogni fase della vita del modello.
Risultati:
- Si stanno sviluppando diversi progetti che aiuteranno i modelli di ML a diventare più affidabili. Ad esempio, deeptune (link to: );
- Per lo sviluppo futuro della metodologia è necessario migliorare significativamente la qualità delle pubblicazioni nel campo del ML;
- Il machine learning ha bisogno di leader con una preparazione multidisciplinare e competenze sia in ambito tecnico che umanistico.
“Human Behavior Modeling with Machine Learning: Opportunities and Challenges” Nuria M Oliver, Albert Ali Salah
Una lezione dedicata alla modellazione del comportamento umano, alle sue basi tecnologiche e alle prospettive di applicazione.
La modellazione del comportamento umano può essere suddivisa in:
- comportamento individuale
- comportamento di piccoli gruppi
- comportamento di massa
Ognuno di questi tipi può essere modellato utilizzando il ML, ma con informazioni e caratteristiche di input completamente diverse. Ogni tipo presenta anche le proprie problematiche etiche, che ogni progetto deve affrontare:
- comportamento individuale – furto di identità, deepfake;
- comportamento di gruppi di persone – de-anonimizzazione, ottenimento di informazioni su spostamenti, telefonate, ecc.;
Comportamento individuale
Riguarda principalmente il tema della Computer Vision – riconoscimento delle emozioni umane e delle reazioni. Può avvenire solo nel contesto, nel tempo o con una scala relativa alla variabilità delle proprie emozioni. Nella diapositiva – riconoscimento delle emozioni della Gioconda utilizzando il contesto dallo spettro emotivo delle donne mediterranee. Risultato: sorriso di gioia, ma con disprezzo e disgusto. La ragione è probabilmente nel modo tecnico di definire l'emozione "neutra".
Comportamento di un piccolo gruppo di persone
Attualmente è il peggio modellato a causa della scarsità di informazioni. Come esempio sono stati mostrati lavori del 2018 – 2019 su decine di persone X decine di video (cfr. set di dati di immagini 100k++). Per una modellazione ottimale in questa attività, è necessaria un'informazione multimodale, preferibilmente da sensori sul corpo – altimetro, termometro, registrazione con microfono, ecc.
Comportamento di massa
Questo è il settore più avanzato, poiché i clienti includono l'ONU e molti stati. Telecamere di sorveglianza esterne, dati dalle torri telefoniche – fatturazione, SMS, chiamate, dati sul movimento oltre i confini nazionali – forniscono tutte informazioni molto affidabili sui flussi di persone e sulle instabilità sociali. Applicazioni potenziali della tecnologia: ottimizzazione delle operazioni di salvataggio, assistenza e evacuazione tempestiva della popolazione in caso di emergenze. I modelli utilizzati sono per lo più difficili da interpretare in questo momento: si tratta di vari LSTM e reti neurali convoluzionali. È stata fatta una breve osservazione che l'ONU sta spingendo per una nuova legge che obbligherà le aziende europee a condividere dati anonimizzati necessari per qualsiasi ricerca.
“From System 1 to System 2 Deep Learning”, Yoshua Bengio
Nella lezione di Yoshua Bengio, l'apprendimento profondo incontra le neuroscienze a livello di definizione degli obiettivi.
Bengio identifica due principali tipi di compiti secondo la metodologia del premio Nobel Daniel Kahneman (libro “» )
tipo 1 — Sistema 1, azioni inconsce che realizziamo «automaticamente» (cervello primordiale): guidare l'auto in luoghi familiari, camminare, riconoscere volti.
Tipo 2 — Sistema 2, azioni consapevoli (corteccia cerebrale), definizione degli obiettivi, analisi, pensiero, compiti complessi.
L'IA ha finora raggiunto alti livelli solo in compiti di tipo uno, mentre il nostro compito è portarla al secondo, insegnandole a eseguire operazioni multidisciplinari e a operare con logica e abilità cognitive avanzate.
Per raggiungere questo obiettivo si propone:
- di utilizzare l'attenzione nei compiti di NLP come meccanismo chiave per modellare il pensiero
- di impiegare il meta-apprendimento e l'apprendimento delle rappresentazioni per meglio modellare le caratteristiche che influenzano la coscienza e la loro localizzazione, e basandosi su di esse passare a operare con concetti di livello superiore.
In conclusione, lasciamo una registrazione della presentazione: Benjiro — uno dei molti ricercatori che cercano di espandere l'ambito del ML oltre i problemi di ottimizzazione, SOTA e nuove architetture.
Rimane aperta la questione su quanto la connessione tra i problemi della coscienza, l'influenza del linguaggio sul pensiero, la neurobiologia e gli algoritmi sia ciò che ci attende in futuro e ci permetterà di passare a macchine che "pensano" come gli esseri umani.
Grazie!

Fonte: habr.com
