

Павел Селиванов, архитектор решений Southbridge и преподаватель Слёрма, выступил с докладом на DevOpsConf 2019. Этот доклад — часть одной из тем углубленного курса по Kubernetes «Слёрм Мега».
проходит в Москве 18-20 ноября.
— Москва, 22-24 ноября.
доступен всегда.

Под катом — расшифровка доклада.
Доброго дня, коллеги и им сочувствующие. Сегодня я буду рассказывать про безопасность.
Я вижу, что в зале сегодня много безопасников. Я заранее перед вами извиняюсь, если термины из мира безопасности я буду использовать не совсем так, как у вас принято.
Так получилось, что где-то полгода назад мне в руки попал один публичный кластер Kubernetes. Публичный — означает, что там есть n-ное количество namespaces, в этих неймспейсах есть users, изолированные в своём неймспейсе. Все эти юзеры принадлежат разным компаниям. Ну, и предполагалось, что этот кластер нужно использовать как CDN. То есть вам дают кластер, дают туда пользователя, вы туда приходите в свой namespace, деплоите свои фронты.
Моей предыдущей компании попытались такую услугу продать. И меня попросили потыкать кластер на предмет — подходит или не подходит такое решение.
Пришёл я в этот кластер. Мне дали ограниченные права, ограниченный namespace. Там ребята понимали, что такое безопасность. Они читали, что такое Role-based access control (RBAC) у Кубернетеса — и они его закрутили так, что я не мог запускать поды отдельно от деплойментов. Не помню задачу, которую я пытался решить, запуская под без деплоймента, но мне очень хотелось запустить просто под. Я решил на удачу посмотреть, какие права у меня в кластере есть, что я могу, что не могу, что они там понакрутили. Заодно расскажу, что у них в RBAC настроено неправильно.
Так получилось, что через две минуты я получил админа к их кластеру, посмотрел во все соседние namespaces, увидел там запущенные продакшн фронты компаний, которые уже купили услугу и задеплоились. Я еле остановил себя, чтобы не прийти к кому-нибудь во фронт и на главную страницу не поместить какое-нибудь матерное слово.
Я расскажу на примерах, как я это сделал и как от этого надо защищаться.
Но для начала представлюсь. Меня зовут Павел Селиванов. Я архитектор компании Southbridge. Я разбираюсь в Kubernetes, DevOps и всяких модных штуках. Мы с инженерами Southbridge всё это строим, а я консультирую.
Помимо основной деятельности мы ещё недавно запустили проекты, которые называются Слёрмы. Мы наше умение работать с Kubernetes пытаемся немного привнести в массы, научить других людей тоже работать с К8s.
О чём я буду сегодня рассказывать. Тема доклада очевидна — про безопасность кластера Kubernetes. Но сразу хочу сказать, что эта тема очень большая — и потому я сразу хочу оговорить, о чём я точно рассказывать не буду. Я не буду рассказывать про заезженные термины, которые в интернете уже сто раз перемусолены. Всякие RBAC и сертификаты.
Я буду рассказывать о том, что у меня и у моих коллег болит от безопасности в кластере Kubernetes. Мы эти проблемы видим и у провайдеров, которые предоставляют кластера Kubernetes, и у клиентов, которые к нам приходят. И даже у клиентов, которые приходят к нам от других консалтинговых админских компаний. То есть масштаб трагедии очень большой на самом деле.
Буквально три пункта, о которых я сегодня расскажу:
- Права пользователей vs права pod’ов. Права пользователей и права подов — это не одно и то же.
- Сбор информации о кластере. Покажу, что из кластера можно собирать всю информацию, которая понадобится, не имея особых прав в этом кластере.
- DoS-атака на кластер. Если мы не сможем собирать информацию, мы сможем кластер положить в любом случае. Я расскажу про DoS-атаки на управляющие элементы кластера.
Ещё одна общая вещь, о которой я упомяну — на чём я всё это тестировал, на чём я точно могу сказать, что всё это работает.
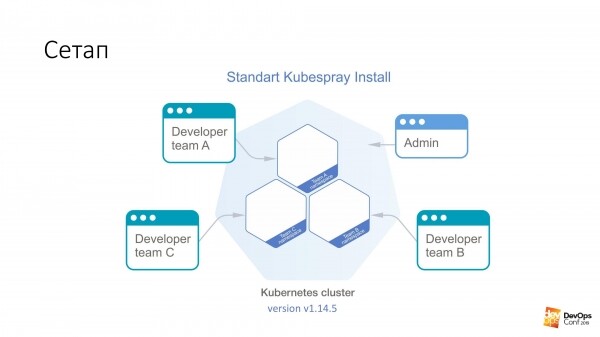
За основу мы берём установку кластера Kubernetes с помощью Kubespray. Если кто-то не знает, это фактически набор ролей для Ansible. Мы в работе его постоянно используем. Хорош тем, что можно накатить куда угодно — и на железки можно накатить, и куда-нибудь в облако. Один способ установки подходит в принципе для всего.
В этом кластере у меня будет Kubernetes v1.14.5. Весь кластер Куба, который мы будем рассматривать, поделен на неймспейсы, каждый неймспейс принадлежит отдельной команде, в каждый неймспейс есть доступ у членов этой команды. В разные неймспейсы они ходить не могут, только в свой. Но есть некая админская учётка, у которой есть права на весь кластер.
Я обещал, что первое у нас будет — получение админских прав на кластер. Нам нужен специально подготовленный pod, который будет ломать кластер Kubernetes. Всё, что нам нужно сделать, это применить его в кластер Кубернетес.
kubectl apply -f pod.yamlЭтот pod у нас приедет на один из мастеров кластера Kubernetes. И кластер нам после этого радостно вернёт файлик, который называется admin.conf. В Кубе в этом файле хранятся все сертификаты админа, а заодно настроен API кластера. Вот так просто можно получить админский доступ, думаю, к 98% кластеров Kubernetes.
Повторюсь, этот pod сделал один разработчик в вашем кластере, у которого есть доступ деплоить свои предложения в один маленький namespace, он весь зажат RBAC. Прав у него никаких не было. Но тем не менее сертификат вернулся.
А теперь о специально подготовленном поде. Запускаем на любом образе. Для примера возьмём debian:jessie.
У нас есть такая штука:
tolerations:
- effect: NoSchedule
operator: Exists
nodeSelector:
node-role.kubernetes.io/master: "" Что такое toleration? Мастера в кластере Кубернетеса обычно помечены штукой, которая называется taint («зараза» по-английски). И суть этой «заразы» — она говорит, что на мастеровые ноды нельзя назначать поды. Но никто не мешает в любом поде указать, что он толерантен к «заразе». Секция Toleration как раз и говорит, что если на какой-то ноде стоит NoSchedule, то наш под к такой заразе толерантен — и никаких проблем.
Дальше, мы говорим, что наш под не просто толерантен, но и хочет специально попадать на мастера. Потому что на мастерах находится самое вкусное, что нам нужно — все сертификаты. Поэтому мы говорим nodeSelector — и у нас есть стандартный лейбл на мастерах, который позволяет выбрать из всех нод кластера именно те ноды, которые являются мастерами.
Вот с такими двумя секциями под точно приедет на мастер. И ему разрешат там жить.
Но просто приехать на мастер нам недостаточно. Это нам ничего не даст. Поэтому далее у нас есть такие две вещи:
hostNetwork: true
hostPID: true Мы указываем, что наш под, который мы запускаем, будет жить в неймспейсе ядра, в network неймспейсе и в PID неймспейсе. Как только под запустится на мастере, он сможет видеть все настоящие, живые интерфейсы этой ноды, прослушивать весь трафик и видеть PID всех процессов.
Далее дело за малым. Берете etcd и читаете, что хотите.
Самое интересное — эта возможность Kubernetes, которая там по умолчанию присутствует.
volumeMounts:
- mountPath: /host
name: host
volumes:
- hostPath:
path: /
type: Directory
name: host И суть её в том, что мы можем в поде, который мы запускаем, даже без прав на этот кластер, сказать, что мы хотим создать volume типа hostPath. Значит взять путь с хоста, на которым мы запустимся — и взять его как volume. И дальше его обзываем name: host. Весь этот hostPath мы монтируем внутрь пода. В данном примере в директорию /host.
Ещё раз повторюсь. Мы сказали поду приезжать на мастер, получать туда hostNetwork и hostPID — и весь root мастера замонтировать внутрь этого пода.
Вы понимаете, что в дебиане у нас запущен bash, и этот bash у нас работает под рутом. То есть мы только что получили рута на мастер, при этом не обладая какими-то правами в кластере Kubernetes.
Дальше вся задача — зайти в под в директорию /host /etc/kubernetes/pki, если не ошибаюсь, забрать там все мастеровые сертификаты кластера и, соответственно, стать админом кластера.
Если так посмотреть, это одни из самых опасных прав в подах — несмотря на то, какие права есть у пользователя:
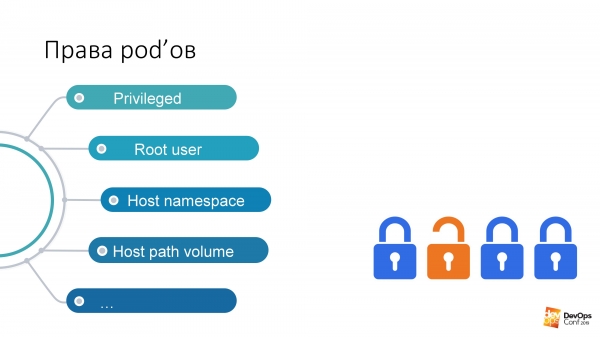
Если у меня есть права запустить под в каком-то неймспейсе кластера, то у этого пода эти права есть по умолчанию. Я могу запускать привилегированные поды, а это вообще все права, практически рут на ноду.
Моё любимое — Root user. А у Кубернетеса есть такая опция Run As Non-Root. Это такая типа защита от хакера. Знаете, что такое «молдавский вирус»? Если вы вдруг хакер и пришли в мой кластер Кубернетес, то мы, бедные администраторы, просим: «Укажите, пожалуйста, в своих подах, которыми вы будете хакать мой кластер, run as non-root. А то так получится, что вы запустите процесс в своём поде под рутом, и вам очень просто будет меня хакнуть. Защититесь, пожалуйста, от себя сами».
Host path volume — на мой взгляд, самый быстрый способ получить желаемый результат от кластера Кубернетеса.
Но что со всем этим делать?
Мысли, которая должны приходить любому нормальному администратору, который сталкивается с Кубернетесом: «Ага, я же говорил, Кубернетес не работает. В нём дырки. И весь Куб фигня». На самом деле, есть такая штука, как документация, а если туда посмотреть, то там есть раздел .
Это такой yaml-объект — мы его можем создавать в кластере Кубернетес — который контролирует аспекты безопасности именно в описании подов. То есть фактически он контролирует те права на использование всяких hostNetwork, hostPID, определённых типов volume, которые есть в подах при запуске. С помощью Pod Security Policy всё это можно описать.
Самое интересное в Pod Security Policy, что в кластере Кубернетеса у всех установщиков PSP не просто никак не описаны, они просто по умолчанию выключены. Pod Security Policy включается с помощью admission plugin.
Окей, в кластер задеплоим Pod Security Policy, скажем, что у нас есть служебные некие поды в неймспейсе, к которому имеют доступ только админы. Скажем, во всех остальных поды имеют ограниченные права. Потому что скорее всего разработчикам не нужно запускать в вашем кластере привилегированные поды.
И у нас вроде всё хорошо. И наш кластер Кубернетес нельзя взломать за две минуты.
Есть проблема. Скорее всего, если у вас есть кластер Кубернетес, то в вашем кластере установлен мониторинг. Я даже берусь предсказать, что если в вашем кластере есть мониторинг, то он называется Prometheus.
То, что я сейчас расскажу, будет валидно и для Prometheus-оператора, и для Prometheus, поставленного в чистом виде. Вопрос в том, что если я в кластер не могу так быстро админа получить, то это означает, что мне нужно больше искать. А искать я могу с помощью вашего мониторинга.
Вероятно, все читали одни и те же статьи на Хабре, и мониторинг находится в неймспейсе monitoring. Helm chart у всех называется примерно одинаково. Я предполагаю, что если вы сделаете helm install stable/prometheus, то у вас получаться примерно одинаковые названия. И даже скорее всего DNS-имя в вашем кластере мне угадывать не придётся. Потому что оно стандартное.
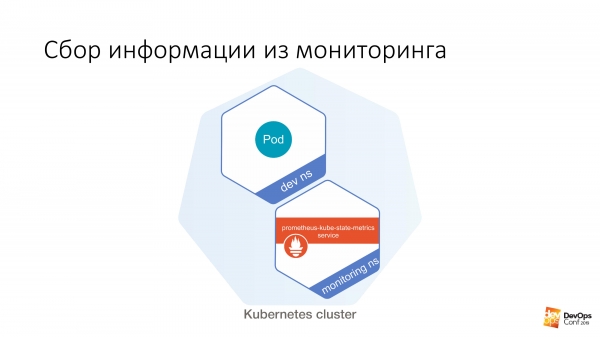
Дальше у нас есть некий dev ns, в нём можно запустить некий под. И дальше из этого пода очень легко сделать вот так:
$ curl http://prometheus-kube-state-metrics.monitoring prometheus-kube-state-metrics — это один из экспортеров прометеуса, который собирает метрики из API самого Kubernetes. Там очень много данных, что запущено у вас в кластере, какое оно, какие у вас с ним есть проблемы.
Как простой пример:
kube_pod_container_info{namespace=«kube-system»,pod=»kube-apiserver-k8s- 1″,container=»kube-apiserver»,image=
«gcr.io/google-containers/kube-apiserver:v1.14.5»
,image_id=»docker-pullable://gcr.io/google-containers/kube- apiserver@sha256:e29561119a52adad9edc72bfe0e7fcab308501313b09bf99df4a96 38ee634989″,container_id=»docker://7cbe7b1fea33f811fdd8f7e0e079191110268f2 853397d7daf08e72c22d3cf8b»} 1
Сделав простой запрос curl из непривилегированного пода, можно получить такую вот информацию. Если вы не знаете, в какой версии Кубернетес вы запущены, то он легко вам расскажет.
А самое интересное, что кроме того, что вы обращаетесь к kube-state-metrics, вы можете с тем же успехом обратиться и в сам Prometheus напрямую. Вы можете собрать оттуда метрики. Вы даже можете построить оттуда метрики. Даже теоретически вы можете построить такой запрос из кластера в Prometheus, который его просто выключит. И у вас мониторинг вообще перестанет от кластера работать.
И тут уже возникает вопрос, мониторит ли какой-нибудь внешний мониторинг ваш мониторинг. Только что я получил возможность действовать в кластере Кубернетес вообще без последствий для себя. Вы даже не узнаете, что я там действую, так как мониторинга уже нет.
Точно так же, как с PSP, возникает ощущение, будто бы проблема в том, что все эти модные технологии — Kubernetes, Prometheus — они просто не работают и полны дырок. На самом деле нет.
Есть такая штука — .
Если вы нормальный админ, то скорее всего про Network Policy вы знаете, что это очередной yaml, которых в кластере и так дофига. И Network Policies какие-то точно не нужны. А если даже вы и прочитали, что такое Network Policy, что это yaml-файервол Кубернетеса, он позволяет ограничивать права доступа между неймспейсами, между подами, то вы уж точно решили, что файервол в формате yaml в Кубернетесе на очередных абстракциях… Не-не. Это точно не нужно.
Даже если у вас специалистам по безопасности не рассказали, что с помощью вашего Кубернетеса можно строить очень легко и просто файервол, причём очень гранулированный. Если они у вас ещё этого не знают и вас не дёргают: «Ну дайте, дайте…» То в любом случае Network Policy вам нужно, чтобы закрывать доступ к некоторым служебным местам, которые можно из вашего кластера подёргать, не имея никакой авторизации.
Как в примере, который я приводил, можно подёргать kube state metrics из любого неймспейса в кластере Кубернетес, не имея на это никаких прав. Network policies закрыли доступ из всех остальных неймспейсов в неймспейс мониторинга и как бы всё: нет доступа, нет проблем. Во всех чартах, которые есть, и стандартного прометеуса, и того прометеуса, который в операторе, там просто в values хелма есть опция просто включить network policies для них. Нужно просто включить, и они будут работать.
Есть тут правда одна проблема. Будучи нормальным бородатым админом, вы скорее всего решили, что network policies не нужны. И почитав всякие статьи на ресурсах типа Хабра, вы решили, что flannel особенно с режимом host-gateway — это самое лучшее, что вы можете выбрать.
Что делать?
Вы можете попробовать передеплоить сетевое решение, которое стоит у вас в кластере Кубернетес, попробовать заменить на что-то более функциональное. На то же самое Calico, например. Но сразу же хочу сказать, задача поменять сетевое решение в рабочем кластере Кубернетес — довольно нетривиальная. Я её два раза решал (оба раза, правда, теоретически), но мы даже на Слёрмах показывали, как это сделать. Для наших обучаемых мы показывали, как поменять сетевое решение в кластере Кубернетес. В принципе можете попробовать сделать так, чтобы на продакшн-кластере даунтайма не было. Но вероятно у вас ничего не получится.
И проблема на самом деле решается очень просто. В кластере есть сертификаты, и вы знаете, что сертификаты у вас через год протухнут. Ну, и обычно нормальное решение с сертификатами в кластере — а чего мы будем париться, мы рядом новый кластер поднимем, в старом пусть протухнет, и всё передеплоим. Правда, когда оно протухнет, у нас день всё полежит, но вот зато новый кластер.
Когда будете новый кластер поднимать, заодно Calico вставьте вместо flannel.
Что делать если у вас сертификаты выписаны на сто лет и кластер вы передеплоивать не собираетесь? Есть такая штука Kube-RBAC-Proxy. Это очень классная разработка, она позволяет встроить себя, как sidecar container к любому поду в кластере Кубернетес. И она фактически добавляет к этому поду авторизацию через RBAC самого Kubernetes.
Одна проблема есть. Раньше в прометеус оператора это решение Kube-RBAC-Proxy было встроено. Но его потом не стало. Сейчас современные версии опираются на то, что у вас есть network policу и закрываете с помощью них. И поэтому придётся немного переписать чартом. На самом деле если вы зайдёте в , там есть примеры, как это использовать как sidecars, и чарты придётся переписать минимально.
Есть ещё одна небольшая проблема. Не только Prometheus отдаёт свои метрики кому ни попадя. У нас все компоненты кластер Кубернетес тоже свои метрики умеют отдавать.
Но как я уже говорил, если не можешь получить доступ к кластеру и собрать информацию, то можно хотя бы навредить.
Так что я быстренько покажу два способа, как можно кластеру Kubernetes испортить здоровье.
Вы будете смеяться, когда я это расскажу, это два случая из реальной жизни.
Способ первый. Исчерпание ресурсов.
Запускаем ещё один специальный под. У него будет вот такая секция.
resources:
requests:
cpu: 4
memory: 4Gi Как вы знаете, requests — это то количество ЦПУ и памяти, которое на хосте резервируется для конкретных подов с реквестами. Если у нас есть четырёхядерный хост в кластере Кубернетес, и туда приезжает под с реквестами четыре по ЦПУ, то значит ни одного больше пода с реквестами на этот хост приехать не сможет.
Если я запущу такой под, потом сделаю команду:
$ kubectl scale special-pod --replicas=...То больше никто в кластер Кубернетес деплоиться не сможет. Потому что во всех нодах закончатся реквесты. И таким образом я ваш кластер Kubernetes остановлю. Если я вечерком такое сделаю, то деплои могу остановить довольно надолго.
Если мы посмотрим в очередной раз в документацию Kubernetes, то мы увидим такую штуку, которая называется Limit Range. Он устанавливает ресурсы для объектов кластера. Вы можете написать в yaml объект Limit Range, применить его в определённые неймспейсы — и дальше в этом неймспейсе вы можете сказать, что у вас есть ресурсы для подов дефолтные, максимальные и минимальные.
С помощью такой штуки мы можем ограничить пользователей в конкретных продуктовых неймспейсах команд в возможностях указывать на своих подах всякую гадость. Но к сожалению, даже если вы скажете пользователю, что нельзя запускать поды с реквестами больше одного ЦПУ, есть такая замечательная команда scale, ну или через dashboard они могут делать scale.
И отсюда проистекает способ номер два. Запускаем 11 111 111 111 111 подов. Это одиннадцать миллиардов. Это не потому, что я придумал такое число, а потому что я сам это видел.
Реальная история. Поздним вечером я уже собирался уходить из офиса. Смотрю, в уголке сидит группка разработчиков и что-то судорожно с ноутбуками делает. Я подхожу к ребятам и спрашиваю: «Что у вас случилось?»
Чуть пораньше, часов в девять вечера один из разработчиков собирался домой. И решил: «Я сейчас своё приложению заскейлю до единички». Нажал единичку, а интернет немножко затупил. Он ещё раз нажал на единичку, он надавил на единичку, клацнул по Enter. Потыкал на всё, что мог. Тут интернет ожил — и всё начало скейлиться до этого числа.
Правда, эта история происходила не на Kubernetes, на тот момент это был Nomad. Закончилось это тем, что через час наших попыток остановить Nomad от упорных попыток скейлиться, Nomad ответил, что скейлиться не перестанет и ничем другим заниматься не будет. «Я устал, я ухожу». И свернулся.
Я естественно попробовал сделать то же самое на Kubernetes. Одиннадцать миллиардов подов Кубернетес не обрадовали, он сказал: «Не могу. Превышает внутренние капы». А вот 1 000 000 000 подов смог.
В ответ на один миллиард Куб в себя не ушёл. Он действительно начал скейлить. Чем дальше процесс заходил, тем больше времени у него уходило на создание новых подов. Но всё равно процесс шёл. Единственная проблема в том, что если я могу в своём неймспейсе неограниченно запускать поды, то даже без реквестов и лимитов я могу позапускать с какими-то задачами такое количество подов, что с помощью этих задач ноды начнут складываться по памяти, по ЦПУ. Когда я запускаю столько подов, информация из них должна попасть в хранилище, то бишь etcd. А когда туда поступает слишком много информации, хранилище начинает слишком медленно отдавать — и у Кубернетеса начинаются затупы.
А ещё одна проблема… Как знаете, управляющие элементы Кубернетес — это не одна какая-то центральная штуковина, а несколько компонентов. Там в частности есть контроллер менеджер, scheduler и так далее. Все эти ребята начнут выполнять одновременно ненужную бестолковую работу, которая со временем начнёт занимать всё больше и больше времени. Контроллер менеджер будет новые поды создавать. Scheduler будет пытаться найти им новую ноду. Новые ноды у вас в кластере, скорее всего, скоро закончатся. Кластер Кубернетес начнёт работать всё медленнее и медленнее.
Но я решил пойти ещё дальше. Как вы знаете, в Кубернетес есть такая штука, которая называется сервис. Ну, и по умолчанию в ваших кластерах, скорее всего, сервис работает с помощью IP tables.
Если запустить один миллиардов подов, к примеру, а потом с помощью скриптика заставить Кубернетис создавать новые сервисы:
for i in {1..1111111}; do
kubectl expose deployment test --port 80
--overrides="{"apiVersion": "v1",
"metadata": {"name": "nginx$i"}}";
done На всех нодах кластера приблизительно одновременно будет генерироваться всё новые и новые правила iptables. Причём на каждый сервис будут генериться по одному миллиарду правил iptables.
Я это всё дело проверял на несколько тысячах, до десятка. И проблема в том, что уже на этом пороге ssh на ноду сделать довольно проблематично. Потому что пакеты, проходя такое количество цепочек, начинают не очень хорошо себя чувствовать.
И это тоже всё решается с помощью Кубернетеса. Есть такой объект Resource quota. Устанавливает количество доступных ресурсов и объектов для неймспейса в кластере. Мы можем создать yaml объект в каждом неймспейсе кластера Кубернетес. С помощью этого объекта мы можем сказать, что у нас для этого неймспейса выделено определённое количество реквестов, лимитов, и дальше мы можем сказать, что в этом нейспейсе возможно создать 10 сервисов и 10 подов. И разработчик единичкой может хоть обдавиться по вечерам. Кубернетес ему скажет: «Нельзя заскейлить ваши поды до такого количества, потому что превышает ресурс квоту». Всё, проблема решена. .
Один проблемный момент в связи с этим возникает. Вы чувствуете, как сложно становится создать в Кубернетесе неймспейс. Чтобы его создать, нам необходимо кучу всего учесть.
Resource quota + Limit Range + RBAC
• Создаем namespace
• Создаем внутри limitrange
• Создаем внутри resourcequota
• Создаем serviceaccount для CI
• Создаем rolebinding для CI и пользователей
• Опционально запускаем нужные служебные поды
Поэтому пользуясь случаем, я хотел бы поделиться своими разработками. Есть такая штука, называется оператор SDK. Это способ в кластере Кубернетес писать для него операторы. Вы можете писать операторы с помощью Ansible.
Сначала у нас было написано на Ansible, а потом я посмотрел, что есть оператор SDK и переписал Ansible-роль в оператор. Этот оператор позволяет создать в кластере Кубернетес объект, который называется команда. Внутри команды он позволяет описывать в yaml окружение для этой команды. И внутри окружения команды он позволяет описывать, что мы выделяем столько-то ресурсов.
Маленькая .
И в заключении. Что со всем этим делать?
Первое. Pod Security Policy — это хорошо. И не смотря на то, что ни один из установщиков Кубернетес по сей день их не использует, всё-таки в ваших кластерах их использовать нужно.
Network Policy — это не какая-то еще одна ненужная фича. Это то, что в кластере реально нужно.
LimitRange/ResourceQuota — пора бы использовать. Мы давно начали этим пользоваться, и я долго был уверен, что все поголовно это применяют. Оказалось, что это редкость.
Помимо того, что я упоминал в ходе доклада, есть незадокументированные фичи, которые позволяют атаковать кластер. Вышел недавно .
Некоторые вещи настолько печальные и обидные. Как например, при некоторых условиях кублеты в кластере Кубернетес могут отдавать содержимое warlocks директории, причём неавторизованному пользователю.
лежат инструкции, как воспроизвести всё, что я рассказывал. Там лежат файлики с продакшн примерами, как ResourceQuota, Pod Security Policy выглядят. И всё это можно потрогать.
Всем спасибо.
Источник: habr.com






