

2019 metų vasario–kovo mėnesiais vyko socialinio tinklo sklaidos kanalo reitingavimo konkursas , kuriame mūsų komanda užėmė pirmąją vietą. Straipsnyje kalbėsiu apie varžybų organizavimą, išbandytus metodus ir „catboost“ nustatymus, skirtus mokymui apie didelius duomenis.

SNA hakatonas
Hakatonas tokiu pavadinimu rengiamas jau trečią kartą. Ją organizuoja socialinis tinklas ok.ru, atitinkamai užduotis ir duomenys yra tiesiogiai susiję su šiuo socialiniu tinklu.
SNA (social network analysis) šiuo atveju teisingiau suprantama ne kaip socialinio grafiko, o veikiau kaip socialinio tinklo analizė.
- 2014 m. užduotis buvo numatyti, kiek paspaudimų „Patinka“ sulauks įrašas.
- 2016 m. - VVZ užduotis (galbūt esate susipažinę), arčiau socialinio grafiko analizės.
- 2019 m. naudotojo sklaidos kanalo reitingavimas pagal tikimybę, kad vartotojui įrašas patiks.
Negaliu pasakyti apie 2014 metus, bet 2016 ir 2019 metais, be duomenų analizės gebėjimų, prireikė ir įgūdžių dirbant su dideliais duomenimis. Manau, kad šiuose konkursuose mane patraukė mašininio mokymosi ir didelių duomenų apdorojimo problemų derinys, o mano patirtis šiose srityse padėjo man laimėti.
mlbootcamp
2019 metais konkursas buvo organizuotas platformoje .
Konkursas internete prasidėjo vasario 7 d., jį sudarė 3 užduotys. Kiekvienas galėjo užsiregistruoti svetainėje, atsisiųsti ir pakrauti savo automobilį kelioms valandoms. Pasibaigus internetiniam etapui kovo 15 d., 15 geriausių kiekvieno konkūro renginio buvo pakviesti į Mail.ru biurą offline etapui, kuris vyko kovo 30 – balandžio 1 d.
Užduotis
Šaltinio duomenys pateikia vartotojo ID (userId) ir įrašo ID (objectId). Jei vartotojui buvo parodytas įrašas, duomenyse yra eilutė, kurioje yra userId, objectId, vartotojų reakcijos į šį įrašą (atsiliepimai) ir įvairių funkcijų arba nuorodų į paveikslėlius ir tekstus rinkinys.
| Vartotojo ID | objekto ID | savininko ID | grįžtamasis ryšys | vaizdai |
|---|---|---|---|---|
| 3555 | 22 | 5677 | [patiko, paspaudėte] | [hash1] |
| 12842 | 55 | 32144 | [nepatiko] | [hash2,hash3] |
| 13145 | 35 | 5677 | [paspaudė, bendrino] | [hash2] |
Bandymo duomenų rinkinyje yra panaši struktūra, tačiau trūksta grįžtamojo ryšio lauko. Užduotis yra numatyti „patinka“ reakcijos buvimą grįžtamojo ryšio lauke.
Pateikimo failo struktūra yra tokia:
| Vartotojo ID | Rūšiuotas sąrašas[objekto ID] |
|---|---|
| 123 | 78,13,54,22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Metrika yra vidutinis naudotojų ROC AUC.
Išsamesnį duomenų aprašymą rasite adresu. Ten taip pat galite atsisiųsti duomenis, įskaitant testus ir nuotraukas.
Internetinė scena
Internetiniame etape užduotis buvo padalinta į 3 dalis
- — apima visas funkcijas, išskyrus vaizdus ir tekstus;
- — apima tik informaciją apie vaizdus;
- — apima informaciją tik apie tekstus.
Scena neprisijungus
Neprisijungus, duomenys apėmė visas funkcijas, o tekstų ir vaizdų buvo nedaug. Duomenų rinkinyje buvo 1,5 karto daugiau eilučių, kurių jau buvo daug.
Problemos sprendimas
Kadangi darbe darau CV, savo kelionę šiame konkurse pradėjau nuo užduoties „Vaizdai“. Pateikti duomenys buvo userId, objectId, ownerId (grupė, kurioje buvo paskelbtas įrašas), įrašo kūrimo ir rodymo laiko žymos ir, žinoma, šio įrašo vaizdas.
Sukūrus keletą funkcijų, pagrįstų laiko žymomis, kita idėja buvo paimti priešpaskutinį neurono sluoksnį, iš anksto apmokytą „imagenet“ tinkle, ir išsiųsti šiuos įterpimus, kad būtų padidintas.
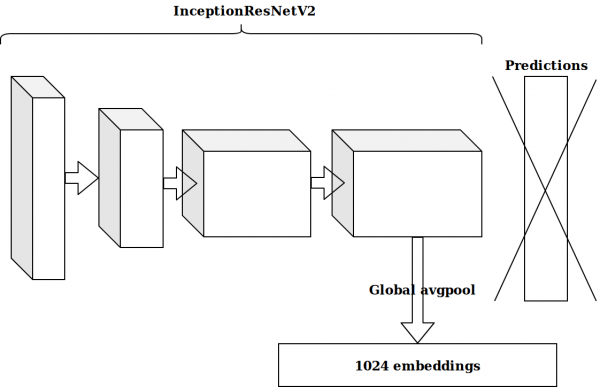
Rezultatai nebuvo įspūdingi. Įterpimai iš „imagenet“ neurono yra nesvarbu, pagalvojau, man reikia sukurti savo automatinį kodavimo įrenginį.
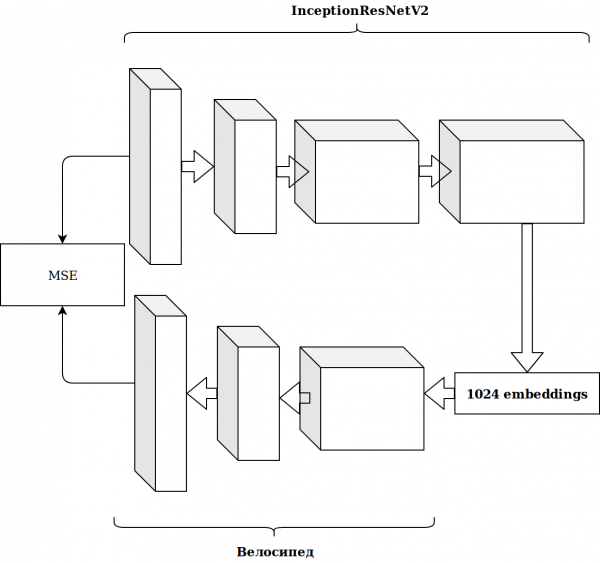
Tai užtruko daug laiko, o rezultatas nepagerėjo.
Funkcijų generavimas
Darbas su vaizdais užima daug laiko, todėl nusprendžiau padaryti ką nors paprastesnio.
Kaip iš karto matote, duomenų rinkinyje yra keletas kategoriškų ypatybių ir, kad per daug nesivargintų, tiesiog paėmiau catboost. Sprendimas buvo puikus, be jokių nustatymų iš karto patekau į pirmąją pirmaujančiųjų sąrašo eilutę.
Duomenų yra gana daug ir jie išdėlioti parketo formatu, tad negalvojęs paėmiau scala ir pradėjau rašyti viską kibirkštiniu būdu.
Paprasčiausios funkcijos, kurios suteikė daugiau augimo nei vaizdo įterpimas:
- kiek kartų objektoId, userId ir ownerId pasirodė duomenyse (turėtų koreliuoti su populiarumu);
- kiek įrašų userId matė iš ownerId (turėtų koreliuoti su vartotojo susidomėjimu grupe);
- kiek unikalių vartotojų ID peržiūrėjo savininko ID įrašus (atspindi grupės auditorijos dydį).
Iš laiko žymų buvo galima gauti dienos laiką, kuriuo vartotojas žiūrėjo sklaidos kanalą (rytas / popietė / vakaras / naktis). Sujungę šias kategorijas galite toliau kurti funkcijas:
- kiek kartų userId prisijungė vakare;
- kuriuo metu šis įrašas dažniausiai rodomas (objectId) ir pan.
Visa tai palaipsniui gerino rodiklius. Tačiau treniruočių duomenų rinkinio dydis yra apie 20 mln. įrašų, todėl funkcijų pridėjimas labai sulėtino treniruotę.
Pergalvojau savo požiūrį į duomenų naudojimą. Nors duomenys priklauso nuo laiko, akivaizdžių informacijos nutekėjimų „ateityje“ nepastebėjau, vis dėlto, tik tuo atveju, suskaidžiau juos taip:
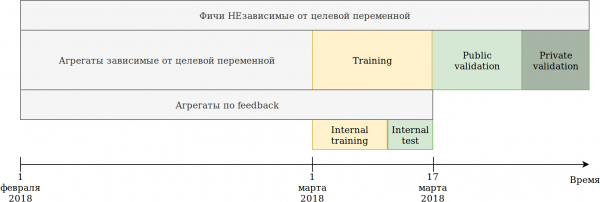
Mums pateiktas mokymų komplektas (vasario mėn. ir kovo 2 savaitės) buvo padalintas į 2 dalis.
Modelis buvo apmokytas remiantis pastarųjų N dienų duomenimis. Aukščiau aprašyti agregatai buvo sukurti remiantis visais duomenimis, įskaitant testą. Tuo pačiu metu atsirado duomenų, kuriais remiantis galima sukurti įvairias tikslinio kintamojo kodavimus. Paprasčiausias būdas yra pakartotinai naudoti kodą, kuris jau kuria naujas funkcijas, ir tiesiog pateikti jam duomenis, kurių jis nebus apmokytas, ir taikykite = 1.
Taigi, gavome panašias funkcijas:
- Kiek kartų userId matė įrašą grupėje ownerId;
- Kiek kartų userId patiko įrašas grupėje ownerId;
- Procentas įrašų, kurie userId patiko iš savininkoId.
Tai yra, paaiškėjo vidutinis tikslinis kodavimas dalyje duomenų rinkinio įvairiems kategorinių požymių deriniams. Iš esmės „catboost“ taip pat kuria tikslinę kodavimą ir šiuo požiūriu jokios naudos nėra, tačiau, pavyzdžiui, tapo įmanoma suskaičiuoti unikalių vartotojų, kuriems patiko šios grupės įrašai, skaičių. Tuo pačiu buvo pasiektas pagrindinis tikslas – mano duomenų rinkinys buvo kelis kartus sumažintas ir buvo galima toliau generuoti funkcijas.
Nors „catboost“ gali sukurti kodavimą tik pagal patikusią reakciją, grįžtamasis ryšys turi ir kitų reakcijų: bendrinamas dar kartą, nepatiko, nepatinka, spustelėtas, ignoruojamas, kodavimas gali būti atliekamas rankiniu būdu. Perskaičiavau visų rūšių suvestinius duomenis ir pašalinau mažai svarbias funkcijas, kad nepadidinčiau duomenų rinkinio.
Tuo metu aš buvau pirmoje vietoje dideliu skirtumu. Vienintelis painiavos dalykas buvo tai, kad vaizdo įterpimas beveik neaugo. Kilo mintis viską atiduoti catboostui. Sujungiame Kmeans vaizdus ir gauname naują kategorišką funkciją imageCat.
Štai keletas klasių po rankinio filtravimo ir klasterių, gautų iš KMeans, sujungimo.
Remdamiesi „imageCat“ generuojame:
- Naujos kategoriškos savybės:
- Kurį imageCat dažniausiai peržiūrėjo userId;
- Kuris imageCat dažniausiai rodo savininko ID;
- Kuris imageCat dažniausiai patiko userId;
- Įvairūs skaitikliai:
- Kiek unikalių imageCat peržiūrėjo userId;
- Apie 15 panašių funkcijų ir tikslinė koduotė, kaip aprašyta aukščiau.
Tekstai
Rezultatai įvaizdžio konkurse man tiko ir nusprendžiau išbandyti savo jėgas tekstuose. Aš anksčiau mažai dirbau su tekstais ir, kvaila, dieną užmušiau tf-idf ir svd. Tada pamačiau bazinę liniją su doc2vec, kuri atlieka būtent tai, ko man reikia. Šiek tiek pakoregavęs doc2vec parametrus, gavau teksto įterpimus.
Ir tada aš tiesiog pakartotinai panaudojau vaizdų kodą, kuriame vaizdų įterpimus pakeičiau teksto įterpimais. Dėl to teksto konkurse užėmiau 2 vietą.
Bendradarbiavimo sistema
Liko vienas konkursas, kurio dar „nepakišau“ lazda, o sprendžiant pagal AUC pirmaujančiųjų sąraše, būtent šių varžybų rezultatai turėjo turėti didžiausią įtaką offline etape.
Paėmiau visas ypatybes, kurios buvo šaltinio duomenyse, pasirinkau kategoriškus ir apskaičiavau tuos pačius suvestinius rodiklius kaip ir vaizdams, išskyrus ypatybes pagal pačias nuotraukas. Vien įtraukus tai į „catboost“, užėmiau 2 vietą.
Pirmieji catboost optimizavimo žingsniai
Viena pirmoji ir dvi antrosios vietos mane džiugino, bet buvo supratimas, kad nieko ypatingo nepadariau, vadinasi, galiu tikėtis pozicijos praradimo.
Konkurso užduotis yra reitinguoti įrašus vartotojo viduje, o aš visą tą laiką sprendžiau klasifikavimo problemą, tai yra, optimizavau neteisingą metriką.
Pateiksiu paprastą pavyzdį:
| Vartotojo ID | objekto ID | prognozė | pagrindine tiesa |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 1 |
| 1 | 14 | 0.5 | 0 |
| 2 | 15 | 0.4 | 0 |
| 2 | 16 | 0.3 | 1 |
Padarykime nedidelį pertvarkymą
| Vartotojo ID | objekto ID | prognozė | pagrindine tiesa |
|---|---|---|---|
| 1 | 10 | 0.9 | 1 |
| 1 | 11 | 0.8 | 1 |
| 1 | 12 | 0.7 | 1 |
| 1 | 13 | 0.6 | 0 |
| 2 | 16 | 0.5 | 1 |
| 2 | 15 | 0.4 | 0 |
| 1 | 14 | 0.3 | 1 |
Gauname tokius rezultatus:
| Modelis | AUC | User1 AUC | User2 AUC | vidutinis AUC |
|---|---|---|---|---|
| Parinktis 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Parinktis 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Kaip matote, bendros AUC metrikos gerinimas nereiškia, kad pagerinsite vidutinę vartotojo AUC metriką.
Catboost iš dėžės. Skaičiau apie reitingavimo metriką, kai naudojate catboost ir nustatykite YetiRankPairwise treniruotis per naktį. Rezultatas nebuvo įspūdingas. Nusprendęs, kad esu nepakankamai apmokytas, pakeičiau klaidos funkciją į QueryRMSE, kuri, sprendžiant iš „catboost“ dokumentacijos, susilieja greičiau. Galų gale gavau tokius pačius rezultatus kaip ir treniruodamasis klasifikacijoje, tačiau šių dviejų modelių ansambliai davė neblogą prieaugį, dėl ko visose trijose varžybose užėmiau pirmąją vietą.
Likus 5 minutėms iki „Bendradarbiaujančių sistemų“ konkurso internetinio etapo uždarymo, Sergejus Šalnovas mane perkėlė į antrąją vietą. Tolimesnį kelią ėjome kartu.
Pasiruošimas neprisijungus etapui
Mums buvo garantuota pergalė internetiniame etape su RTX 2080 TI vaizdo plokšte, tačiau pagrindinis 300 000 rublių prizas ir, greičiausiai, net galutinė pirmoji vieta privertė atidirbti šias 2 savaites.
Kaip paaiškėjo, Sergejus taip pat naudojo „catboost“. Apsikeitėme idėjomis ir savybėmis, aš sužinojau apie kuriame buvo atsakymai į daugelį mano klausimų ir net į tuos, kurių iki tol dar neturėjau.
Peržiūrėjus ataskaitą kilo mintis, kad reikia grąžinti visus parametrus į numatytąsias reikšmes, o nustatymus atlikti labai atsargiai ir tik sutvarkius funkcijų rinkinį. Dabar vienos treniruotės truko apie 15 valandų, tačiau vienam modeliui pavyko pasiekti didesnį greitį nei gautas ansamblyje su reitingavimu.
Funkcijų generavimas
Bendradarbiaujančių sistemų konkurse daugelis funkcijų yra vertinamos kaip svarbios modeliui. Pavyzdžiui, auditweights_spark_svd – svarbiausias ženklas, bet informacijos apie tai, ką jis reiškia, nėra. Pagalvojau, kad vertėtų suskaičiuoti įvairius agregatus pagal svarbias savybes. Pavyzdžiui, vidutinis auditweights_spark_svd pagal naudotoją, grupę, pagal objektą. Tą patį galima apskaičiuoti naudojant duomenis, pagal kuriuos treniruotės nevykdomos, o tikslas = 1, tai yra, vidurkis auditweights_spark_svd vartotojas pagal jam patikusius objektus. Be to, svarbūs ženklai auditweights_spark_svd, buvo keletas. Štai keletas iš jų:
- auditweightsCtrGender
- audito svorisCtrHigh
- userOwnerCounterCreateLikes
Pavyzdžiui, vidurkis auditweightsCtrGender pagal userId tai pasirodė svarbi funkcija, kaip ir vidutinė vertė userOwnerCounterCreateLikes pagal userId+ownerId. Tai jau turėtų priversti susimąstyti, kad reikia suprasti laukų reikšmę.
Taip pat buvo svarbios savybės auditweightsLikesCount и auditweightsShowsCount. Padalijus vieną iš kitos, gauta dar svarbesnė savybė.
Duomenų nutekėjimas
Konkurencija ir gamybos modeliavimas yra labai skirtingos užduotys. Rengiant duomenis labai sunku atsižvelgti į visas detales ir neperteikti kažkokios nereikšmingos informacijos apie testo tikslinį kintamąjį. Jei kuriame gamybinį sprendimą, treniruodami modelį stengsimės nenaudoti duomenų nutekėjimo. Bet jei norime laimėti konkursą, duomenų nutekėjimas yra geriausios savybės.
Išstudijavę duomenis matote, kad pagal objectId reikšmes auditweightsLikesCount и auditweightsShowsCount pokytis, o tai reiškia, kad šių funkcijų maksimalių verčių santykis daug geriau atspindės konversiją po to, nei santykis rodymo metu.
Pirmas nuotėkis, kurį radome auditweightsLikesCountMax/auditweightsShowsCountMax.
Bet ką daryti, jei pažvelgsime į duomenis atidžiau? Rūšiuokime pagal pasirodymo datą ir gaukime:
| objekto ID | Vartotojo ID | auditweightsShowsCount | auditweightsLikesCount | taikinys (patinka) |
|---|---|---|---|---|
| 1 | 1 | 12 | 3 | tikriausiai ne |
| 1 | 2 | 15 | 3 | gal taip |
| 1 | 3 | 16 | 4 |
Nustebino, kai radau pirmą tokį pavyzdį ir paaiškėjo, kad mano spėjimas nepasitvirtino. Tačiau, atsižvelgdami į tai, kad maksimalios šių charakteristikų vertės objekte padidėjo, mes nebuvome tingūs ir nusprendėme rasti auditweightsShowsCountNext и auditweightsLikesCountNextty vertės kitą akimirką. Pridėjus funkciją
(auditweightsShowsCountNext-auditweightsShowsCount)/(auditweightsLikesCount-auditweightsLikesCountNext) greitai padarėme staigų šuolį.
Panašūs nutekėjimai gali būti naudojami ieškant toliau nurodytų verčių userOwnerCounterCreateLikes skiltyje userId+ownerId ir, pvz., auditweightsCtrGender objekto ID+userGender. Radome 6 panašius laukus su nutekėjimais ir iš jų ištraukėme kuo daugiau informacijos.
Iki to laiko iš bendradarbiavimo funkcijų buvome išspaudę kuo daugiau informacijos, bet prie vaizdo ir teksto konkursų nebegrįžome. Man kilo puiki idėja patikrinti: kiek duoda funkcijos, tiesiogiai pagrįstos vaizdais ar tekstais atitinkamuose konkursuose?
Vaizdo ir teksto konkursuose nebuvo jokių nutekėjimų, tačiau iki to laiko grąžinau numatytuosius „catboost“ parametrus, išvaliau kodą ir pridėjau keletą funkcijų. Iš viso buvo:
| sprendimas | greitai |
|---|---|
| Daugiausia su vaizdais | 0.6411 |
| Daugiausia nėra vaizdų | 0.6297 |
| Antros vietos rezultatas | 0.6295 |
| sprendimas | greitai |
|---|---|
| Maksimaliai su tekstais | 0.666 |
| Maksimaliai be tekstų | 0.660 |
| Antros vietos rezultatas | 0.656 |
| sprendimas | greitai |
|---|---|
| Maksimaliai bendradarbiaujant | 0.745 |
| Antros vietos rezultatas | 0.723 |
Tapo akivaizdu, kad vargu ar pavyks daug išspausti iš tekstų ir vaizdų, ir išmėginę porą įdomiausių idėjų, su jomis nebedirbame.
Tolesnė funkcijų generacija bendradarbiavimo sistemose nepadidėjo, todėl pradėjome reitinguoti. Internetiniame etape klasifikavimo ir reitingavimo ansamblis man davė nedidelį padidėjimą, nes paaiškėjo, kad aš nepakankamai išmokau klasifikaciją. Nė viena iš klaidų funkcijų, įskaitant YetiRanlPairwise, nepateikė rezultato, kurį padarė LogLoss (0,745 prieš 0,725). Vis dar buvo vilties dėl QueryCrossEntropy, kurios nepavyko paleisti.
Scena neprisijungus
Neprisijungus duomenų struktūra išliko ta pati, tačiau buvo nedidelių pakeitimų:
- identifikatoriai userId, objectId, ownerId buvo perrinkti atsitiktine tvarka;
- keli ženklai buvo pašalinti, o keli pervadinti;
- duomenys išaugo maždaug 1,5 karto.
Be išvardytų sunkumų, buvo vienas didelis pliusas: komandai buvo skirtas didelis serveris su RTX 2080TI. Ilgai mėgaujuosi htop.
Buvo tik viena mintis – tiesiog atgaminti tai, kas jau yra. Praleidę porą valandų kurdami aplinką serveryje, pamažu pradėjome tikrinti, ar rezultatai atkuriami. Pagrindinė problema, su kuria susiduriame, yra duomenų kiekio padidėjimas. Nusprendėme šiek tiek sumažinti apkrovą ir nustatyti „catboost“ parametrą ctr_complexity=1. Tai šiek tiek sumažina greitį, bet mano modelis pradėjo veikti, rezultatas buvo geras - 0,733. Sergejus, skirtingai nei aš, nepaskirstė duomenų į 2 dalis ir mokėsi pagal visus duomenis, nors tai davė geriausią rezultatą internetiniame etape, neprisijungus buvo daug sunkumų. Jei naudotume visas sukurtas funkcijas ir pabandytume jas įtraukti į „catboost“, niekas neveiks prisijungus. Sergejus atliko tipo optimizavimą, pavyzdžiui, konvertuodamas float64 į float32 tipus. Informacijos apie atminties optimizavimą galite rasti pandose. Dėl to Sergejus treniravosi su CPU naudodamas visus duomenis ir gavo apie 0,735.
Šių rezultatų pakako laimėti, tačiau slėpėme savo tikrąjį greitį ir negalėjome būti tikri, kad kitoms komandoms taip nesielgia.
Kovok iki paskutinio
Catboost derinimas
Mūsų sprendimas buvo pilnai atkurtas, pridėjome tekstinių duomenų ir vaizdų funkcijas, tad beliko sureguliuoti catboost parametrus. Sergejus treniravosi prie procesoriaus su nedideliu iteracijų skaičiumi, o aš – su ctr_complexity=1. Liko viena diena, o jei tik pridėtumėte pakartojimų arba padidintumėte ctr_complexity, tada iki ryto galėtumėte pasiekti dar didesnį greitį ir vaikščioti visą dieną.
Neprisijungus, greitis gali būti labai lengvai paslėptas, tiesiog pasirenkant ne geriausią sprendimą svetainėje. Tikėjomės drastiškų pokyčių lyderių lentelėje paskutinėmis minutėmis iki pateikimo pabaigos ir nusprendėme nesustoti.
Iš Anos vaizdo įrašo sužinojau, kad norint pagerinti modelio kokybę, geriausia pasirinkti šiuos parametrus:
- mokymosi_norma — Numatytoji vertė apskaičiuojama pagal duomenų rinkinio dydį. Didinant mokymosi greitį, reikia padidinti iteracijų skaičių.
- l2_lapo_reg — Reguliavimo koeficientas, numatytoji reikšmė 3, pageidautina pasirinkti nuo 2 iki 30. Sumažinus vertę, padidėja perkrovimas.
- pakavimo_temperatūra — prideda atsitiktinių imties objektų svorius. Numatytoji reikšmė yra 1, kai svoriai parenkami iš eksponentinės skirstinio. Sumažinus vertę, padidėja persirengimas.
- atsitiktinis_stiprumas — Įtakoja padalijimų pasirinkimą konkrečioje iteracijoje. Kuo didesnis atsitiktinis_stiprumas, tuo didesnė tikimybė, kad bus pasirinktas mažos svarbos padalijimas. Kiekvienoje paskesnėje iteracijoje atsitiktinumas mažėja. Sumažinus vertę, padidėja persirengimas.
Kiti parametrai turi daug mažesnę įtaką galutiniam rezultatui, todėl jų atrinkti nebandžiau. Viena mano GPU duomenų rinkinio mokymo iteracija su ctr_complexity=1 užtruko 20 minučių, o pasirinkti parametrai sumažintame duomenų rinkinyje šiek tiek skyrėsi nuo optimalių visame duomenų rinkinyje. Galų gale aš padariau apie 30 pakartojimų su 10% duomenų, o tada dar apie 10 visų duomenų iteracijų. Tai pasirodė maždaug taip:
- mokymosi_norma Aš padidinau 40% nuo numatytojo;
- l2_lapo_reg paliko tą patį;
- pakavimo_temperatūra и atsitiktinis_stiprumas sumažintas iki 0,8.
Galime daryti išvadą, kad modelis buvo nepakankamai apmokytas pagal numatytuosius parametrus.
Labai nustebau, kai pamačiau rezultatą pirmaujančiųjų sąraše:
| Modelis | modelis 1 | modelis 2 | modelis 3 | ansamblis |
|---|---|---|---|---|
| Be tiuningo | 0.7403 | 0.7404 | 0.7404 | 0.7407 |
| Su derinimu | 0.7406 | 0.7405 | 0.7406 | 0.7408 |
Pati padariau išvadą, kad jei nereikia greito modelio pritaikymo, tada parametrų pasirinkimą geriau pakeisti kelių modelių ansambliu, naudojant neoptimizuotus parametrus.
Sergejus optimizavo duomenų rinkinio dydį, kad jis būtų paleistas GPU. Paprasčiausias variantas yra iškirpti dalį duomenų, tačiau tai galima padaryti keliais būdais:
- palaipsniui pašalinkite seniausius duomenis (vasario pradžioje), kol duomenų rinkinys pradės tilpti į atmintį;
- pašalinti mažiausią reikšmę turinčias funkcijas;
- pašalinti vartotojo ID, kuriems yra tik vienas įrašas;
- palikite tik teste esančius vartotojo ID.
Ir galiausiai iš visų variantų sukurkite ansamblį.
Paskutinis ansamblis
Iki vėlyvo paskutinės dienos vakaro išdėliojome savo modelių ansamblį, kuris davė 0,742. Per naktį paleidau savo modelį su ctr_complexity=2 ir vietoj 30 minučių jis treniravosi 5 valandas. Buvo suskaičiuota tik 4 val., o aš padariau paskutinį ansamblį, kuris viešoje lyderių lentelėje davė 0,7433.
Dėl skirtingų požiūrių į problemos sprendimą mūsų prognozės nebuvo stipriai koreliuojamos, o tai leido gerai padidinti ansamblį. Norint gauti gerą ansamblį, geriau naudoti neapdorotus modelio prognozes (prediction_type='RawFormulaVal') ir nustatyti scale_pos_weight=neg_count/pos_count.
Svetainėje galite pamatyti .
Kiti sprendimai
Daugelis komandų laikėsi rekomendacijų sistemos algoritmų kanonų. Aš, nebūdamas šios srities ekspertas, negaliu jų įvertinti, bet prisimenu 2 įdomius sprendimus.
- . Nikolajus, būdamas Mail.ru darbuotojas, į prizus nesikreipė, todėl jo tikslas buvo ne pasiekti maksimalų greitį, o gauti lengvai keičiamą sprendimą.
- Žiuri prizą laimėjusios komandos sprendimas, pagrįstas , leidžia labai gerai sugrupuoti vaizdus be rankinio darbo.
išvada
Kas labiausiai įsiminė į atmintį:
- Jei duomenyse yra kategoriškų ypatybių ir žinote, kaip teisingai atlikti tikslinį kodavimą, vis tiek geriau išbandyti catboost.
- Jei dalyvaujate konkurse, neturėtumėte gaišti laiko pasirinkdami kitus parametrus, išskyrus mokymosi greitį ir iteracijas. Greitesnis sprendimas – sudaryti kelių modelių ansamblį.
- Padidinimų galima išmokti naudojant GPU. „Catboost“ gali labai greitai išmokti GPU, tačiau sunaudoja daug atminties.
- Idėjų kūrimo ir testavimo metu geriau nustatyti mažą rsm~=0.2 (tik CPU) ir ctr_complexity=1.
- Skirtingai nuo kitų komandų, mūsų modelių ansamblis davė didelį prieaugį. Mes tik keitėmės idėjomis ir rašėme įvairiomis kalbomis. Mes turėjome skirtingą požiūrį į duomenų padalijimą ir, manau, kiekvienas turėjo savo klaidų.
- Neaišku, kodėl reitingų optimizavimas buvo blogesnis nei klasifikavimo optimizavimas.
- Įgijau patirties dirbant su tekstais ir supratimą, kaip kuriamos rekomendacinės sistemos.

Ačiū organizatoriams už emocijas, žinias ir gautus prizus.
Šaltinis: www.habr.com
