

Kanariefågeln är en liten fågel som hela tiden sjunger. Dessa fåglar är känsliga för metan och kolmonoxid. Även från en liten koncentration av överskottsgaser i luften förlorar de medvetandet eller dör. Guldgrävare och gruvarbetare tog fåglarna till gruvan: medan kanariefågeln sjunger kan du arbeta, om du är tyst - det finns gas i gruvan och det är dags att gå. Gruvarbetarna offrade en liten fågel för att komma ur gruvorna levande.

En liknande praxis har funnits inom IT. Till exempel i standarduppgiften att distribuera en ny version av en tjänst eller applikation till produktion med testning innan dess. Testmiljön kan bli för dyr, automatiserade tester täcker inte allt du vill, och att inte testa och offra kvalitet är riskabelt. Det är här Canary Deployment-metoden kommer väl till pass, där en del verklig produktionstrafik riktas mot den nya versionen. Tillvägagångssättet hjälper på ett säkert sätt kolla ny version för produktion, offra lite för en stor sak. Mer information om hur tillvägagångssättet fungerar, vad som är användbart och hur man implementerar det, kommer att berätta Andrey Markelov (), om exemplet med implementering i företaget Infobip.
Andrey Markelov - Lead Software Engineer på Infobip, har utvecklat Java-applikationer inom ekonomi och telekommunikation i 11 år. Utvecklar produkter med öppen källkod, deltar aktivt i Atlassian Community och skriver plugins för Atlassian-produkter. Evangelist av Prometheus, Docker och Redis.

Om Infobip
Det är en global telekommunikationsplattform som tillåter banker, återförsäljare, nätbutiker och transportföretag att skicka meddelanden till sina kunder via SMS, push, brev och röstmeddelanden. I en sådan verksamhet är stabilitet och tillförlitlighet viktigt så att kunderna får meddelanden i tid.
Infobip IT-infrastruktur i antal:
- 15 datacenter runt om i världen;
- 500 unika tjänster i drift;
- 2500 instanser av tjänster, vilket är mycket mer än kommandon;
- 4,5 TB månatlig trafik;
- 4,5 miljarder telefonnummer;
Verksamheten växer, och med det antalet releaser. Vi spenderar på 60 släpp per dageftersom kunderna vill ha fler funktioner och kraft. Men det här är svårt - det finns många tjänster, men få kommandon. Du måste snabbt skriva kod som ska fungera i produktion utan fel.
Släpp
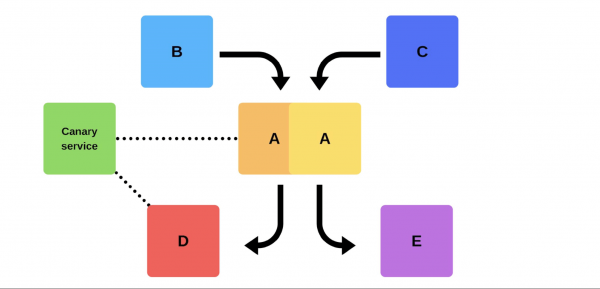
En typisk release går så här. Till exempel finns det tjänster A, B, C, D och E, var och en av dem utvecklas av ett separat team.
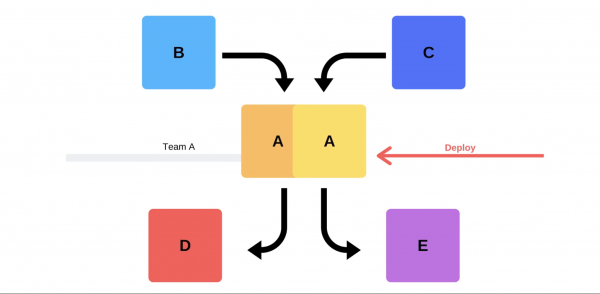
Vid något tillfälle beslutar teamet av tjänst A att distribuera en ny version, men teamen av tjänster B, C, D och E vet inte om det. Det finns två alternativ för hur serviceteam A kommer att agera.
Kommer hålla inkrementell utgivning: byt först ut en version och sedan den andra.
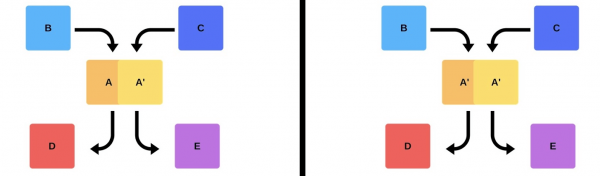
Men det finns ett andra alternativ: kommandot kommer att hitta ytterligare kapacitet och maskiner, distribuera den nya versionen och byt sedan routern, och versionen börjar fungera för produktion.

Hur som helst är det nästan alltid problem efter installationen, även om versionen är testad. Du kan testa manuellt, du kan göra det automatiskt, du kan inte testa - problem kommer att uppstå i alla fall. Det enklaste och mest korrekta sättet att lösa dem är att gå tillbaka till den fungerande versionen. Först då kan du hantera skadan, med orsakerna och rätta till dem.
Så vad vill vi?
Vi behöver inga problem. Om kunderna hittar dem snabbare än oss kommer det att skada deras rykte. Därför måste vi hitta problem snabbare än kunder. Genom att arbeta proaktivt minimerar vi skador.
Samtidigt vill vi påskynda utbyggnadenså att det sker snabbt, enkelt, naturligt och utan press från laget. Ingenjörer, DevOps-ingenjörer och programmerare måste skyddas – lanseringen av en ny version är stressande. Laget är inte förbrukat, vi strävar rationell användning av mänskliga resurser.
Implementeringsproblem
Kundtrafiken är oförutsägbar. Det är omöjligt att förutsäga när klienttrafiken kommer att vara som lägst. Vi vet inte var eller när kunder kommer att starta sina kampanjer - kanske ikväll i Indien, imorgon i Hong Kong. Med tanke på den stora tidsskillnaden garanterar inte driftsättning även klockan 2:XNUMX att kunderna inte kommer att påverkas.
Leverantörsproblem. Budbärare och leverantörer är våra partners. Ibland har de krascher som orsakar fel under distributionen av nya versioner.
Utdelade lag. Teamen som utvecklar klientsidan och backend finns i olika tidszoner. På grund av detta kan de ofta inte komma överens sinsemellan.
Datacenter kan inte upprepas på scenen. Det finns 200 rack i ett datacenter - du kan inte ens upprepa detta i en sandlåda.
Driftstoppoacceptabel! Vi har en felbudget när vi till exempel arbetar 99,99 % av tiden och den återstående procenten är "felmarginal". Att uppnå 100 % tillförlitlighet är omöjligt, men det är viktigt att ständigt övervaka fall och stillestånd.
Klassiska lösningar
Skriv kod utan buggar. När jag var en ung utvecklare kontaktade chefer mig med en begäran om att släppa utan buggar, men det är inte alltid möjligt.
Skriv prov. Tester fungerar, men ibland inte på det sätt som verksamheten vill. Att tjäna pengar är inte testets uppgift.
Testa på scen. Under 3,5 år av mitt arbete på Infobip har jag aldrig sett att scenens tillstånd åtminstone delvis sammanfaller med produktionen.
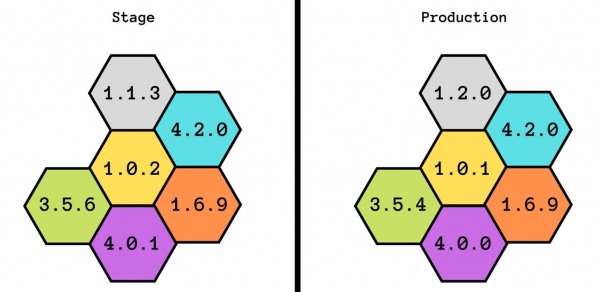
Vi försökte till och med utveckla denna idé: först hade vi en scen, sedan förproduktion och sedan förproduktion. Men detta hjälpte inte heller - de matchade inte ens i makten. Med stage kan vi garantera grundläggande funktionalitet, men vi vet inte hur det kommer att fungera under belastning.
Utgivningen är gjord av den som utvecklade den. Detta är en bra praxis: även om någon ändrar namnet på kommentaren lägger de omedelbart till den i produktionen. Detta hjälper till att utveckla ansvar och inte glömma de förändringar som gjorts.
Det finns också ytterligare komplikationer. Det är stressande för en utvecklare att lägga mycket tid på att manuellt kontrollera allt.
Överenskomna releaser. Det här alternativet erbjuds vanligtvis av ledningen: "Låt oss komma överens om att du varje dag kommer att testa och lägga till nya versioner." Det fungerar inte: det finns alltid ett kommando som väntar på alla andra, eller vice versa.
Röktester
Ett annat sätt att lösa våra distributionsproblem. Tänk på hur röktester fungerar i det föregående exemplet, när team A vill distribuera en ny version.
Först distribuerar teamet en instans till produktion. Meddelanden till instansen från mocks simulerar verklig trafikför att matcha normal daglig trafik. Om allt är bra byter teamet den nya versionen till användartrafik.
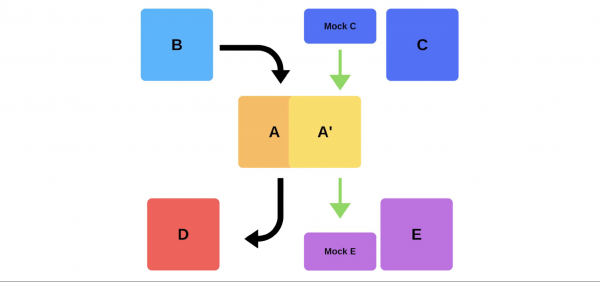
Det andra alternativet är att distribuera med extra järn. Teamet testar det för produktion, växlar sedan och allt fungerar.
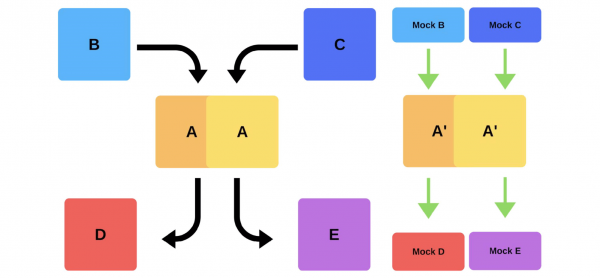
Nackdelar med röktester:
- Tester kan inte lita på. Var får man samma trafik som för produktion? Du kan använda igår eller för en vecka sedan, men det matchar inte alltid den nuvarande.
- Svårt att underhålla. Du måste underhålla testkonton, ständigt återställa dem före varje distribution, när aktiva poster skickas till förvaret. Det här är svårare än att skriva ett test i din egen sandlåda.
Den enda bonusen här är prestanda kan testas.
Canary releaser
På grund av bristerna i röktester började vi använda kanariefågel.
En praxis som liknar hur gruvarbetare använde kanariefåglar för att indikera nivån av gaser som hittade sin väg till IT. Vi låter lite riktig produktionstrafik till den nya versionensamtidigt som du försöker uppfylla Service Level Agreement (SLA). SLA är vår "rätt att göra ett misstag", som vi kan använda en gång om året (eller under någon annan tidsperiod). Om allt går bra kommer vi att lägga till mer trafik. Om inte kommer vi att returnera de tidigare versionerna.
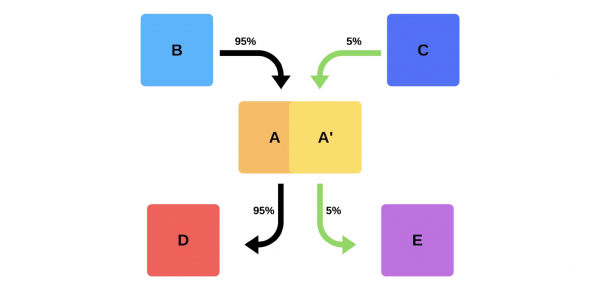
Genomförande och nyanser
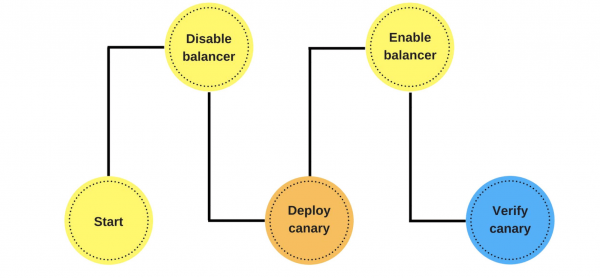
Hur implementerade vi kanariefågelsläpp? Till exempel skickar en grupp kunder meddelanden via vår tjänst.
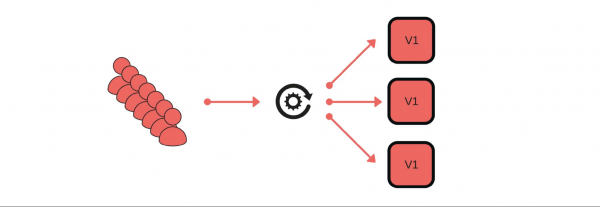
Utplaceringen går till så här: vi tar bort en nod under balanseraren (1), ändrar versionen (2) och låter lite trafik separat (3).

I allmänhet kommer alla i gruppen att vara nöjda, även om en användare är missnöjd. Om allt är bra ändrar vi alla versioner.
Jag kommer att visa schematiskt hur det ser ut för mikrotjänster i de flesta fall.
Det finns Service Discovery och ytterligare två tjänster: S1N1 och S2. Den första tjänsten (S1N1) meddelar Service Discovery när den startar och Service Discovery kommer ihåg den. Den andra tjänsten med två noder (S2N1 och S2N2) meddelar också Service Discovery när den startar.
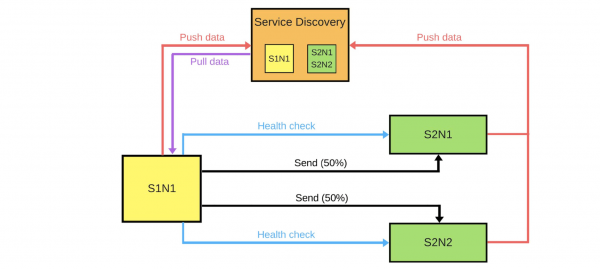
Den andra tjänsten för den första fungerar som en server. Den första ber Service Discovery om information om sina servrar, och när den tar emot den letar den efter och kontrollerar dem ("hälsokontroll"). När han kontrollerar kommer han att skicka meddelanden till dem.
När någon vill distribuera en ny version av den andra tjänsten, säger han till Service Discovery att den andra noden kommer att vara en kanariefågelnod: mindre trafik kommer att skickas till den, eftersom driftsättningen kommer att ske nu. Vi tar bort kanariefågelnoden under balanseraren och den första tjänsten skickar inte trafik till den.
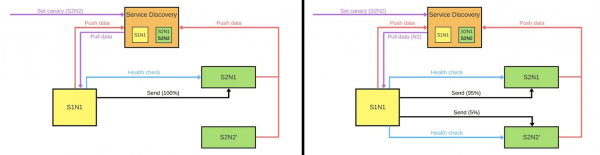
Vi ändrar versionen och Service Discovery vet att den andra noden nu är kanariefågel - du kan ge den mindre belastning (5%). Om allt är bra ändrar vi versionen, returnerar lasterna och jobbar vidare.
För att implementera allt detta behöver vi:
- balansering;
- övervakning aveftersom det är viktigt att veta vad varje användare förväntar sig och hur våra tjänster fungerar i detalj;
- versionsanalysatt förstå hur väl den nya versionen kommer att fungera i produktionen;
- automation - vi skriver distributionssekvensen (deployment pipeline).
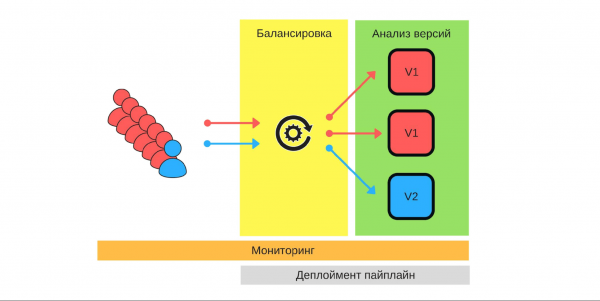
balansering
Det här är det första vi bör tänka på. Det finns två balanseringsstrategier.
Det enklaste alternativet när en nod är alltid kanariefågel. Den här noden får alltid mindre trafik och vi startar distributionen från den. Vid problem kommer vi att jämföra dess arbete före och under driftsättningen. Till exempel, om det finns 2 gånger fler fel, så har skadan ökat 2 gånger.
Kanariefågelnod ställs in under driftsättningsprocessen. När driftsättningen avslutas och vi tar bort kanariefågens nodstatus från den, kommer trafikbalansen att återställas. Med färre bilar får vi en rättvis fördelning.
övervakning
Hörnstenen för kanariefågelutsättningar. Vi måste förstå exakt varför vi gör detta och vilka mätvärden vi vill samla in.
Exempel på mätvärden vi samlar in från våra tjänster.
- Antal misstag, som skrivs till loggarna. Detta är en tydlig indikator på att allt fungerar som det ska. I allmänhet är detta ett bra mått.
- Exekveringstid för fråga (latens). Alla övervakar detta mått eftersom alla vill arbeta snabbt.
- Köstorlek (genomströmning).
- Antal lyckade svar per sekund.
- Utförandetid på 95 % av alla förfrågningar.
- Affärsstatistik: hur mycket pengar ett företag tjänar under en viss tid eller användarchurn. Dessa mätvärden för vår nya version kan vara viktigare än de som lagts till av ingenjörerna.
Exempel på mått i de flesta populära övervakningssystem.
Disken. Detta är något ökande värde, till exempel antalet fel. Detta mått är lätt att interpolera och studera diagrammet: igår var det 2 fel och idag 500, vilket betyder att något gick fel.
Antalet fel per minut eller per sekund är den viktigaste indikatorn som kan beräknas med Counter. Dessa data ger en tydlig bild av hur systemet fungerar på avstånd. Betrakta exemplet med en graf över antalet fel per sekund för två versioner av produktionssystemet.
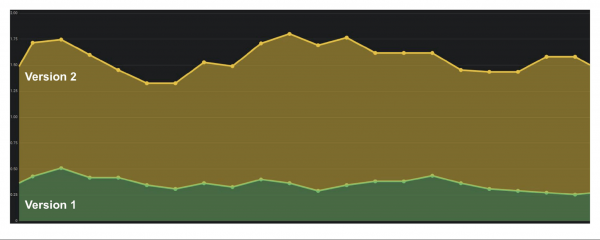
Det var få fel i den första versionen, kanske fungerade inte revisionen. I den andra versionen är allt mycket värre. Vi kan med säkerhet säga att det finns problem, så vi bör återställa den här versionen.
Mätare. Mätvärden liknar Counter, men vi registrerar värden som antingen kan öka eller minska. Till exempel exekveringstid för frågor eller köstorlek.
Grafen visar ett exempel på latens. Grafen visar att versionerna är lika, du kan arbeta med dem. Men tittar man noga kan man se hur värdet förändras. Om frågekörningstiden ökar när användare läggs till, är det omedelbart uppenbart att det finns problem - så var det inte tidigare.
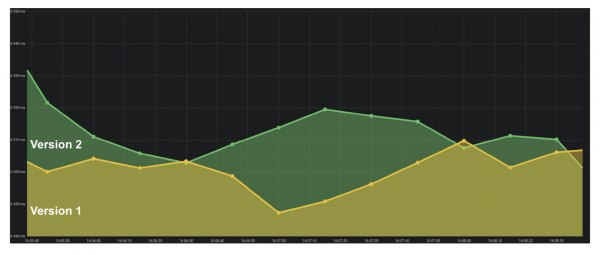
Sammanfattning. En av de viktigaste indikatorerna för företag är percentiler. Mätvärdet visar det 95% av fallen vårt system fungerar som vi vill. Vi kan acceptera om det finns problem någonstans, eftersom vi förstår den allmänna trenden, hur bra eller dåligt allt är.
Verktyg
ELK Stack. Du kan implementera kanariefågel med Elasticsearch - vi skriver fel till den när händelser inträffar. Med det enklaste API-anropet kan du få antalet fel vid varje given tidpunkt och jämföra med tidigare segment: GET /applg/_cunt?q=level:errr.
Prometheus. Han visade sig väl i Infobip. Det låter dig implementera flerdimensionella mätvärden eftersom etiketter används.
Vi kan använda level, instance, service, kombinera dem i ett system. Med hjälp offset du kan till exempel se värdet av ett värde för en vecka sedan med bara ett kommando GET /api/v1/query?query={query}var {query}:
rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)Versionsanalys
Det finns flera versionsstrategier.
Visa endast mätvärden för kanariefågelnoder. Ett av de enklaste alternativen: distribuera en ny version och studera bara arbetet. Men om ingenjören vid denna tidpunkt börjar studera loggarna och ständigt nervöst laddar om sidorna, så skiljer sig denna lösning inte från de andra.
Kanariefågelnod jämförs med vilken annan nod som helst. Detta är en jämförelse med andra instanser som körs med full trafik. Om det till exempel är sämre med liten trafik, eller inte bättre än på verkliga instanser, är något fel.
Kanarie-noden jämförs med sig själv tidigare. Noder allokerade till kanariefågel kan jämföras med historiska data. Till exempel, om allt var bra för en vecka sedan, då kan vi fokusera på dessa data för att förstå den nuvarande situationen.
Automation
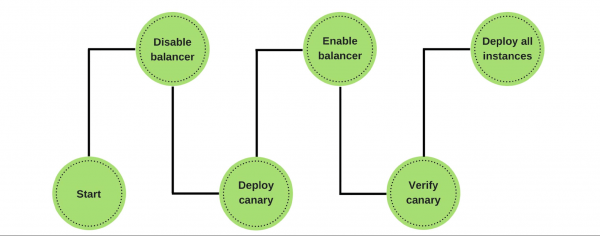
Vi vill befria ingenjörer från manuell jämförelse, så det är viktigt att implementera automatisering. Distributionspipelinen ser vanligtvis ut så här:
- vi börjar;
- ta bort noden från under balansen;
- ställ in en kanariefågelnod;
- slå på balanseraren med en begränsad mängd trafik;
- jämföra.
I detta skede implementerar vi automatisk jämförelse. Hur det kan se ut och varför det är bättre än verifiering efter implementering, låt oss titta på ett exempel från Jenkins.
Detta är pipelinen till Groovy.
while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Här i slingan ställer vi in att vi ska jämföra den nya noden i en timme. Om kanariefågelprocessen ännu inte har avslutat processen anropar vi funktionen. Hon rapporterar att allt är bra eller inte: def isOk = compare(srv, canary, time, base, offset, metrics).
Om allt är bra - sleep DEFAULT SLEEPt.ex. en sekund, och fortsätt. Om inte, avsluta — distributionen misslyckades.
Beskrivning av måtten. Låt oss se hur funktionen kan se ut compare på exemplet med DSL.
metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)Låt oss säga att vi jämför antalet fel och vi vill veta antalet fel per sekund under de senaste 5 minuterna.
Vi har två värden: bas- och kanariefågelnoder. Värdet på kanariefågelnoden är det nuvarande. Grundläggande - baseValue är värdet av någon annan icke-kanariefågelnod. Vi jämför värdena med varandra enligt formeln, som vi ställer in baserat på våra erfarenheter och observationer. Om värdet canaryValue dåligt, sedan misslyckades distributionen och vi rullar tillbaka.
Varför är allt detta nödvändigt?
En person kan inte kontrollera hundratals och tusentals mätvärdenspeciellt att göra det snabbt. Automatisk jämförelse hjälper dig att kontrollera alla mätvärden och meddelar dig snabbt om problem. Tidpunkten för varningen är kritisk: om något hände under de senaste 2 sekunderna kommer skadan inte att vara lika stor som om den hände för 15 minuter sedan. Tills någon upptäcker ett problem, skriver till supporten och stöttar oss att rulla tillbaka, kan du förlora kunder.
Om processen gick igenom och allt är bra kommer vi att distribuera alla andra noder automatiskt. Under denna tid gör ingenjörerna ingenting. Först när de lanserar kanariefågeln bestämmer de vilka mätvärden de ska ta, hur lång tid de ska göra jämförelsen, vilken strategi de ska använda.
Om det finns problem rullar vi automatiskt tillbaka kanariefågelnoden, arbetar med tidigare versioner och fixar de fel vi hittade. Av mätvärden är de lätta att hitta och se skadan från den nya versionen.
Hinder
Detta är naturligtvis inte lätt att genomföra. Först och främst behöver du allmänt övervakningssystem. Ingenjörer har sina egna mätvärden, support och analytiker har olika mätvärden, och företag har tredje. Det gemensamma systemet är det gemensamma språk som näringsliv och utveckling talar.
Behöver testas i praktiken metrisk stabilitet. Att kontrollera hjälper dig att förstå vad är den minsta uppsättning mått som behövs för att säkerställa kvalitet.
Hur kan detta uppnås? Använd canary-service inte vid tidpunkten för driftsättning. Vi lägger till en viss tjänst på den gamla versionen, som när som helst kan ta vilken dedikerad nod som helst, minska trafiken utan distribution. Efter att vi har jämfört: vi studerar misstagen och letar efter den linjen när vi uppnår kvalitet.
Hur hade vi nytta av kanariefågelutsättningar?
Minimerade procentandelen skada från buggar. De flesta distributionsfel beror på inkonsekvenser i viss data eller prioritet. Det finns mycket färre sådana fel, eftersom vi kan lösa problemet under de första sekunderna.
Optimerat teamarbete. Nybörjare har "rätt att göra ett misstag": de kan distribuera till produktion utan rädsla för att göra ett misstag, det finns ytterligare ett initiativ, ett incitament att arbeta. Om de slår sönder något, då blir det inte kritiskt, och den som gör ett misstag kommer inte att få sparken.
Automatiserad distribution. Detta är inte längre en manuell process, som tidigare, utan en verklig automatiserad. Men det tar längre tid.
Markerade viktiga mätvärden. Hela företaget, med utgångspunkt från affärer och ingenjörer, förstår vad som verkligen är viktigt i vår produkt, vilka mätvärden, till exempel utflöde och inflöde av användare. Vi kontrollerar processen: vi testar mätvärden, introducerar nya, ser hur gamla fungerar för att bygga ett system som kommer att tjäna pengar mer produktivt.
Vi har många coola metoder och system som hjälper oss. Trots detta strävar vi efter att vara professionella och göra vårt jobb bra, oavsett om vi har ett system som hjälper oss eller inte.
Tekniska tillvägagångssätt och praxis - . Om du har nått framgång på vägen mot teknisk excellens och är redo att berätta vad som hjälpte dig i detta, — .
Vi planerar att 8 juni. Vi förstår att det är svårt att fatta beslut om deltagande i konferensen nu. Men samtidigt anser vi att karantän inte är en anledning att stoppa professionell kommunikation och utveckling. Därför kommer vi i alla fall att hitta ett sätt att diskutera uppgifterna för en teknisk lead och tillvägagångssätt för att lösa dem - vid behov kommer vi att gå online och sätta upp nätverk där!
Källa: will.com
