

Nota. trad.: Siamo lieti di condividere la traduzione di materiale meraviglioso del Senior Technology Evangelist di AWS - Adrian Hornsby. In termini semplici, spiega l’importanza della sperimentazione per mitigare gli effetti dei guasti nei sistemi IT. Probabilmente hai già sentito parlare di Chaos Monkey (o hai utilizzato soluzioni simili)? Oggi, gli approcci alla creazione di tali strumenti e alla loro implementazione in un contesto più ampio vengono condotti nell’ambito di un’attività chiamata ingegneria del caos. Maggiori informazioni in questo articolo.

“Ma dietro tutta questa bellezza si celano caos e follia.” —Tanner Walling
I vigili del fuoco. Questi professionisti altamente qualificati rischiano la vita ogni giorno combattendo gli incendi. Sapevi che devi trascorrere almeno 600 ore di formazione prima di diventare un vigile del fuoco? E questo è solo l'inizio. Secondo i rapporti, i vigili del fuoco si addestrano fino all'80% del loro tempo di lavoro.
Perché?
Quando un vigile del fuoco deve combattere un vero incendio, ha bisogno dell'attrezzatura adeguata intuizione. Per svilupparlo bisogna allenarsi ora dopo ora, giorno dopo giorno. Come si suol dire, la pratica fa miracoli.
“Sembrano penetrare nell'essenza stessa del fuoco; un po' come il Dr. Phil per le fiamme." —
Nota. trad.: Phillip Calvin "Phil" McGraw è uno psicologo, scrittore e conduttore americano del popolare programma televisivo Dr. Phil, in cui il conduttore offre ai suoi partecipanti soluzioni ai loro problemi.
C'era una volta a Seattle
All'inizio degli anni 2000 , che ha ricoperto un incarico presso Amazon con il titolo ufficiale Maestro del disastro, ha creato e guidato il programma GameDay. Si basava sulla sua esperienza come pompiere. GameDay aveva lo scopo di testare, formare e preparare i vari sistemi, software e persone di Amazon per potenziali situazioni di crisi.
Proprio come i vigili del fuoco sviluppano l'intuito per combattere gli incendi, Jesse voleva aiutare la sua squadra a sviluppare l'intuito per affrontare eventi catastrofici su larga scala.

"GameDay: Creare resilienza attraverso la distruzione" - Jesse Robbins
è stato progettato per aumentare la stabilità del sito di vendita al dettaglio di Amazon introducendo deliberatamente errori nei sistemi critici.
Il GameDay è iniziato con una serie di annunci all'intera azienda che era prevista un'esercitazione, a volte su larga scala, ad esempio, per chiudere un intero data center. Sono stati forniti dettagli minimi sull'interruzione pianificata e al team sono stati concessi diversi mesi per prepararsi. Lo scopo principale dell’esercitazione era verificare se il personale fosse in grado di far fronte a una crisi locale e risolverne rapidamente le conseguenze.
Durante queste esercitazioni sono stati utilizzati strumenti e processi specifici, come monitoraggio, avvisi e chiamate urgenti, per analizzare e identificare errori nelle procedure di risposta agli incidenti. A quanto pare, GameDay è bravissimo nell'identificare i classici problemi architettonici. A volte è stato possibile rilevare anche i cosiddetti "difetti latenti", problemi che si manifestano a causa delle specificità dell'incidente. Ad esempio, i sistemi di gestione degli incidenti fondamentali per il processo di ripristino hanno fallito a causa di effetti collaterali imprevisti causati da un problema causato dall’uomo.
Con la crescita dell'azienda, il raggio di esplosione teorico di GameDay si è ampliato. Alla fine, questi esercizi furono abbandonati perché il danno potenziale per l'azienda se le cose non fossero andate secondo i piani era diventato troppo grande. Da allora, il programma è degenerato in una serie di esperimenti disparati e senza impatto aziendale per formare il personale in situazioni di crisi. Non entrerò nei dettagli degli esperimenti in questo articolo, ma lo farò in futuro. Questa volta voglio discutere un'idea importante alla base di GameDay: l'ingegneria dell'affidabilità (ingegneria della resilienza), conosciuta anche come ingegneria del caos ().
L'ascesa delle scimmie
Probabilmente hai sentito parlare di Netflix, un fornitore di contenuti video online. Netflix ha iniziato a passare dal proprio data center al cloud AWS nell'agosto 2008. La mossa è stata provocata da una grave corruzione del database che ha ritardato le spedizioni di DVD di tre giorni (sì, Netflix ha iniziato a inviare film tramite posta ordinaria). La migrazione al cloud è stata guidata dalla necessità di gestire carichi di streaming molto più elevati, nonché dal desiderio di abbandonare un'architettura monolitica e orientarsi verso microservizi facilmente scalabili in base al numero di utenti e alle dimensioni del team di ingegneri. Il lato consumer del servizio di streaming è passato prima ad AWS, tra il 2010 e il 2011, seguito dall’IT aziendale e da tutte le altre strutture. Il data center di Netflix è stato chiuso nel 2016. L'azienda misura la disponibilità come rapporto tra il numero di tentativi riusciti di lanciare un film rispetto al numero totale, piuttosto che come un semplice confronto tra tempi di attività e tempi di inattività, e si sforza di raggiungere una cifra di 0,9999 in ciascuna regione su base trimestrale (è spesso ci riesce). L'architettura globale di Netflix si estende su tre regioni AWS. Pertanto, se sorgono problemi in una delle regioni, l'azienda ha la capacità di reindirizzare gli utenti ad altre.
Ripeto una delle mie citazioni preferite:
“Le interruzioni sono inevitabili; alla fine qualsiasi sistema crollerà nel tempo. —Werner Vogels
Infatti, i guasti nei sistemi distribuiti, soprattutto quelli su larga scala, sono inevitabili, anche nel cloud. Tuttavia, il cloud AWS e le sue primitive di ridondanza, in particolare , su cui è costruito, consente a chiunque di progettare servizi altamente affidabili.
Utilizzando principi di ridondanza (ridondanza) e graduale declino della funzionalità (degradazione aggraziata)Netflix senza influenzare gli utenti finali.
Fin dall'inizio, Netflix ha aderito ai più severi principi architettonici. Una delle prime applicazioni distribuite su AWS è stata la loro — per supportare i microservizi stateless con scalabilità automatica. In altre parole, qualsiasi istanza può essere arrestata e sostituita automaticamente senza alcuna perdita di stato. Chaos Monkey si assicura che nessuno violi questo principio.
Nota. trad.: A proposito, per Kubernetes esiste un analogo chiamato , il cui sviluppo sembra essersi interrotto nel marzo di quest'anno.
Netflix ha un'altra regola che distribuisce ciascun servizio in tre zone di disponibilità. Dovrebbe continuare a funzionare se solo due di essi sono disponibili. Per garantire che questa regola venga rispettata, disabilita le zone di disponibilità. Su scala più globale è in grado di chiudere un'intera regione AWS per confermare che tutti gli utenti Netflix possono essere serviti da una qualsiasi delle tre regioni. E durante la produzione eseguono questi test approfonditi ogni poche settimane per assicurarsi che nulla sia sfuggito di mano.
Infine, Netflix si è sviluppato anche in modo più mirato per aiutare a identificare i problemi con i microservizi e l'architettura di archiviazione. Puoi approfondire queste tecniche nel libro Chaos Engineering, che consiglio a chiunque sia interessato a questo argomento.
“Conducendo regolarmente esperimenti che simulano interruzioni regionali, siamo stati in grado di identificare tempestivamente varie carenze del sistema e correggerle”. —
Oggi i principi dell'ingegneria del caos ; viene loro data la seguente definizione:
“L’ingegneria del caos è un approccio che prevede la conduzione di esperimenti su un sistema di produzione per garantirne la capacità di resistere ai vari disturbi che si verificano durante il funzionamento”. —
Tuttavia, nel suo dedicato all'ingegneria del caos, , l'ex creatore dell'architettura cloud di Netflix che ha aiutato l'azienda a passare a un'infrastruttura interamente cloud, ha presentato una definizione alternativa di ingegneria del caos. Secondo me è più preciso e accertato:
"L'ingegneria del caos è un esperimento progettato per mitigare gli effetti del fallimento."
In effetti, sappiamo che i fallimenti accadono continuamente. Se adeguatamente affrontati, non dovrebbero avere alcun impatto sugli utenti finali. L’obiettivo principale dell’ingegneria del caos è scoprire problemi che non vengono affrontati correttamente.
Condizioni necessarie per creare il caos
Prima di iniziare l’ingegneria del caos, assicurati di aver svolto tutto il lavoro necessario per garantire la sostenibilità a tutti i livelli dell’organizzazione. La creazione di sistemi tolleranti agli errori non riguarda solo il software. Si inizia a livello infrastruttura, si diffonde rete e dati, influisce sulla struttura applicazioni, e alla fine copre persone e cultura. Ho scritto ampiamente in passato sui modelli di resilienza e sui fallimenti (, , и ) e non mi soffermerò su questo adesso, ma non posso fare a meno di un piccolo promemoria.
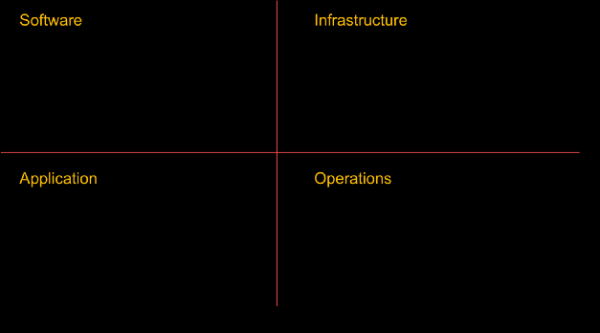
Alcuni elementi necessari prima di introdurre il caos nel sistema (l'elenco non è esaustivo)
Fasi dell'ingegneria del caos
È importante comprendere l'essenza dell'ingegneria del caos NON è liberare le scimmie in libertà e lasciare che distruggano tutto, senza alcuno scopo. Lo scopo di questa disciplina è interrompere alcuni elementi di un sistema in un ambiente controllato attraverso esperimenti ben progettati per vedere se la tua applicazione può resistere a condizioni turbolente.
Per fare ciò, è necessario seguire un processo chiaramente definito e formalizzato delineato nella figura seguente. Può aiutarti a passare dalla comprensione dello stato stazionario del tuo sistema alla formulazione di un'ipotesi, alla sua verifica e infine all'analisi dell'esperienza acquisita dall'esperimento e al miglioramento della stabilità del sistema stesso.
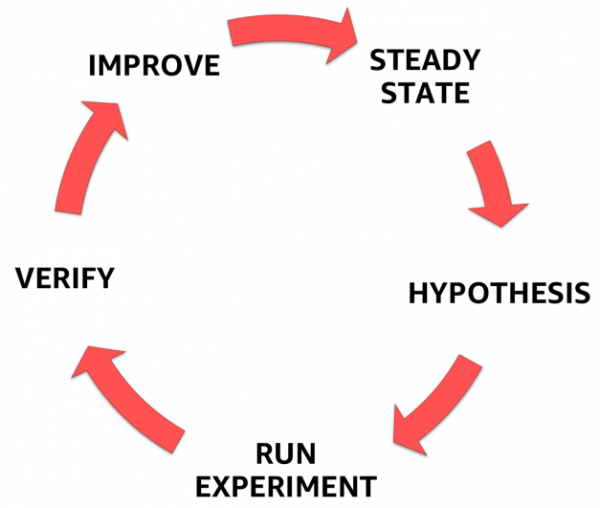
Fasi dell'ingegneria del caos
1. Stato stabile
Uno degli elementi più importanti dell’ingegneria del caos è comprendere il comportamento del sistema in condizioni normali.
Perché? È semplice: dopo aver introdotto un guasto artificiale, è necessario assicurarsi che il sistema sia tornato a uno stato stabile ben studiato e che l'esperimento non interferisca più con il suo comportamento normale.
La chiave qui è concentrarsi non sugli attributi interni del sistema (processore, memoria, ecc.) ma su risultati misurabili che collegano le prestazioni all’esperienza dell’utente. Affinché questi output siano in uno stato stabile, il comportamento osservato del sistema deve avere uno schema prevedibile, ma cambiare in modo significativo quando si verifica un guasto nel sistema.
Tenere a mente , proposto sopra da Adrian Cockcroft, questo stato stabile cambia quando un problema tecnico fuori controllo causa un problema inaspettato e segnala che l'esperimento del caos dovrebbe essere interrotto.
Come esempio di stati stabili, prendiamo l'esperienza di Amazon. L’azienda utilizza il volume degli ordini come uno dei suoi parametri di stato stazionario, e per una buona ragione. Nel 2007, Greg Linden, ex Amazon, ha descritto un esperimento utilizzando il metodo Ho provato a rallentare il tempo di caricamento delle pagine del sito web con incrementi di 100 ms e ho scoperto che anche i ritardi più piccoli portano a un grave calo delle entrate. Con un aumento del tempo di caricamento di 100 ms, il numero di ordini (e quindi di vendite) è diminuito dell'1%. Questo è il motivo per cui il numero di ordini è un eccellente candidato per i parametri di stato stazionario.
Netflix utilizza una metrica lato server associata all'inizio della riproduzione: il numero di clic sul pulsante "Riproduci". Hanno notato uno schema nel comportamento dell'indicatore SPS (avvii al secondo) e le sue fluttuazioni significative quando si verificavano guasti al sistema. La metrica si chiama “Netflix's Pulse” ().
I numeri degli ordini di Amazon e Pulse di Netflix sono eccellenti barometri dello stato stazionario perché combinano l'esperienza dell'utente e i parametri operativi in un unico parametro, misurabile e altamente prevedibile.
Misurare, misurare e misurare ancora
Inutile dire che se non riesci ad acquisire correttamente i parametri del sistema, non sarai in grado di monitorare (o addirittura rilevare) i cambiamenti nello stato stazionario. Prestare particolare attenzione alla lettura di tutti i parametri/indicatori, dalla rete, all'hardware, all'applicazione e alle persone. Disegna grafici di queste misurazioni, anche se non cambiano nel tempo. Sarai sorpreso di scoprire correlazioni che non sapevi esistessero.
"Rendere il più semplice possibile per gli ingegneri l'accesso ai dati che possono calcolare o rappresentare graficamente." —
2. Ipotesi
Dopo aver affrontato lo stato stabile, puoi procedere alla formulazione di un'ipotesi.

- Cosa succede se il motore dei suggerimenti si ferma?
- Cosa succede se il sistema di bilanciamento del carico si interrompe?
- Cosa succede se la memorizzazione nella cache fallisce?
- Cosa succede se la latenza aumenta di 300 ms?
- Cosa succede se il database principale si blocca?
Naturalmente dovreste scegliere solo un’ipotesi e non complicarla inutilmente. Inizia in piccolo. Mi piace partire dall’ipotesi personale. Ne hai sentito parlare? fattore autobus ()? Il fattore bus è una misura del rischio associato alla distribuzione non uniforme della conoscenza tra i membri del team. Ti consente di calcolare il numero minimo dei suoi partecipanti, dopo la perdita improvvisa del quale il progetto si fermerà per mancanza di conoscenza o esperienza.
Molte aziende hanno esperti tecnici la cui improvvisa scomparsa (“essere investiti da un autobus”) avrebbe un impatto devastante sia sul progetto che sul team. Identifica queste persone e conduci su di loro esperimenti caotici: ad esempio, porta via i loro computer e mandali a casa per la giornata, quindi osserva i risultati (spesso caotici).
Rendi il problema comune a tutti!
Attirare tutta la squadra per sviluppare un'ipotesi. Lascia che tutti partecipino al brainstorming: proprietario del prodotto, responsabile tecnico, sviluppatori backend e frontend, designer, architetti, ecc. Chiunque sia in un modo o nell'altro connesso al prodotto.
Per prima cosa, chiedi a ognuno di scrivere la propria risposta alla domanda “E se...?” su un pezzo di carta. Vedrai che nella maggior parte dei casi ognuno avrà una risposta diversa e ti renderai conto che alcuni membri del team non hanno pensato affatto a questo problema fino ad ora.
A questo punto fai una pausa e discuti il motivo per cui i membri del team hanno idee diverse su come si comporterà il prodotto in una domanda "E se...?" Torna alle sue specifiche e assicurati che tutti abbiano una buona idea di cosa accadrà dopo.
Prendiamo, ad esempio, il già citato sito di vendita al dettaglio Amazon. Cosa succede se Acquista per categoria interrompe il caricamento sulla home page?
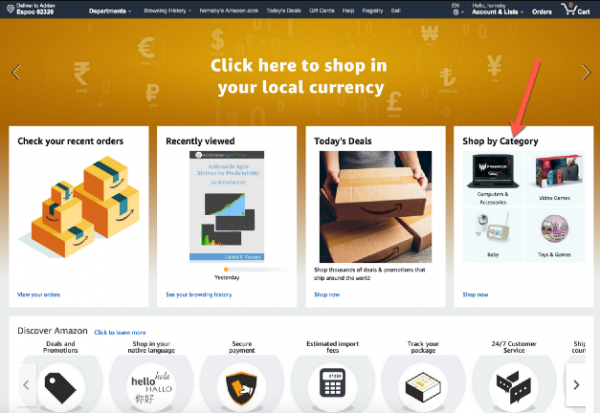
Dovrei restituire un errore 404? Vale la pena caricare la pagina lasciando uno spazio vuoto come nello screenshot qui sotto?
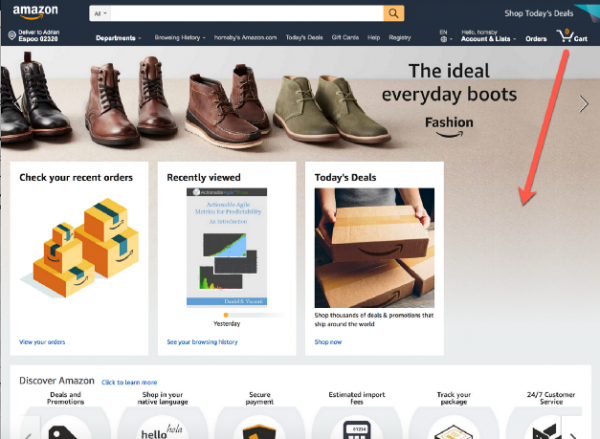
Vale la pena sacrificare alcune funzionalità e, ad esempio, consentire alla pagina di espandersi e nascondere l'errore?
E questo è solo dal punto di vista dell'interfaccia utente. Cosa dovrebbe succedere nel backend? È opportuno inviare avvisi? Il servizio in errore dovrebbe continuare a ricevere richieste ogni volta che l'utente carica la home page o il backend dovrebbe interromperlo completamente?
E un'ultima cosa. Per favore, non formulare un'ipotesi che sai in anticipo causerà problemi! Sperimenta parti del sistema che ritieni stabili: dopo tutto, questo è il punto centrale della sperimentazione.
3. Progetta e conduci un esperimento
- Scegli un'ipotesi;
- Definire l'ambito dell'esperimento;
- Identificare i relativi indicatori che verranno misurati;
- Avvisare l'organizzazione.
Oggi molte persone, così come il sito , promuovere l'idea dell'ingegneria del caos nella produzione. Anche se questo dovrebbe essere l'obiettivo finale, la maggior parte delle organizzazioni è intimidita da questo approccio, quindi non è un buon punto di partenza.
Per me, l’ingegneria del caos non significa solo la distruzione di vari elementi dei sistemi di produzione. Questo è un viaggio. Un viaggio nel mondo della conoscenza, indissolubilmente legato a un'attività come la distruzione di sistemi in un ambiente controllato: qualsiasi ambiente, sia esso un ambiente di sviluppo locale, beta, staging o prod. Interrompi attraverso esperimenti ben progettati per creare fiducia nella capacità della tua applicazione di resistere a condizioni turbolente. "Costruire la fiducia" è un punto chiave perché è un precursore dei cambiamenti culturali necessari per implementare con successo pratiche di ingegneria del caos e affidabilità nella vostra azienda.
Onestamente, la maggior parte dei team impara molto rompendo le cose, anche in un ambiente non di produzione. Prova e basta docker stop database nel tuo ambiente locale e vedi se riesci a gestire questo problema senza conseguenze. C'è un'alta probabilità che non lo faccia.
Arresto di un database - Esempio
Inizia in piccolo e costruisci gradualmente la fiducia all’interno del tuo team e della tua organizzazione. Le persone ti diranno che “il traffico di produzione reale è l’unico modo per acquisire in modo affidabile il comportamento del sistema”. Ascolta, sorridi e continua lentamente a fare quello che stai facendo. La cosa peggiore che puoi fare è applicare l’ingegneria del caos alla produzione e fallire miseramente. Dopodiché nessuno si fiderà di te e sarai costretto a dimenticare per sempre le "scimmie del caos".
Innanzitutto, guadagna la fiducia. Mostra all'organizzazione e ai tuoi colleghi che sai cosa stai facendo. Diventa un vigile del fuoco e impara il più possibile sulle fiamme prima di passare all'addestramento sul fuoco dal vivo. Guadagna la tua credibilità. Ricordare la storia della tartaruga e della lepre? Lento e paziente vince sempre la gara.
Uno dei punti più importanti durante un esperimento è comprenderne il potenziale raggio del danno dal fallimento che introduci e dalla sua minimizzazione. Poniti le seguenti domande:
- Quanti clienti saranno interessati dall'esperimento?
- Quali funzionalità saranno interessate?
- Quali luoghi saranno interessati?
Pensa a un "pulsante di interruzione" o a un modo per interrompere immediatamente l'esperimento e tornare a uno stato stabile il più rapidamente possibile. Mi piace condurre esperimenti usando il cosiddetto. implementazioni “canarie”. Questa tecnica consente di ridurre il rischio di fallimento quando si lanciano nuove versioni di un'applicazione in produzione distribuendo gradualmente le modifiche a un piccolo sottoinsieme di utenti e poi propagandole lentamente all'intera infrastruttura e a tutti gli utenti. Adoro i rollout dei canarini semplicemente perché soddisfano il principio , e l'esperimento stesso è abbastanza facile da interrompere.
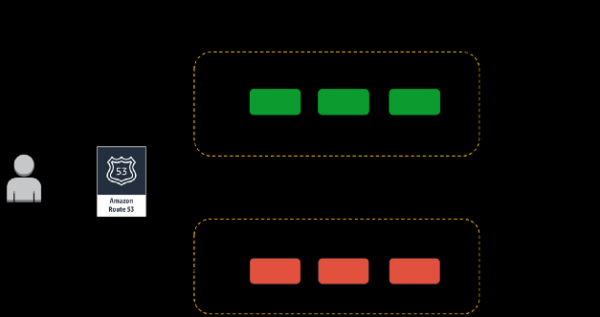
Esempio di implementazione canary basata su DNS per esperimenti sul caos
Fare attenzione agli esperimenti che modificano lo stato dell'applicazione (cache o database) o a quelli di cui non è possibile eseguire il rollback (facilmente o affatto).
È interessante notare che Adrian Cockcroft mi ha detto che uno dei motivi per cui Netflix ha iniziato a utilizzare i database NoSQL è perché non avevano uno schema per modifiche o rollback, quindi era molto più semplice aggiornare o correggere in modo incrementale i singoli record di dati (ovvero erano più adatti all'ingegneria del caos) .
4. Osserva e impara
Per imparare qualcosa di nuovo e monitorare l'avanzamento di un esperimento, devi essere in grado di monitorare le prestazioni del sistema. Come accennato in precedenza, presta la massima attenzione a tutti i tipi di metriche e parametri! Poi quantifica i risultati e sempre – sempre! — annotare il tempo prima che compaiano i primi segni di un problema. È successo molte volte nella mia storia che i sistemi di allarme abbiano fallito e che i clienti abbiano twittato prima il problema... fidati di me, non vorrai finire in quella situazione, quindi usa gli esperimenti del caos per testare i tuoi sistemi di monitoraggio e allarme come BENE.
- Tempo fino al rilevamento?
- Tempo prima della notifica e dell'inizio delle azioni attive?
- Tempo fino all'avviso pubblico?
- Tempo fino alla perdita parziale della funzionalità?
- Quanto dura il periodo di autoguarigione?
- Tempo fino al recupero totale o parziale?
- C'è tempo fino alla fine della crisi e al ritorno a uno stato stabile?
Ricordare che non esiste un'unica causa isolata di guasto. Gli incidenti gravi sono sempre il risultato di diversi piccoli fallimenti che si accumulano e portano a una crisi su larga scala.
Conduci un'analisi post-mortem dettagliata di ciascun esperimento!
In AWS, attribuiamo grande importanza all'analisi dei guasti rilevati e alla comprensione delle cause che li hanno causati, in modo da poter prevenire problemi simili in futuro. Tutte le conclusioni e i risultati dell'esperimento sono riassunti in un documento chiamato Correzione degli errori (COE). Il COE ci consente di imparare dai nostri errori, siano essi difetti nella tecnologia, nei processi o persino nell'organizzazione. Utilizziamo questo meccanismo per eliminare le cause alla base dei guasti e migliorare continuamente.
La chiave del successo in questo processo è l’apertura e la trasparenza su ciò che è andato storto. Uno dei principi più importanti nello scrivere un buon COE è essere imparziali ed evitare di menzionare persone specifiche. Ciò è spesso difficile in un ambiente che scoraggia tale comportamento e non ammette la possibilità di fallimento. Amazon utilizza una raccolta di "principi di leadership" () per incoraggiare tale comportamento - ad es. autocritica, approccio analitico, impegno per gli standard più elevati e responsabilità sono componenti chiave del processo COE e dell’eccellenza operativa in generale.
Il rapporto COE è composto da cinque sezioni principali:
- Cosa è successo (ordine cronologico)?
- Qual è stato l’impatto sui clienti?
- Perché si è verificato l'errore? ()
- Cosa abbiamo imparato?
- Come prevenire questo in futuro?
È più difficile rispondere a queste domande di quanto sembri a prima vista, poiché è necessario assicurarsi che ogni punto poco chiaro/sconosciuto sia studiato attentamente.
Per trasformare il meccanismo COE in un processo a tutti gli effetti, conduciamo costantemente revisioni sotto forma di riunioni settimanali con analisi obbligatorie dei parametri operativi. Inoltre, i responsabili tecnici conducono revisioni settimanali dei parametri con l'intero staff AWS.
5. Correggi e migliora!
La lezione principale qui è risolvere prima i problemi identificati durante gli esperimenti sul caos, dando loro una priorità più alta rispetto allo sviluppo di nuove funzionalità. Coinvolgere il senior management in questo processo e instillare in loro l'idea che risolvere i problemi attuali è più importante che sviluppare nuove funzionalità.
Una volta ho aiutato un cliente a identificare problemi critici di stabilità utilizzando un esperimento del caos, ma a causa della pressione del team di vendita, le correzioni hanno perso la priorità e tutti gli sforzi si sono concentrati sull'introduzione di una nuova cosa che era "di fondamentale importanza" per i clienti. Due settimane dopo, un tempo di inattività di 16 ore ha costretto l'azienda ad affrontare gli stessi problemi identificati durante l'esperimento del caos. Solo le perdite si sono rivelate molto più elevate.
Vantaggi dell'ingegneria del caos
Ci sono molti vantaggi. Ne evidenzio due, a mio avviso, i più importanti:
In primo luogo, l’ingegneria del caos aiuta a scoprire problemi sconosciuti in un sistema e a risolverli prima che causino un arresto anomalo della produzione, ad esempio alle 3 del mattino di domenica. Cioè, lui aumenta la resistenza ai fallimenti e, di fatto, la qualità del sonno.
In secondo luogo, gli esperimenti di caos condotti in modo efficace causano sempre cambiamenti più estesi (soprattutto culturali) del previsto. Forse il più importante di questi è la naturale evoluzione verso "innocente" (senza colpa) cultura, quando la domanda "Perché l'hai fatto?" diventa “Come possiamo evitarlo in futuro?” Il risultato è un team più felice, più efficiente, più impegnato e di maggior successo. Ed è bellissimo!
Questo conclude la prima parte. Spero che ti sia piaciuto. Per favore scrivi recensioni, condividi opinioni o semplicemente batti le mani . Nella parte successiva esaminerò gli strumenti e le tecniche per introdurre errori nei sistemi. Fino a!
Per coloro che sono ansiosi di leggere la seconda parte, offro il mio intervento sul tema dell'ingegneria del caos all'NDC di Oslo. In esso parlo di molti dei miei strumenti preferiti:

PS da traduttore
La seconda parte dell'articolo in inglese e lo tradurremo anche se vediamo un sufficiente interesse da parte dei lettori di Habr per questo materiale: commenti appropriati sull'articolo sono benvenuti!
Leggi anche sul nostro blog:
- «";
- «";
- «'.
Fonte: habr.com
