

Den här anteckningen kommer att vara av intresse för dem som använder tabelldatabehandlingsbiblioteket för R - data.table, och kan vara glada över att se flexibiliteten i dess användning i olika exempel.
Inspirerad av ett gott exempel , och hoppas att du redan har läst hans artikel, föreslår jag att du gräver djupare mot kodoptimering och prestanda baserat på datatabell.
Inledning: Var kommer data.table ifrån?
Det är bäst att börja bekanta sig med biblioteket lite på långt håll, nämligen med de datastrukturer från vilka data.table-objektet (nedan kallat DT) kan erhållas.
array
Kod
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
En sådan struktur är en array (?bas::array). Liksom på andra språk är arrayer här flerdimensionella. Det intressanta är dock att till exempel en tvådimensionell array börjar ärva egenskaper från matrisklassen (?bas::matris), och en endimensionell array, som också är viktig, ärver inte från en vektor (?bas::vektor).
Det bör förstås att typen av data som finns i ett objekt bör kontrolleras med funktionen base::typeof, som returnerar den interna typbeskrivningen enl R Interner - Det allmänna protokollet för det språk som är kopplat till originalet C.
Ett annat kommando för att bestämma klassen för ett objekt är bas::klass, när det gäller vektorer, returnerar vektortypen (den skiljer sig i namn från den interna, men låter dig också förstå datatypen).
Lista
Från en tvådimensionell matris, även känd som en matris, kan du gå till listan (?bas::lista).
Kod
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
Flera saker händer samtidigt:
- Den andra dimensionen av matrisen kollapsar, det vill säga vi får både en lista och en vektor samtidigt.
- Listan ärver alltså från dessa klasser. Man måste komma ihåg att ett listelement kommer att motsvara ett (skalärt) värde från en cell i matrismatrisen.
Eftersom en lista också är en vektor kan vissa vektorfunktioner tillämpas på den.
Dataram
Du kan gå från en lista, matris eller vektor till en dataram (?base::data.frame).
Kod
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Vad är intressant med det: dataramen ärver från listan! Dataramkolumner är listceller. Detta kommer att vara viktigt senare när vi använder funktioner som tillämpas på listor.
datatabell
Skaffa DT (?data.table::data.table) kan vara från dataram, lista, vektor eller matris. Till exempel så här (på plats).
Kod
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Det är användbart att, precis som en dataram, en DT ärver egenskaperna hos en lista.
DT och minne
Till skillnad från alla andra objekt i R-basen, skickas DT genom referens. Om du behöver göra en kopia till ett nytt minnesområde behöver du en funktion data.table::copy eller så måste du göra ett urval från det gamla objektet.
Kod
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
Detta avslutar inledningen. DT är en fortsättning på utvecklingen av datastrukturer i R, som huvudsakligen sker på grund av expansionen och accelerationen av operationer som utförs på objekt i dataramklassen. Samtidigt bevaras arv från andra primitiver.
Några exempel på användning av data.table-egenskaper
Som en lista...
Att iterera över raderna i en dataram eller DT är ingen bra idé, eftersom loopkoden i språket R mycket långsammare C, men det är fullt möjligt att gå igenom kolumnerna, som vanligtvis är mycket mindre. När du går igenom kolumnerna, kom ihåg att varje kolumn är ett element i en lista, som vanligtvis innehåller en vektor. Och operationer på vektorer är väl vektoriserade i språkets grundläggande funktioner. Du kan också använda urvalsoperatorer som är gemensamma för listor och vektorer: `[[`, `$`.
Kod
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Vektorisering
Om det finns ett behov av att gå igenom linjerna i en stor DT skulle den bästa lösningen vara att skriva en funktion med vektorisering. Men om detta inte fungerar, bör du komma ihåg att cykeln inom DT är fortfarande snabbare än cykeln R, eftersom det utförs på C.
Låt oss prova det på ett större exempel med 100K rader. Vi kommer att extrahera den första bokstaven från orden som ingår i vektorkolumnen w.
Uppdaterad
Kod
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Kör först itererande över rader:
Enhet: millisekunder
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq medel median uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Den andra körningen, där vektorisering sker genom att listan omvandlas till en matris och tar element på skivan med index 1 (det senare är själva vektoriseringen). Korrigering: vektorisering på funktionsnivå strsplit, som kan acceptera en vektor som indata. Det visar sig att proceduren för att omvandla en lista till en matris är mycket svårare än vektorisering i sig, men i det här fallet är det mycket snabbare än den icke-vektoriserade versionen.
Enhet: millisekunder
expr min lq medelvärde median uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Acceleration med median in 3 gånger.
Den tredje körningen, där transformationsschemat till matrisen ändrades.
Enhet: millisekunder
expr min lq medelvärde median uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Acceleration med median in 13 gånger.
Du måste experimentera med den här saken, ju mer, desto bättre blir det.
Ett annat exempel med vektorisering, där det också finns text, men det är nära verkliga förhållanden: olika långa ord, olika antal ord. Du måste få de första 3 orden. Så här:
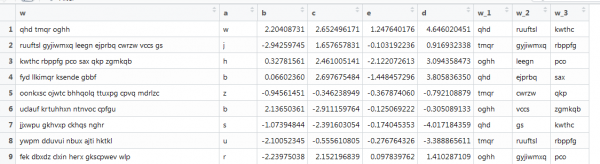
Här fungerar inte den föregående funktionen, eftersom vektorerna har olika längd, och vi ställer in matrisstorleken. Låt oss göra om detta genom att gräva runt på Internet.
Kod
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Enhet: millisekunder
expr min lq medelmedian
{ dt[, `:=`((klistra in0(“w_”, 1:3)), strsplit(w, split = " ", fix = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Skriptet kördes med en genomsnittlig hastighet på 1 sekund. Inte illa.
Förbunden med en kedja...
Du kan arbeta med DT-objekt med hjälp av kedja. Det ser ut som att fästa parentessyntax till höger, i huvudsak socker.
Kod
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Flödar genom rören...
Samma operationer kan göras genom rörledningar, det ser likadant ut, men är funktionellt rikare, eftersom du kan använda vilka metoder som helst, inte bara DT. Låt oss härleda logistiska regressionskoefficienter för våra syntetiska data med ett antal filter på DT.
Kod
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Statistik, maskininlärning och mer inom DT
Du kan använda lambda-funktioner, men ibland är det bättre att skapa dem separat, skriva hela dataanalyspipelinen och gå vidare - de fungerar i DT. Exemplet är berikat med alla ovanstående funktioner, plus flera användbara saker från DT-arsenalen (som att komma åt själva DT inuti DT via en länk, ibland insatt inte sekventiellt, men så att det är det).
Kod
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
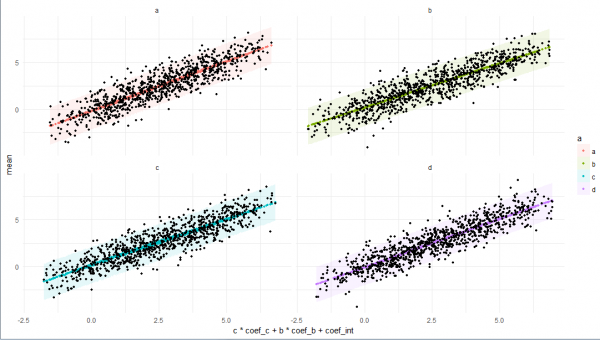
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Slutsats
Jag hoppas att jag kunde skapa en komplett, men naturligtvis inte fullständig, bild av ett sådant objekt som data.table, med början från dess egenskaper som är associerade med arv från R-klasser och slutar med dess egna egenskaper och miljö från tidyverse element . Jag hoppas att detta kommer att hjälpa dig att bättre lära dig och använda det här biblioteket för arbete och underhållning.
Tack!
Fullständig kod
Kod
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Källa: will.com
