

Tere, mina olen Dmitri Logvinenko — andengineer grupi firmade «Vezot» analüütika osakonnas.
Kojutame teile suurepärasest tööriistast ETL-protsesside arendamiseks — Apache Airflow. Kuid Airflow on nii universaalne ja mitmekesine, et tasub sellele tähelepanu pöörata ka siis, kui te ei tegele andmevoogudega, vaid vajate aeg-ajalt mõne protsessi käivitamist ja nende täitmise jälgimist.
Jah, ma ei räägi ainult, vaid näitan ka: programmi sisaldab palju koodi, ekraanipilte ja soovitusi.
Mida tavaliselt näed, kui googeldad sõna Airflow / Wikimedia Commons
Sisukord
Sissejuhatus
Apache Airflow — ta on nagu Django:
- kirjutatud Pythonis,
- seal on suurepärane adminpaneel,
- piiramatu laiendatavusega,
— ainult parim, ja see on loodud hoopis muude eesmärkide jaoks, nimelt (nagu enne katset):
- ülesannete käivitamine ja jälgimine piiramatul arvul masinatel (nii palju kui teie südametunnistus ja Celery/Kubernetes lubavad)
- dünaamilise töövoo genereerimise abil, kasutades väga lihtsat Python-koodi, mis on lihtne kirjutada ja mõista
- ning võimalusega siduda omavahel mis tahes andmebaasid ja API-d valmiskomponentide ning isetehtud pluginatega (mida on äärmiselt lihtne teha).
Kasutame Apache Airflow'i järgmiselt:
- kogume andmeid erinevatest allikatest (mitmed SQL Serveri ja PostgreSQL instance, erinevad API-d rakenduste mõõdikute jaoks, isegi 1C) DWH-sse ja ODS-sse (meie puhul Vertica ja Clickhouse).
- nagu arenenud
cron, mis käivitab andmete konsolideerimise protsesse ODS-is ja jälgib ka nende haldamist.
Kuni hiljuti katab meie vajadusi üks väike server 32 tuuma ja 50 GB mäluga. Airflow'is töötab sel juhul:
- üle 200 dag'i (töötavad workflows, kuhu oleme ülesandeid täitnud),
- igaühes keskmiselt 70 ülesannet,
- killedakse seda (jällegi keskmiselt) üks kord tunnis..
Ja sellest, kuidas me laienesime, kirjutan alla, aga nüüd määratleme über-ülesande, mida me lahendame:
Kolmes SQL Serverit, igaühel 50 andmebaasi – ühe projekti instantsid, seega on neil struktuur peaaegu sama (peaaegu kõikjal, muha-haha), mis tähendab, et igas on tabel Orders (õnneks saab sellise nimega tabelit panna igasse ärisse). Me võtame andmed, lisades teenindusväljad (allikaserver, allikandmebaas, ETL-ülesande identifikaator) ning üritame nad süüdistusteta visata, ütleme, Verticasse.
Lähme!
Peamine, praktiline osa (ja natuke teooriat)
Miks see meile (ja teile) vajalik on
Kui puud olid suured ja mina olin lihtne SQL-hooldaja ühes Venemaa jaeketis, heitsime ETL-protsesside ehk andmevoogude kallale kahe käesolevate vahenditega:
- Informatica Power Center — äärmiselt keeruline süsteem, äärmiselt tootlik, oma riistvara ja versioneerimisega. Kasutasin võib-olla 1% selle võimalustest. Miks? No, esmalt, see liides on kuskil nullindatest vaimselt tapnud meid. Teiseks, see vidin on loodud äärmiselt keerukate protsesside, intensiivse komponentide taaskasutamise ja teiste väga-oluliste ettevõtte-nippide jaoks. Me jätame vahele, et see maksab sama palju kui Airbus A380 tiib/ aasta.
Olge ettevaatlik, ekraanipilt võib inimestele, kes on alla 30, natuke haiget teha.

- SQL Server Integration Server — seda tööriista oleme kasutanud oma siseprojektide voogudes. Tegelikult kasutame me juba SQL Serverit ja selle ETL tööriistade mittekasutamine oleks olnud ebaaus. Kõik on selles hästi: liides on ilus, ja töötlemisaruanded... Aga me ei armasta tarkvaratooteid selle pärast, oh ei. Versioonide haldamine
dtsx(mis on XML, millel on salvestamisel segased sõlmed) on meil võimalik, aga mis sellest kasu? Kuidas luua ülesannete pakett, mis tõmbab sada tabelit ühest serverist teise? Mis sada, kahekümne tabeliga kaotab teil sõrm, mis klõpsab rottnuppu. Kuid see näeb kindlasti stiilsem välja:
Oleme absoluutsetelt otsinud väljapääse. Asi oli peaaegu peaaegu jõudnud kohandatud SSIS-pakettide generaatorini...
... ja siis leidis mind uus töö. Ja seal tabas mind Apache Airflow.
Kui ma sain teada, et ETL-protsesside kirjeldused on lihtsalt Python'i kood, ei osanud ma rõõmust tantsida. Nii andmevood läbisid versioonihaldust ja diffimist, ning tabelite koondamine ühise struktuuriga sadadest andmebaasidest ühte sihtkohta muutus Python'i koodi kettaks 13” ekraanil.
Klastri kokkupanemine
Ärge muretsege siin lasteaiatuks, räägime hoopis asjadest, mis on ilmselged, nagu Airflow installimine, teie valitud andmebaas, Celery ja muud teemad, mis on dokumentides kirjeldatud.
Selleks, et me võiksime kohe katsetama asuda, olen ma koostanud docker-compose.yml mille sisu on järgmine:
- Käivitame enda Airflow: Scheduler, Webserver. Seal töötab ka Flower, et jälgida Celery ülesandeid (kuna see on juba pakitud
apache/airflow:1.10.10-python3.7, ja me pole selle vastu); - PostgreSQL, kuhu Airflow kirjutab oma logifailid (plaanijate andmed, täitmise statistika jne), ja Celery märkis lõpetatud ülesandeid;
- Redis, mis toimib Celery jaoks ülesannete vahendajana;
- Celery worker, mis tõeliselt tegeleb ülesannete täitmisega.
- Katalooge
./dagskasutame meie DAGi kirjeldusfailide salvestamiseks. Need tuvastatakse reaalajas, seega ei ole vaja kogu steki iga väiksema muudatuse järel edastada.
Mõnes kohas on kood näidetes osaliselt esitatud (et mitte teksti üle koormata), ja mõnes kohas muudetakse seda protsessi käigus. Terveid ja töötavaid koodinäiteid saab vaadata hoidlas. .
docker-compose.yml
version: '3.4'
x-airflow-config: &airflow-config
AIRFLOW__CORE__DAGS_FOLDER: /dags
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__FERNET_KEY: MJNz36Q8222VOQhBOmBROFrmeSxNOgTCMaVp2_HOtE0=
AIRFLOW__CORE__HOSTNAME_CALLABLE: airflow.utils.net:get_host_ip_address
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgres+psycopg2://airflow:airflow@airflow-db:5432/airflow
AIRFLOW__CORE__PARALLELISM: 128
AIRFLOW__CORE__DAG_CONCURRENCY: 16
AIRFLOW__CORE__MAX_ACTIVE_RUNS_PER_DAG: 4
AIRFLOW__CORE__LOAD_EXAMPLES: 'False'
AIRFLOW__CORE__LOAD_DEFAULT_CONNECTIONS: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_RETRY: 'False'
AIRFLOW__EMAIL__DEFAULT_EMAIL_ON_FAILURE: 'False'
AIRFLOW__CELERY__BROKER_URL: redis://broker:6379/0
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@airflow-db/airflow
x-airflow-base: &airflow-base
image: apache/airflow:1.10.10-python3.7
entrypoint: /bin/bash
restart: always
volumes:
- ./dags:/dags
- ./requirements.txt:/requirements.txt
services:
# Redis as a Celery broker
broker:
image: redis:6.0.5-alpine
# DB for the Airflow metadata
airflow-db:
image: postgres:10.13-alpine
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
volumes:
- ./db:/var/lib/postgresql/data
# Main container with Airflow Webserver, Scheduler, Celery Flower
airflow:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint initdb &&
(/entrypoint webserver &) &&
(/entrypoint flower &) &&
/entrypoint scheduler"
ports:
# Celery Flower
- 5555:5555
# Airflow Webserver
- 8080:8080
# Celery worker, will be scaled using `--scale=n`
worker:
<<: *airflow-base
environment:
<
-c " sleep 10 &&
pip install --user -r /requirements.txt &&
/entrypoint worker"
depends_on:
- airflow
- airflow-db
- brokerMärkused:
- Kompositsiooni koostamisel toetus mulle palju tuntud mudelid. — kindlasti vaadake. Võib-olla ei vajagi te elus midagi muud.
- Kõik Airflow seadistused on saadaval mitte ainult läbi
airflow.cfg, vaid ka keskkonnaparameetrite kaudu (tänu arendajatele), mille kaudu ma laialdaselt kasutasin. - Muidugi ei ole see production-ready: ma ei seadnud konteineritele teadetega ühendust ja ei aja turvalisusega jamas. Aga miinimum, mis sobib meie katsetamiseks, on loomulikult olemas.
- Pange tähele, et:
- DAG-failide kaust peab olema juurdepääsetav nii ajastajale kui ka töötajatele.
- Sama kehtib ka kõikide kolmandate osapoolte raamatukogude kohta — need peavad olema installitud masinatesse, kus on ajastaja ja töötajad.
Nüüd on see lihtne:
$ docker-compose up --scale worker=3Pärast seda, kui kõik on üles tõusnud, saab vaadata veebiliideseid:
- Airflow:
- Flower:
Peamised mõisted
Kui te ei saanud aru nendest "DAGidest", siis siin on lühike sõnastik:
- Ajastaja — kõige tähtsam tegelane Airflow's, kes jälgib, et töötehnikud teevad tööd ja mitte inimene: jälgib graafikut, värskendab DAG-e, käivitab ülesandeid.
Üldiselt, vanades versioonides olid tal mäluga (ei, mitte amneesia, vaid leketega) probleemid ja konfiguratsioonides jäi isegi alles pärandparameeter.
run_duration— tema taaskäivitamisintervall. Kuid nüüd on kõik korras. - DAG (niisugune "dag") — "suunatud aktsükliline graaf", kuid selline määratlemine ütleb vähe kellelegi, kuigi tegelikult on see konteiner omavahel suhtlevate ülesannete jaoks (vt allpool) või analoog paketile SSIS ja töövoogudele Informatica-s.
Lisaks DAG-idele võivad olla veel subdag-id, kuid me ei jõua neid tõenäoliselt käsitleda.
- DAG Run — initsialiseeritud DAG, millele on antud oma
execution_date. Ühe DAG-i DAG-runnid võivad kenasti töötada paralleelselt (kui olete oma ülesanded idempotentseteks teinud). - Operator — need on koodijupid, mis vastutavad konkreetse tegevuse täitmise eest. On kolm tüüpi operaatorit:
- action, nagu näiteks meie lemmik
PythonOperator, mis on võimeline täitma igasugust (kehtivat) Python-koodi; - transfer, mis viivad andmeid ühest kohast teise, näiteks
MsSqlToHiveTransfer; - sensor , mis võimaldab reageerida või peatada DAG-i edasise täitmise mingisuguse sündmuse toimumiseni.
HttpSensorsuudab küsida määratud lõpp-punkti ja kui ootab vajalikku vastust, alustada ülekannetGoogleCloudStorageToS3Operator. Uudishimu küsib: „miks? Kõike saab ju teha otse operaatori sees!” Järgnevalt, et mitte koormata tööülesannete panga riputanud operaatoritega. Sensor käivitub, kontrollib ja sureb järgmise katse ootamiseks.
- action, nagu näiteks meie lemmik
- Ülesanne — kuulutatud operaatorid, sõltumata tüübist ja seotud DAGiga, tõstetakse ülesande tasemele.
- Ülesande instants — kui peaplanner otsustab, et ülesanded on valmis heidma võitlejate töödele (otse kohal, kui me kasutame
LocalExecutorvõi kaugnõlva puhulCeleryExecutor), määrab ta neile konteksti (st muutujate komplekti — täitmise parameetrid), rakendab käsu või päringu malle ning paneb need pangale.
Ülesannete genereerimine
Esmalt määratlege meie DAGi üldine skeem ja seejärel süveneme üha rohkem detailidesse, sest rakendame mõningaid ebatavalisi lahendusi.
Nii et kõige lihtsamas vormis näeb selline DAG välja nii:
impordi {timedelta, datetime}
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from commons.datasources import sql_server_ds
dag = DAG('orders',
schedule_interval=timedelta(hours=6),
start_date=datetime(2020, 7, 8, 0))
def workflow(**context):
print(context)
for conn_id, schema in sql_server_ds:
PythonOperator(
task_id=schema,
python_callable=workflow,
provide_context=True,
dag=dag)Alustame:
- Esimesena impordime vajalikud teegid ja veel mõned asjad;
sql_server_ds— see onList[namedtuple[str, str]], mis sisaldab Airflow Connections-i ühenduste nimesid ja andmebaase, millest me oma tabelit võtame;dag— meie DAG-i deklareerimine, mis peab kindlasti olemaglobals(), muidu Airflow ei leia seda. DAG-ile tuleb ka öelda:- kuidas seda nimetada
orders— see nimi ilmub hiljem veebiliideses, - et see hakkab tööle alates 8. juulist keskööst,
- ja et selle ajakavad on umbes iga 6 tunni järel (kõvadele kutidele on siin 'timedelta()' asemel lubatud
-string, vähem kõvadele kutidele - lause nagucron@daily0 0 0/6 ? * * *workflow()teeb põhiosa tööst, aga mitte nüüd. Hetkel lihtsalt väljastame meie konteksti logisse.);
- kuidas seda nimetada
Ja nüüd lihtne maagia ülesannete loomise osas:kõnnime allikate järgi;- algatame
- , mis täidab meie tühi funktsioon
- initsialiseerime
PythonOperator, mis täidab meie tühikutJa nüüd lihtne maagia ülesannete loomise osas:. Ära unusta anda unikaalne (DAGi piires) ülesande nimi ning siduda see DAGiga. Lippprovide_contexttoob omakorda funktsiooni täiendavad argumendid, mille me ettevaatlikult kogume**context.
Siinkohal lõpetame. Mida me oleme saanud:
- uus DAG veebiliideses,
- kahesaja viiskümmend ülesannet, mis töötavad paralleelselt (kui Airflow, Celery ja serverite seaded seda lubavad).
Noh, peaaegu saime.
Kes paigaldab sõltuvused?
Kogu seda asja lihtsustada, lükkasin ma docker-compose.yml töötlemisse requirements.txt kõikidesse nodidesse.
Nüüd läheb asi kiireks:
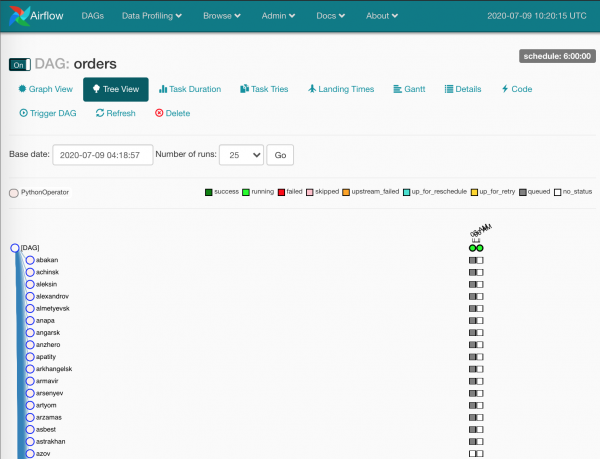
Hallid ruudud — ülesande instantsid, mida planeerija on töötlenud.
Ootame veidi, ülesanded haaravad töötajad:
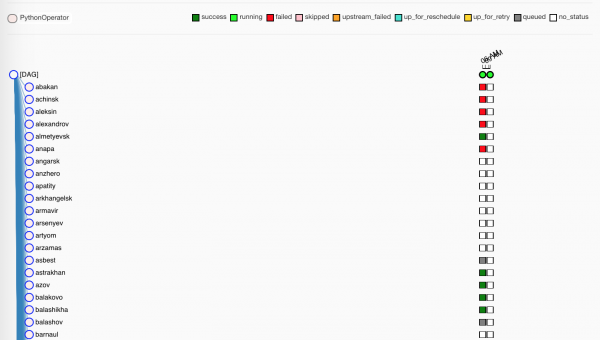
Rohelised, loomulikult, — edukalt läbitud. Punased — mitte nii edukalt.
Muide, meie tootmises ei ole mingit kausta
./dags, mis sünkroniseerub masinate vahel — kõik DAGid asuvadgitmeie Gitlabis, ja Gitlab CI seab uuendused masinatesse, kui need on kokku pandudmaster.
Natuke Flowerist
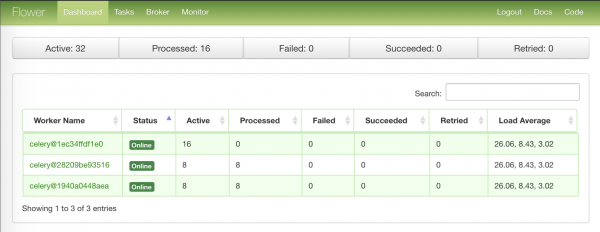
Kuni töötajad töötlevad meie tühje ülesandeid, tuletame meelde veel ühe tööriista, mis võib meile mõningaid asju näidata — Flower.
Esimene leht, kus on kokkuvõtete info töötajate nodide kohta:
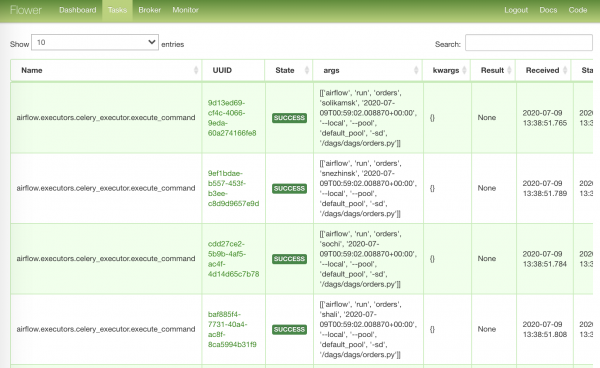
Kõige sisukam leht ülesannetega, mis on töös:
Kõige igavam leht meie maaklerite seisuga:
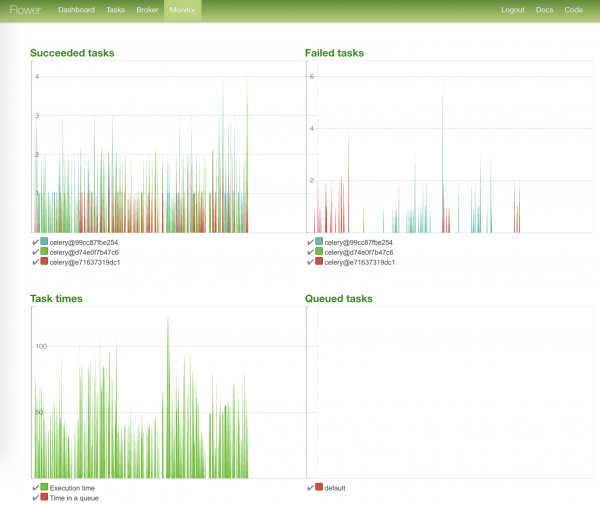
Kõige silmatorkavam leht — ülesannete seisugraafik ja nende täitmise ajad:
Laadime alla, mis ei ole laaditud
Nii, kõik ülesanded on töös, saame kannatanud välja viia.
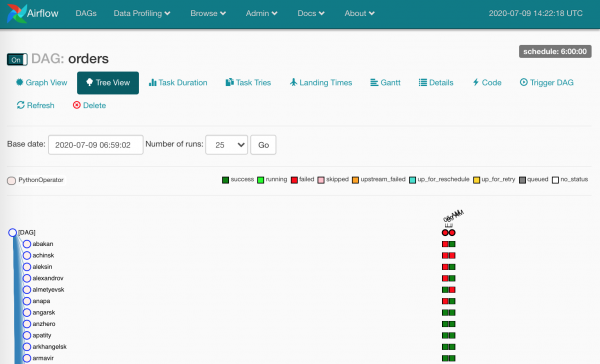
Ja kannatanuid oli päris mitu — erinevatel põhjustel. Kui Airflowd õigesti kasutada, siis need ruudud näitavad, et andmed pole kindlasti kohale jõudnud.
Tuleb vaadata logi ja taaskäivitada kukkunud ülesandeinstantsid.
Klikkides mõnel ruudul, näeme meie jaoks saadaval olevaid tegevusi:
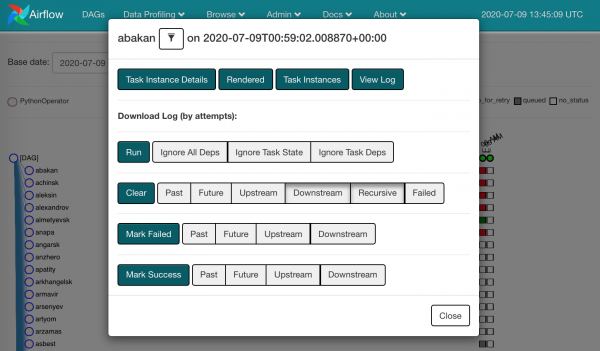
Saame võtta ja teha kukkunutele Clear. See tähendab, et unustame, et seal midagi takerdus, ja sama ülesandeinstants suundub planeerijale.

Selge, et teiste punaste ruutudega hiirega nii käituda ei ole kuigi inetu — mitte seda me Airflowlt ootame. Loomulikult on meil massihävitusrelv: Browse/Task Instances
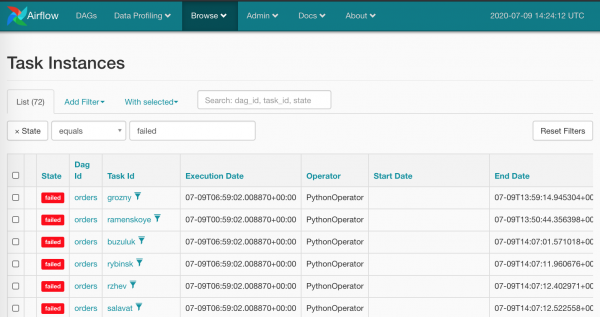
Valime kõik korraga ja nullime, vajutame õiget punkti:
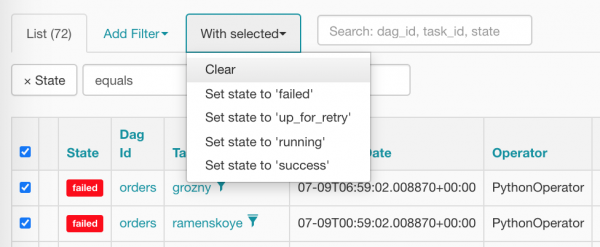
Pärast puhastamist näevad meie taksod välja nii (nad juba ootavad, millal planeerija nad plaanib):

Ühendused, hooikud ja muud muutujad
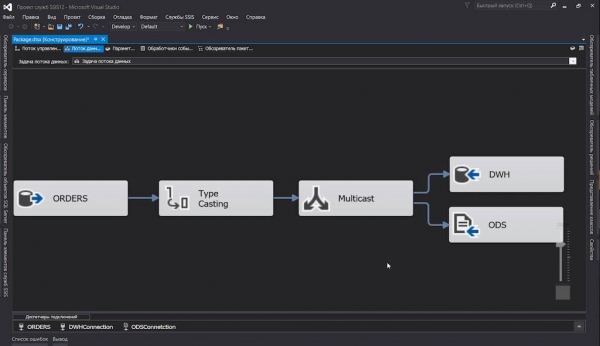
On viimane aeg vaadata järgmist DAG-i, update_reports.py:
from collections import namedtuple
from datetime import datetime, timedelta
from textwrap import dedent
from airflow import DAG
from airflow.contrib.operators.vertica_operator import VerticaOperator
from airflow.operators.email_operator import EmailOperator
from airflow.utils.trigger_rule import TriggerRule
from commons.operators import TelegramBotSendMessage
dag = DAG('update_reports',
start_date=datetime(2020, 6, 7, 6),
schedule_interval=timedelta(days=1),
default_args={'retries': 3, 'retry_delay': timedelta(seconds=10)})
Report = namedtuple('Report', 'source target')
reports = [Report(f'{table}_view', table) for table in [
'reports.city_orders',
'reports.client_calls',
'reports.client_rates',
'reports.daily_orders',
'reports.order_duration']]
email = EmailOperator(
task_id='email_success', dag=dag,
to='{{ var.value.all_the_kings_men }}',
subject='DWH Reports updated',
html_content=dedent("""Tere, head inimesed, raportid on uuendatud"""),
trigger_rule=TriggerRule.ALL_SUCCESS)
tg = TelegramBotSendMessage(
task_id='telegram_fail', dag=dag,
tg_bot_conn_id='tg_main',
chat_id='{{ var.value.failures_chat }}',
message=dedent("""
Natasha, ärka üles, me kukutasime {{ dag.dag_id }}
"""),
trigger_rule=TriggerRule.ONE_FAILED)
for source, target in reports:
queries = [f"TRUNCATE TABLE {target}",
f"INSERT INTO {target} SELECT * FROM {source}"]
report_update = VerticaOperator(
task_id=target.replace('reports.', ''),
sql=queries, vertica_conn_id='dwh',
task_concurrency=1, dag=dag)
report_update >> [email, tg]Kas oleme kõik kunagi aru saanud aruandeid uuendama? Siin see on jälle: meil on loetelu allikatest, kust andmed võtta; on loetelu, kuhu need panna; ärme unustame signaale anda, kui kõik on sündinud või purunenud (aga see ei kehti meie kohta, eks?).
Vaadakem uuesti faili ja vaatame uusi mõistetavaid asju:
from commons.operators import TelegramBotSendMessage— mis takistab meid oma operaatorite loomisel, ja me kasutasime seda ära, tehes väikese mähise sõnumite saatmiseks Razblokirovanny'sse. (Selle operaatori kohta räägime veel allpool);default_args={}— DAG võib jagada samu argumente kõigile oma operaatoritele;to='{{ var.value.all_the_kings_men }}'— välitomeil ei ole seda kõvakooditud, vaid dünaamiliselt genereeritav Jinja ja muutujaga, kus on e-posti aadresside loend, mille ma ettevaatlikult paninAdmin/Variables;trigger_rule=TriggerRule.ALL_SUCCESS— operaatori käivitamise tingimus. Meie juhul saadetakse kiri juhtidele ainult juhul, kui kõik sõltuvused on töötanud edu;tg_bot_conn_id='tg_main'— argumendidconn_idvõtavad endasse ühenduste identifikaatorid, mille me loomeAdmin/Connections;trigger_rule=TriggerRule.ONE_FAILED— sõnumid Telegramis saadetakse ainult siis, kui on ebaõnnestunud ülesandeid;task_concurrency=1— keelame ühe ülesande mitme taski instantsi samaaegse käitamise. Vastasel juhul saame mitu ülesande instantsi,VerticaOperator(mis vaatavad ühte tabelit);report_update >> [email, tg]— kõikVerticaOperatorkoondatakse e-kirjade ja sõnumite saatmiseks, nagu järgneb:

Kuna aga teavitajate operaatoritel on erinevad käivitamistingimused, töötab vaid üks. Tree View'is näeb see välja vähem läbipaistev:

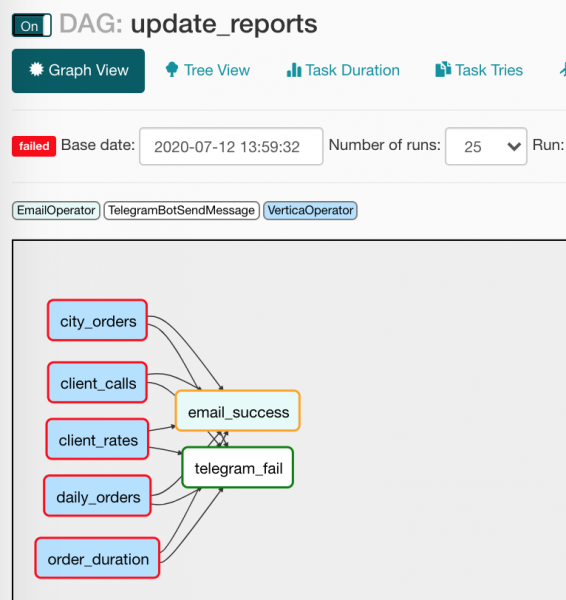

Räägin natuke makrode ja nende sõprade — muutujate.
Makrod on Jinja-sisu kohandajad, mis võivad asetada erinevat kasulikku teavet operaatorite argumentidesse. Näiteks nii:
SELECT
id,
payment_dtm,
payment_type,
client_id
FROM orders.payments
WHERE
payment_dtm::DATE = '{{ ds }}'::DATE{{ ds }} laiendab konteksti muutujate sisu execution_date vormingus YYYY-MM-DD: 2020-07-14. Parim on see, et konteksti muutujad on kinnitatud kindla taski instantsi (ruudu) külge Tree View'is, ja kui instantsi uuesti käivitada, lahetakse kohandajad samadele väärtustele.
Määratud väärtusi saab vaadata igas taski instantsis nupul Rendered. Nii on e-kirjade saatmise ülesande puhul:
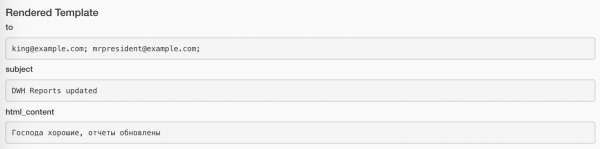
Ja nii on sõnumi saatmise ülesande puhul:

Viimane koodiversioon sisaldab kõiki integreeritud makrode loendit, mis on saadaval siin:
Lisaks saame pluginade abil luua oma makrosid, kuid sellest räägime hiljem.
Eeldefineeritud asjade kõrval saame sisestada ka oma muutuja väärtusi (nagu olen juba koodis teinud). Loome mõned: Admin/Variables paar asja:
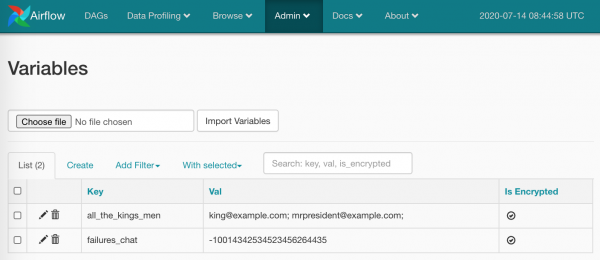
Nii, nüüd saab kasutada:
TelegramBotSendMessage(chat_id='{{ var.value.failures_chat }}')Väärtuses võib olla skalaarsed andmed või isegi JSON. JSON-i puhul:
bot_config
{
"bot": {
"token": 881hskdfASDA16641,
"name": "Verter"
},
"service": "TG"
}kasutame lihtsalt õige võtme teed: {{ var.json.bot_config.bot.token }}.
Ütlen lihtsalt ühe sõna ja näitan ühte ekraanipilti seoses ühendustega. Siin on kõik lihtne: lehe peal Admin/Connections loome ühenduse, salvestame sinna oma kasutajanimesid/paroolid ja spetsiifilisemad parameetrid. Nii:
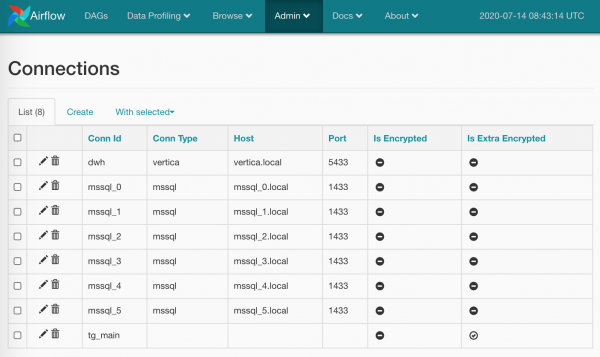
Paroolid saab krüpteerida (täiendavalt, kui võrrelda vaikeseadetega) või ei pea ka ühenduse tüüpi mainima (nagu ma tegin) tg_main) — asi on selles, et Airflow mudelites on tüüpide nimekiri sisse ehitatud ja seda ei saa muudetud allikateta laiendada (kui ma midagi valesti otsisin — palun parandage mind), kuid me ei takista midagi, et saada akrediteeringud lihtsalt nime järgi.
Samuti saab luua mitu ühendust sama nimega: sellisel juhul meetod BaseHook.get_connection(), mis toob meile ühendused nime järgi, annab juhusliku mitme sarnase seas (loogilisem oleks olnud kasutada Round Robin'i, kuid jätame selle Airflow arendajate südametunnistusele).
Muutujad ja ühendused on kindlasti suurepärased tööriistad, kuid on oluline hoida tasakaalu: millised osad teie voogudest te hoiate koodis ja milliseid — annate Airflow’le säilitamiseks. Ühelt poolt võib väärtuse, näiteks postkasti, kiirelt muutmine UI kaudu olla mugav. Teiselt poolt on see siiski tagasipöördumine hiireklikkide juurde, millest me (mina) tahtsime vabaneda.
Ühendustega töötamine on üks hook'ideülesandeid. Üldiselt on Airflow hook'id side punktid kolmandate teenuste ja raamatukogudega. Näiteks, JiraHook avatakse meie jaoks klient, et suhelda Jira'ga (saame ülesandeid edasi-tagasi liigutada), ja SambaHook abil saab pushida kohaliku faili smb-punkti.
Kohandatud operaatori analüüs
Ja me oleme lähenenud sellele, et vaadata, kuidas on tehtud TelegramBotSendMessage
Kood commons/operators.py isegi operaatori juurde:
from typing import Union
from airflow.operators import BaseOperator
from commons.hooks import TelegramBotHook, TelegramBot
class TelegramBotSendMessage(BaseOperator):
"""Saada sõnum chat_id-le, kasutades TelegramBotHook'i
Näide:
>>> TelegramBotSendMessage(
... task_id='telegram_fail', dag=dag,
... tg_bot_conn_id='tg_bot_default',
... chat_id='{{ var.value.all_the_young_dudes_chat }}',
... message='{{ dag.dag_id }} ebaõnnestus :(',
... trigger_rule=TriggerRule.ONE_FAILED)
"""
template_fields = ['chat_id', 'message']
def __init__(self,
chat_id: Union[int, str],
message: str,
tg_bot_conn_id: str = 'tg_bot_default',
*args, **kwargs):
super().__init__(*args, **kwargs)
self._hook = TelegramBotHook(tg_bot_conn_id)
self.client: TelegramBot = self._hook.client
self.chat_id = chat_id
self.message = message
def execute(self, context):
print(f'Saada "{self.message}" chat' + f'{self.chat_id}')
self.client.send_message(chat_id=self.chat_id,
message=self.message)Siin, nagu kõik muu Airflow's, on kõik väga lihtne:
- Oleme pärinud
BaseOperator, mis rakendab üsna palju Airflow'le spetsiifilisi asju (vaadake rahus) - Oleme kuulutanud välja väljad
template_fields, kus Jinja otsib makrosid töötlemiseks. - Oleme korraldanud õiged argumendid
__init__(), määrasid vaikimisi, kus vaja. - Eeljätku initsialiseerimist ei unustatud.
- Avatud vastav hook.
TelegramBotHook, saime temalt klient-objekti. - Ülekirjutasime meetodi.
BaseOperator.execute(), mida Airflow kutsub, kui on aega operaatori käivitamiseks — selles realiseerime põhitegevuse, unustamata logida. (Logime, muide, kohe.stdoutjastderr— Airflow kõik püüab kinni, pakib ilusti kokku ja paigutab õigesse kohta.)
Vaadakem, mis meil on failis commons/hooks.py. Faili esimene osa, mis sisaldab hooki:
from typing import Union
from airflow.hooks.base_hook import BaseHook
from requests_toolbelt.sessions import BaseUrlSession
class TelegramBotHook(BaseHook):
"""Telegram Bot API hook
Märkus: lisage ühendus tühja Conn Type'iga ja ärge unustage
täita Extra:
{"bot_token": "YOuRAwEsomeBOtToKen"}
"""
def __init__(self,
tg_bot_conn_id='tg_bot_default'):
super().__init__(tg_bot_conn_id)
self.tg_bot_conn_id = tg_bot_conn_id
self.tg_bot_token = None
self.client = None
self.get_conn()
def get_conn(self):
extra = self.get_connection(self.tg_bot_conn_id).extra_dejson
self.tg_bot_token = extra['bot_token']
self.client = TelegramBot(self.tg_bot_token)
return self.clientMa isegi ei tea, mida siin seletada, lihtsalt toon välja mõned olulised punktid:
- Kasutame pärandit, mõtleme argumentide üle — enamikul juhtudel on see üks:
conn_id; - Üksikute standardmeetodite ületamine: piirdun
get_conn(), kus ma saan ühenduse parameetrid nime järgi ja lihtsalt tõmban sektsiooniextra(see väli on JSON-i jaoks), kuhu ma (kui ma ise juba selgitasin!) panin Telegrami boti tokeni:{"bot_token": "YOuRAwEsomeBOtToKen"}. - Loome meie
TelegramBot, edastades talle konkreetse tokeni.
Ja ongi kõik. Saame kliendi ülesandest läbi TelegramBotHook().clent või TelegramBotHook().get_conn().
Ja teises osas faile, kus ma teen mikropakkumise Telegram REST API jaoks, et mitte vedada sama ühe meetodi jaoks sendMessage.
class TelegramBot:
"""Telegram Bot API wrapper
Examples:
>>> TelegramBot('YOuRAwEsomeBOtToKen', '@myprettydebugchat').send_message('Hi, darling')
>>> TelegramBot('YOuRAwEsomeBOtToKen').send_message('Hi, darling', chat_id=-1762374628374)
"""
API_ENDPOINT = 'https://api.telegram.org/bot{}/'
def __init__(self, tg_bot_token: str, chat_id: Union[int, str] = None):
self._base_url = TelegramBot.API_ENDPOINT.format(tg_bot_token)
self.session = BaseUrlSession(self._base_url)
self.chat_id = chat_id
def send_message(self, message: str, chat_id: Union[int, str] = None):
method = 'sendMessage'
payload = {'chat_id': chat_id or self.chat_id,
'text': message,
'parse_mode': 'MarkdownV2'}
response = self.session.post(method, data=payload).json()
if not response.get('ok'):
raise TelegramBotException(response)
class TelegramBotException(Exception):
def __init__(self, *args, **kwargs):
super().__init__((args, kwargs))Õige tee on kõik see kokku panna:
TelegramBotSendMessage,TelegramBotHook,TelegramBot— plugina, panna avalikku hoidlasse ja jagada avatud lähtekoodiga.
Kuna me kõike seda uurisime, olid meie raporti värskendused edukalt ilmu t seekord kokku kukkunud ja saatsid mulle kanalis vea teate. Pean minema kontrollima, mis seekord valesti läks…
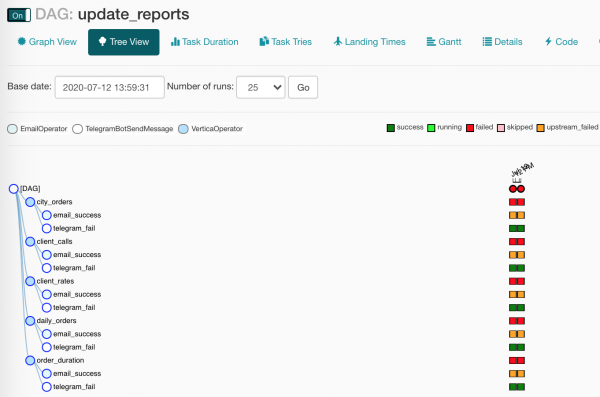
Meie dags on katki! Ja ei olnud just seda, mida me ootasime? Just nimelt!
Kas hakkad valama?
Kas tunnete, et jätan midagi tähelepanuta? Tundub, et lubasin andmed SQL Serverist Vertica'le üle kanda, ja nüüd läksin teemadest kõrvale, kurat!
Kuritegu oli tahtlik, ma pidin teile selgitama mõningaid termineid. Nüüd saame liikuda edasi.
Meie plaan oli järgmine:
- Luua dag
- Genererida ülesanded
- Vaadata, kui ilus kõik välja näeb
- Kinnituselamistele jagada sessiooninumbreid
- Andmete võtmine SQL Serverist
- Andmete paigutamine Verticasse
- Statistika kogumine
Nii et selle kõik käivitamiseks tegin väikese täienduse meie docker-compose.yml:
docker-compose.db.yml
version: '3.4'
x-mssql-base: &mssql-base
image: mcr.microsoft.com/mssql/server:2017-CU21-ubuntu-16.04
restart: always
environment:
ACCEPT_EULA: Y
MSSQL_PID: Express
SA_PASSWORD: SayThanksToSatiaAt2020
MSSQL_MEMORY_LIMIT_MB: 1024
services:
dwh:
image: jbfavre/vertica:9.2.0-7_ubuntu-16.04
mssql_0:
<<: *mssql-base
mssql_1:
<<: *mssql-base
mssql_2:
<<: *mssql-base
mssql_init:
image: mio101/py3-sql-db-client-base
command: python3 ./mssql_init.py
depends_on:
- mssql_0
- mssql_1
- mssql_2
environment:
SA_PASSWORD: SayThanksToSatiaAt2020
volumes:
- ./mssql_init.py:/mssql_init.py
- ./dags/commons/datasources.py:/commons/datasources.pySeal me tõstame:
- Vertica kui host
dwhkõige vaikimisi seadistustega, - kolm SQL Serveri instantsi,
- täidame andmebaasid viimaste andmetega (ärge lükake vaadata
mssql_init.py!)
Käivitame kogu selle hea veidi keerulisema käsu abil kui eelmisel korral:
$ docker-compose -f docker-compose.yml -f docker-compose.db.yml up --scale worker=3Mida meie imetore juhuslik generaator genereeris, saab kasutada punkti kaudu Andmete profiilimine/Ad Hoc päring:
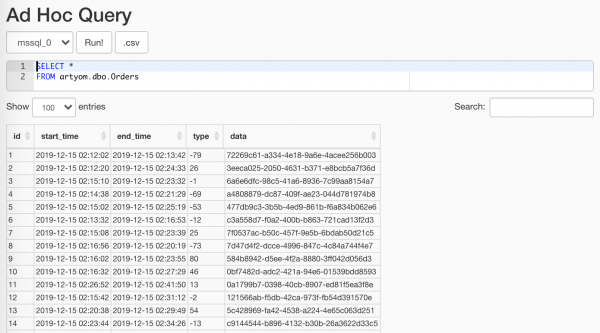
Peamine, et seda analüütikutele ei näidata
Detailidesse laskuda ETL-seansid ei hakka, seal on kõik triviaalne: loome andmebaasi, sinna tabeli, mähkime kõik konteksti haldajasse ja nüüd teeme nii:
with Session(task_name) as session:
print('Load', session.id, 'started')
# Laadimise töövoog
...
session.successful = True
session.loaded_rows = 15session.py
from sys import stderr
class Session:
"""ETL töövoo sessioon
Näide:
with Session(task_name) as session:
print(session.id)
session.successful = True
session.loaded_rows = 15
session.comment = 'Tore töö'
"""
def __init__(self, connection, task_name):
self.connection = connection
self.connection.autocommit = True
self._task_name = task_name
self._id = None
self.loaded_rows = None
self.successful = None
self.comment = None
def __enter__(self):
return self.open()
def __exit__(self, exc_type, exc_val, exc_tb):
if any(exc_type, exc_val, exc_tb):
self.successful = False
self.comment = f'{exc_type}: {exc_val}n{exc_tb}'
print(exc_type, exc_val, exc_tb, file=stderr)
self.close()
def __repr__(self):
return (f'')
@property
def task_name(self):
return self._task_name
@property
def id(self):
return self._id
def _execute(self, query, *args):
with self.connection.cursor() as cursor:
cursor.execute(query, args)
return cursor.fetchone()[0]
def _create(self):
query = """
LOONI TABEL, KUI EI OLE JUBA olemas sessioonid (
id SERIAL NOT NULL PRIMARY KEY,
task_name VARCHAR(200) NOT NULL,
started TIMESTAMPTZ NOT NULL DEFAULT current_timestamp,
finished TIMESTAMPTZ DEFAULT current_timestamp,
successful BOOL,
loaded_rows INT,
comment VARCHAR(500)
);
"""
self._execute(query)
def open(self):
query = """
INSERT INTO sessions (task_name, finished)
VALUES (%s, NULL)
RETURNING id;
"""
self._id = self._execute(query, self.task_name)
print(self, 'avatud')
return self
def close(self):
if not self._id:
raise SessionClosedError('Sessioon ei ole avatud')
query = """
UPDATE sessions
SET
finished = DEFAULT,
successful = %s,
loaded_rows = %s,
comment = %s
WHERE
id = %s
RETURNING id;
"""
self._execute(query, self.successful, self.loaded_rows,
self.comment, self.id)
print(self, 'suletud',
', edukas: ', self.successful,
', Laetud: ', self.loaded_rows,
', kommentaar:', self.comment)
class SessionError(Exception):
pass
class SessionClosedError(SessionError):
passOn aeg teha meie andmete võtmisest meie poolest sada tabelit. Teeme seda lihtsate ridade abil:
source_conn = MsSqlHook(mssql_conn_id=src_conn_id, schema=src_schema).get_conn()
query = f"""
SELECT
id, start_time, end_time, type, data
FROM dbo.Orders
WHERE
CONVERT(DATE, start_time) = '{dt}'
"""
df = pd.read_sql_query(query, source_conn)- Kasutame Airflow'd, et saada
pymssql-ühendust - Lisame päringusse kuupäeva piirangu — funktsioon lisab selle šabloonide kaudu.
- Saadame meie päringu
pandas, mis toob meileDataFrame— see tuleb meile kasuks edaspidi.
Kasutame asendust
{dt}päringu parameetri asemel%smitte sellepärast, et ma oleks kuri Buratino, vaid sellepärast, etpandasei oska hakkama saadapymssqlja annab viimasele edasiparams: List, kuigi see väga tahabtuple.
Olge tähelepanelik, et arendajapymssqlotsustas seda enam mitte toetada, ja on viimane aeg minna ülepyodbc.
Vaadakem, millised argumendid Airflow meie funktsioonidesse sisestas:
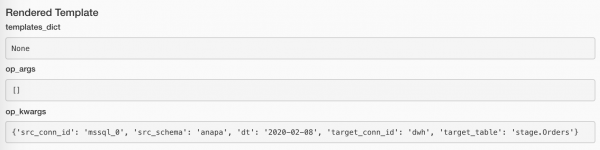
Kui andmeid polnud, siis pole mõtet edasi minna. Kuid arvestada, et üleslaadimine oli edukas, on ka kummaline. Kuid see ei ole ka viga. Ah, mida teha?! Niimoodi:
if df.empty:
raise AirflowSkipException('No rows to load')AirflowSkipException Airflow ütleb, et viga ei ole, ja ülesanne jäetakse vahele. Liideses ei ole rohelise ega punase ruudu asemel roosa värv.
Lisame oma andmetele mitu veergu:
df['etl_source'] = src_schema
df['etl_id'] = session.id
df['hash_id'] = hash_pandas_object(df[['etl_source', 'id']])Konkreetsemalt:
- Andmebaas, kust me tellimused saime,
- Meie laadimise seansi identifikaator (see erineb kõigil ülesannetel),
- Ressursi ja tellimuse identifikaatorist saadud hash — et lõpp-andmebaasis (kus kõik kogutakse ühte tabelisse) oleks ainulaadne tellimuse identifikaator.
Jäänud on eelviimane samm: laadida kõik Verticasse. Ja, kummalisel kombel, üks kõige efektsematest viisidest selleks on CSV kaudu!
# Export data to CSV buffer
buffer = StringIO()
df.to_csv(buffer,
index=False, sep='|', na_rep='NUL', quoting=csv.QUOTE_MINIMAL,
header=False, float_format='%.8f', doublequote=False, escapechar='\')
buffer.seek(0)
# Push CSV
target_conn = VerticaHook(vertica_conn_id=target_conn_id).get_conn()
copy_stmt = f"""
COPY {target_table}({df.columns.to_list()})
FROM STDIN
DELIMITER '|'
ENCLOSED '"'
ABORT ON ERROR
NULL 'NUL'
"""
cursor = target_conn.cursor()
cursor.copy(copy_stmt, buffer)- Loome spetsiaalse vastuvõtja
StringIO. pandasmis kenasti kogub meieDataFramekujulCSV-ridu.- Avame ühenduse meie lemmik Vertica hookiga.
- Ja nüüd kasutame
copy()saadame meie andmed otse Verticasse!
Draiverist saame, kui palju ridu laaditi, ja ütleme seansi juhile, et kõik on OK:
session.loaded_rows = cursor.rowcount
session.successful = TrueJa kõik.
Tootmises loome sihttabeli käsitsi. Siin julgen lubada väikest automatiseerimist:
create_schema_query = f'CREATE SCHEMA IF NOT EXISTS {target_schema};'
create_table_query = f"""
CREATE TABLE IF NOT EXISTS {target_schema}.{target_table} (
id INT,
start_time TIMESTAMP,
end_time TIMESTAMP,
type INT,
data VARCHAR(32),
etl_source VARCHAR(200),
etl_id INT,
hash_id INT PRIMARY KEY
);"""
create_table = VerticaOperator(
task_id='create_target',
sql=[create_schema_query,
create_table_query],
vertica_conn_id=target_conn_id,
task_concurrency=1,
dag=dag)Ma olen abiks
VerticaOperator()loome andmebaasi skeemi ja tabeli (kui neid pole, muidugi). Peamine on õigesti seada sõltuvused:
for conn_id, schema in sql_server_ds:
load = PythonOperator(
task_id=schema,
python_callable=workflow,
op_kwargs={
'src_conn_id': conn_id,
'src_schema': schema,
'dt': '{{ ds }}',
'target_conn_id': target_conn_id,
'target_table': f'{target_schema}.{target_table}'},
dag=dag)
create_table >> loadTeeme kokkuvõtteid
— Noh, — ütles hiir, — ei ole tõsi, et nüüd
Sa veendusid, et metsas olen mina kõige hirmsam metsaline?
Julia Donaldson, „Gruffalo“
Ma arvan, et kui me oma kolleegidega korraldaksime konkurentsi: kes suudab kiiremini koostada ja käivitada ETL-protsessi nullist: nemad oma SSIS ja hiirega ning mina Airflow’ga… Ja seejärel võrdleksime hooldamise mugavust… Oh, arvan, et nõustute, et ma tõenäoliselt ületan neid igal rindel!
Kui võtta asja veidi tõsisemalt, siis Apache Airflow — tänu protsesside kirjeldamisele programmeerimiskoodina — tegi minu töö kaugelt mugavamaks ja meeldivamaks.
Tema piiramatud laienemisvõimalused: nii pistikprogrammide osas kui ka skaleeritavuse poolest — annavad teile võimaluse rakendada Airflow’d praktiliselt igas valdkonnas: olgu see siis andmete kogumise, töötlemise ja ettevalmistamise täislüka või rakettide käivitamine (Marsile, muidugi).
Lõpposa, viidatud ja informatiivne
Kühvlid, mis me teie eest kogusime
start_date. Jah, see on juba kohalike meemide teemade ring. Peamise dünaamika argumendi kaudustart_dateläbivad kõik. Lühidalt, kui määratastart_datepraegune kuupäev jaschedule_interval— üks päev, siis DAG käivitub homme mitte varem.start_date = datetime(2020, 7, 7, 0, 1, 2)Ja rohkem ei mingeid probleeme.
Sellega on seotud ka üks teine täitmisviga:
Task is missing the start_date parameter, mis enamasti tähendab, et unustasite seondada DAG operaatoriga.- Kõik ühel masinal. Jah, nii Airflow andmebaasid kui ka meie kattekiht, veebiserver, ajakavaja ja töötajad. Ja see töötas isegi. Kuid aja jooksul kasvas teenuste ülesannete arv ning kui PostgreSQL hakkas andma vastuse indeksi järgi 20 ms asemel 5 ms, siis me võtsime selle ja viibisime ära.
- LocalExecutor. Jah, me kasutame seda endiselt ja oleme jõudnud ääre poole. LocalExecutor on seni olnud piisav, kuid nüüd on aeg vähemalt ühe töötaja võrra laieneda ja tuleb pingutada, et üle minna CeleryExecutorile. Kuna sellega saab töötada ka ühel masinal, ei ole miski takistuseks kasutada Celery't isegi serveris, mis "loomulikult ei lähe kunagi tootmisse, ausõna!"
- Kasutamata sisseehitatud tööriistu:
- Ühendused teenuste autentimisandmete salvestamiseks,
- SLA puudumised ülesannete jaoks, mis ei töötanud õigel ajal,
- XCom metaandmete vahetamiseks (ma ütlesin metaandmed!) ülesannete vahel DAG'is.
- E-kirjade liialdamine. Mis siin muud öelda? Oleme seadnud hoiatused kõigi ebaõnnestunud ülesannete korduste kohta. Nüüd on mu töö Gmailis >90k kirja Airflow'ilt ja e-kirjade veebirakendus keeldub võtma ja kustutama rohkem kui 100 korraga.
Rohkem takistusi:
Veel suurema automatiseerimise vahendid
Kuna soovime veelgi rohkem mõtlema hakata, mitte kätega töötada, on Airflow meie jaoks valmistanud järgmise:
- — ta jätkuvalt omab Ekspressi staatust, mis ei takista selle tööleminekut. Selle abil on võimalus mitte ainult saada teavet DAGide ja ülesannete kohta, vaid ka peatada/algatada DAGi, luua DAGi jooksu või hulki.
- — käsurealt on kergesti kättesaadavad paljud tööriistad, mis ei ole mitte ainult ebamugavad WebUI's, vaid ei ole seal üldse saadaval. Näiteks:
backfillon vajalik ülesannete instantside uuesti käivitamiseks.
Näiteks kui analüütikud tulevad ja ütlevad: «Teie andmeanalüüs on halb ja vajab parandamist 1. kuni 13. jaanuarini! Parandage, parandage, parandage, parandage!» Siis võtad ja teed:airflow backfill -s '2020-01-01' -e '2020-01-13' orders- Andmebaasi hooldus:
initdb,resetdb,upgradedb,checkdb. run, mis võimaldab käivitada ühe ülesande instantsi, jättes kõik sõltuvused tähelepanuta. Veelgi enam, seda on võimalik käivitada läbiLocalExecutor, isegi kui teil on Celery-klaster.- Umbes sama asja teeb
test, ainult et ei kirjuta midagi andmebaasi. connectionsvõimaldab massiliselt luua ühendusi shell'ist.
- — üsna hardcore viis suhtlemiseks, mis on mõeldud pistikprogrammide jaoks, mitte käsitsi tööks. Aga kes meid küll takistab minemast
/home/airflow/dags, käivitadaipythonja hakkama saama? Näiteks on võimalik kõik ühendused eksportida sellise koodiga:from airflow import settings from airflow.models import Connection fields = 'conn_id conn_type host port schema login password extra'.split() session = settings.Session() for conn in session.query(Connection).order_by(Connection.conn_id): d = {field: getattr(conn, field) for field in fields} print(conn.conn_id, '=', d) - Airflow'i metaandmebaasiga ühendamine. Soovitan sinna kirjutada mitte, kuid erinevate spetsiifiliste mõõdikute jaoks ülesannete olekute kätte saamine on kindlasti kiirem ja lihtsam kui läbi ükskõik millise API.
Ütleme, et kõik meie ülesanded ei ole idempotentsed, ja need võivad mõnikord ebaõnnestuda, ja see on normaalne. Kuid mitu kokkuvarisemist on juba kahtlane ning tuleks kontrollida.
Ole ettevaatlik, SQL!
WITH last_executions AS ( SELECT task_id, dag_id, execution_date, state, row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) AS rn FROM public.task_instance WHERE execution_date > now() - INTERVAL '2' DAY ), failed AS ( SELECT task_id, dag_id, execution_date, state, CASE WHEN rn = row_number() OVER ( PARTITION BY task_id, dag_id ORDER BY execution_date DESC) THEN TRUE END AS last_fail_seq FROM last_executions WHERE state IN ('failed', 'up_for_retry') ) SELECT task_id, dag_id, count(last_fail_seq) AS unsuccessful, count(CASE WHEN last_fail_seq AND state = 'failed' THEN 1 END) AS failed, count(CASE WHEN last_fail_seq AND state = 'up_for_retry' THEN 1 END) AS up_for_retry FROM failed GROUP BY task_id, dag_id HAVING count(last_fail_seq) > 0
Lingid
Ja ja, ja esiteks kümme linki Google'i otsingust, mis viivad minu Airflow kaustade sisule.
- — muidugi tuleks alustada ametlikust dokumentatsioonist, aga kes neid juhiseid ikka loeb?
- — vähemalt loo autorite soovitusi loe.
- — esialgne tutvustus: kasutajaliides piltidena
- — peamised mõisted on hästi kirjeldatud, juhul kui (äkki!) sa ei saanud minust kõigest aru.
- — lühike juhend Airflow-kliendi seadistamiseks.
- — peaaegu sama huvitav artikel, ainult et ametlikumat juttu on rohkem ja näiteid vähem.
- — koostööst Celeryga.
- — idempotentsuse, ülesannete laadimise ID järgi mitte kuupäeva, transformatsioonide, failistruktuuri ja muu huvitava kohta.
- — ülesannete sõltuvused ja Trigger Rule, millest ma ainult märkisin.
- — kuidas ületada teatud «see töötab nagu kavandatud» planeerija puhul, laadida kadunud andmeid ja seada ülesannete prioriteedid.
- — kasulikud SQL-päringud Airflow'i metaandmetele.
- — on kasulik jaotis kohandatud sensori loomisest.
- — huvitav lühike märkus AWS-i andmeteaduse infrastruktuuri rajamisest.
- — levinud vead (kui keegi siiski ei loe juhiseid).
- — naeratage, kuidas inimesed paroolide salvestamist teevad, kuigi saaks lihtsalt kasutada Connections.
- — DAG-i vaikimisi edastamine, konteksti edastamine funktsioonides, taas sõltuvustest, samuti tööde käivituste vahelejätmisest.
- — kasutamise kohta
vaikimisi argumendidjaparamsšabloonides, samuti Variables ja Connections. - — jutustus sellest, kuidas ajakava Airflow 2.0-ks ette valmistatakse.
- — veidi aegunud artikkel meie klastrite kasutuselevõtust
docker-compose. - — dünaamilised ülesanded šabloonide ja konteksti edastamise abil.
- — standardsete ja kohandatud teavitustega e-posti ja Slacki kaudu.
- — Ülesannete harud, makrod ja XCom.
Ja lingid, mis on artiklis kasutusel:
- — šablonites kasutamiseks saadaval olevad kohtade hoidjad.
- — Levinud vead dagide loomisel.
- —
docker-composeeksperimentideks, silumiseks ja muuks. - — Python-mähis Telegram REST API jaoks.
Allikas: habr.com
