

Notera. transl.Vi är glada att kunna dela översättningen av ett fantastiskt material från Adrian Hornsby, Senior Technology Evangelist på AWS. Enkelt uttryckt förklarar han vikten av experiment utformade för att mildra konsekvenserna av fel i IT-system. Har du förmodligen redan hört talas om Chaos Monkey (eller ens använt liknande lösningar)? Idag genomförs metoder för att skapa sådana verktyg och deras implementering i ett bredare sammanhang inom ramen för en aktivitet som kallas chaos engineering. Läs mer om det i den här artikeln.

”Men bakom all denna skönhet döljer sig kaos och galenskap.” – Tanner Walling
BrandmänDessa välutbildade yrkesmän riskerar sina liv varje dag när de bekämpar bränder. Visste du att innan du kan bli brandman måste du utbilda dig i minst 600 timmar? Och det är bara början. Brandmän rapporteras utbilda sig upp till 80 % av sin tid på jobbet.
Varför?
När en brandman bekämpar en riktig brand behöver hen lämplig utrustning. intuitionFör att utveckla det måste man öva timme efter timme, dag efter dag. Som man brukar säga, övning ger färdighet.
"De tycks penetrera själva eldens väsen; likt lågans Dr. Phil."
Notera. transl.Phillip Calvin "Phil" McGraw är en amerikansk psykolog, författare och programledare för det populära tv-programmet Dr. Phil, där programledaren erbjuder sina deltagare lösningar på deras problem.
Det var en gång i Seattle
I början av 2000 -talet , som hade en position på Amazon med den officiella titeln Mästare i katastrofen, skapade och ledde GameDay-programmet. Det baserades på hans erfarenhet som brandman. GameDay utformades för att testa, utbilda och förbereda olika Amazon-system, programvara och personer för potentiella krissituationer.
Precis som brandmän utvecklar intuition för att bekämpa bränder, skulle Jesse hjälpa sitt team att utveckla intuition för att hantera storskaliga katastrofala händelser.

"GameDay: Skapa motståndskraft genom förstörelse" - Jesse Robbins
utformades för att förbättra motståndskraften hos Amazons detaljhandelssajt genom att avsiktligt introducera buggar i kritiska system.
GameDay började med en serie företagsomfattande tillkännagivanden om att en övning planerades – ibland en storskalig sådan, som att stänga ner ett helt datacenter. Detaljerna om det planerade avbrottet var minimala, och teamet fick flera månader på sig att förbereda sig. Huvudmålet med övningen var att testa om personalen kunde hantera en lokal kris och snabbt lösa dess konsekvenser.
Under dessa övningar användes specialverktyg och processer som övervakning, varningar och nödsamtal för att analysera och identifiera fel i incidenthanteringsprocedurer. Det visade sig att GameDay är mycket bra på att identifiera klassiska arkitekturproblem. Ibland var det också möjligt att hitta så kallade "dolda defekter" – problem som manifesterade sig på grund av incidentens detaljer. Till exempel misslyckades incidenthanteringssystem som var avgörande för återställningsprocessen på grund av oväntade biverkningar orsakade av ett konstgjort problem.
Allt eftersom företaget växte utökades GameDays teoretiska explosionsradie. Så småningom avbröts övningarna eftersom den potentiella skadan för företaget om saker och ting gick fel var för stor. Sedan dess har programmet urartat till en serie isolerade, icke-affärspåverkande experiment för att utbilda personal i krishantering. Jag kommer inte att gå in på detaljerna om experimenten i den här artikeln, men jag kommer att göra det i framtiden. Under tiden vill jag diskutera en viktig idé bakom GameDay: tillförlitlighetsteknik. (motståndskraftsteknik), även känd som kaosteknik ().
Apornas uppgång
Du har säkert hört talas om Netflix, leverantören av onlinevideoinnehåll. Netflix började flytta från sitt lokala datacenter till AWS Cloud i augusti 2008. Flytten föranleddes av en större databaskorruption som försenade DVD-leveranser med tre dagar (ja, Netflix började med att skicka filmer via vanlig post). Flytten till molnet drevs av behovet av att hantera mycket högre streamingbelastningar, samt en önskan att gå ifrån en monolitisk arkitektur och mot mikrotjänster som enkelt kunde skalas beroende på antalet användare och storleken på teknikteamet. Streamingtjänstens front-end flyttade först till AWS, mellan 2010 och 2011, följt av företagets IT och allt annat. Netflix lokala datacenter stängdes 2016. Företaget mäter tillgänglighet som antalet lyckade försök att starta en film dividerat med det totala antalet, snarare än som en enkel jämförelse av drifttid och driftstopp, och strävar efter att uppnå 0,9999 i varje region kvartalsvis (det lyckas ofta). Netflix globala arkitektur sträcker sig över tre AWS-regioner, så om det finns ett problem i en region kan företaget omdirigera användare till andra.
Jag ska upprepa ett av mina favoritcitat:
"Misslyckanden är oundvikliga; så småningom kommer alla system att kollapsa." - Werner Vogels
Visst, fel i distribuerade system, särskilt i stor skala, är oundvikliga även i molnet. Men AWS-molnet och dess redundansprimitiver – i synnerhet, , som den bygger på, gör det möjligt för vem som helst att utforma mycket tillförlitliga tjänster.
Använda principerna för redundans (redundans) och gradvis minskning av funktionalitet (graciös förnedring)Netflix , utan att påverka slutanvändarna.
Netflix har haft de mest rigorösa arkitekturprinciperna från början. En av de första applikationerna de driftsatte på AWS var deras — för att stödja automatisk skalning av tillståndslösa mikrotjänster. Med andra ord kan vilken instans som helst stoppas och ersättas automatiskt utan tillståndsförlust. Chaos Monkey ser till att ingen bryter mot denna princip.
Notera. transl.Förresten, det finns en analog till Kubernetes som heter , vars utveckling verkar ha upphört i mars i år.
Netflix har ytterligare en regel som kräver att varje tjänst ska vara distribuerad över tre tillgänglighetszoner. Den måste fortsätta att fungera om bara två av dem är tillgängliga. För att säkerställa att denna regel följs, inaktiverar tillgänglighetszoner. På en mer global skala kapabla att stänga ner en hel AWS-region för att bekräfta att alla Netflix-användare kan betjänas från vilken som helst av de tre regionerna. Och de kör dessa storskaliga tester med några veckors mellanrum i produktionen för att säkerställa att ingenting slinker mellan stolarna.
Slutligen har Netflix också utvecklat mer riktade för att identifiera problem med mikrotjänster och lagringsarkitektur. Du kan lära dig mer om dessa tekniker i boken Chaos Engineering, som jag rekommenderar till alla som är intresserade av detta ämne.
"Genom att regelbundet genomföra experiment som simulerar regionala avbrott kunde vi tidigt identifiera olika systemiska svagheter och åtgärda dem."
Idag, principerna för kaosteknik de har följande definition:
"Kaosteknik är ett tillvägagångssätt som innebär att man experimenterar med ett produktionssystem för att säkerställa att det kan motstå olika störningar som kan uppstå under drift."
Men i hans , tillägnad kaosteknik, , den tidigare skaparen av Netflix molnarkitektur som hjälpte företaget att gå över till en molnbaserad infrastruktur, har en alternativ definition av kaosteknik som jag anser vara mer korrekt och väletablerad:
"Kaosteknik är ett experiment för att mildra effekterna av misslyckanden."
Vi vet att fel inträffar hela tiden. Med rätt respons bör de inte påverka slutanvändarna. Huvudmålet med kaosteknik är att upptäcka problem som inte åtgärdas ordentligt.
Nödvändiga förutsättningar för att skapa kaos
Innan du börjar med kaosteknik, se till att du har gjort allt arbete som krävs för att säkerställa motståndskraft på alla nivåer i organisationen. Att bygga motståndskraftiga system handlar inte bara om programvara. Det börjar vid infrastruktur, gäller för nätverk och data, påverkar strukturen tillämpningar, och täcker slutligen människor och kulturJag har skrivit mycket om resiliensmodeller och misslyckanden tidigare (, , и ) och jag kommer inte att fokusera på detta nu, men jag kan inte klara mig utan en liten påminnelse.
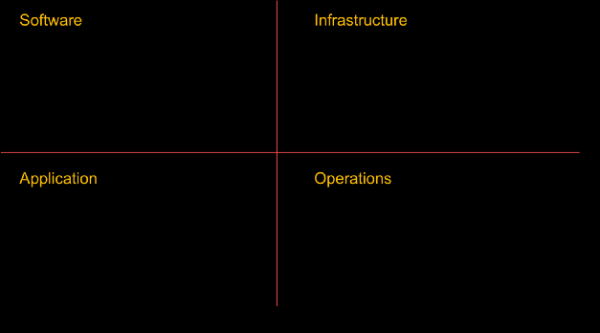
Några obligatoriska element innan man introducerar kaos i ett system (listan är inte uttömmande)
Steg av kaosteknik
Det är viktigt att förstå kärnan i kaosteknik INTE handlar om att släppa lös apor och låta dem krossa saker utan något syfte. Tanken bakom denna disciplin är att bryta sönder vissa delar av ett system i en kontrollerad miljö genom väl utformade experiment för att se om din applikation kan motstå turbulenta förhållanden.
För att göra detta måste du följa en tydligt definierad, formaliserad process, som visas i figuren nedan, som tar dig från att förstå ditt systems stationära tillstånd till att formulera en hypotes, testa den och slutligen analysera erfarenheterna från experimentet och förbättra systemets stabilitet.
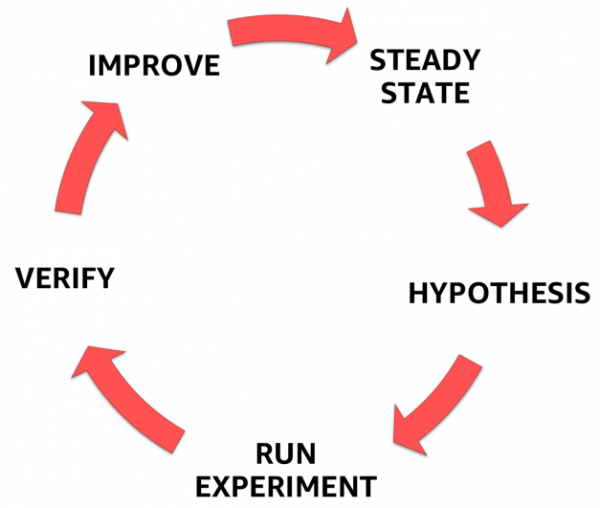
Steg av kaosteknik
1. Stabilt tillstånd
En av de viktigaste delarna av kaosteknik är att förstå systemets beteende under normala förhållanden.
Varför? Det är enkelt: efter att ha introducerat ett artificiellt fel måste du se till att systemet har återgått till ett väl studerat stabilt tillstånd och att experimentet inte längre stör dess normala beteende.
Nyckeln här är att inte fokusera på systemets interna attribut (processor, minne, etc.), utan på de mätbara utsignaler som kopplar prestanda till användarupplevelse. För att dessa utsignaler ska vara stabila bör systemets observerbara beteende ha ett förutsägbart mönster, men förändras avsevärt när ett fel uppstår i systemet.
Med tanke på , som föreslagits ovan av Adrian Cockcroft, förändras detta stabila tillstånd när ett utom kontroll fel orsakar ett oväntat problem och signalerar att kaosexperimentet bör avbrytas.
Som ett exempel på stabila tillstånd kan man ta Amazon. Företaget använder ordervolym som ett av sina stationära mätvärden, och det av goda skäl. År 2007 beskrev Greg Linden, tidigare på Amazon, hur han experimenterade med metoden. försökte sakta ner laddningstiden för webbplatsens sidor i steg om 100 ms och fann att även mindre förseningar resulterade i en betydande minskning av intäkterna. För varje 100 ms ökning av laddningstiden minskade antalet beställningar (och därmed försäljningen) med 1 %. Det är därför antalet beställningar är en bra kandidat för ett steady-state-mått.
Netflix, å andra sidan, använder ett serversidesmått relaterat till när en video börjar spelas – antalet gånger spelaren klickar på "play"-knappen. De lade märke till ett mönster i beteendet hos SPS-måttet (starter per sekund) och dess betydande fluktuationer vid systemfel. Måttet kallades "Netflix Pulse" ().
Amazons Orders och Netflix Pulse är utmärkta barometrar för stabilitet eftersom de kombinerar användarupplevelse och operativa mätvärden till ett enda, mätbart och mycket förutsägbart mått.
Mät, mät och mät igen
Det säger sig självt att om du inte kan fånga systemstatistik korrekt, kommer du inte att kunna övervaka (eller ens upptäcka) förändringar i stationärt tillstånd. Var särskilt uppmärksam på att fånga alla parametrar/statistik, från nätverk, hårdvara, applikation och människor. Rita dessa mätningar, även om de inte förändras över tid. Du kommer att bli förvånad över att upptäcka korrelationer du inte visste fanns.
"Gör det så enkelt som möjligt för ingenjörer att få tillgång till data som de kan beräkna eller grafiskt se på."
2. Hypotes
Efter att ha behandlat det stabila tillståndet kan vi gå vidare till att formulera en hypotes.

- Vad händer om rekommendationsmotorn stannar?
- Vad händer om lastbalanseraren går ner?
- Vad händer om cachningen misslyckas?
- Vad händer om latensen ökar med 300 ms?
- Vad händer om masterbasen faller?
Naturligtvis bör du bara välja en hypotes och inte komplicera den i onödan. Börja i liten skala. Jag gillar att börja med personalhypotesen. Har du hört talas om bussfaktor ()Bussfaktorn är ett mått på risken i samband med att kunskapen är ojämnt fördelad mellan teammedlemmarna. Den låter dig beräkna det minsta antalet teammedlemmar, efter vilka projektet plötsligt kommer att avbrytas på grund av bristande kunskap eller erfarenhet.
Många företag har tekniska experter vars plötsliga försvinnande ("att bli påkörd av en buss") skulle ha en förödande effekt på både projektet och teamet. Identifiera dessa personer och genomför kaosexperiment med dem: till exempel ta bort deras datorer och skicka hem dem i en dag, och observera sedan de (ofta kaotiska) resultaten.
Gör problemet gemensamt för alla!
Attrahera hela laget att utveckla en hypotes. Låt alla delta i brainstormingen: produktägaren, teknisk chef, backend- och frontend-utvecklare, designers, arkitekter etc. Alla som på något sätt är kopplade till produkten.
Be först alla att skriva ner svaret på frågan ”Tänk om…?” på ett papper. Du kommer att se att i de flesta fall har alla sitt eget svar, och du kommer att inse att en del av teamet inte alls har tänkt på det här problemet tidigare.
Stanna här och diskutera varför teammedlemmar har olika uppfattningar om hur produkten kommer att bete sig i fallet ”Tänk om…?”. Gå tillbaka till produktspecifikationerna och se till att alla har en klar uppfattning om vad som kan hända.
Ta den tidigare nämnda Amazon-butiken som exempel. Tänk om tjänsten Handla efter kategori slutade laddas på startsidan?
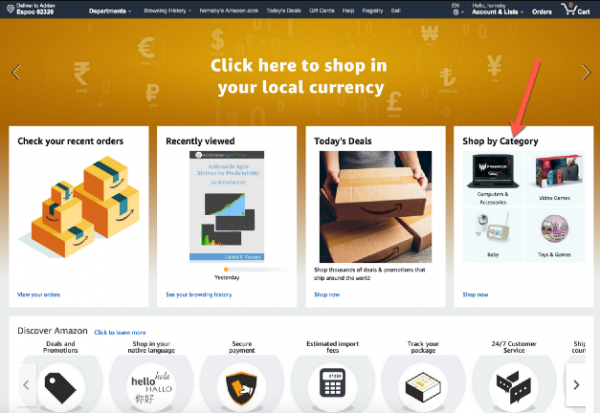
Ska jag returnera ett 404-fel? Ska jag ladda sidan och lämna tomt utrymme som i skärmdumpen nedan?
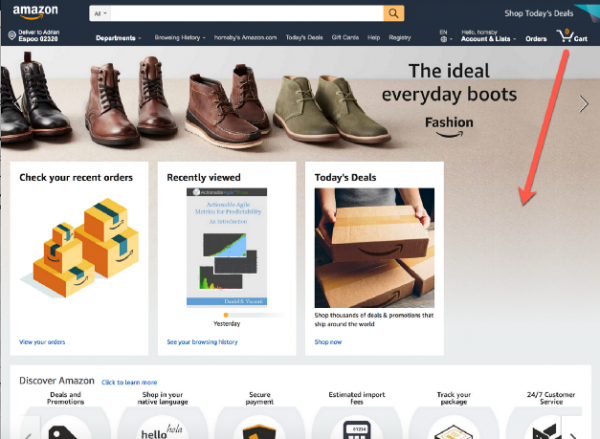
Är det värt att offra viss funktionalitet och till exempel låta sidan expandera och dölja felet?
Och det är bara på gränssnittssidan. Vad ska hända i backend? Ska aviseringar skickas? Ska den felande tjänsten fortsätta att ta emot förfrågningar varje gång användaren laddar startsidan, eller ska backend stänga av den helt?
Slutligen, formulera inte en hypotes som du vet kommer att misslyckas! Experimentera med delar av systemet som du tror är stabila – det är ju hela poängen med att experimentera.
3. Utforma och genomföra ett experiment
- Välj en hypotes;
- Definiera experimentets omfattning;
- Identifiera de relaterade mätvärden som kommer att mätas;
- Meddela organisationen.
Idag många människor, liksom webbplatsen , driver idén om kaosteknik i produktionen. Även om detta borde vara slutmålet, tycker de flesta organisationer att det här tillvägagångssättet är skrämmande, så det är inte rätt ställe att börja.
För mig handlar kaosteknik inte bara om att ha förstört olika delar av produktionssystem. Det är en resa. En upptäcktsresa som följer med att ha förstört system i en kontrollerad miljö – vilken miljö som helst, vare sig det är lokal utveckling, beta, staging eller produktion. Att bryta igenom väl utformade experiment för att bygga förtroende för din applikations förmåga att motstå turbulenta förhållanden.Bygga upp självförtroende" är en viktig punkt här eftersom det är en föregångare till de kulturella förändringar som krävs för att framgångsrikt implementera kaosteknik och tillförlitlighetspraxis i ditt företag.
Ärligt talat lär sig de flesta team mycket genom att knäcka saker även i en icke-produktionsmiljö. Testa bara. docker stop database i den lokala miljön och se om du kan hantera problemet utan konsekvenser. Chansen är stor att du inte kan det.
Stoppa en databas - exempel
Börja i liten skala och bygg gradvis upp förtroendet inom ditt team och din organisation. Du kommer att få höra att "riktig produktionstrafik är det enda sättet att på ett tillförlitligt sätt fånga upp systembeteende." Lyssna, le och fortsätt göra det du gör, långsamt. Det värsta du kan göra är att tillämpa kaosteknik på produktionen och misslyckas kapitalt. Efter det kommer ingen att lita på dig, och du kommer att tvingas glömma "kaosaporna" för alltid.
Förtjäna förtroende först. Visa organisationen och dina kollegor att du vet vad du gör. Bli brandman och lär dig så mycket om brand som möjligt innan du går vidare till brandutbildning i realtid. Förtjäna din trovärdighet. Kom ihåg. berättelsen om sköldpaddan och harenDen långsamme och tålmodige vinner alltid loppet.
En av de viktigaste sakerna att komma ihåg när man experimenterar är att förstå potentialen förstörelsens radie från det misslyckande du introducerar och dess minimering. Ställ dig själv följande frågor:
- Hur många kunder kommer experimentet att påverka?
- Vilken funktionalitet kommer att påverkas?
- Vilka platser kommer att påverkas?
Tänk på en "kill switch", eller ett sätt att omedelbart avbryta experimentet och återgå till ett stabilt tillstånd så snabbt som möjligt. Jag gillar att köra experiment med hjälp av vad jag kallar "canary"-distributioner. Denna teknik minskar risken för misslyckanden när nya versioner av en applikation lanseras i produktion genom att gradvis rulla ut ändringar till en liten delmängd av användare och sedan långsamt rulla ut dem till hela infrastrukturen och alla användare. Jag älskar canary-distributioner helt enkelt för att de uppfyller principen om , och själva experimentet är ganska lätt att stoppa.
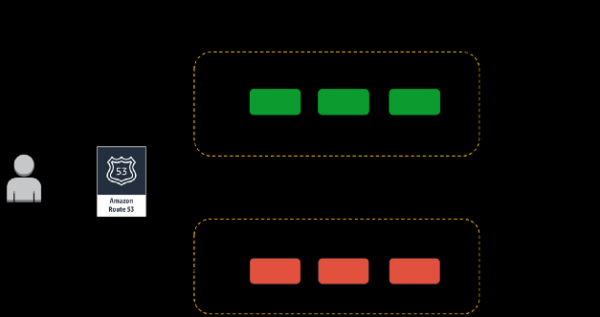
Ett exempel på en DNS-baserad canary-utrullning för kaosexperiment
Var försiktig med experiment som ändrar applikationens tillstånd (cache eller databas) eller som inte kan återställas (enkelt eller alls).
Intressant nog berättade Adrian Cockcroft för mig att en av anledningarna till att Netflix började använda NoSQL-databaser var att de inte har ett schema för ändringar eller återställningar, så det är mycket enklare att stegvis uppdatera eller åtgärda enskilda dataposter (dvs. de är mer kaosteknikvänliga).
4. Observera och lär
För att lära sig nya saker och övervaka experimentets framsteg är det nödvändigt att kunna övervaka systemets mätvärden. Som tidigare nämnts, var noga med alla möjliga mätvärden och parametrar! Kvantifiera sedan resultaten och tajma alltid – alltid! – de första tecknen på ett problem. Jag har haft många fall i min historia där varningssystem misslyckades och de första att rapportera problemet var kunder på Twitter… tro mig, du vill inte hamna i den situationen, så använd kaosexperiment för att testa dina övervaknings- och varningssystem också.
- Dags för upptäckt?
- Tid före avisering och start av aktiva åtgärder?
- Tid före offentligt tillkännagivande?
- Tid till delvis funktionsförlust?
- Hur länge varar självläkningsperioden?
- Dags för hel eller delvis återhämtning?
- Hur lång tid tar det innan krisen är över och en återgång till ett stabilt tillstånd?
Kom ihåg att det inte finns någon enskild isolerad orsak till misslyckanden. Stora katastrofer är alltid resultatet av flera små misslyckanden som ackumuleras och leder till en större kris.
Genomför en detaljerad analys (obduktion) av resultaten från varje experiment!
På AWS är vi noggranna med att analysera de fel vi stöter på och förstå grundorsakerna för att förhindra liknande problem i framtiden. Alla resultat från experimentet sammanställs i ett dokument som kallas felkorrigering (Correction-of-Errors, COE). COE låter oss lära av våra misstag, oavsett om de är brister i teknik, process eller till och med organisation. Vi använder denna mekanism för att eliminera grundorsakerna till fel och kontinuerligt förbättra oss.
Nyckeln till framgång i denna process är öppenhet och transparens kring vad som gick fel. En av de viktigaste principerna för att skriva en bra COE är att vara opartisk och undvika att namnge specifika personer. Detta är ofta svårt i en miljö som inte belönar sådant beteende och inte tolererar möjligheten till misslyckande. Amazon använder en samling "ledarskapsprinciper" () för att uppmuntra sådant beteende - till exempel, självkritik, analytiskt förhållningssätt, engagemang för högsta standard och ansvarstagande är viktiga komponenter i COE-processen och operativ excellens i allmänhet.
COE-rapporten har fem huvudavsnitt:
- Vad hände (kronologisk ordning)?
- Vilken påverkan hade kunderna?
- Varför uppstod felet? ()
- Vad lärde vi oss?
- Hur kan man förhindra detta i framtiden?
Dessa frågor är svårare att besvara än de kan verka vid första anblicken, eftersom du måste se till att varje oklar/okänd punkt undersöks noggrant.
För att göra COE till en fullfjädrad process genomför vi löpande granskningar i form av veckomöten med obligatoriska granskningar av operativa mätvärden. Dessutom genomför tekniska chefer veckovisa mätvärden med all AWS-personal.
5. Korrigera och förbättra!
Den viktigaste lärdomen här är prioritera att åtgärda problem som identifierats under kaosexperiment framför att utveckla nya funktionerInvolvera den högsta ledningen i denna process och ingjut i dem idén att det är mycket viktigare att åtgärda befintliga problem än att utveckla ny funktionalitet.
Jag använde en gång ett kaosexperiment för att hjälpa en kund att identifiera kritiska stabilitetsproblem, men påtryckningar från säljföretaget ledde till att lösningen nedgraderades till en ny funktion som var "kritisk" för kunderna. Två veckor senare tvingade ett 16 timmar långt avbrott företaget att åtgärda samma problem som vi hade identifierat i kaosexperimentet. Bara det att förlusterna var mycket högre.
Fördelar med kaosteknik
Det finns många fördelar. Jag kommer att lyfta fram två, enligt min mening de viktigaste:
För det första hjälper kaosteknik till att avslöja okända problem i systemet och åtgärda dem innan de leder till ett produktionsfel, säg klockan 3 på morgonen på en söndag. Det vill säga, det ökar motståndskraften mot störningar och i själva verket sömnkvaliteten.
För det andra producerar effektivt genomförda kaosexperiment alltid mer omfattande förändringar (främst kulturella) än förväntat. Den kanske viktigaste av dessa är den naturliga utvecklingen till "oskyldig" (icke-klandrande) kultur, när frågan ”Varför gjorde ni det?” blir ”Hur kan vi undvika detta i framtiden?” Resultatet är ett lyckligare, effektivare, mer engagerat och mer framgångsrikt team. Och det är underbart!
Detta avslutar den första delen. Jag hoppas att du gillade den. Lämna gärna en recension, dela dina åsikter eller klappa bara händerna. I nästa del kommer jag att titta på verktyg och metoder för att introducera fel i system. Tills dess - hej då!
För er som är ivriga att läsa den andra delen, här är mitt föredrag om kaosteknik på NDC i Oslo. I det pratar jag om många av mina favoritverktyg:

PS från översättaren
Den andra delen av artikeln på engelska och vi kommer även att översätta det om vi ser tillräckligt intresse från Habr-läsare för detta material – motsvarande kommentarer till artikeln är välkomna!
Läs även på vår blogg:
- «";
- «";
- «".
Källa: will.com
