

מאמר זה הוא כבר השני בנושא דחיסת נתונים במהירות גבוהה. המאמר הראשון תיאר מדחס הפועל במהירות של 10 GB/sek. לכל ליבת מעבד (דחיסה מינימלית, RTT-Min).
מדחס זה כבר מיושם בציוד של משכפלים משפטיים לדחיסה מהירה של השלכות מדיית אחסון ולשיפור חוזק ההצפנה; ניתן להשתמש בו גם כדי לדחוס תמונות של מכונות וירטואליות וקבצי החלפת RAM בעת שמירתן במהירות גבוהה כונני SSD.
המאמר הראשון הכריז גם על פיתוח אלגוריתם דחיסה לדחיסת עותקי גיבוי של כונני דיסקים HDD ו-SSD (דחיסה בינונית, RTT-Mid) עם פרמטרי דחיסת נתונים משופרים משמעותית. עד עכשיו, המדחס הזה מוכן לחלוטין והמאמר הזה עוסק בזה.
מדחס שמיישם את אלגוריתם RTT-Mid מספק יחס דחיסה השווה לארכיונים סטנדרטיים כגון WinRar, 7-Zip, הפועלים במצב מהיר. יחד עם זאת, מהירות הפעולה שלו גבוהה לפחות בסדר גודל.
מהירות אריזה/פירוק נתונים היא פרמטר קריטי הקובע את היקף היישום של טכנולוגיות הדחיסה. לא סביר שמישהו יחשוב על דחיסה של טרה-בייט של נתונים במהירות של 10-15 מגה-בייט לשנייה (זו בדיוק המהירות של ארכיונים במצב דחיסה סטנדרטי), כי זה ייקח כמעט עשרים שעות עם עומס מלא של המעבד. .
מצד שני, ניתן להעתיק את אותו טרה-בייט במהירויות בסדר גודל של 2-3 ג'יגה-בייט לשנייה תוך כעשר דקות.
לכן, דחיסה של מידע בנפח גדול חשובה אם היא מבוצעת במהירות שאינה נמוכה ממהירות הקלט/פלט האמיתי. עבור מערכות מודרניות זה לפחות 100 מגה בייט לשנייה.
מדחסים מודרניים יכולים לייצר מהירויות כאלה רק במצב "מהיר". במצב הנוכחי הזה נשווה את אלגוריתם RTT-Mid עם מדחסים מסורתיים.
בדיקה השוואתית של אלגוריתם דחיסה חדש
המדחס RTT-Mid עבד כחלק מתוכנית הבדיקה. באפליקציה אמיתית "עובדת" היא עובדת הרבה יותר מהר, היא משתמשת ב-multithreading בחוכמה ומשתמשת במהדר "רגיל", לא ב-C#.
מכיוון שהמדחסים המשמשים בבדיקה ההשוואתית בנויים על עקרונות שונים וסוגים שונים של נתונים נדחסים בצורה שונה, לצורך אובייקטיביות הבדיקה, נעשה שימוש בשיטת מדידת "הטמפרטורה הממוצעת בבית החולים"...
נוצר קובץ dump של סקטור אחר סקטור של הדיסק הלוגי המכיל את מערכת ההפעלה. Windows 10זהו השילוב הטבעי ביותר של מבני נתונים שונים שנמצא בכל מחשב. דחיסת קובץ זה תאפשר לנו להשוות את המהירות ויחס הדחיסה של האלגוריתם החדש עם המדחסים המתקדמים ביותר המשמשים בארכיונים מודרניים.
הנה קובץ ה-dump:
קובץ ה-dump נדחס באמצעות מדחסי PTT-Mid, 7-zip ו-WinRar. ה-WinRar ומדחס 7-zip הוגדרו למהירות מרבית.
מדחס פועל 7-zip:
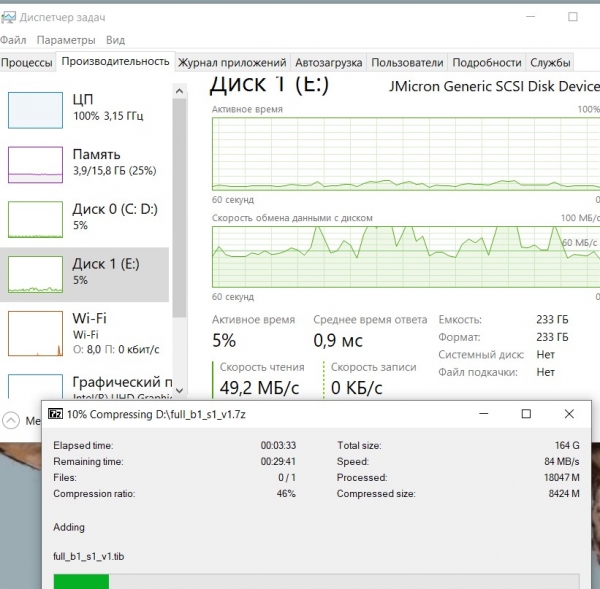
הוא טוען את המעבד ב-100%, בעוד שהמהירות הממוצעת של קריאת ה-dump המקורית היא כ-60 מגה-בייט לשנייה.
מדחס פועל WinRAR:
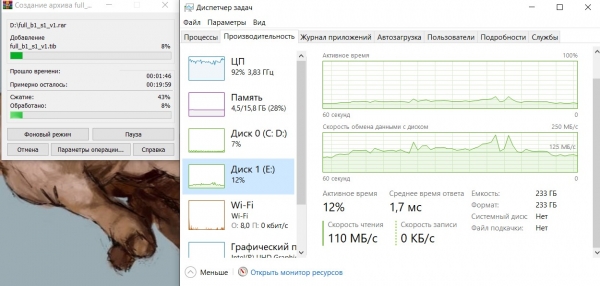
המצב דומה, עומס המעבד הוא כמעט 100%, מהירות קריאת dump הממוצעת היא כ-125 מגה-בייט/שנייה.
כמו במקרה הקודם, מהירות הארכיון מוגבלת על ידי יכולות המעבד.
תוכנית בדיקת המדחס פועלת כעת RTT-Mid:
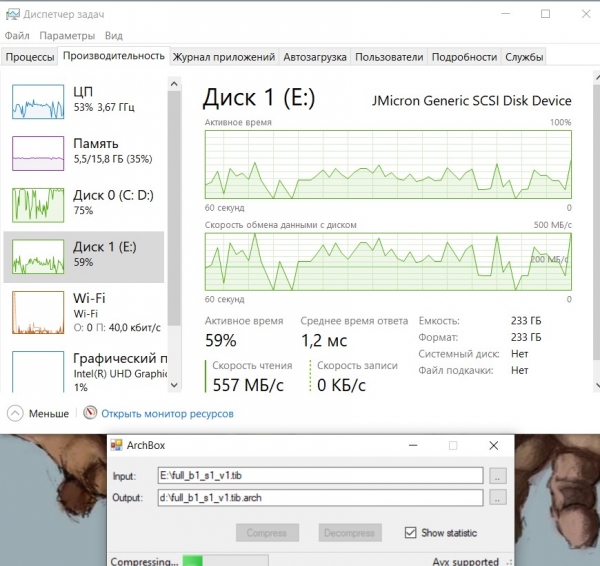
צילום המסך מראה שהמעבד נטען ב-50% והוא לא פעיל בשאר הזמן, כי אין לאן להעלות את הנתונים הדחוסים. דיסק העלאת הנתונים (דיסק 0) נטען כמעט במלואו. מהירות קריאת הנתונים (דיסק 1) משתנה מאוד, אך בממוצע יותר מ-200 מגה-בייט לשנייה.
מהירות המדחס מוגבלת במקרה זה על ידי היכולת לכתוב נתונים דחוסים לדיסק 0.
כעת יחס הדחיסה של הארכיונים שהתקבלו:



ניתן לראות שהקומפרסור RTT-Mid עשה את עבודת הדחיסה הטובה ביותר; הארכיון שיצר היה קטן ב-1,3 גיגה-בייט מארכיון WinRar וקטן ב-2,1 גיגה-בייט מארכיון 7z.
הזמן שהושקע ביצירת הארכיון:
- 7-zip - 26 דקות 10 שניות;
- WinRar – 17 דקות 40 שניות;
- RTT-Mid – 7 דקות 30 שניות.
כך, אפילו תוכנית בדיקה, לא מותאמת, תוך שימוש באלגוריתם RTT-Mid, הצליחה ליצור ארכיון יותר מפי שניים וחצי מהר יותר, בעוד שהארכיון התברר כקטן משמעותית מזה של מתחריו...
מי שלא מאמין לצילומי המסך יכול לבדוק בעצמו את האותנטיות שלהם. תוכנית המבחן זמינה בכתובת , הורד ובדוק.
אבל רק על מעבדים עם תמיכה ב-AVX-2, ללא תמיכה בהוראות אלו המדחס לא עובד, ואל תבדקו את האלגוריתם על מעבדי AMD ישנים יותר, הם איטיים מבחינת ביצוע הוראות AVX...
נעשה שימוש בשיטת הדחיסה
האלגוריתם משתמש בשיטה לאינדקס של קטעי טקסט חוזרים בפירוט בתים. שיטת דחיסה זו ידועה כבר זמן רב, אך לא הייתה בשימוש מכיוון שפעולת ההתאמה הייתה יקרה מאוד מבחינת המשאבים הדרושים ודרשה הרבה יותר זמן מאשר בניית מילון. אז אלגוריתם RTT-Mid הוא דוגמה קלאסית למעבר "חזרה לעתיד"...
מדחס ה-PTT משתמש בסורק חיפוש התאמה ייחודי במהירות גבוהה, המאפשר לנו להאיץ את תהליך הדחיסה. סורק מתוצרת עצמית, זה "הקסם שלי...", "זה די יקר, כי זה לגמרי בעבודת יד" (כתוב ב-assembler).
סורק חיפוש ההתאמה נעשה על פי סכמה הסתברותית דו-מפלסית: ראשית, נסרקת נוכחותו של "סימן" של התאמה, ורק לאחר זיהוי ה"סימן" במקום זה, ההליך לזיהוי התאמה אמיתית התחיל.
לחלון חיפוש ההתאמה יש גודל בלתי צפוי, בהתאם למידת האנטרופיה בבלוק הנתונים המעובדים. עבור נתונים אקראיים לחלוטין (בלתי ניתנים לדחיסה) יש לו גודל של מגה בייט, עבור נתונים עם חזרות הוא תמיד גדול ממגה בייט.
אבל פורמטי נתונים מודרניים רבים אינם ניתנים לדחיסה והפעלת סורק עתיר משאבים דרכם חסרת תועלת ובזבזנית, ולכן הסורק משתמש בשני מצבי פעולה. ראשית, מתבצע חיפוש בקטעים של טקסט המקור עם חזרות אפשריות, פעולה זו מתבצעת גם היא בשיטה הסתברותית ומתבצעת במהירות רבה (במהירות של 4-6 GigaBytes/sek). האזורים עם התאמות אפשריות מעובדים לאחר מכן על ידי הסורק הראשי.
דחיסת אינדקס אינה יעילה במיוחד, יש להחליף קטעים כפולים באינדקסים, ומערך האינדקס מפחית משמעותית את יחס הדחיסה.
כדי להגדיל את יחס הדחיסה, לא רק התאמות שלמות של מחרוזות בתים מתווספות לאינדקס, אלא גם חלקיות, כאשר המחרוזת מכילה בתים תואמים ולא תואמים. לשם כך, פורמט האינדקס כולל שדה מסיכת התאמה המציין את הבתים התואמים של שני בלוקים. לדחיסה גדולה עוד יותר, נעשה שימוש באינדקס להצבת מספר בלוקים תואמים חלקית על הבלוק הנוכחי.
כל זה איפשר להשיג במדחס PTT-Mid יחס דחיסה השווה למדחסים שנעשו בשיטת המילון, אך עובדים הרבה יותר מהר.
מהירות אלגוריתם הדחיסה החדש
אם המדחס פועל עם שימוש בלעדי בזיכרון מטמון (נדרשים 4 מגה-בייט לכל חוט), אז מהירות הפעולה נעה בין 700-2000 מגה-בייט לשנייה. לכל ליבת מעבד, תלוי בסוג הנתונים הנדחסים ותלוי מעט בתדירות הפעולה של המעבד.
עם מימוש רב-הליכי של המדחס, מדרגיות יעילה נקבעת לפי גודל המטמון ברמה השלישית. לדוגמה, אם יש 9 מגה-בייט של זיכרון מטמון "על הסיפון", אין טעם להשיק יותר משני חוטי דחיסה; המהירות לא תגדל מכאן. אבל עם מטמון של 20 מגה-בייט, אתה כבר יכול להריץ חמישה שרשורי דחיסה.
כמו כן, השהיה של ה-RAM הופך לפרמטר חשוב שקובע את מהירות המדחס. האלגוריתם משתמש בגישה אקראית ל-OP, שחלקם לא נכנסים לזיכרון המטמון (כ-10%) והוא צריך להתבטל, להמתין לנתונים מה-OP, מה שמפחית את מהירות הפעולה.
מערכת הקלט/פלט משפיעה באופן משמעותי על מהירות הדחיסה. בקשות קלט/פלט למעבד של בלוק ה-RAM מבקשות נתונים, מה שמפחית גם את מהירות הדחיסה. בעיה זו משמעותית עבור מחשבים ניידים ונייחים. שרתים זה פחות משמעותי עקב יחידת בקרת גישה מתקדמת יותר לאפיק המערכת וזיכרון RAM רב-ערוצי.
לאורך הטקסט במאמר אנו מדברים על דחיסה; דקומפרסיה נשארת מחוץ לתחום המאמר הזה מכיוון ש"הכל מכוסה בשוקולד". פירוק הדחיסה הוא הרבה יותר מהיר ומוגבלת על ידי מהירות I/O. ליבה פיזית אחת בחוט אחד מספקת בקלות מהירויות פריקה של 3-4 GB/sek.
הדבר נובע מהיעדר פעולת חיפוש התאמה במהלך תהליך הדחיסה, אשר "אוכלת" את המשאבים העיקריים של המעבד וזיכרון המטמון במהלך הדחיסה.
אמינות של אחסון נתונים דחוס
כפי שמרמז שמה של כל מחלקה של תוכנות המשתמשות בדחיסת נתונים (ארכיונים), הן מיועדות לאחסון מידע ארוך טווח, לא לשנים, אלא למאות ואלפי שנים...
במהלך האחסון, מדיית אחסון מאבדת נתונים מסוימים, הנה דוגמה:

נושא המידע ה"אנלוגי" הזה הוא בן אלף שנים, חלק מהשברים אבדו, אבל באופן כללי המידע "קריא"...
אף אחד מהיצרנים האחראים של מערכות מודרניות לאחסון נתונים דיגיטליים ומדיה דיגיטלית עבורם מספק ערבויות לבטיחות נתונים מלאה במשך יותר מ-75 שנים.
וזו בעיה, אבל בעיה נדחית, צאצאינו יפתרו אותה...
מערכות אחסון נתונים דיגיטליות יכולות לאבד נתונים לא רק לאחר 75 שנים, שגיאות בנתונים יכולות להופיע בכל עת, אפילו במהלך הקלטתן, הן מנסות למזער את העיוותים הללו על ידי שימוש יתירות ותיקון שלהם עם מערכות תיקון שגיאות. מערכות יתירות ותיקון לא תמיד יכולות לשחזר מידע שאבד, ואם כן, אין ערובה שפעולת השחזור הושלמה כהלכה.
וזו גם בעיה גדולה, אבל לא נדחית, אלא נוכחית.
מדחסים מודרניים המשמשים לארכיון נתונים דיגיטליים בנויים על שינויים שונים בשיטת המילון, ועבור ארכיונים כאלה אובדן של פיסת מידע יהיה אירוע קטלני; יש אפילו מונח מבוסס למצב כזה - ארכיון "שבור" ...
המהימנות הנמוכה של אחסון מידע בארכיונים עם דחיסת מילון קשורה למבנה הנתונים הדחוסים. המידע בארכיון כזה אינו מכיל את טקסט המקור, מספרי הערכים במילון מאוחסנים בו, והמילון עצמו משתנה באופן דינמי על ידי הטקסט הדחוס הנוכחי. אם קטע ארכיון אבד או פגום, לא ניתן לזהות את כל ערכי הארכיון הבאים לא לפי התוכן ולא לפי אורך הערך במילון, שכן לא ברור למה מתאים מספר הערך במילון.
אי אפשר לשחזר מידע מארכיון "שבור" שכזה.
אלגוריתם RTT מבוסס על שיטה אמינה יותר לאחסון נתונים דחוסים. הוא משתמש בשיטת האינדקס של חשבון לשברים חוזרים. גישה זו לדחיסה מאפשרת למזער את ההשלכות של עיוות מידע על מדיית האחסון, ובמקרים רבים לתקן אוטומטית עיוותים שנוצרו במהלך אחסון המידע.
זאת בשל העובדה שקובץ הארכיון במקרה של דחיסת אינדקס מכיל שני שדות:
- שדה טקסט מקור עם קטעים חוזרים שהוסרו ממנו;
- שדה אינדקס.
שדה האינדקס, שהוא קריטי לשחזור מידע, אינו גדול בגודלו וניתן לשכפל אותו לאחסון נתונים אמין. לכן, גם אם אבד חלק מטקסט המקור או מערך האינדקס, כל שאר המידע ישוחזר ללא בעיות, כמו בתמונה עם אמצעי אחסון "אנלוגי".
חסרונות האלגוריתם
אין יתרונות בלי חסרונות. שיטת דחיסת האינדקס אינה דוחסת רצפים קצרים שחוזרים על עצמם. זאת בשל מגבלות שיטת המדד. אינדקסים הם בגודל של לפחות 3 בתים ויכולים להיות בגודל של עד 12 בתים. אם נתקלת בחזרה בגודל קטן יותר מהאינדקס המתאר אותה, אז היא לא נלקחת בחשבון, לא משנה באיזו תדירות חזרות כאלה מזוהות בקובץ הדחוס.
שיטת הדחיסה המסורתית של המילון דוחסת ביעילות מספר חזרות באורך קצר ולכן משיגה יחס דחיסה גבוה יותר מדחיסת אינדקס. נכון, זה מושג בגלל העומס הרב על המעבד המרכזי; כדי ששיטת המילון תתחיל לדחוס נתונים בצורה יעילה יותר משיטת האינדקס, היא צריכה להפחית את מהירות עיבוד הנתונים ל-10-20 מגה-בייט לשנייה על אמת. התקנות מחשוב עם עומס מעבד מלא.
מהירויות נמוכות כאלה אינן מקובלות עבור מערכות אחסון נתונים מודרניות והן בעלות עניין "אקדמי" יותר מאשר מעשי.
מידת דחיסת המידע תוגדל משמעותית בשינוי הבא של אלגוריתם RTT (RTT-Max), שכבר נמצא בפיתוח.
אז כמו תמיד המשך...
מקור: www.habr.com
