

Tai net ne juokas, atrodo, kad šis paveikslėlis tiksliausiai atspindi šių duomenų bazių esmę, ir galiausiai bus aišku, kodėl:

Pagal DB-Engines reitingą, dvi populiariausios NoSQL stulpelių duomenų bazės yra Cassandra (toliau CS) ir HBase (HB).
Likimo valia mūsų duomenų įkėlimo valdymo komanda Sberbank jau padarė ir glaudžiai bendradarbiauja su HB. Per tą laiką gana gerai ištyrėme jo stipriąsias ir silpnąsias puses bei išmokome jį virti. Tačiau alternatyvos buvimas CS pavidalu visada priversdavo mus šiek tiek kankinti abejones: ar padarėme teisingą pasirinkimą? Be to, rezultatai , kurį atliko DataStax, jie teigė, kad CS lengvai įveikia HB beveik triuškinamu balu. Kita vertus, „DataStax“ yra suinteresuota šalis, ir jūs neturėtumėte to pasitikėti. Mus taip pat glumino gana mažas informacijos kiekis apie testavimo sąlygas, todėl nusprendėme patys išsiaiškinti, kas yra BigData NoSql karalius, o gauti rezultatai pasirodė labai įdomūs.
Tačiau prieš pereinant prie atliktų bandymų rezultatų, būtina apibūdinti reikšmingus aplinkos konfigūracijų aspektus. Faktas yra tas, kad CS gali būti naudojamas režimu, leidžiančiu prarasti duomenis. Tie. tai yra tada, kai tik vienas serveris (mazgas) yra atsakingas už tam tikro rakto duomenis, o jei dėl kokių nors priežasčių jis sugenda, tada šio rakto reikšmė bus prarasta. Daugeliui užduočių tai nėra labai svarbu, tačiau bankų sektoriui tai yra greičiau išimtis nei taisyklė. Mūsų atveju, norint patikimai saugoti, svarbu turėti kelias duomenų kopijas.
Todėl buvo atsižvelgta tik į CS darbo režimą trigubo replikavimo režimu, t.y. Dėklo erdvė buvo sukurta naudojant šiuos parametrus:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; Be to, yra du būdai, kaip užtikrinti reikiamą nuoseklumo lygį. Pagrindinė taisyklė:
NW + NR > RF
Tai reiškia, kad patvirtinimų skaičius iš mazgų rašant (NW) ir patvirtinimų skaičius iš mazgų skaitant (NR) turi būti didesnis nei replikacijos koeficientas. Mūsų atveju RF = 3, o tai reiškia, kad tinka šios parinktys:
2 + 2 > 3
3 + 1 > 3
Kadangi mums iš esmės svarbu duomenis saugoti kuo patikimiau, buvo pasirinkta 3+1 schema. Be to, HB veikia panašiu principu, t.y. toks palyginimas bus teisingesnis.
Reikėtų pažymėti, kad DataStax savo tyrime pasielgė priešingai, jie nustatė RF = 1 tiek CS, tiek HB (pastariesiems pakeisdami HDFS nustatymus). Tai tikrai svarbus aspektas, nes įtaka CS veikimui šiuo atveju yra didžiulė. Pavyzdžiui, toliau pateiktame paveikslėlyje parodytas pailgėjęs laikas, reikalingas duomenims įkelti į CS:
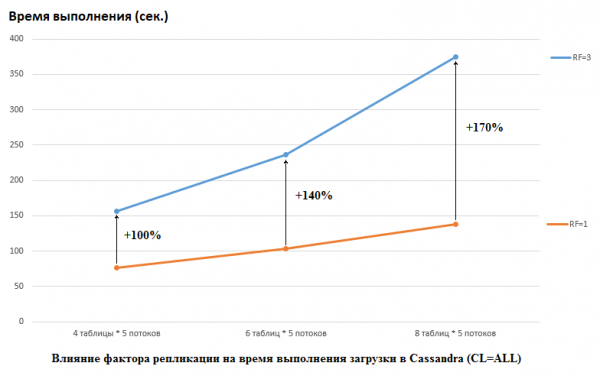
Čia matome taip: kuo daugiau konkuruojančių gijų įrašo duomenis, tuo ilgiau tai užtrunka. Tai natūralu, tačiau svarbu, kad RF=3 veikimo pablogėjimas būtų žymiai didesnis. Kitaip tariant, jei įrašome 4 gijas į 5 lenteles (iš viso 20), tada RF=3 praranda maždaug 2 kartus (150 sekundžių RF=3, palyginti su 75, kai RF=1). Bet jei padidintume apkrovą įkeldami duomenis į 8 lenteles po 5 gijas (iš viso 40), tai RF=3 praradimas jau yra 2,7 karto (375 sekundės prieš 138).
Galbūt tai iš dalies yra sėkmingo DataStax CS atlikto apkrovos testavimo paslaptis, nes HB mūsų stende replikacijos koeficiento keitimas nuo 2 iki 3 neturėjo jokios įtakos. Tie. diskai nėra HB kliūtis mūsų konfigūracijai. Tačiau čia yra daug kitų spąstų, nes reikia pastebėti, kad mūsų HB versija buvo šiek tiek pataisyta ir pataisyta, aplinkos visiškai kitokios ir pan. Taip pat verta paminėti, kad galbūt aš tiesiog nežinau, kaip teisingai paruošti CS ir yra keletas efektyvesnių būdų, kaip su ja dirbti, ir tikiuosi, kad tai sužinosime komentaruose. Bet pirmiausia pirmiausia.
Visi bandymai buvo atlikti aparatinės įrangos klasteryje, kurį sudaro 4 serveriai, kurių kiekvienas turi tokią konfigūraciją:
CPU: Xeon E5-2680 v4 @ 2.40 GHz 64 gijos.
Diskai: 12 vienetų SATA HDD
java versija: 1.8.0_111
CS versija: 3.11.5
cassandra.yml parametraižetonų skaičius: 256
hinted_handoff_enabled: tiesa
hinted_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
hints_directory: /data10/cassandra/hints
hints_flush_period_in_ms: 10000 XNUMX
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autentifikavimo priemonė: AllowAllAuthenticator
autorizatorius: AllowAllAuthorizer
role_manager: CassandraRoleManager
roles_validity_in_ms: 2000
permissions_validity_in_ms: 2000
credentials_validity_in_ms: 2000
skirstytuvas: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directories:
- /data1/cassandra/data # kiekvienas dataN katalogas yra atskiras diskas
- /data2/cassandra/data
- /data3/cassandra/data
- /data4/cassandra/data
- /data5/cassandra/data
- /data6/cassandra/data
- /data7/cassandra/data
- /data8/cassandra/data
commitlog_katalogas: /data9/cassandra/commitlog
cdc_enabled: false
disk_failure_policy: sustabdyti
commit_failure_policy: stop
ready_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
išsaugotų_talpyklų_katalogas: /data10/cassandra/saved_caches
commitlog_sync: periodinis
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
seed_provider:
- klasės_pavadinimas: org.apache.cassandra.locator.SimpleSeedProvider
parametrai:
— sėklos: "*,*"
concurrent_reads: 256 # bandė 64 - jokio skirtumo nepastebėta
concurrent_writes: 256 # bandė 64 - jokio skirtumo nepastebėta
concurrent_counter_writes: 256 # bandė 64 - jokio skirtumo nepastebėta
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # bandė 16 GB – buvo lėčiau
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutes: 60
trickle_fsync: klaidinga
trickle_fsync_interval_in_kb: 10240
saugyklos prievadas: 7000
ssl_storage_port: 7001
klausymo_adresas: *
transliacijos_adresas: *
listen_on_broadcast_address: tiesa
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: tiesa
native_transport_port: 9042
start_rpc: tiesa
rpc_adresas: *
rpc_port: 9160
rpc_keepalive: tiesa
rpc_server_type: sinchronizavimas
thrift_framed_transport_size_in_mb: 15
incremental_backups: false
snapshot_before_compaction: false
auto_snapshot: tiesa
stulpelio_indekso_dydis_kb: 64
column_index_cache_size_in_kb: 2
concurrent_compactors: 4
compaction_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000 XNUMX
range_request_timeout_in_ms: 200000 XNUMX
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000 XNUMX
cas_contention_timeout_in_ms: 20000
truncate_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000 XNUMX
slow_query_log_timeout_in_ms: 500
cross_node_timeout: false
endpoint_snitch: GossipingPropertyFileSnitch
dynamic_snitch_update_interval_in_ms: 100
dynamic_snitch_reset_interval_in_ms: 600000 XNUMX
dinaminis_snitch_badness_threshold: 0.1
request_scheduler: org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: nėra
client_encryption_options:
įjungta: klaidinga
internode_compression: dc
inter_dc_tcp_nodelay: klaidinga
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: false
enable_scripted_user_defined_functions: false
windows_timer_interval: 1
transparent_data_encryption_options:
įjungta: klaidinga
tombstone_warn_threshold: 1000
antkapio_gedimo_slenkstis: 100000 XNUMX
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compaction_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pressure_enabled: klaidinga
enable_materialized_views: tiesa
enable_sasi_indexes: tiesa
GC nustatymai:
### TVS nustatymai-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+CMSParallelRemarkEnabled
-XX:Išgyvenimo koeficientas=8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+Naudokite CMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSEdenChunksRecordAlways
-XX:+CMSClassUnloadingEnabled
Atminčiai jvm.options buvo skirta 16Gb (bandėme ir 32 Gb, jokio skirtumo nepastebėjome).
Lentelės buvo sukurtos komanda:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};HB versija: 1.2.0-cdh5.14.2 (klasėje org.apache.hadoop.hbase.regionserver.HRegion neįtraukėme MetricsRegion, dėl kurio atsirado GC, kai regionų skaičius buvo didesnis nei 1000 regionų serveryje)
Nenumatytieji HBase parametraizookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minutės
hbase.client.scanner.timeout.period: 2 minutės
hbase.master.handler.count: 10
hbase.regionsserver.lease.period, hbase.client.scanner.timeout.period: 2 minutės (-ės)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 valanda(s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplier: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompaction: 1 diena(s)
„HBase Service“ išplėstinės konfigūracijos fragmentas (apsauginis vožtuvas), skirtas hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionsserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Java konfigūracijos parinktys, skirtos HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minutės
hbase.snapshot.region.timeout: 2 minutės
hbase.snapshot.master.timeout.millis: 2 minutės
HBase REST serverio maksimalus žurnalo dydis: 100 MiB
HBase REST serverio maksimali žurnalo failo atsarginė kopija: 5
HBase Thrift Server maksimalus žurnalo dydis: 100 MiB
HBase Thrift Server Maksimali žurnalo failo atsarginė kopija: 5
Pagrindinis maksimalus žurnalo dydis: 100 MiB
Pagrindinės didžiausios žurnalo failų atsarginės kopijos: 5
Regiono serverio maksimalus žurnalo dydis: 100 MiB
Regiono serverio didžiausios žurnalo failų atsarginės kopijos: 5
HBase aktyvaus pagrindinio aptikimo langas: 4 minutės
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 milisekundžių
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Maksimalus proceso failo aprašų skaičius: 180000 XNUMX
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Region Mover Gijos: 6
Kliento Java krūvos dydis baitais: 1 GiB
HBase REST serverio numatytoji grupė: 3 GiB
„HBase Thrift“ serverio numatytoji grupė: 3 GiB
Java krūvos HBase Master dydis baitais: 16 GiB
„Java Heap“ HBase RegionServer dydis baitais: 32 GiB
+ZooKeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Lentelių kūrimas:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Čia yra vienas svarbus dalykas – DataStax aprašyme nenurodoma, kiek regionų buvo panaudota kuriant HB lenteles, nors tai labai svarbu dideliems kiekiams. Todėl testams buvo pasirinktas kiekis = 64, kuris leidžia saugoti iki 640 GB, t.y. vidutinio dydžio stalas.
Bandymo metu HBase turėjo 22 tūkstančius lentelių ir 67 tūkstančius regionų (tai būtų buvę mirtina 1.2.0 versijai, jei ne anksčiau minėta pataisa).
Dabar dėl kodo. Kadangi nebuvo aišku, kurios konfigūracijos buvo naudingesnės konkrečiai duomenų bazei, bandymai buvo atliekami įvairiais deriniais. Tie. kai kuriuose bandymuose vienu metu buvo įkeltos 4 lentelės (jungimui panaudoti visi 4 mazgai). Kituose bandymuose dirbome su 8 skirtingomis lentelėmis. Kai kuriais atvejais partijos dydis buvo 100, kitais - 200 (partijos parametras – kodą žr. žemiau). Vertės duomenų dydis yra 10 baitų arba 100 baitų (dataSize). Iš viso kiekvienoje lentelėje kiekvieną kartą buvo parašyta ir perskaityta 5 milijonai įrašų. Tuo pačiu metu į kiekvieną lentelę buvo įrašytos / perskaitytos 5 gijos (gijos numeris - thNum), kurių kiekviena naudojo savo raktų diapazoną (skaičius = 1 milijonas):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Atitinkamai, HB buvo suteikta panaši funkcija:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Kadangi HB klientas turi rūpintis vienodu duomenų paskirstymu, pagrindinė sūdymo funkcija atrodė taip:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Dabar įdomiausia dalis – rezultatai:
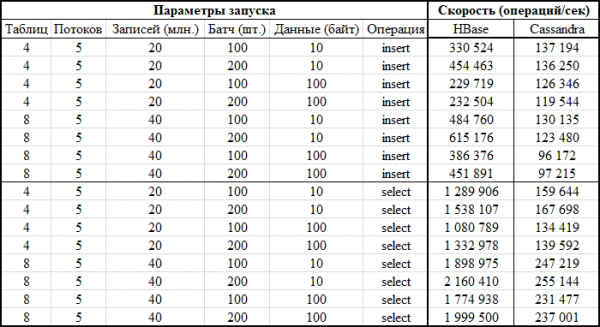
Tas pats grafiko pavidalu:
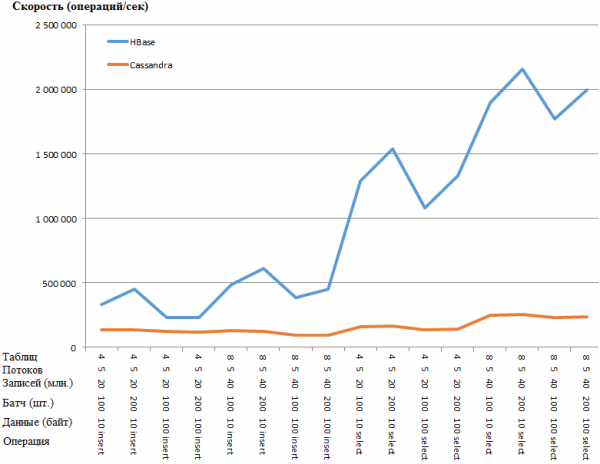
HB pranašumas taip stebina, kad kyla įtarimas, kad CS sąrankoje yra tam tikra kliūtis. Tačiau „Google“ paieška ir akivaizdžiausių parametrų (pvz., „concurrent_writes“ arba „memtable_heap_space_in_mb“) paieška nepaspartino. Tuo pačiu metu rąstai yra švarūs ir niekuo neprisiekia.
Duomenys buvo paskirstyti tolygiai po mazgus, statistika iš visų mazgų buvo maždaug vienoda.
Taip atrodo lentelės statistika iš vieno mazgoKlavišų tarpas: ks
Skaitymų skaičius: 9383707
Skaitymo delsa: 0.04287025042448576 ms
Rašymų skaičius: 15462012
Rašymo delsa: 0.1350068438699957 ms
Laukiantys praplovimai: 0
Lentelė: t1
SST lentelių skaičius: 16
Naudojama erdvė (tiesiogiai): 148.59 MiB
Panaudota erdvė (iš viso): 148.59 MiB
Momentinių nuotraukų naudojama erdvė (iš viso): 0 baitų
Naudojama ne krūvos atmintis (iš viso): 5.17 MiB
SSTable suspaudimo koeficientas: 0.5720989576459437
Pertvarų skaičius (apytikslis): 3970323
Įsimintinų ląstelių skaičius: 0
Įsimintinų duomenų dydis: 0 baitų
Naudojama įsimenama krūvos atmintis: 0 baitų
Įsimintinų jungiklių skaičius: 5
Vietinis skaitymų skaičius: 2346045
Vietinis skaitymo delsa: NaN ms
Vietinis rašymo skaičius: 3865503
Vietinis rašymo delsa: NaN ms
Laukiami praplovimai: 0
Remonto procentas: 0.0
Bloom filtro klaidingi teigiami rezultatai: 25
Bloom filtro klaidingas santykis: 0.00000
Naudojama Bloom filtro erdvė: 4.57 MiB
Naudota „Bloom“ filtras krūvos atmintis: 4.57 MiB
Naudotos krūvos atminties indekso suvestinė: 590.02 KiB
Suspaudimo metaduomenys iš krūvos atminties: 19.45 KiB
Mažiausias suglaudinto skaidinio baitų skaičius: 36
Suglaudinto skaidinio maksimalus baitų skaičius: 42
Suglaudinto skaidinio vidurkis baitai: 42
Vidutinis gyvų ląstelių kiekis viename gabale (paskutines penkias minutes): NaN
Didžiausias gyvų ląstelių skaičius pjūvėje (paskutines penkias minutes): 0
Vidutinis antkapių skaičius viename gabale (paskutines penkias minutes): NaN
Maksimalus antkapių skaičius viename gabale (paskutines penkias minutes): 0
Nutrauktos mutacijos: 0 baitų
Bandymas sumažinti partijos dydį (net ir siunčiant atskirai) neturėjo jokio poveikio, tik pablogėjo. Gali būti, kad iš tikrųjų tai yra didžiausias CS našumas, nes CS gauti rezultatai yra panašūs į tuos, kurie buvo gauti naudojant DataStax - apie šimtus tūkstančių operacijų per sekundę. Be to, jei pažvelgsime į išteklių panaudojimą, pamatysime, kad CS naudoja daug daugiau procesoriaus ir diskų:
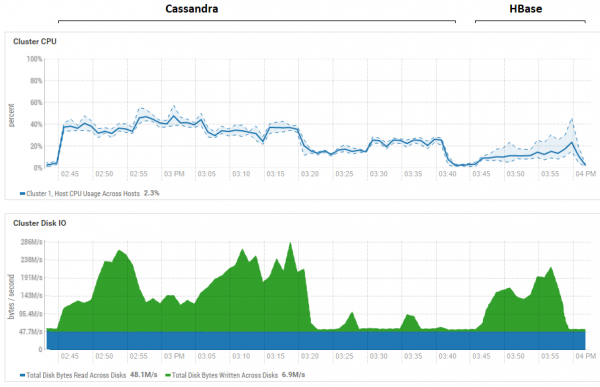
Paveikslėlyje parodytas abiejų duomenų bazių visų bandymų iš eilės panaudojimas.
Kalbant apie galingą HB skaitymo pranašumą. Čia matote, kad abiejų duomenų bazių disko panaudojimas skaitymo metu yra labai mažas (skaitymo testai yra paskutinė kiekvienos duomenų bazės testavimo ciklo dalis, pavyzdžiui, CS tai yra nuo 15:20 iki 15:40). HB atveju priežastis aiški – dauguma duomenų kabo atmintyje, memstore, o dalis yra talpykloje blokatinėje. Kalbant apie CS, nelabai aišku, kaip jis veikia, bet disko perdirbimo taip pat nematyti, bet tik tuo atveju buvo bandyta įjungti cache row_cache_size_in_mb = 2048 ir nustatyti caching = {'keys': 'ALL', 'rows_per_partition': ' 2000000'}, bet tai dar labiau pablogino.
Taip pat verta dar kartą paminėti svarbų dalyką apie regionų skaičių HB. Mūsų atveju reikšmė buvo nurodyta 64. Jei ją sumažiname ir padarome lygų, pavyzdžiui, 4, tai skaitant greitis sumažėja 2 kartus. Priežastis ta, kad „memstore“ pildysis greičiau ir failai bus dažniau plaunami, o skaitant reikės apdoroti daugiau failų, o tai HB yra gana sudėtinga operacija. Realiomis sąlygomis tai gali būti išspręsta apgalvojus išankstinio padalijimo ir sutankinimo strategiją. Mes naudojame savarankiškai parašytą įrankį, kuris renka šiukšles ir nuolat fone suspaudžia HFiles. Visai įmanoma, kad DataStax testams jie skyrė tik 1 regioną vienai lentelei (tai nėra teisinga), ir tai šiek tiek paaiškintų, kodėl HB buvo toks prastesnis jų skaitymo testuose.
Iš to daromos šios preliminarios išvados. Darant prielaidą, kad atliekant bandymus didelių klaidų nebuvo padaryta, Cassandra atrodo kaip kolosas su molio pėdomis. Tiksliau, kol ji balansuoja ant vienos kojos, kaip paveikslėlyje straipsnio pradžioje, ji demonstruoja palyginti gerus rezultatus, tačiau kovoje tokiomis pačiomis sąlygomis pralaimi kategoriškai. Tuo pačiu metu, atsižvelgdami į žemą aparatinės įrangos procesoriaus panaudojimą, išmokome įdiegti du „RegionServer HB“ vienam pagrindiniam kompiuteriui ir taip padvigubinti našumą. Tie. Atsižvelgiant į išteklių panaudojimą, CS padėtis yra dar apgailėtina.
Žinoma, šie testai yra gana sintetiniai, o čia panaudotų duomenų kiekis yra palyginti nedidelis. Gali būti, kad jei pereitume prie terabaitų, situacija būtų kitokia, bet kol HB galime įkelti terabaitus, CS tai pasirodė problematiška. Jis dažnai išmesdavo OperationTimedOutException net su šiais tomais, nors atsakymo laukimo parametrai jau buvo kelis kartus padidinti, palyginti su numatytaisiais.
Tikiuosi, kad bendromis pastangomis rasime CS kliūtis ir jei pavyks tai paspartinti, tai įrašo pabaigoje būtinai papildysiu informaciją apie galutinius rezultatus.
UPD: Draugų patarimų dėka man pavyko pagreitinti skaitymą. Buvo:
159 644 operacijos (4 lentelės, 5 srautai, 100 partija).
Pridėta:
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
Ir aš žaidžiau su gijų skaičiumi. Rezultatas yra toks:
4 lentelės, 100 siūlų, partija = 1 (gabalas po gabalo): 301 969 operacijos
4 lentelės, 100 gijų, partija = 10: 447 608 operacijos
4 lentelės, 100 gijų, partija = 100: 625 655 operacijos
Vėliau pritaikysiu kitus derinimo patarimus, atliksiu visą bandymo ciklą ir rezultatus pridėsiu įrašo pabaigoje.
Šaltinis: www.habr.com
