

Data Science për fillestarët
1. Analiza e Ndjenjave (Analiza e ndjenjave përmes tekstit)

Shikoni implementimin e plotë të projektit Data Science me përdorimin e kodit burim — .
Analiza e Ndjenjave është analiza e fjalëve për të përcaktuar ndjenjat dhe opinionet, të cilat mund të jenë pozitive ose negative. Ky është një tip klasifikimi, ku klasat mund të jenë binar (pozitive dhe negative) ose multipel (të lumtur, të zemëruar, të trishtuar, të pakëndshëm …). Ne do ta realizojmë këtë projekt Data Science në gjuhën R dhe do të përdorim një grup të dhënash nga paketa 'janeaustenR'. Do të përdorim fjalorë të përgjithshëm, si AFINN, bing dhe loughran, do të kryejmë bashkimin e brendshëm, dhe në fund do të krijojmë një re fjalësh për të ilustruar rezultatin.
Gjuha: R
Grupi i të dhënave/Paketa: janeaustenR
Artikulli është përkthyer me mbështetje nga kompania EDISON Software, e cila , si dhe .
2. Zbulimi i Fake News (Zbulimi i lajmeve false)
Ç elevoni aftësitë tuaja në një nivel të ri duke punuar në një projekt për Data Science për fillestarët — .
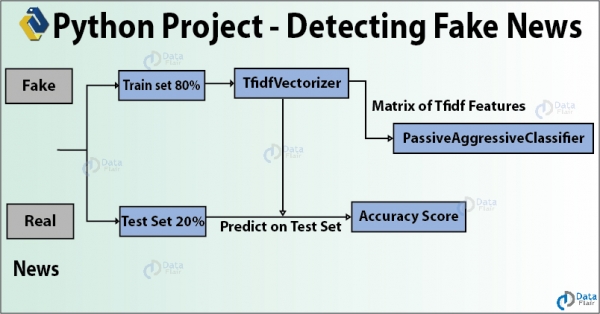
Lajmet e rreme janë informacion i rremë që përhapet përmes mediave sociale dhe burimeve të tjera për arritjen e qëllimeve politike. Në këtë ide projekti për Data Science, ne do të përdorim Python për të ndërtuar një model që mund të përcaktojë saktësisht nëse një lajm është i vërtetë apo i rremë. Ne do të krijojmë TfidfVectorizer dhe do të përdorim PassiveAggressiveClassifier për të klasifikuar lajmet si "të vërteta" ose "të rreme". Ne do të përdorim një grup të dhënash me formën 7796 × 4 dhe do të realizojmë gjithçka në Jupyter Lab.
Gjuha: Python
Grupi i të dhënave/Paketa: news.csv
3. Identifikimi i Sëmundjes së Parkinsonit
Shkoni përpara duke punuar në idenë e projektit Data Science - .
Kemi filluar të përdorim Shkencën e Të Dhënave për të përmirësuar shëndetësinë dhe shërbimet — nëse mund të parashikojmë sëmundjen në fazat e para, do të kemi shumë përfitime. Prandaj, në këtë ide projekti për Shkencën e Të Dhënave do të mësojmë si të identifikojmë sëmundjen e Parkinsonit duke përdorur Python. Kjo është një sëmundje neurodegjenerative, progresive e sistemit nervor qendror, e cila ndikon në lëvizje dhe shkakton dridhje dhe ngurtësi. Ajo ndikon te neuronet që prodhojnë dopaminë në tru, dhe çdo vit, ajo prek më shumë se 1 milion njerëz në Indi.
Gjuha: Python
Grupi i të dhënave/Paketa: UCI ML Parkinsons dataset
Projekte të Shkencës së Të Dhënave me vështirësi të mesme
4. Njohja e Emocioneve në Fjalë (Speech Emotion Recognition)
Shikoni realizimin e plotë të shembujve të projekteve të Shkencës së Të Dhënave — .
Tani le të mësojmë të përdorim biblioteka të ndryshme. Ky projekt në Data Science përdor librosa për njohjen e zërit. SER—a është procesi i identifikimit të emocioneve njerëzore dhe gjendjeve affective përmes zërit. Duke qenë se ne përdorim tonin dhe lartësinë e tonit për të shprehur emocionet me zë, SER është në raund. Por, pasi emocionet janë subjektive, annotimi i tingujve është një detyrë e komplikuar. Ne do të përdorim funksionet mfcc, chroma dhe mel dhe do të përdorim setin e të dhënave RAVDESS për njohjen e emocioneve. Ne do të krijojmë një klasifikues MLPC për këtë model.
Gjuha: Python
Grupi i të dhënave/Paketa: RAVDESS dataset
5. Gender and Age Detection (Detektimi i Gjinisë dhe Moshës)
Merrni vëmendjen e punëdhënësve me projektin më të ri në Data Science — .
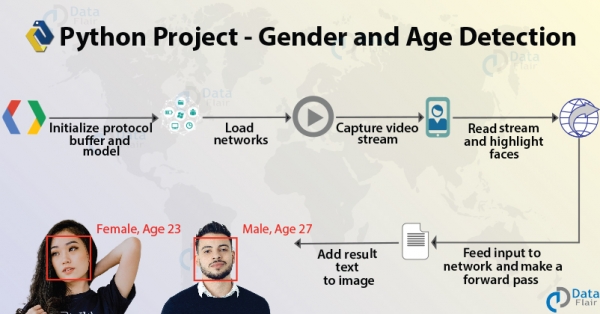
Ky është një projekt interesant Data Science me Python. Duke përdorur vetëm një imazh, do të mësoni të parashikoni gjininë dhe moshën e një personi. Në këtë projekt do t’ju prezantojmë me Computer Vision dhe principet e tij. Ne do të ndërtojmë dhe do të përdorim modelet e trajnuara nga Tal Hassner dhe Gil Levi për setin e të dhënave Adience. Gjatë rrugës do të përdorim disa skedarë .pb, .pbtxt, .prototxt dhe .caffemodel.
Gjuha: Python
Grupi i të dhënave/Paketa: Adience
6. Uber Data Analysis (Analiza e të Dhënave të Uberit)
Shikoni realizimin e plotë të projektit Data Science me kodin burimor — .
Ky është një projekt vizualizimi të dhënash me ggplot2, në të cilin do të përdorim R dhe bibliotekat e tij për të analizuar parametrat e ndryshëm. Do të përdorim setin e të dhënave Uber Pickups në New York dhe do të krijojmë vizualizime për periudha të ndryshme të vitit. Kjo na tregon se si koha ndikon në udhëtimet e klientëve.
Gjuha: R
Grupi i të dhënave/Paketa: Dataset-i Uber Pickups në qytetin e New York-ut
7. Zbulimi i dueriz si rezultat i lodhjes (Driver Drowsiness detection)
Përmirësoni aftësitë tuaja duke punuar në një projekt të lartë të Data Science — .
Të drejtuarit në gjumë është jashtëzakonisht e rrezikshme, dhe çdo vit ndodhin rreth një mijë aksidente për shkak se shoferët bien në gjumë gjatë drejtimit. Në këtë projekt në Python, ne do të krijojmë një sistem që mund të zbulojë shoferë të lodhur dhe t’i paralajmërojë ata me një sinjal akustik.
Ky projekt është realizuar duke përdorur Keras dhe OpenCV. Ne do të përdorim OpenCV për zbulimin e fytyrës dhe syve, dhe me Keras ne do të klasifikojmë gjendjen e syve (Të hapur ose Të mbyllur) duke përdorur metoda të rrjeteve nervore të thella.
8. Chatbot
Krijoni një chatbot me Python dhe bëni një hap përpara në karrierën tuaj — .

Chatbotët janë një pjesë e pandashme e biznesit. Shumë ndërmarrje duhet të ofrojnë shërbime për klientët e tyre, dhe për t’i shërbyer atyre kërkohet shumë punë, kohë dhe përpjekje. Chatbotët mund të automatizojnë një pjesë të madhe të ndërveprimit me klientët, duke u përgjigjur në disa pyetje të shpeshta që bëjnë klientët. Në thelb, ka dy lloje chatbot-ësh: Domain-specific dhe Open-domain. Chatbotët Domain-specific përdoren shpesh për të zgjidhur një problem të caktuar. Kështu, ju duhet ta përshtatni atë për të funksionuar në mënyrë efektive në sektorin tuaj. Chatbotët Open-domain mund t'u bëhen çdo pyetje, prandaj kërkojnë një masë të madhe të dhënash për t'u trajnuar.
Grupi i të dhënave: Skedari json për Intentet
Gjuha: Python
Projekte të avancuara të Shkencës së të Dhënave
9. Gjeneratori i përshkrimeve të imazheve
Kontrolloni realizimin e plotë të projektit me kodin burimor — .

Përshkrimi i asaj që është në imazh është një detyrë e lehtë për njerëzit, por për kompjuterët, imazhi është thjesht një grup numrash që përfaqësojnë vlerën e ngjyrës së secilit pixel. Kjo është një detyrë e vështirë për kompjuterët. Të kuptosh atë që ndodhet në imazh dhe pastaj të krijosh një përshkrim në një gjuhë natyrale (për shembull, anglisht) është një detyrë tjetër e vështirë. Ky projekt përdor metoda të mësimit të thellë, në të cilat ne implementojmë një Rrjet Neuronal Konvolucional (CNN) me një Rrjet Neuronal Rekurent (LSTM) për të krijuar një gjenerator përshkrimesh për imazhe.
Grupi i të dhënave: Flickr 8K
Gjuha: Python
Korniza: Keras
10. Zbulesa e Mashtrimit të Kartave të Kreditit
Bëni maksimumin duke punuar në idenë e projektit Data Science — .
Derisa të arrini këtë pikë, keni filluar të kuptoni metodat dhe konceptet. Le të kalojmë në disa projekte më të avancuara në fushën e shkencave të të dhënave. Në këtë projekt do të përdorim gjuhën R me algoritme të tillë si , regresioni logjistik, rrjetet nervore të artificiale dhe klasifikuesi i përmirësimit të gradientit. Ne do të përdorim një set të dhënash të transaksioneve me karta për të klasifikuar transaksionet e kartave të kreditit si mashtruese ose të vërteta. Ne do të zgjidhim modele të ndryshme dhe do të ndërtojmë kurba performancës.
Gjuha: R
Grupi i të dhënave/Paketa: Seti i të dhënave të Transaksioneve me Karta
11. Sistema i rekomandimeve për filma
Eksploroni realizimin e projektit më të mirë të Shkencës së të Dhënave me Kodin Burimor —
Në këtë projekt të Shkencës së të Dhënave, ne do të përdorim R për të realizuar rekomandimet për filma përmes mësimit të makinerive. Sistemi i rekomandimeve dërgon sugjerime përdoruesve përmes një procesi filtrimi, duke u bazuar në preferencat e përdoruesve të tjerë dhe historinë e shikimeve. Nëse A dhe B e pëlqejnë Home Alone, dhe B e do Mean Girls, mund t'i sugjerohet A — mund t'i pëlqejë edhe atij. Kjo lejon që klientët të ndërveprojnë me platformën.
Gjuha: R
Grupi i të dhënave/Paketa: Seti i të dhënave MovieLens
12. Segmente të klientëve
Bëni përshtypje të punëdhënësve me ndihmën e projektit të Shkencës së të Dhënave (duke përfshirë kodin burimor) — .
Segmentimi i blerësve është një aplikacion popullor . Duke përdorur grupimin, kompanitë përcaktojnë segmentet e klientëve për të punuar me një bazë të mundshme përdoruesish. Ato ndajnë klientët në grupe sipas karakteristikave të përbashkëta, siç janë gjinia, mosha, interesat dhe zakonet e shpenzimit, në mënyrë që të mund të shesin produktet e tyre në mënyrë efikase për çdo grup. Ne do të përdorim , si dhe të visualizojmë shpërndarjen sipas gjinisë dhe moshës. Më pas do të analizojmë të ardhurat e tyre vjetore dhe nivelin e shpenzimeve.
Gjuha: R
Grupi i të dhënave/Paketa: datasetin Mall_Customers
13. Klassifikimi i Kancerit të Gjirit
Shikoni realizimin e plotë të projektit të Shkencës së të Dhënave në Python — .

Duke u kthyer te kontributi mjekësor i shkencës së të dhënave, le të mësojmë të identifikojmë kancerin e gjirit duke përdorur Python. Ne do të përdorim setin e të dhënave IDC_regular për të identifikuar karcinomën invazive të kanaleve, lloji më i zakonshëm i kancerit të gjirit. Ai zhvillohet në kanalet e qumështit, duke depërtuar në indet fibrilare ose yndyrore të gjirit nga jashtë kanalit. Në këtë projekt shkencor të mbledhjes së të dhënave ne do të përdorim dhe bibliotekën Keras për klasifikim.
Gjuha: Python
Grupi i të dhënave/Paketa: IDC_regular
14. Traffic Signs Recognition (NJohja e Shenjave Rrugore)
Arritja e saktësisë në teknologjinë e drejtimit të automjeteve me projektin e shkencës së të dhënave për me kod të hapur.

Tabelat e trafikut dhe rregullat e qarkullimit janë shumë të rëndësishme për çdo shofer për të shmangur aksidentet. Për të respektuar rregullin, së pari duhet të kuptohet si duket një tabelë e trafikut. Njëri duhet të mësojë të gjitha tabelat e trafikut para se t'i jepet leja për të drejtuar ndonjë mjet. Por tani numri i mjeteve autonome është në rritje dhe në të ardhmen të ardhmen, njeriu nuk do të drejtojë më vetë makinën. Në projektin “Njohja e Tabelave të Trafikut” do të mësoni si programi mund të njohë llojin e tabelave të trafikut duke marrë imazhin si hyrje. Grupi i të dhënave për njohjen e tabelave të trafikut në Gjermani (GTSRB) përdoret për ndërtimin e një rrjeti nervor të thellë për të njohur klasën në të cilën përket tabela e trafikut. Ne gjithashtu po krijojmë një ndërfaqe grafike të thjeshtë për ndërveprimin me aplikacionin.
Gjuha: Python
Grupi i të dhënave: GTSRB (German Traffic Sign Recognition Benchmark)
Lexoni më shumë
Burimi: habr.com
