

Hej, Habr! Jag presenterar för din uppmärksamhet en översättning av artikeln
.
När det kommer till relationsdatabaser kan jag inte låta bli att tycka att något saknas. De används överallt. Det finns många olika databaser tillgängliga, från den lilla och användbara SQLite till den kraftfulla Teradata. Men det finns bara ett fåtal artiklar som förklarar hur databasen fungerar. Du kan söka själv med "howdoesarelationaldatabasework" för att se hur få resultat det finns. Dessutom är dessa artiklar korta. Om du letar efter den senaste buzzy-tekniken (BigData, NoSQL eller JavaScript), hittar du mer djupgående artiklar som förklarar hur de fungerar.
Är relationsdatabaser för gamla och för tråkiga för att förklaras utanför universitetskurser, forskningsrapporter och böcker?

Som utvecklare hatar jag att använda något jag inte förstår. Och om databaser har använts i mer än 40 år måste det finnas en anledning. Under åren har jag tillbringat hundratals timmar för att verkligen förstå dessa konstiga svarta lådor som jag använder varje dag. Relationsdatabaser mycket intressant eftersom de baserad på användbara och återanvändbara koncept. Om du är intresserad av att förstå en databas, men aldrig har haft tid eller lust att fördjupa dig i detta breda ämne, bör du njuta av den här artikeln.
Även om rubriken på denna artikel är tydlig, Syftet med den här artikeln är inte att förstå hur man använder databasen. Därav, du borde redan veta hur man skriver en enkel anslutningsförfrågan och grundläggande frågor SKICK; annars kanske du inte förstår den här artikeln. Det är det enda du behöver veta, jag ska förklara resten.
Jag börjar med några grunder inom datavetenskap, som algoritmernas tidskomplexitet (BigO). Jag vet att några av er hatar det här konceptet, men utan det kommer ni inte att kunna förstå krångligheterna i databasen. Eftersom detta är ett stort ämne, Jag ska fokusera på vad jag tycker är viktigt: hur databasen bearbetar SQL förfrågan. Jag ska bara presentera grundläggande databaskonceptså att du i slutet av artikeln har en uppfattning om vad som händer under huven.
Eftersom det här är en lång och teknisk artikel som involverar många algoritmer och datastrukturer, ta dig tid att läsa igenom den. Vissa begrepp kan vara svåra att förstå; du kan hoppa över dem och fortfarande få den allmänna uppfattningen.
För de mer kunniga bland er är den här artikeln uppdelad i 3 delar:
- Översikt över databaskomponenter på låg och hög nivå
- Översikt över frågeoptimeringsprocessen
- Översikt över transaktions- och buffertpoolshantering
Tillbaka till grunderna
För år sedan (i en galax långt, långt borta...) var utvecklare tvungna att veta exakt hur många operationer de kodade. De kunde sina algoritmer och datastrukturer utantill eftersom de inte hade råd att slösa bort processorn och minnet på sina långsamma datorer.
I den här delen kommer jag att påminna dig om några av dessa begrepp eftersom de är viktiga för att förstå databasen. Jag kommer också att presentera konceptet databasindex.
O(1) vs O(n2)
Nuförtiden bryr sig många utvecklare inte om tidskomplexiteten hos algoritmer... och de har rätt!
Men när du har att göra med mycket data (jag pratar inte tusentals) eller om du kämpar på millisekunder, blir det avgörande att förstå detta koncept. Och som du kan föreställa dig måste databaser hantera båda situationerna! Jag kommer inte att tvinga dig att spendera mer tid än nödvändigt för att få fram poängen. Detta kommer att hjälpa oss att förstå konceptet med kostnadsbaserad optimering senare (kosta baserat optimering).
Koncept
Algoritmens tidskomplexitet används för att se hur lång tid det tar att slutföra en algoritm för en given mängd data. För att beskriva denna komplexitet använder vi matematisk notation med stor O. Denna notation används med en funktion som beskriver hur många operationer en algoritm behöver för ett givet antal ingångar.
Till exempel, när jag säger "den här algoritmen har komplexitet O(some_function())", betyder det att algoritmen kräver some_function(a_certain_amount_of_data) operationer för att bearbeta en viss mängd data.
I detta fall, Det är inte mängden data som spelar roll**, annars ** hur antalet operationer ökar med ökande datavolym. Tidskomplexitet ger inte ett exakt antal operationer, men är ett bra sätt att uppskatta exekveringstiden.
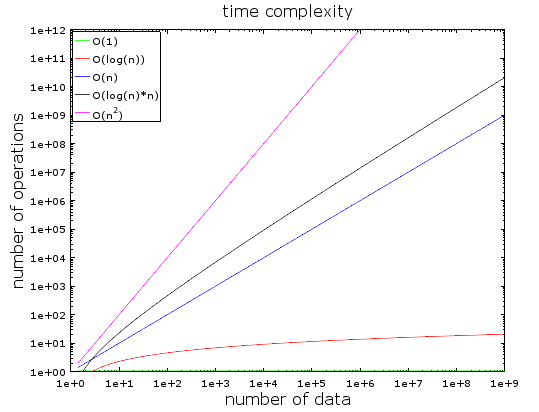
I den här grafen kan du se antalet operationer kontra mängden indata för olika typer av algoritmtidskomplexitet. Jag använde en logaritmisk skala för att visa dem. Med andra ord, mängden data ökar snabbt från 1 till 1 miljard. Vi kan se att:
- O(1) eller konstant komplexitet förblir konstant (annars skulle det inte kallas konstant komplexitet).
- O(log(n)) förblir låg även med miljarder data.
- Värsta svårigheten - O(n2), där antalet operationer växer snabbt.
- De andra två komplikationerna ökar lika snabbt.
Примеры
Med en liten mängd data är skillnaden mellan O(1) och O(n2) försumbar. Låt oss till exempel säga att du har en algoritm som behöver bearbeta 2000 element.
- O(1)-algoritmen kommer att kosta dig 1 operation
- O(log(n))-algoritmen kommer att kosta dig 7 operationer
- O(n)-algoritmen kommer att kosta dig 2 000 operationer
- O(n*log(n))-algoritmen kommer att kosta dig 14 000 operationer
- O(n2)-algoritmen kommer att kosta dig 4 000 000 operationer
Skillnaden mellan O(1) och O(n2) verkar stor (4 miljoner operationer) men du kommer att förlora maximalt 2 ms, bara tid att blinka med ögonen. Moderna processorer kan faktiskt bearbeta . Det är därför som prestanda och optimering inte är ett problem i många IT-projekt.
Det är som sagt fortfarande viktigt att känna till detta koncept när man arbetar med enorma mängder data. Om algoritmen den här gången måste bearbeta 1 000 000 element (vilket inte är så mycket för en databas):
- O(1)-algoritmen kommer att kosta dig 1 operation
- O(log(n))-algoritmen kommer att kosta dig 14 operationer
- O(n)-algoritmen kommer att kosta dig 1 000 000 operationer
- O(n*log(n))-algoritmen kommer att kosta dig 14 000 000 operationer
- O(n2)-algoritmen kommer att kosta dig 1 000 000 000 000 operationer
Jag har inte räknat ut, men jag skulle säga att med O(n2)-algoritmen hinner du dricka en kaffe (även två!). Lägger du till ytterligare 0 till datavolymen kommer du att hinna ta en tupplur.
Låt oss gå djupare
För din information:
- En bra hashtabellsökning hittar ett element i O(1).
- Att söka i ett välbalanserat träd ger resultat i O(log(n)).
- Sökning i en array ger resultat i O(n).
- De bästa sorteringsalgoritmerna har komplexiteten O(n*log(n)).
- En dålig sorteringsalgoritm har komplexiteten O(n2).
Notera: I följande delar kommer vi att se dessa algoritmer och datastrukturer.
Det finns flera typer av algoritmens tidskomplexitet:
- genomsnittligt fallscenario
- bästa fallet
- och värsta scenariot
Tidskomplexitet är ofta det värsta scenariot.
Jag pratade bara om tidskomplexiteten för algoritmen, men komplexiteten gäller även för:
- minnesförbrukning av algoritmen
- disk I/O-förbrukningsalgoritm
Naturligtvis finns det komplikationer värre än n2, till exempel:
- n4: det här är hemskt! Några av de nämnda algoritmerna har denna komplexitet.
- 3n: det här är ännu värre! En av algoritmerna vi kommer att se i mitten av den här artikeln har denna komplexitet (och den används faktiskt i många databaser).
- factorial n: du kommer aldrig att få dina resultat även med en liten mängd data.
- nn: Om du stöter på denna komplexitet bör du fråga dig själv om detta verkligen är ditt verksamhetsområde...
Notera: Jag gav dig inte den faktiska definitionen av den stora O-beteckningen, bara en idé. Du kan läsa den här artikeln på för den verkliga (asymptotiska) definitionen.
MergeSort
Vad gör du när du behöver sortera en samling? Vad? Du anropar sort()-funktionen... Ok, bra svar... Men för en databas måste du förstå hur den här sort()-funktionen fungerar.
Det finns flera bra sorteringsalgoritmer, så jag ska fokusera på det viktigaste: slå samman sortering. Du kanske inte förstår varför det är användbart att sortera data just nu, men du bör göra det efter frågeoptimeringsdelen. Dessutom kommer förståelsen av merge sort att hjälpa oss att senare förstå den gemensamma databasanslutningsoperationen som kallas sammanfoga delta (fusionsförening).
Sammanfoga
Liksom många användbara algoritmer förlitar sig sammanslagningssortering på ett knep: att kombinera 2 sorterade arrayer av storlek N/2 till en N-elementsorterad array kostar bara N operationer. Denna operation kallas sammanslagning.
Låt oss se vad detta betyder med ett enkelt exempel:
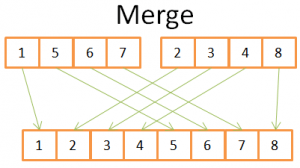
Den här figuren visar att för att bygga den slutliga sorterade 8-elements arrayen behöver du bara iterera en gång över de 2 4-element arrayerna. Eftersom båda arrayerna med 4 element redan är sorterade:
- 1) du jämför båda aktuella elementen i två arrayer (i början ström = först)
- 2) ta sedan den minsta för att sätta den i en 8 elementarray
- 3) och flytta till nästa element i arrayen där du tog det minsta elementet
- och upprepa 1,2,3 tills du når det sista elementet i en av arrayerna.
- Sedan tar du de återstående elementen i den andra arrayen för att lägga dem i en 8 element array.
Detta fungerar eftersom båda 4-elements arrayer är sorterade och så att du inte behöver "gå tillbaka" i dessa arrayer.
Nu när vi förstår tricket, här är min pseudokod för sammanfogning:
array mergeSort(array a)
if(length(a)==1)
return a[0];
end if
//recursive calls
[left_array right_array] := split_into_2_equally_sized_arrays(a);
array new_left_array := mergeSort(left_array);
array new_right_array := mergeSort(right_array);
//merging the 2 small ordered arrays into a big one
array result := merge(new_left_array,new_right_array);
return result;Merge sort delar upp ett problem i mindre problem och hittar sedan resultatet av de mindre problemen för att få resultatet av det ursprungliga problemet (obs: denna typ av algoritm kallas divide and conquer). Om du inte förstår denna algoritm, oroa dig inte; Jag förstod det inte första gången jag såg det. Om det kan hjälpa dig ser jag den här algoritmen som en tvåfasalgoritm:
- Divisionsfas, där arrayen är uppdelad i mindre arrayer
- Sorteringsfasen är där små arrayer kombineras (med hjälp av union) för att bilda en större array.
Indelningsfas
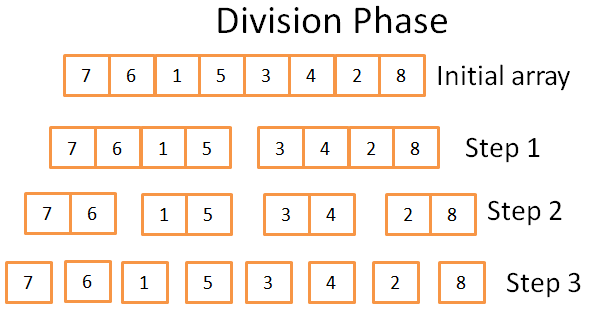
I divisionssteget delas arrayen in i enhetliga arrayer i 3 steg. Det formella antalet steg är log(N) (eftersom N=8, log(N) = 3).
Hur vet jag detta?
Jag är ett geni! Med ett ord - matematik. Tanken är att varje steg delar storleken på den ursprungliga arrayen med 2. Antalet steg är antalet gånger du kan dela den ursprungliga arrayen i två. Detta är den exakta definitionen av en logaritm (bas 2).
Sorteringsfas
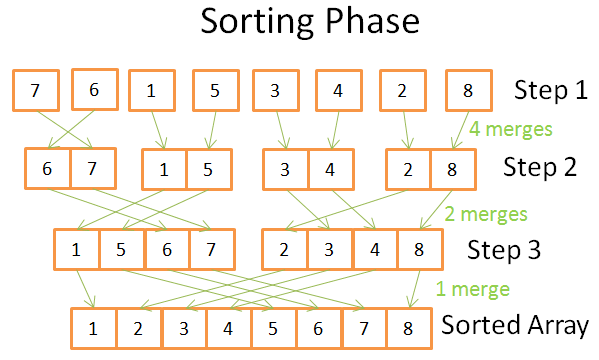
I sorteringsfasen börjar man med enhetliga (single-element) arrayer. Under varje steg tillämpar du flera sammanslagningsoperationer och den totala kostnaden är N = 8 operationer:
- I det första steget har du 4 sammanslagningar som kostar 2 operationer vardera
- I det andra steget har du 2 sammanslagningar som kostar 4 operationer vardera
- I det tredje steget har du 1 sammanfogning som kostar 8 operationer
Eftersom det finns log(N)-steg, total kostnad N * log(N) operationer.
Fördelar med merge sort
Varför är denna algoritm så kraftfull?
eftersom:
- Du kan ändra det för att minska minnesfotavtrycket så att du inte skapar nya matriser utan direkt modifierar inmatningsmatrisen.
Obs: denna typ av algoritm kallas (sortering utan extra minne).
- Du kan ändra det så att det använder diskutrymme och en liten mängd minne samtidigt utan att det ådrar sig betydande disk I/O-overhead. Tanken är att bara ladda de delar som för närvarande bearbetas i minnet. Detta är viktigt när du behöver sortera en multi-gigabyte-tabell med endast en 100-megabyte minnesbuffert.
Obs: denna typ av algoritm kallas .
- Du kan ändra det så att det körs på flera processer/trådar/servrar.
Till exempel är distribuerad sammanslagning en av nyckelkomponenterna (som är en struktur i big data).
- Denna algoritm kan förvandla bly till guld (på riktigt!).
Denna sorteringsalgoritm används i de flesta (om inte alla) databaser, men den är inte den enda. Vill du veta mer kan du läsa detta , som diskuterar för- och nackdelar med vanliga databassorteringsalgoritmer.
Array-, träd- och hashtabell
Nu när vi förstår idén om tidskomplexitet och sortering, borde jag berätta om 3 datastrukturer. Detta är viktigt eftersom de är grunden för moderna databaser. Jag kommer också att presentera konceptet databasindex.
array
En tvådimensionell array är den enklaste datastrukturen. En tabell kan ses som en array. Till exempel:
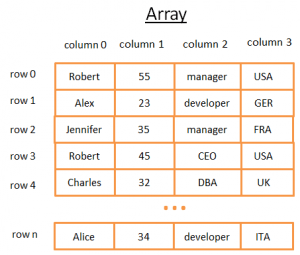
Denna 2-dimensionella array är en tabell med rader och kolumner:
- Varje rad representerar en enhet
- Kolumner lagrar egenskaper som beskriver entiteten.
- Varje kolumn lagrar data av en specifik typ (heltal, sträng, datum...).
Detta är praktiskt för att lagra och visualisera data, men när du behöver hitta ett specifikt värde är detta inte lämpligt.
Om du till exempel vill hitta alla killar som jobbar i Storbritannien, måste du titta på varje rad för att avgöra om den raden tillhör Storbritannien. Det kommer att kosta dig N transaktionervar N - antal rader, vilket inte är dåligt, men kan det finnas ett snabbare sätt? Nu är det dags för oss att bekanta oss med träden.
Obs: De flesta moderna databaser tillhandahåller utökade arrayer för att lagra tabeller effektivt: heap-organized-tabeller och index-organized-tabeller. Men detta ändrar inte problemet med att snabbt hitta ett specifikt tillstånd i en grupp kolumner.
Databasträd och index
Ett binärt sökträd är ett binärt träd med en speciell egenskap, nyckeln vid varje nod måste vara:
- större än alla nycklar lagrade i det vänstra underträdet
- mindre än alla nycklar lagrade i det högra underträdet
Låt oss se vad detta betyder visuellt
Idé
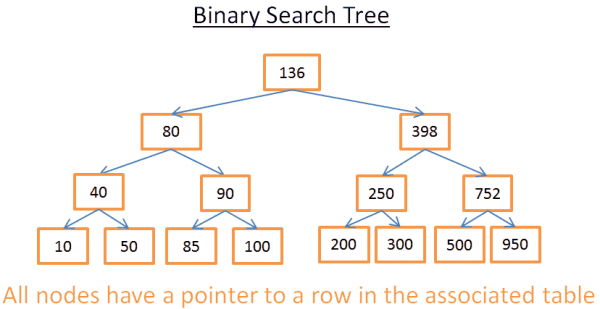
Detta träd har N = 15 element. Låt oss säga att jag letar efter 208:
- Jag börjar på roten vars nyckel är 136. Sedan 136<208 tittar jag på det högra underträdet till nod 136.
- 398>208 därför tittar jag på det vänstra underträdet av nod 398
- 250>208 därför tittar jag på det vänstra underträdet av nod 250
- 200<208, därför tittar jag på det högra underträdet i nod 200. Men 200 har inget höger underträd, värde finns inte (eftersom om det finns kommer det att finnas i det högra underträdet 200).
Låt oss säga att jag letar efter 40
- Jag börjar på roten vars nyckel är 136. Eftersom 136 > 40 tittar jag på det vänstra underträdet av nod 136.
- 80 > 40, därför tittar jag på det vänstra underträdet av nod 80
- 40=40, noden finns. Jag hämtar rad-ID inuti noden (visas inte på bilden) och letar i tabellen efter angivet rad-ID.
- Genom att känna till rad-ID:t kan jag veta exakt var data finns i tabellen, så att jag kan hämta den direkt.
I slutändan kommer båda sökningarna att kosta mig antalet nivåer inne i trädet. Om du läser delen om merge sort noggrant, bör du se att det finns log(N) nivåer. Det visar sig, sökkostnadslogg(N), inte dåligt!
Låt oss återgå till vårt problem
Men det här är väldigt abstrakt, så låt oss återgå till vårt problem. Istället för ett enkelt heltal, föreställ dig en sträng som representerar landet för någon i föregående tabell. Låt oss säga att du har ett träd som innehåller fältet "land" (kolumn 3) i tabellen:
- Om du vill veta vem som jobbar i Storbritannien
- du tittar på trädet för att få noden som representerar Storbritannien
- inuti "UKnode" hittar du platsen för brittiska arbetsuppgifter.
Denna sökning kommer att kosta log(N) operationer istället för N operationer om du använder arrayen direkt. Det du just presenterade var databasindex.
Du kan bygga ett indexträd för vilken grupp av fält som helst (sträng, nummer, 2 rader, nummer och sträng, datum...) så länge du har en funktion för att jämföra nycklar (dvs. fältgrupper) så att du kan ställa in ordning bland nycklarna (vilket är fallet för alla grundläggande typer i databasen).
B+Trädindex
Även om detta träd fungerar bra för att få ett specifikt värde, finns det ett STORT problem när du behöver få flera element mellan två värden. Detta kommer att kosta O(N) eftersom du måste titta på varje nod i trädet och kontrollera om den ligger mellan dessa två värden (t.ex. med en beställd korsning av trädet). Dessutom är denna operation inte disk I/O-vänlig eftersom du måste läsa hela trädet. Vi måste hitta ett sätt att effektivt utföra intervallförfrågan. För att lösa detta problem använder moderna databaser en modifierad version av det tidigare trädet som heter B+Tree. I ett B+träd:
- endast de lägsta noderna (löven) butiksinformation (placering av rader i den relaterade tabellen)
- resten av noderna är här för routing till rätt nod under sökning.
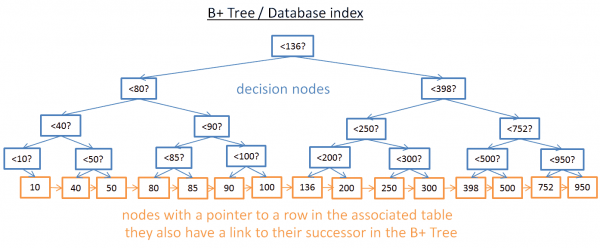
Som du kan se finns det fler noder här (två gånger). Du har faktiskt ytterligare noder, "beslutsnoder", som hjälper dig att hitta rätt nod (som lagrar platsen för raderna i den tillhörande tabellen). Men sökkomplexiteten är fortfarande O(log(N)) (det finns bara en nivå till). Den stora skillnaden är att noder på den lägre nivån är anslutna till sina efterföljare.
Med detta B+Tree, om du letar efter värden mellan 40 och 100:
- Du behöver bara leta efter 40 (eller det närmaste värdet efter 40 om 40 inte finns) som du gjorde med föregående träd.
- Samla sedan 40 arvingar med hjälp av direkta arvingar tills du når 100.
Låt oss säga att du hittar M efterföljare och trädet har N noder. Att hitta en specifik nod kostar log(N) som föregående träd. Men när du väl får den här noden kommer du att få M efterföljare i M-operationer med referenser till deras efterföljare. Denna sökning kostar bara M+log(N) operationer jämfört med N operationer på föregående träd. Dessutom behöver du inte läsa hela trädet (endast M+log(N)-noder), vilket innebär mindre diskanvändning. Om M är litet (t.ex. 200 rader) och N är stort (1 000 000 rader) blir det STOR skillnad.
Men det finns nya problem här (igen!). Om du lägger till eller tar bort en rad i databasen (och därmed i det tillhörande B+Tree-indexet):
- du måste upprätthålla ordning mellan noderna inuti ett B+Tree, annars kommer du inte att kunna hitta noderna inuti ett osorterat träd.
- du måste behålla minsta möjliga antal nivåer i B+Tree, annars blir O(log(N)) tidskomplexiteten O(N).
Med andra ord måste B+Tree vara självbeställande och balanserat. Lyckligtvis är detta möjligt med smarta borttagnings- och infogningsoperationer. Men detta kommer till en kostnad: insättningar och raderingar i ett B+-träd kostar O(log(N)). Det är därför några av er har hört det att använda för många index är inte en bra idé. Verkligen, du saktar ner snabb infogning/uppdatering/radering av en rad i en tabelleftersom databasen behöver uppdatera tabellens index med en dyr O(log(N))-operation för varje index. Dessutom innebär att lägga till index mer arbetsbelastning för transaktionsansvarig (kommer att beskrivas i slutet av artikeln).
För mer information kan du se Wikipedia-artikeln om . Om du vill ha ett exempel på att implementera B+Tree i en databas, ta en titt и från en ledande MySQL-utvecklare. De fokuserar båda på hur InnoDB (MySQL-motorn) hanterar index.
Notera: En läsare sa till mig att B+-trädet borde vara helt balanserat på grund av lågnivåoptimeringar.
Hastbar
Vår sista viktiga datastruktur är hashtabellen. Detta är mycket användbart när du snabbt vill slå upp värden. Dessutom kommer förståelsen av en hashtabell att hjälpa oss att senare förstå en vanlig databaskopplingsoperation som kallas en hash-join ( hash gå med). Denna datastruktur används också av databasen för att lagra vissa interna saker (t.ex. låsbord eller buffertpool, vi kommer att se båda dessa begrepp senare).
En hashtabell är en datastruktur som snabbt hittar ett element genom sin nyckel. För att bygga en hashtabell måste du definiera:
- ключ för dina element
- hash-funktion för nycklar. De beräknade nyckelhascharna anger platsen för elementen (kallas segment ).
- funktion för att jämföra nycklar. När du har hittat rätt segment måste du hitta det element du letar efter inom segmentet med hjälp av denna jämförelse.
Enkelt exempel
Låt oss ta ett tydligt exempel:
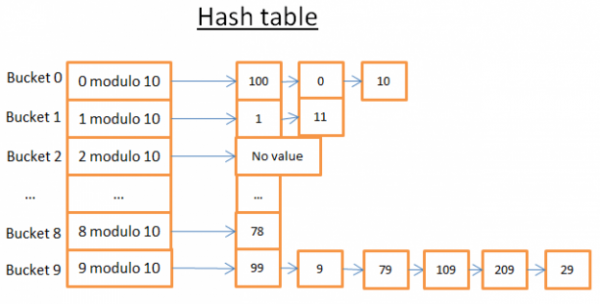
Denna hashtabell har 10 segment. Eftersom jag är lat, tog jag bara bilder på 5 segment, men jag vet att du är smart, så jag låter dig föreställa de andra 5 på egen hand. Jag använde en hash-funktion modulo 10 av nyckeln. Med andra ord lagrar jag bara den sista siffran i elementets nyckel för att hitta dess segment:
- om den sista siffran är 0, hamnar elementet i segment 0,
- om den sista siffran är 1, hamnar elementet i segment 1,
- om den sista siffran är 2, hamnar elementet i område 2,
- .
Jämförelsefunktionen jag använde är helt enkelt likhet mellan två heltal.
Låt oss säga att du vill få element 78:
- Hashtabellen beräknar hashkoden för 78, vilket är 8.
- Hashtabellen tittar på segment 8, och det första elementet den hittar är 78.
- Hon returnerar artikel 78 till dig
- Sökning kostar endast 2 operationer (en för att beräkna hashvärdet och den andra för att slå upp elementet inom segmentet).
Låt oss nu säga att du vill få element 59:
- Hashtabellen beräknar hashkoden för 59, vilket är 9.
- Hashtabellen söker i segment 9, det första elementet som hittas är 99. Eftersom 99!=59 är element 99 inte ett giltigt element.
- Med samma logik tas det andra elementet (9), det tredje (79), ..., det sista (29).
- Elementet hittades inte.
- Sökandet kostade 7 operationer.
Bra hashfunktion
Som du kan se, beroende på vilket värde du letar efter, är kostnaden inte densamma!
Om jag nu ändrar hashfunktionen modulo 1 000 000 av nyckeln (det vill säga tar de sista 6 siffrorna) kostar den andra uppslagningen bara 1 operation eftersom det inte finns några element i segment 000059. Den verkliga utmaningen är att hitta en bra hashfunktion som skapar hinkar som innehåller ett mycket litet antal element.
I mitt exempel är det lätt att hitta en bra hashfunktion. Men det här är ett enkelt exempel, att hitta en bra hashfunktion är svårare när nyckeln är:
- sträng (till exempel - efternamn)
- 2 rader (till exempel - efternamn och förnamn)
- 2 rader och datum (till exempel - efternamn, förnamn och födelsedatum)
- .
Med en bra hashfunktion kostar hashtabellssökningar O(1).
Array vs hashtabell
Varför inte använda en array?
Hmm, bra fråga.
- Hashbordet kan vara delvis laddad i minnet, och de återstående segmenten kan finnas kvar på disken.
- Med en array måste du använda sammanhängande utrymme i minnet. Om du laddar ett stort bord det är mycket svårt att hitta tillräckligt kontinuerligt utrymme.
- För en hashtabell kan du välja den nyckel du vill ha (till exempel land och personens efternamn).
För mer information kan du läsa artikeln om , som är en effektiv implementering av en hashtabell; du behöver inte förstå Java för att förstå begreppen som behandlas i den här artikeln.
Källa: will.com
