


מבוסס על המצגות שלי ב-Highload++ וב-DataFest מינסק 2019.
עבור רבים כיום, דואר הוא חלק בלתי נפרד מהחיים המקוונים. בעזרתו אנו מנהלים התכתבויות עסקיות, מאחסנים כל מיני מידע חשוב הקשור לפיננסים, הזמנות מלונות, עיבוד הזמנות ועוד. באמצע 2018 גיבשנו אסטרטגיית מוצר לפיתוח דואר. כיצד אמור להיראות דואר מודרני?
הדואר חייב להיות לִכאוֹב, כלומר, לעזור למשתמשים לנווט בכמות המידע ההולכת וגדלה: לסנן, לבנות ולהציג אותו בצורה הנוחה ביותר. זה צריך להיות שימושי, המאפשר לך לפתור בעיות שונות ישירות בתיבת הדואר שלך, למשל, לשלם קנסות (פונקציה שאני, למרבה הצער, משתמש בה). ובמקביל, כמובן, דואר צריך לספק הגנה על מידע, ניתוק דואר זבל והגנה מפני פריצות, כלומר, להיות בטוח.
תחומים אלה מגדירים מספר משימות מרכזיות, שרבות מהן ניתנות לפתרון ביעילות באמצעות למידת מכונה. להלן דוגמאות לתכונות קיימות שפותחו במסגרת האסטרטגיה - אחת לכל תחום.
- תשובה חכמהלדואר יש פונקציית מענה חכם. הרשת הנוירונים מנתחת את טקסט המכתב, מבינה את משמעותו ומטרתו, וכתוצאה מכך מציעה שלוש אפשרויות תגובה מתאימות ביותר: חיובית, שלילית וניטרלית. זה עוזר לחסוך הרבה זמן בעת מענה למכתבים, וגם לעתים קרובות להגיב בצורה לא שגרתית ומשעשעת עבור עצמך.
- קיבוץ אותיות, הקשור להזמנות בחנויות מקוונות. אנו מבצעים רכישות רבות באינטרנט, וככלל, חנויות יכולות לשלוח מספר מכתבים עבור כל הזמנה. לדוגמה, AliExpress, השירות הגדול ביותר, שולח הרבה מכתבים עבור הזמנה אחת, וחישבנו שבמקרה הסופי מספרם יכול להגיע ל-29. לכן, באמצעות מודל Named Entity Recognition, אנו מחלצים את מספר ההזמנה ומידע נוסף מהטקסט ומקבצים את כל האותיות לשרשור אחד. אנו מציגים גם את המידע העיקרי על ההזמנה בתיבה נפרדת, מה שמקל על העבודה עם סוג זה של מכתבים.

- אנטי פישינגפישינג הוא סוג מסוכן במיוחד של דוא"ל הונאה, שבעזרתו מנסים תוקפים להשיג מידע פיננסי (כולל על כרטיסי האשראי של המשתמש) ופרטי התחברות. דוא"ל כזה מחקה הודעות דוא"ל אמיתיות שנשלחות על ידי השירות, כולל מבחינה ויזואלית. לכן, בעזרת Computer Vision, אנו מזהים את הלוגואים והסגנון של הודעות דוא"ל מחברות גדולות (לדוגמה, Mail.ru, Sber, Alfa) ולוקחים זאת בחשבון יחד עם הטקסט ותכונות אחרות בסוויגי הספאם והפישינג שלנו.
למידת מכונה
קצת על למידת מכונה בדואר באופן כללי. דואר הוא מערכת עמוסה מאוד: בממוצע, 1,5 מיליארד מכתבים עוברים דרך השרתים שלנו ביום עבור 30 מיליון משתמשי DAU. כל הפונקציות והתכונות הדרושות נתמכות על ידי כ-30 מערכות למידת מכונה.
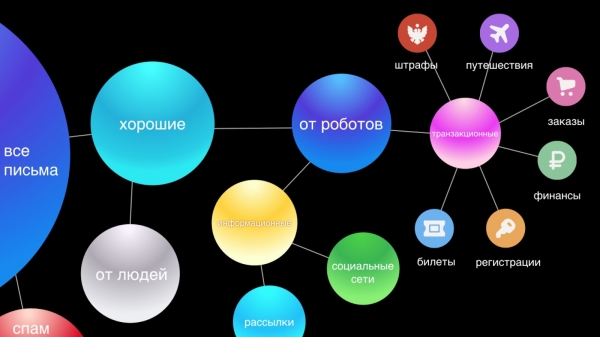
כל מכתב עובר דרך מסוע סיווג שלם. ראשית, אנו מסננים ספאם ומשאירים מכתבים טובים. משתמשים לעיתים קרובות אינם שמים לב לעבודת מערכת האנטי-ספאם, מכיוון ש-95-99% מהספאם אפילו לא מגיע לתיקייה המתאימה. זיהוי ספאם הוא חלק חשוב מאוד במערכת שלנו, והקשה ביותר, שכן בתחום האנטי-ספאם ישנה הסתגלות מתמדת בין מערכות הגנה ותקיפה, מה שמספק אתגר הנדסי מתמשך לצוות שלנו.
בשלב הבא, אנו מפרידים בין מכתבים לאנשים לבין רובוטים. מכתבים מאנשים הם החשובים ביותר, לכן אנו מספקים עבורם פונקציות כמו תשובה חכמה. מכתבים מרובוטים מחולקים לשני חלקים: חלקים עסקיים - אלו הם מכתבים חשובים משירותים, למשל, אישור רכישות או הזמנות מלון, חלקים פיננסיים, וחלקים אינפורמטיביים - זהו פרסום עסקי, הנחות.
אנו מאמינים שאימיילים עסקיים חשובים לא פחות מהתכתבויות אישיות. הם צריכים להיות בהישג יד, כי לעתים קרובות אנו צריכים למצוא במהירות מידע על הזמנה או הזמנת טיסה, ואנחנו משקיעים זמן בחיפוש אחר אימיילים אלה. לכן, לנוחיותנו, אנו מחלקים אותם אוטומטית לשש קטגוריות עיקריות: נסיעות, הזמנות, כספים, כרטיסים, הרשמות ולבסוף, קנסות.
מכתבי מידע הם הקבוצה הרבים ביותר וכנראה הפחות חשובה, שאינם דורשים תגובה מיידית, מכיוון ששום דבר משמעותי לא ישתנה בחיי המשתמש אם הוא לא יקרא מכתב כזה. בממשק החדש שלנו, אנו מקצצים אותם לשני שרשורים: רשתות חברתיות וניוזלטרים, ובכך מנקים ויזואלית את תיבת הדואר הנכנס ומשאירים רק מכתבים חשובים בטווח ראייה.
ניצול
מספר רב של מערכות גורמות לקשיים רבים בתפעול. אחרי הכל, מודלים מתדרדרים עם הזמן, כמו כל תוכנה: תכונות נשברות, מכונות כושלות, קוד עקום מופעל. בנוסף, נתונים משתנים כל הזמן: נתונים חדשים מתווספים, דפוסי התנהגות משתמשים משתנים וכו', כך שמודל ללא תמיכה מתאימה יעבוד גרוע יותר ויותר עם הזמן.
אסור לנו לשכוח שככל שלמידת מכונה חודרת עמוק יותר לחייהם של המשתמשים, כך גדלה ההשפעה שלהם על המערכת האקולוגית, וכתוצאה מכך, כך שחקני השוק יכולים לספוג יותר הפסדים או רווחים כספיים. לכן, ביותר ויותר תחומים, שחקנים מסתגלים לעבודתם של אלגוריתמי למידת מכונה (דוגמאות קלאסיות הן פרסום, חיפוש ואנטי-ספאם שכבר הוזכר).
גם למשימות למידת מכונה יש ייחודיות: כל שינוי במערכת, אפילו קטן, יכול לייצר עבודה רבה עם המודל: עבודה עם נתונים, אימון מחדש, פריסה, שיכולים להימשך שבועות או חודשים. לכן, ככל שהסביבה שבה המודלים שלכם משתנה מהר יותר, כך התמיכה שלהם דורשת יותר מאמץ. הצוות יכול ליצור מערכות רבות ולשמוח על כך, ואז להשקיע כמעט את כל המשאבים בתמיכה שלו, מבלי יכולת לעשות משהו חדש. פעם נתקלנו במצב כזה בצוות אנטי-ספאם. והגענו למסקנה ברורה שיש לאוטומט את התמיכה.
אוטומציה
מה ניתן להפוך לאוטומטי? כמעט הכל, למעשה. זיהיתי ארבעה תחומים המגדירים את תשתית למידת המכונה:
- איסוף נתונים;
- הכשרה נוספת;
- לִפְרוֹס;
- בדיקות וניטור.
אם הסביבה אינה יציבה ומשתנה כל הזמן, אז כל התשתית סביב המודל חשובה הרבה יותר מהמודל עצמו. זה יכול להיות מסווג ליניארי טוב וישן, אבל אם תזינו אותו עם התכונות הנכונות ותגדירו משוב טוב מהמשתמשים, הוא יעבוד הרבה יותר טוב ממודלים חדישים עם כל הפעמונים והשריקות.
לולאת משוב
מחזור זה משלב איסוף נתונים, הכשרה נוספת ופריסה - למעשה כל מחזור עדכון המודל. מדוע זה חשוב? התבונן בלוח הזמנים של רישום הדואר:
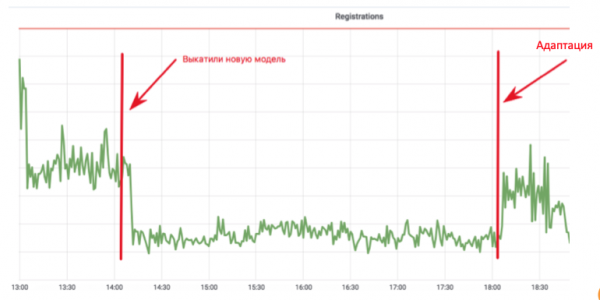
מפתח למידת מכונה יישם מודל אנטי-בוטים שמונע מבוטים להירשם בדואר. הגרף יורד לערך שבו נותרים רק משתמשים אמיתיים. הכל נהדר! אבל ארבע שעות חולפות, מפעילי הבוטים משנים את הסקריפטים שלהם, והכל חוזר לקדמותו. במימוש זה, המפתח בילה חודש בהוספת תכונות ואימון מחדש של המודל, אך שולח הספאם הצליח להסתגל תוך ארבע שעות.
כדי להימנע מכאב בלתי נסבל שכזה וכדי להימנע מלעשות הכל מחדש מאוחר יותר, עלינו לחשוב בתחילה כיצד תיראה לולאת המשוב ומה נעשה אם הסביבה תשתנה. נתחיל באיסוף נתונים - זהו הדלק לאלגוריתמים שלנו.
איסוף נתונים
ברור שככל שיש יותר נתונים ברשתות נוירונים מודרניות, כך ייטב, והם למעשה נוצרים על ידי משתמשי המוצר. משתמשים יכולים לעזור לנו על ידי תיוג הנתונים, אבל אנחנו לא יכולים לנצל זאת לרעה, כי בשלב מסוים משתמשים יתעייפו מאימון המודלים שלכם והם יעברו למוצר אחר.
אחת הטעויות הנפוצות ביותר (אני מתייחס כאן לאנדרו נג) היא התמקדות יתרה במדדים של מערך הנתונים של הבדיקה, במקום במשוב המשתמש, שהוא למעשה המדד העיקרי לאיכות העבודה, מכיוון שאנחנו יוצרים מוצר עבור המשתמש. אם המשתמש לא מבין או לא אוהב את עבודת המודל, אז הכל לשווא.
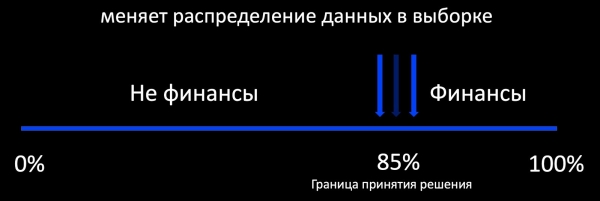
לכן, למשתמש צריכה להיות תמיד אפשרות להצביע, עלינו לתת לו כלי למשוב. אם נחשוב שהגיע לתיבת הדואר מכתב שקשור לפיננסים, עלינו לסמן אותו כ"פיננסים" ולצייר כפתור שהמשתמש יכול ללחוץ עליו ולומר שזה לא פיננסים.
איכות המשוב
בואו נדבר על איכות משוב המשתמשים. ראשית, אתם והמשתמש עשויים לשים משמעויות שונות למושג אחד. לדוגמה, אתם ומנהלי המוצר מאמינים ש"כספים" הם מכתבים מהבנק, והמשתמש מאמין שמכתב מסבתא על הפנסיה שלה קשור גם לכספים. שנית, ישנם משתמשים שאוהבים ללחוץ על כפתורים ללא כל היגיון. שלישית, המשתמש עלול לטעות עמוקות במסקנותיו. דוגמה בולטת מהפרקטיקה שלנו היא יישום של מסווג. , סוג מצחיק מאוד של ספאם, כאשר מוצע למשתמש לקחת כמה מיליוני דולרים מקרוב משפחה רחוק שנמצא לפתע באפריקה. לאחר הטמעת מסווג זה, בדקנו את הקליקים על "לא ספאם" במכתבים אלה, והתברר ש-80% מהם הם ספאם ניגרי עסיסי, מה שמרמז על כך שמשתמשים יכולים להיות תמימים ביותר.
ובואו לא נשכח שלא רק אנשים יכולים ללחוץ על כפתורים, אלא גם בוטים שמתחזים לדפדפן. לכן משוב גולמי אינו טוב ללמידה. מה אפשר לעשות עם המידע הזה?
אנו משתמשים בשתי גישות:
- משוב מה-ML המשויךלדוגמה, יש לנו מערכת אנטי-בוטים מקוונת, שכפי שכבר הזכרתי, מקבלת החלטה מהירה על סמך מספר מוגבל של תכונות. וישנה מערכת שנייה, איטית, שעובדת לאחר מעשה. יש לה יותר נתונים על המשתמש, התנהגותו וכו'. כתוצאה מכך, מתקבלת ההחלטה המאוזנת ביותר, ובהתאם יש לה דיוק ושלמות גבוהים יותר. ניתן לכוון את ההבדל בעבודתן של מערכות אלו למערכת הראשונה כנתוני אימון. לפיכך, המערכת הפשוטה יותר תמיד תנסה להתקרב לביצועים של המערכת המורכבת יותר.
- סיווג קליקיםניתן פשוט לסווג כל קליק של משתמש, להעריך את תוקפו ואת השימושיות שלו. אנו עושים זאת במודל אנטי-ספאם בדואר, באמצעות תכונות משתמש, היסטוריית המשתמש שלו, תכונות השולח, הטקסט עצמו ותוצאת המסווגים. כתוצאה מכך, אנו מקבלים מערכת אוטומטית המאמתת משוב משתמשים. ומכיוון שצריך לאמן אותה מחדש בתדירות נמוכה הרבה יותר, עבודתה יכולה להפוך לעיקרית עבור כל המערכות האחרות. העדיפות העיקרית במודל זה היא דיוק, מכיוון שאימון מודל על נתונים לא מדויקים כרוך בתוצאות.
בזמן שאנחנו מנקים את הנתונים ומאמנים את מערכות ה-ML שלנו, אסור לנו לשכוח את המשתמשים, כי עבורנו, אלפי, מיליוני שגיאות בגרף הן סטטיסטיקה, ועבור המשתמש, כל באג הוא טרגדיה. בנוסף לעובדה שהמשתמש צריך איכשהו לחיות עם השגיאה שלו במוצר, לאחר משוב, הוא מצפה לחריג ממצב כזה בעתיד. לכן, תמיד כדאי לתת למשתמשים לא רק את ההזדמנות להצביע, אלא גם לתקן את התנהגות מערכות ה-ML, ליצור, למשל, היוריסטיקות אישיות עבור כל קליק על משוב, במקרה של דואר, זו יכולה להיות היכולת לסנן מכתבים כאלה לפי שולח ותואר עבור משתמש זה.
כמו כן, יש צורך להשתמש בכמה דוחות או בקשות תמיכה כדי לכוונן את המודל במצב חצי אוטומטי או ידני, כך שמשתמשים אחרים לא יסבלו מבעיות דומות.
היוריסטיקות ללמידה
ישנן שתי בעיות עם היוריסטיקות וקביים אלה. הראשונה היא שמספר הקביים ההולך וגדל קשה לתחזוקה, שלא לדבר על איכותם וביצועיהם למרחקים ארוכים. הבעיה השנייה היא שהשגיאה עשויה להיות לא תכופה, וכמה לחיצות לאימון מחדש של המודל לא יספיקו. נראה שניתן למתן משמעותית את שתי ההשפעות שאינן קשורות זו לזו על ידי יישום הגישה הבאה.
- בואו ניצור קביים זמניים.
- אנחנו שולחים ממנו נתונים למודל, הוא עובר אימונים באופן קבוע, כולל על הנתונים שהתקבלו. כאן, כמובן, חשוב שההיוריסטיקות יהיו בעלות דיוק גבוה, כדי לא לפגוע באיכות הנתונים במערך האימונים.
- לאחר מכן הגדרנו ניטור כדי שהקב יפעל, ואם לאחר זמן מה הקב כבר לא יעבוד והוא מכוסה לחלוטין על ידי המודל, נוכל להסיר אותו בבטחה. כעת, סביר להניח שהבעיה הזו לא תחזור על עצמה.
אז צבא של קביים הוא מאוד שימושי. העיקר הוא ששירותם זמני, לא קבוע.
הכשרה נוספת
אימון מחדש הוא תהליך של הוספת נתונים חדשים, המתקבלים ממשוב ממשתמשים או ממערכות אחרות, ואימון מודל קיים עליו. ישנן מספר בעיות באימון מחדש:
- ייתכן שהמודל פשוט לא תומך בהכשרה נוספת, אלא בלמידה רק מאפס.
- בשום מקום בספר הטבע לא כתוב שהכשרה נוספת תשפר בהכרח את איכות העבודה בייצור. לעתים קרובות, קורה ההפך, כלומר, רק הידרדרות אפשרית.
- שינויים יכולים להיות בלתי צפויים. זוהי נקודה עדינה למדי שזיהינו בעצמנו. גם אם מודל חדש בבדיקת A/B מציג תוצאות דומות בהשוואה למודל הנוכחי, אין זה אומר שהוא יעבוד באופן זהה. עבודתם יכולה להיות שונה בכאחוז אחד, מה שיכול להביא שגיאות חדשות או להחזיר שגיאות ישנות שכבר תוקנו. גם אנחנו וגם המשתמשים כבר יודעים איך לחיות עם שגיאות קיימות, וכאשר מספר רב של שגיאות חדשות צצות, ייתכן שהמשתמש גם לא יבין מה קורה, כי הוא מצפה להתנהגות צפויה.
לכן, הדבר החשוב ביותר באימון מחדש הוא להבטיח שהמודל ישתפר, או לפחות לא יחמיר.
הדבר הראשון שעולה בראש כשאנחנו מדברים על אימון נוסף הוא גישת הלמידה האקטיבית. מה המשמעות של זה? לדוגמה, מסווג קובע האם אות קשורה לפיננסים, וסביב גבול ההחלטה שלה אנו מוסיפים דגימה של דוגמאות מתויגות. זה עובד היטב, למשל, בפרסום, שבו יש הרבה משוב וניתן לאמן את המודל באינטרנט. אבל אם יש מעט משוב, אז אנחנו מקבלים דגימה מוטה מאוד יחסית להתפלגות נתוני הייצור, שעל סמך זה בלתי אפשרי להעריך את התנהגות המודל במהלך הפעולה.
למעשה, המטרה שלנו היא לשמר דפוסים ישנים, מודלים ידועים, ולרכוש חדשים. המשכיות חשובה כאן. המודל שלעתים קרובות יישמנו בקושי רב כבר עובד, כך שאנחנו יכולים להתמקד בביצועיו.
מודלים שונים משמשים בדואר: עצים, רשתות לינאריות ורשתות עצביות. עבור כל אחד מהם, אנו יוצרים אלגוריתם משלנו לאימון נוסף. בתהליך האימון הנוסף, אנו מקבלים לא רק נתונים חדשים, אלא לעתים קרובות גם תכונות חדשות, אותן ניקח בחשבון בכל האלגוריתמים להלן.
מודלים ליניאריים
נניח שיש לנו רגרסיה לוגיסטית. אנו מרכיבים את מודל ההפסד מהרכיבים הבאים:
- LogLoss על נתונים חדשים;
- אנו מסדירים את המשקלים של מאפיינים חדשים (אנו משאירים את הישנים ללא שינוי);
- אנו לומדים מנתונים ישנים כדי לשמר דפוסים ישנים;
- ואולי, הדבר הכי חשוב: אנחנו תולים רגולריזציה הרמונית, מה שמבטיח לא שינוי חזק במשקלים יחסית למודל הישן לפי הנורמה.
מכיוון שלכל רכיב של הפסד יש מקדמים, נוכל לבחור את הערכים האופטימליים עבור המשימה שלנו באמצעות אימות צולב או על סמך דרישות המוצר.
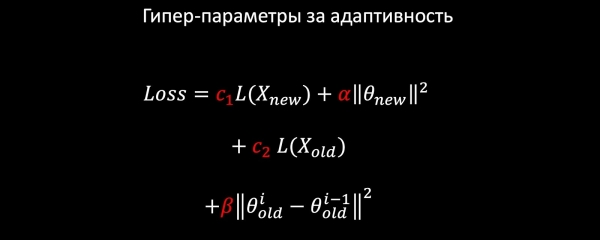
Деревья
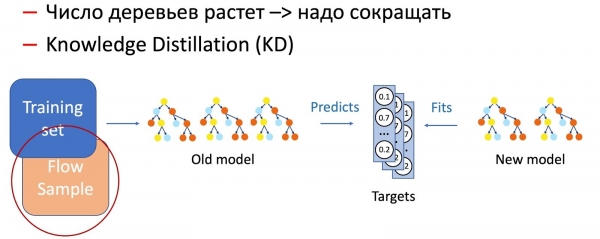
בואו נעבור לעצי החלטה. הגענו לאלגוריתם הבא לאימון מחדש של עצי החלטה:
- הייצור מפעיל יער של 100-300 עצים, שאומנו על בסיס קבוצת הנתונים הישנה.
- אנו מסירים M = 5 חלקים בסוף ומוסיפים 2M = 10 חדשים, שאומנו על כל מערך הנתונים, אך עם משקל גבוה לנתונים חדשים, מה שמבטיח באופן טבעי שינוי הדרגתי במודל.
ברור שעם הזמן מספר העצים גדל מאוד, ויש צורך לצמצם אותם מעת לעת על מנת לעמוד בלוחות הזמנים. לשם כך, אנו משתמשים בזיקוק הידע (KD), הנפוץ כיום. בקצרה על עקרון פעולתו.
- יש לנו מודל "מורכב" נוכחי. אנו מריצים אותו על מערך הנתונים של האימון ומקבלים את התפלגות ההסתברות של מחלקות הפלט.
- לאחר מכן, אנו מאמנים את מודל הסטודנט (המודל עם פחות עצים במקרה זה) לשכפל את ביצועי המודל באמצעות התפלגות המחלקה כמשתנה היעד.
- חשוב לציין כאן שאיננו משתמשים בשום תיוג של מערך נתונים, ולכן אנו יכולים להשתמש בנתונים שרירותיים. כמובן, אנו משתמשים במדגם של נתוני הייצור כקבוצת אימון עבור מודל הסטודנט. לפיכך, קבוצת האימון מאפשרת לנו להבטיח את דיוק המודל, והדגימה של הזרם מבטיחה ביצועים דומים בהתפלגות הייצור, ומפצה על ההטיה של קבוצת האימון.
השילוב של שתי טכניקות אלו (הוספת עצים והפחתה תקופתית של מספרם באמצעות זיקוק ידע) מבטיח הכנסת דפוסים חדשים והמשכיות מלאה.
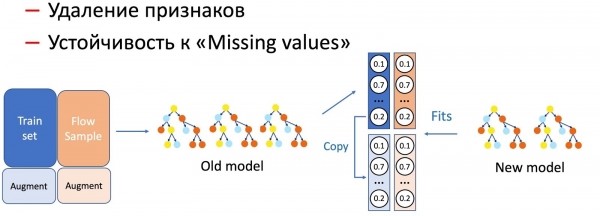
עם KD, אנו מבצעים גם הבחנה בין פעולות עם תכונות מודל, כגון הסרת תכונות ועבודה עם פערים. במקרה שלנו, יש לנו מספר תכונות סטטיסטיות חשובות (לפי שולחים, hashes של טקסט, כתובות URL וכו') המאוחסנות במסד נתונים ויש להן נטייה להיכשל. המודל, כמובן, אינו מוכן לפיתוח כזה, מכיוון שאין מצבי כשל במערך האימון. במקרים כאלה, אנו משלבים KD וטכניקות הרחבה: כאשר אנו מאמנים חלק מהנתונים, אנו מסירים או מאפסים את התכונות הדרושות, ולוקחים את התוויות המקוריות (פלטים של המודל הנוכחי), מודל הסטודנט לומד לחזור על התפלגות זו.
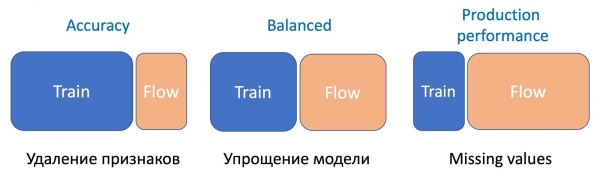
שמנו לב שככל שמתרחשת מניפולציה רצינית יותר של המודל, כך אחוז דגימות הזרימה הנדרש גבוה יותר.
הסרת תכונות, הפעולה הפשוטה ביותר, דורשת רק חלק קטן מהזרימה, מכיוון שרק מספר תכונות משתנות, והמודל הנוכחי אומן על אותו סט - ההבדל מינימלי. פישוט המודל (הפחתת מספר העצים מספר פעמים) דורש יחס של 50/50. והחמצת תכונות סטטיסטיות חשובות שמשפיעות קשות על ביצועי המודל דורשת זרימה רבה עוד יותר כדי ליישר את עבודת המודל החדש, עמידה בפני השמטות, על כל סוגי האותיות.
FastText
בואו נעבור ל-FastText. הרשו לי להזכיר לכם שהייצוג (Embedding) של מילה מורכב מסכום ההטמעה של המילה עצמה וכל האותיות N שלה, בדרך כלל טריגרמות. מכיוון שיכולות להיות לא מעט טריגרמות, משתמשים ב-Bucket Hashing, כלומר, טרנספורמציה של המרחב כולו ל-hashmap קבוע מסוים. כתוצאה מכך, מתקבלת מטריצת המשקל עם ממד השכבה הפנימית במספר המילים + הדליים.
במהלך אימון מחדש, מופיעים מאפיינים חדשים: מילים וטריגרמות. באימון מחדש הסטנדרטי מפייסבוק, שום דבר משמעותי לא קורה. רק משקלים ישנים עם אנטרופיה צולבת על נתונים חדשים מאומנים מחדש. לכן, מאפיינים חדשים אינם בשימוש, כמובן, לגישה זו יש את כל החסרונות שתוארו לעיל הקשורים לחוסר הוודאות של המודל בייצור. לכן, שיפרנו מעט את FastText. אנו מוסיפים את כל המשקלים החדשים (מילים וטריגרמות), מאמנים מחדש את כל המטריצה עם אנטרופיה צולבת ומוסיפים רגולריזציה הרמונית באנלוגיה למודל הליניארי, מה שמבטיח שינוי לא משמעותי במשקלים הישנים.

CNN
עם רשתות קונבולוציוניות זה קצת יותר מסובך. אם השכבות האחרונות מאומנות ב-CNN, אז כמובן שניתן ליישם רגולריזציה הרמונית ולהבטיח המשכיות. אבל אם צריך לאמן את כל הרשת, אז לא ניתן ליישם רגולריזציה כזו על כל השכבות. עם זאת, קיימת אפשרות עם אימון הטמעות משלימות באמצעות Triplet Loss ().
אובדן שלישייה
באמצעות משימת האנטי-פישינג כדוגמה, ננתח את Triplet Loss באופן כללי. ניקח את הלוגו שלנו, כמו גם דוגמאות חיוביות ושליליות של לוגואים של חברות אחרות. אנו ממזערים את המרחק בין הראשון וממקסים את המרחק בין השני, אנו עושים זאת עם רווח קטן כדי להבטיח קומפקטיות רבה יותר של המחלקות.
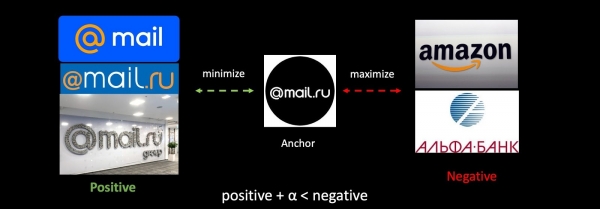
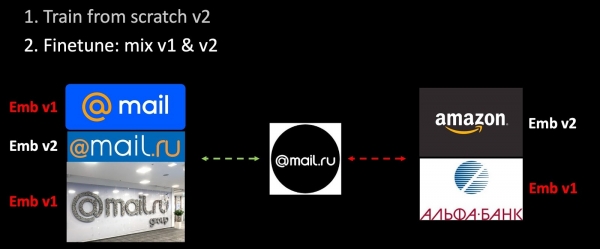
אם נאמן מחדש את הרשת, אז המרחב המטרי שלנו משתנה לחלוטין, והוא הופך להיות בלתי תואם לחלוטין לקודם. זוהי בעיה חמורה במשימות המשתמשות בווקטורים. כדי לעקוף בעיה זו, נערבב הטמעות ישנות במהלך האימון.
הוספנו נתונים חדשים לקבוצת האימונים ואימנו את הגרסה השנייה של המודל מאפס. בשלב השני, אנו מכווננים את הרשת שלנו: ראשית, השכבה האחרונה מכווננת, ולאחר מכן כל הרשת מופשרת. בתהליך הרכבת הטריפלטים, רק חלק מההטמעות מחושבות באמצעות המודל המאומן, השאר - באמצעות המודל הישן. לפיכך, בתהליך הכוונון העדין, אנו מבטיחים את התאימות של המרחבים המטריים v1 ו-v2. גרסה ייחודית של רגולריזציה הרמונית.
אדריכלות בשלמותה
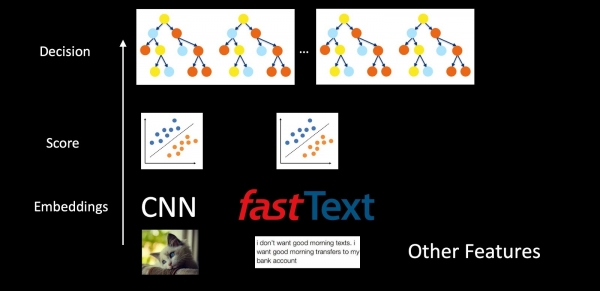
אם ניקח בחשבון את המערכת כולה באמצעות דוגמת אנטי-ספאם, המודלים אינם מבודדים, אלא מקוננים. אנו מצלמים תמונות, טקסט ותכונות אחרות, ובעזרת CNN ו-Fast Text אנו מקבלים הטמעות. לאחר מכן, מסווגים מוחלים על גבי ההטמעות, אשר מייצרים ציונים עבור מחלקות שונות (סוגי מיילים, ספאם, נוכחות לוגו). הציונים והתכונות מוכנסים לאחר מכן ליער העצים כדי לקבל את ההחלטה הסופית. מסווגים נפרדים בתכנית זו מאפשרים לנו לפרש טוב יותר את תוצאות עבודת המערכת וליתר דיוק לאמן רכיבים במקרה של בעיות, במקום להזין את כל הנתונים לעצי ההחלטה בצורה גולמית.
לבסוף, אנו מבטיחים המשכיות בכל רמה. ברמה התחתונה ב-CNN וב-Fast Text אנו משתמשים ברגולריזציה הרמונית, עבור מסווגים באמצע - גם ברגולריזציה הרמונית וכיול ציונים לעקביות של התפלגות הסתברות. ועצים משופרים מאומנים בהדרגה או באמצעות זיקוק ידע.
באופן כללי, תחזוקה של מערכת למידת מכונה מקוננת כזו היא בדרך כלל כאב ראש, מכיוון שכל רכיב ברמה התחתונה מוביל לעדכון של כל המערכת שמעליה. אבל מכיוון שבהגדרה שלנו כל רכיב משתנה מעט ותואם לקודמו, ניתן לעדכן את המערכת כולה בחלקים ללא צורך באימון מחדש של כל המבנה, מה שמאפשר תחזוקה ללא תקורה משמעותית.
לפרוס
כיסינו איסוף נתונים והדרכה נוספת של סוגים שונים של מודלים, ולכן אנו עוברים לפריסתם בסביבת הייצור.
בדיקת A/B
כפי שאמרתי קודם לכן, במהלך תהליך איסוף הנתונים, בדרך כלל אנו מקבלים מדגם מוטה, מה שמקשה על הערכת ביצועי הייצור של המודל. לכן, בעת הפריסה, יש להשוות את המודל לגרסה הקודמת כדי להבין כיצד הדברים מתנהלים בפועל, כלומר, לבצע מבחני A/B. למעשה, תהליך הפריסה והניתוח של גרפים הוא די שגרתי ומתאים היטב לאוטומציה. אנו פורסים את המודלים שלנו בהדרגה ל-5%, 30%, 50% ו-100% מהמשתמשים, תוך איסוף כל המדדים הזמינים על תגובות המודל ומשוב המשתמשים. במקרה של חריגים משמעותיים, אנו מבטלים את המודל באופן אוטומטי, ובמקרים אחרים, לאחר איסוף מספר מספיק של לחיצות משתמשים, אנו מחליטים להגדיל את האחוז. כתוצאה מכך, אנו מביאים את המודל החדש ל-50% מהמשתמשים באופן אוטומטי לחלוטין, והפריסה לכלל הקהל מאושרת על ידי אדם, אם כי ניתן גם לאוטומט שלב זה.
עם זאת, תהליך בדיקות A/B מספק מקום לאופטימיזציה. העובדה היא שכל בדיקת A/B היא ארוכה למדי (במקרה שלנו, היא אורכת בין 6 ל-24 שעות, תלוי בכמות המשוב), מה שהופך אותה ליקרה למדי ומוגבלת במשאבים. בנוסף, נדרש אחוז גבוה למדי מהזרימה של הבדיקה כדי להאיץ באופן מהותי את הזמן הכולל של בדיקת ה-A/B (זה יכול לקחת זמן רב מאוד לאסוף מדגם מובהק סטטיסטית להערכת מדדים באחוז קטן), מה שהופך את מספר משבצות ה-A/B מוגבל ביותר. ברור שעלינו להכניס לבדיקה רק את המודלים המבטיחים ביותר, שמהם אנו מקבלים לא מעט בתהליך האימון הנוסף.
כדי לפתור בעיה זו, אימנו מסווג נפרד שחוזה את הצלחת מבחן A/B. לשם כך, אנו לוקחים את הסטטיסטיקות של קבלת החלטות, דיוק, זיכרון ומדדים אחרים על מערך האימון, על מערך הדחייה ועל הדגימה מהזרם כתכונות. אנו גם משווים את המודל למודל הנוכחי שנמצא בייצור, באמצעות היוריסטיקות, ומתחשבים במורכבות המודל. באמצעות כל התכונות הללו, המסווג שאומן על היסטוריית הבדיקות מדרג את המודלים המועמדים, במקרה שלנו אלו יערות של עצים, ומחליט איזה מהם להכניס למבחן A/B.
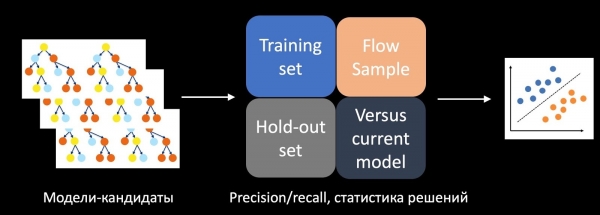
בזמן היישום, גישה זו אפשרה לנו להגדיל את מספר מבחני ה-A/B המוצלחים פי כמה.
בדיקות וניטור
בדיקות וניטור, למרבה הפלא, לא פוגעים בבריאותנו, אלא להיפך, הם משפרים אותה ומקלים על מתחים מיותרים. בדיקות מאפשרות למנוע כשל, וניטור מאפשר לזהות אותו בזמן כדי להפחית את ההשפעה על המשתמשים.
חשוב להבין שבמוקדם או במאוחר המערכת שלך תמיד תעשה טעויות - זה נובע ממחזור הפיתוח של כל תוכנה. בתחילת פיתוח המערכת תמיד יש הרבה באגים עד שהכל מסתדר והשלב העיקרי של החידושים הושלם. אבל עם הזמן, האנטרופיה גובה מחיר, ושגיאות מופיעות שוב - עקב פגיעה ברכיבים מסביב ושינויים בנתונים, שהזכרתי בהתחלה.
כאן ברצוני לציין כי כל מערכת למידת מכונה צריכה להיחשב מבחינת הרווח שלה לאורך מחזור החיים שלה. הגרף שלהלן מציג דוגמה למערכת שעובדת על תפיסת סוג נדיר של דואר זבל (הקו בגרף הוא סביב האפס). פעם אחת, עקב תכונה שנשמרה במטמון בצורה שגויה, היא השתגעה. למרבה המזל, לא היה ניטור אחר טריגרים חריגים, וכתוצאה מכך המערכת החלה לשמור מכתבים לתיקיית דואר הזבל בסף קבלת ההחלטות בכמויות גדולות. למרות תיקון ההשלכות, המערכת כבר עשתה כל כך הרבה טעויות שהיא לא תשלם על עצמה תוך חמש שנים. וזהו כישלון מוחלט מבחינת מחזור החיים של המודל.
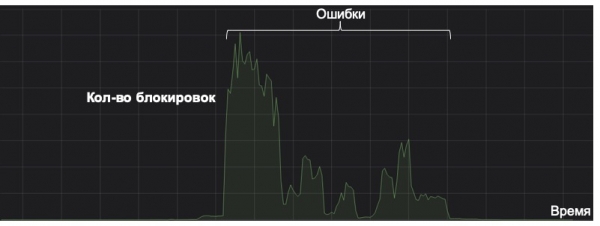
לכן, דבר פשוט כמו ניטור יכול להפוך למפתח בחיי המודל. בנוסף למדדים סטנדרטיים וברורים, אנו בוחנים את התפלגות התגובות והשיעורים של המודל, כמו גם את התפלגות הערכים של מאפיינים מרכזיים. באמצעות סטייה של KL, אנו יכולים להשוות את ההתפלגות הנוכחית להתפלגות ההיסטורית או את הערכים במבחן A/B עם שאר הזרימה, מה שמאפשר לנו להבחין בחריגות במודל ולבטל שינויים בזמן.
ברוב המקרים, אנו משיקים את הגרסאות הראשונות שלנו של מערכות באמצעות היוריסטיקות או מודלים פשוטים בהם נשתמש לניטור בעתיד. לדוגמה, אנו עוקבים אחר מודל ה-NER בהשוואה לביטויים רגולריים עבור חנויות מקוונות ספציפיות, ואם כיסוי המסווג יורד בהשוואה אליהן, אנו מגלים את הסיבות. יישום שימושי נוסף של היוריסטיקות!
תוצאות של
בואו נעבור שוב על הרעיונות המרכזיים של המאמר.
- פיבדקאנחנו תמיד חושבים על המשתמש: איך הוא יחיה עם הטעויות שלנו, איך הוא יוכל לדווח עליהן. אנחנו לא שוכחים שמשתמשים אינם מקור למשוב טהור עבור מודלי אימון, ויש לנקות אותו בעזרת מערכות למידה חינוכית נלוות. אם אין דרך לאסוף אות מהמשתמש, אז אנחנו מחפשים מקורות משוב חלופיים, למשל, מערכות קשורות.
- הכשרה נוספתהעיקר כאן הוא המשכיות, לכן אנו מסתמכים על מודל הייצור הנוכחי. אנו מאמנים מודלים חדשים כך שלא יהיו שונים בהרבה מהקודם עקב רגולריזציה הרמונית וטריקים דומים.
- לפרוספריסה אוטומטית לפי מדדים מפחיתה משמעותית את זמן יישום המודלים. ניטור סטטיסטיקות וחלוקת קבלת החלטות, מספר הנפילות של המשתמשים חיוני לשינה שלווה ולסופי שבוע פרודוקטיביים.
ובכן, אני מקווה שמה שתקראו יעזור לכם לשפר את מערכות ה-ML שלכם מהר יותר, להביא אותן לשוק מהר יותר ולהפוך אותן לאמינות יותר, ולהפחית את כמות הלחץ מהעבודה.
מקור: www.habr.com
