


Jag heter Yuri och är chef för systemadministrationsteamet på Citymobil. Idag ska jag dela med mig av mina erfarenheter av att arbeta med thin provisioning-teknik för filsystem. Linux Jag ska förklara hur det kan tillämpas i ett företags CI/CD-processer. Vi ska undersöka en situation där vi, för att automatiskt testa kod när den levereras till produktion, behöver läs- och skrivkopior av en MySQL-databas som ligger så nära produktionsversionen som möjligt.
Inledning: Varför ge dåliga råd?
En logisk fråga, eftersom det finns beprövade mekanismer för att migrera databasscheman till testmiljöer. Varför ens utöka det huvudsakliga icke-skärda DBMS till sådana volymer? Och inte all data behövs för testning. Jag ska försöka förklara.
För ungefär ett år sedan, mot bakgrund av den aktiva tillväxten av vår taxiaggregator (under 2018 ökade genomförda resor cirka 15 gånger), ökade datavolymen, belastningen på servrarna och frekvensen av utrullningar. Vi hamnade i följande situation:
- Den huvudsakliga MySQL-databasen växte till cirka 1000 tabeller på totalt 2,5 TB och fortsatte att växa.
- Det fanns inget sätt att snabbt bli skärrad och förstöra basen. Detta var inte tillåtet av det gamla tillvägagångssättet "Jag skriver in i databasen vad jag vill och hur jag vill", ett gäng JOINs och interna tabellberoenden.
- Det fanns ingen mekanism för att migrera databasschemat till testmiljöer.
- Det gjordes ingen automatisk testning av koden under distributionen.
Jag ville lösa det sista problemet så snabbt som möjligt. Postman-tester hade redan skrivits för att testa den huvudsakliga PHP-monoliten, men saknade en uppdaterad databas. Samtidigt kunde vi inte skapa en replik på natten, göra den till en mästare och låta den rivas i stycken under dagen: ett mycket stort antal utrullningar och ändringar, inklusive i data- och databasschemat, skulle ha gjorts stativet obrukbart mitt på dagen. Och att begränsa lanseringarna till bara en arbetsdag skulle vara ineffektivt.
Ändå var uppgiften klar: vi fick den första arbetsmontern inom två veckor. Den har genomgått många förändringar under det senaste året och fortsätter att användas.
Därefter kommer jag att beskriva i detalj alla steg och stadier i utvecklingen av vår lösning. Du kommer att se att denna metod förtjänar sin rätt att existera.
Vad är "tunn redundans"?
Detta är en hård- eller mjukvaruteknik (ett annat namn är glesa volymer) som gör att du kan allokera mer av den nödvändiga resursen än vad som är tillgängligt. I det här fallet måste den tilldelade volymen uppfylla kriterierna precis-tillräckligt (så mycket som behövs) och just-in-time (för den tid som krävs). I grund och botten används tunn reservation i olika lagringssystem för att tillhandahålla diskutrymme i de erforderliga volymerna, som överstiger de som faktiskt är tillgängliga. Tekniken stöds av olika filsystem, till exempel LVM2, ZFS, BTRFS. Det används ofta i virtualiseringshypervisorer. Tunn säkerhetskopiering gjorde att vi snabbt kunde skapa från ögonblicksbilder av huvudsektionen med data så många kopior av detta avsnitt som vi behövde (datakatalogen för MySQL DBMS).
Första stativ, Thin LVM-teknik
Det här kapitlet kan också kallas "Hur man gör de snabbaste ögonblicksbilderna av stora datamängder med hjälp av , vilket minskar stabiliteten i filsystemet och MySQL DBMS till oanständiga nivåer."
Eftersom vi redan använde LVM för att bygga de viktigaste OS-partitionerna, bestämde vi oss för att börja med det. Till att börja med behövde vi en separat fysisk maskin - en kopia av vår huvudsakliga MySQL-databas, på vilken vi kunde skapa en ögonblicksbild av repliken på begäran och höja den bredvid en separat MySQL-instans. Under testningen tillät vi modifieringsoperationer att användas på den här instansen, och efter att testerna slutförts tog vi bort den på ett säkert sätt. Serverkonfigurationen var så här:
- 2 x Intel Silver 4114 (10x2,2 GHz HT)
- 8 x 32 GB DDR4
- 8 x 1920 GB Intel SSD i Adaptec RAID-kontroller i RAID-10
Du kan skriva en separat artikel om ämnet att välja mellan en RAID-kontroller och programvara RAID MD. Låt mig bara säga att vårt val påverkades av två faktorer:
- När problemet formulerades installerade vi alla DBMS på RAID-kontroller, så vi kan säga att detta hände historiskt.
- Skillnaden i prestanda mellan syntetiska filsystemtester och tester med olika MySQL-operationer var minimal.
Vi delade upp den resulterande RAID-10: vi skapade en enda volymgrupp (VG) för hela volymen (med overhead på cirka 6,7 GB) och skapade en logisk partition (Logical Volume, LV) för ett 50 GB-system. I en normal situation definierar vi resten av utrymmet som MySQL-sektionen. Men vi behövde tunn backup, så först skapade vi en så kallad pool, i vilken vi skapade en sektion för /var/lib/mysql med 3,5 TB (baserat på de uppskattade databasvolymerna):
lvcreate -l 100%FREE -T vga/thin
lvcreate -V 3.5T -T vga/thin -n mysqlVi formaterade partitionen i ext4, monterade den, spelade in en replik och fick originalstativet. Sedan gjorde vi en bindning i form av ett API, som ska skapa ögonblicksbilder, höja en MySQL-databasinstans på en given port och radera den skapade instansen. Eftersom detta uteslutande använder systemanrop, valde vi vanlig bash som skriptspråk och implementerade en lösning med öppen källkod för att ansluta HTTP → bash API , skrivet i Go.
Någon gång kommer vi att släppa våra bash-skript till öppen källkod, men för tillfället kommer jag helt enkelt att beskriva huvudalgoritmen:
Skapa huvudsnapmain för ögonblicksbild:
- Stoppar huvudrepliken.
- Vi sätter ett block på operationer med snapmain ögonblicksbilden.
- Skapa en ny ögonblicksbild.
- Starta MySQL och ta bort låset.
Skapa en databas på en godtycklig port från snapmain:
- Vi sätter ett lås på en specifik databasinstans (port).
- Vi kontrollerar om skapandet av huvudögonblicksbilden är blockerad. Om det finns där, väntar vi och kontrollerar igen var 5:e sekund.
- Vi kontrollerar om det finns en gammal LV-del av instansen.
3.1 Om det finns, använd kill -9 för att stoppa MySQL-instansen och ta bort LV-partitionen. - Vi skapar en ny instans från snapmain.
- Vi förbereder och monterar kataloger för detta fall.
- Vi tar bort attributen för slaven (filerna) och startar MySQL-instansen.
- Låt oss göra honom till en mästare.
- Vi tar bort blockeringen.
Ta bort en databas på en slumpmässig port:
- Vi sätter ett lås på en specifik databasinstans (port).
- Döda MySQL-instansen med kill -9.
- Låt oss avmontera katalogerna.
- Vi tar bort LV-partitionen och tar bort låset.
Exempelkommandon för kloning av partitioner av en ny databasinstans:
lvcreate -n stage_3307 -s vga/snapmain
lvchange -ay -K vga/stage_3307
mount -o noatime,nodiratime,data=writeback /dev/mapper/vga-stage_3307 /mnt/stage_3307Nu ska jag berätta om huvudproblemet som vi stötte på när vi använde tunn redundans. Vi har fastnat för prestanda hos SSD-enheter. Detta hände på grund av funktionerna i Thin LVM: den fungerar i princip på enhetsnivå med lågnivåbitar med en standardstorlek på 4 MB. Hur det såg ut:
- Skapa en ögonblicksbild från huvudsektionen /var/lib/mysql.
- Vi börjar replikera för att komma ikapp med mastern.
- Varje förändring i replikatabellerna tvingar gamla, oförändrade databitar att lagras i ögonblicksbildssektionen.
- Varje ändring av en upphöjd testinstans gör att gamla, omodifierade databitar lagras i en klonad ögonblicksbildssektion för den instansen.
- Vi får en belastning på 100 % I/O-operationer på enheten, en avmattning av alla operationer och en gradvis fördröjning av repliken.
- I slutet av arbetsdagen får vi en monter som ligger flera timmar efter.
Hur vi hanterade detta för att få ett mer vettigt resultat (huvudpunkter):
RAID-kontroller:
- Alla typer av cachning är inaktiverade som standard.
- Ställ in återskrivning (när data kommer in i bufferten slutförs skrivningen innan den faktiska lagringen på disken utförs).
Filsystem:
- Vid monteringspunkten /var/lib/mysql skrev vi noatime,nodiratime,data=återskrivning
- Inaktiverade ext4-loggning med tune2fs.
MySQL:
- Förskrivet innodb_flush_method = O_DSYNC (ökad inspelningshastighet, vilket minskar tillförlitligheten).
- Loggning är inaktiverad, vi behöver inga loggar.
- Förskrivet innodb_buffer_pool_size = 4G (Ju mindre InnoDB-poolstorleken är, desto snabbare stängs MySQL av när den stoppas, och desto snabbare skapar vi en ögonblicksbild).
Detta är inte en komplett lista, speciellt för MySQL. De återstående ändringarna är dock mindre och är ofta inte alltid eller exakt tillämpliga. Till exempel, i ett försök att ladda ur diskarna, tog vi till och med bort innodb_parallel_doublewrite_path i /dev/shm, vilket i vissa fall sparade oss upp till 5 sekunder när vi startade en felaktigt avslutad instans.
Varför stoppar vi MySQL innan vi tar en ögonblicksbild? När allt kommer omkring kan vi ta bort det från en fungerande replik. Det stämmer, men den nya databasinstansen på denna ögonblicksbild kommer att anses vara skadad som standard och kommer att kräva en fullständig genomsökning vid start. Att stoppa en replik är definitivt snabbare, även om det blir den längsta operationen i hela processen.
Som ett resultat fick vi mer acceptabla tidpunkter och ett färdigt ställ. Även om, som kan ses från den mest vältaliga grafen över replikeringsfördröjningen för huvudrepliken, är situationen fortfarande långt ifrån idealisk:
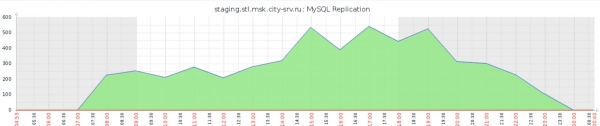
Bland andra brister är det värt att notera den praktiska omöjligheten att övervaka Thin LVM-poolen: förutom systemstandardens iostatfunktioner är det omöjligt att förstå till exempel vilket poolelement som för närvarande producerar den största belastningen på filsystemet.
Separat är det värt att notera en stor nackdel i samband med optimeringen som beskrivs ovan: vi fick ett YOLO-ställ. Ungefär en gång var eller varannan månad kunde ext4 inte motstå sådant missbruk och gick sönder irreparabelt, vilket krävde omformatering och återuppladdning av repliken. Efter att ha vunnit i fart förstörde vi hopplöst stabiliteten.
Vilka mätvärden ska du övervaka när du använder Thin LVM:
- Tunn pool data %
- Tunn pool metadata %
Om vår monter överlever att utrymmet för data tar slut (det räcker för att rengöra diskarna), kommer det slut på utrymme för metadata att leda till en fullständig kollaps av poolen och behovet av att bygga om den från grunden.
Filsystemet i poolen blir mycket fragmenterat med tiden. Jag rekommenderar att du kör cron-kommandot en gång om dagen fstrim -v /var/lib/mysql.
Delsummor:
- Tekniken är enkel att tillämpa, precis som LVM själv, och kräver inga speciella ingenjörsbehörighet.
- Den är väl lämpad för små och inte alltför laddade databaser. Ju mindre databasen är, desto färre bitar rör sig i filsystemet i poolen, och desto lägre belastning på diskarna.
- För vår uppgift började vi leta efter andra lösningar, som kommer att diskuteras i nästa avsnitt.
Andra stativ, ZFS-teknik
Jag arbetade med ZFS-filsystemet för länge sedan, men på den tiden fungerade ZFS pålitligt och bra på sin ursprungliga Solaris-operativsystemfamilj. Det fanns en portering till FreeBSD med en ganska bra implementeringsnivå. Det fanns också en oavslutad portering till Linux, vilket få personer använde. På grund av sin B-trädsstruktur för datalagring (för övrigt har MySQL:s InnoDB samma lagringsstruktur) presterade ZFS dåligt på installationer med ett mycket stort antal filer. Detta, i kombination med behovet av att lära sig allt innan användning, ledde till att jag använde detta filsystem under lång tid. Ext4 och xfs dök upp och blev standarden. Men med tanke på att ZFS är mer än lämpligt för våra behov, och Linux-versionen, att döma av recensionerna, har vuxit till en helt vettig produkt (även om den inte stöds fullt ut, vilket är anledningen till att det bara är möjligt att installera ett system på ZFS från grunden med hjälp av olika voodoo-tekniker), bestämde vi oss för att prova.
Av uppenbara skäl valdes stativet med en liknande konfiguration (med undantag för RAID-kontrollern). Vi installerade åtta 1920 GB SSD-enheter. Det fanns ingen lust att skriva vår egen nätverksbild för att ladda upp servern till blotta ZFS, så vi bet av 50 GB av alla diskar och gjorde MD RAID-10 på dem för systemet. De återstående 1950 GB på varje disk kombinerades till en ZFS-analog av RAID-10:
zpool create zpool mirror /dev/sda2 /dev/sdb2 mirror /dev/sdc2 /dev/sdd2 mirror /dev/sde2 /dev/sdf2 mirror /dev/sdg2 /dev/sdh2Vi skapade sektioner för MySQL:
zfs create zpool/mysql
zfs set compression=gzip zpool/mysql
zfs set recordsize=128k zpool/mysql
zfs set atime=off zpool/mysql
zfs create zpool/mysql/data
zfs set recordsize=16k zpool/mysql/data
zfs set primarycache=metadata zpool/mysql/data
zfs set mountpoint=/var/lib/mysql zpool/mysql/dataObservera att vi har aktiverat inbyggd gzip-datakomprimering. Vi har många processorresurser på servern och de används inte fullt ut. Som ett resultat av detta förvandlades 3 TB av vår databas till 1,6 TB, och eftersom den svaga länken, som i föregående fall, är den maximala diskprestandan. mindre data desto bättre, vi Vi får en fantastisk bonus från ZFS från första början! Under rusningstid vid full belastning tar det upp till 4 kärnor för att hålla gzip igång, men vi har inget emot det.
Då gick implementeringen snabbare. MySQL-replikinställningarna överfördes från LVM-stativet som en kopia. Jag var tvungen att lägga lite tid på att skriva om skripten med hjälp av ZFS-kommandon, men i allmänhet förblev algoritmerna desamma. Ett exempel på hur du skapar en ögonblicksbild:
zfs set snapdir=visible zpool/mysql/data
zfs create zpool/stage_3307
zfs clone zpool/mysql/data@snapmain zpool/stage_3307/data
zfs set mountpoint=/mnt/stage_3307 zpool/stage_3307/dataFrån ytterligare justering: vi flyttade ZFS-partitioner med metadata och l2arc- och zil-loggar till minnet. För vår uppgift, som det visade sig senare, var detta överflödigt, men för närvarande lämnade vi denna optimering, det är lätt att ändra om det behövs. En av de negativa effekterna är att efter omstart av servern måste du återskapa motsvarande minnesområden. Ingen data går förlorad. Zpool-statusklipp:
logs
/dev/shm/zil_slog.img ONLINE 0 0 0
cache
/dev/shm/l2arc.img ONLINE 0 0 0I den här konfigurationen började vi testa stativet och fick utmärkta resultat: med två simultant körande databasinstanser (och en aktiv huvudreplik) i ögonblicksbilder fick vi 50-60% diskutnyttjande.
Vi blev av med vårt huvudproblem, som kan ses i grafen för replikeringsfördröjning (jämför med föregående graf i avsnittet Thin LVM):
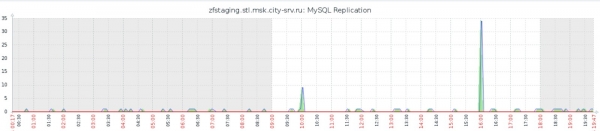
Utöver och tack vare detta har vi påskyndat alla operationer avsevärt: att helt skapa en ögonblicksbild med att stoppa och starta en replik tar upp till 40 sekunder, att distribuera en ny MySQL-instans från en ögonblicksbild tar upp till 20 sekunder. Vilket är mer än tillfredsställande för både oss och våra programkodstester.
Delsummor:
- Resultaten tillfredsställde helt vårt behov av att skaffa en kopia av produktionsdatabasen för att testa koden.
- Tekniken kräver inträde: du måste förstå vad ZFS är och hur du arbetar med det.
- Vi har inte kontrollerat den aktuella statusen för ZFS med ett stort antal (över 1 miljon) små filer. Men vi antar att problemet kvarstår, så jag skulle inte rekommendera detta filsystem för någon fillagring.
Vad händer nu?
Det finns inget annat att göra inom ramen för montern vi är nöjda med resultatet. Kanske kommer vi i framtiden att lägga till uteslutningar av tabeller som inte behövs för testning till monterreplikeringen, vilket kommer att minska storleken på databasen ytterligare. Vi har inte testat BTRFS-systemet och dess implementering av tunn redundansteknologi. En sådan uppgift är dock inte längre värt det, eftersom huvudmålet har uppnåtts. Generellt sett skulle jag naturligtvis vilja gå bort från det tillvägagångssätt som beskrivs ovan - implementera fungerande databasmigreringar till en testmiljö, skapa en separat testdatabaskrets och börja skärpa huvuddatabasen. Vi omsätter redan mycket av detta i praktiken, vilket vi definitivt kommer att prata om i framtida artiklar.
Resultat av
Det ursprungliga problemet löstes, om än på ett ovanligt sätt. De mellanliggande slutsatserna beskrev fördelarna och nackdelarna med var och en av de använda teknikerna, så låt oss bestämma vilken teknik som kan användas och när:
- Tunn LVM - för små databaser och när du inte vill eller inte har tid att lära dig ZFS.
- ZFS - om du har erfarenhet av att arbeta med det eller möjlighet att ägna tid åt att studera det i alla situationer.
På en högre presentationsnivå är den här artikeln inte bara en jämförelse av tekniken för de två filsystemen. Huvudtanken som jag skulle vilja förmedla och förstärka är att man inte ska vara rädd för att tänka utanför ramarna i affärskritiska situationer och bara ta färdiga recept. En gång i tiden kunde vi skaka på huvudet som helhet på den tekniska avdelningen och säga att uppgiften att skapa tre terabyte kopior av en databas på mindre än en minut är omöjlig, och vi behöver ingen riskfylld teknik, låt oss göra det är rätt. Det var möjligt, men vi skulle ha förlorat ungefär sex månader till ett år och många kundresor (resor är vår huvudsakliga affärsindikator) utan testning och under implementering. Genom att agera utanför ramarna förlorade vi inte mycket tid på implementeringen, fick erfarenhet av nya och bortglömda gamla tekniker och testade vid en tidpunkt då vi verkligen behövde det. Detta hade utan tvekan en positiv inverkan på alla våra indikatorer. Valet är alltid ditt, och vi för vår del kommer att fortsätta prata om intressanta nuvarande och framtida prestationer i vår blogg.
Källa: will.com
