


VictoriaMetrics është një DBMS e shpejtë dhe e shkallëzuar për ruajtjen dhe përpunimin e të dhënave në formën e një serie kohore (një rekord përbëhet nga koha dhe një grup vlerash që korrespondojnë me këtë kohë, për shembull, të marra përmes sondazheve periodike të statusit të sensorëve ose koleksioni i metrikës).


Emri im është Kolobaev Pavel. DevOps, SRE, LeroyMerlin, gjithçka është si kodi - ka të bëjë me ne: për mua dhe për punonjësit e tjerë të LeroyMerlin.
Ekziston një re e bazuar në OpenStack. Ekziston një lidhje e vogël me radarin teknik.

Është ndërtuar në harduerin Kubernetes, si dhe në të gjitha shërbimet e lidhura për OpenStack dhe logging.
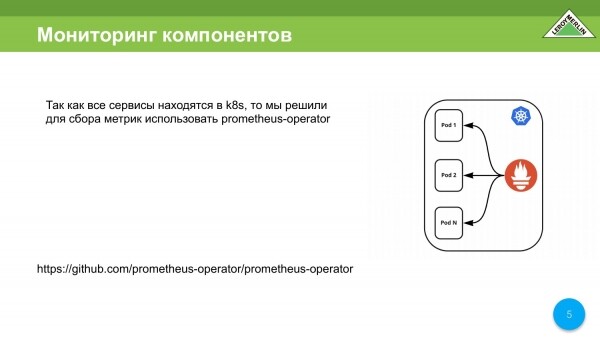
Kjo është skema që kishim në zhvillim. Kur po zhvillonim të gjitha këto, kishim një operator Prometheus që ruante të dhëna brenda vetë grupit K8s. Ai automatikisht gjen atë që duhet të pastrohet dhe e vendos nën këmbët e tij, përafërsisht.

Do të na duhet t'i zhvendosim të gjitha të dhënat jashtë grupit Kubernetes, sepse nëse ndodh diçka, duhet të kuptojmë se çfarë dhe ku.
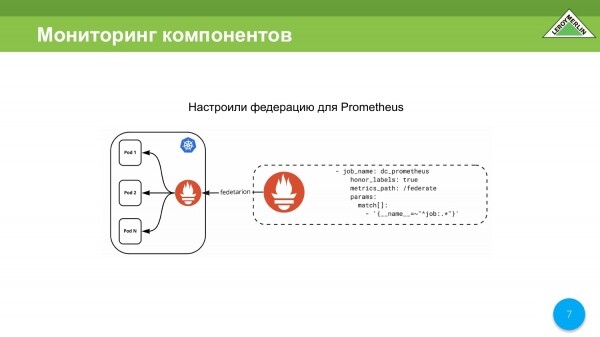
Zgjidhja e parë është se ne përdorim federatën kur kemi një Prometheus të palës së tretë, kur shkojmë në grupin Kubernetes përmes mekanizmit të federatës.

Por këtu ka disa probleme të vogla. Në rastin tonë, problemet filluan kur kishim 250 metrikë dhe kur ishin 000 metrikë, kuptuam se nuk mund të punonim kështu. Rritëm scrape_timeout në 400 sekonda.
Pse duhej ta bënim këtë? Prometeu fillon të numërojë timeout nga fillimi i gardhit. Nuk ka rëndësi që të dhënat ende rrjedhin. Nëse gjatë kësaj periudhe të caktuar kohore të dhënat nuk bashkohen dhe sesioni nuk mbyllet nëpërmjet http, atëherë sesioni konsiderohet i dështuar dhe të dhënat nuk futen në vetë Prometheus.
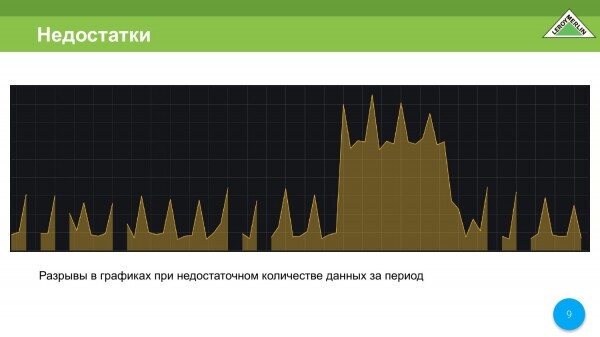
Të gjithë janë të njohur me grafikët që marrim kur mungojnë disa nga të dhënat. Oraret janë të grisura dhe ne nuk jemi të kënaqur me këtë.
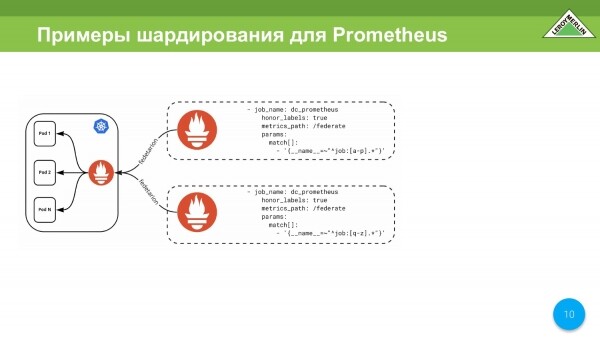
Opsioni tjetër është sharding bazuar në dy Prometheus të ndryshëm përmes të njëjtit mekanizëm federate.
Për shembull, thjesht merrni ato dhe copëtojini me emër. Kjo mund të përdoret gjithashtu, por ne vendosëm të vazhdojmë.
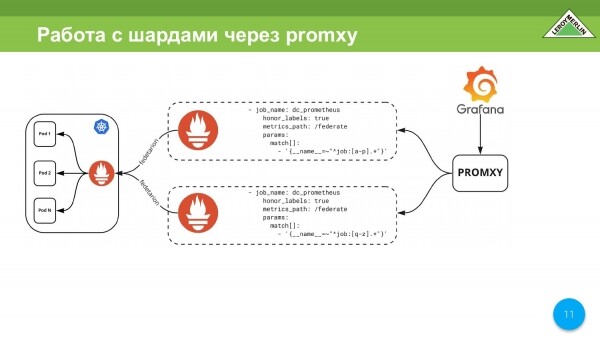
Tani do të na duhet t'i përpunojmë disi këto copa. Ju mund të merrni promxy, i cili shkon në zonën e copëzave dhe shumëzon të dhënat. Punon me dy copëza si një pikë e vetme hyrjeje. Kjo mund të zbatohet përmes promxy, por është ende shumë e vështirë.
Opsioni i parë është që ne duam të braktisim mekanizmin e federatës sepse është shumë i ngadaltë.
Zhvilluesit e Prometheus po thonë qartë, "Djema, përdorni një TimescaleDB të ndryshme sepse ne nuk do të mbështesim ruajtjen afatgjatë të metrikës." Kjo nuk është detyra e tyre. 
Ne shkruajmë në një copë letre që ende duhet ta shkarkojmë jashtë, në mënyrë që të mos ruajmë gjithçka në një vend.
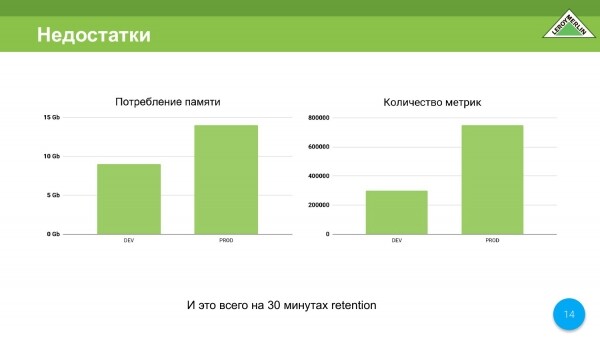
E meta e dytë është konsumi i kujtesës. Po, e kuptoj që shumë do të thonë që në vitin 2020 nja dy gigabajt memorie kushtojnë një qindarkë, por gjithsesi.
Tani ne kemi një mjedis dev dhe prod. Në dev është rreth 9 gigabajt për 350 metrikë. Në produkt është 000 gigabajt dhe pak më shumë se 14 metrikë. Në të njëjtën kohë, koha jonë e mbajtjes është vetëm 780 minuta. Kjo është e keqe. Dhe tani do të shpjegoj pse.
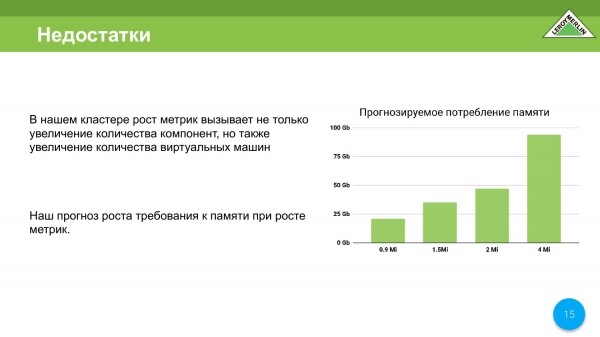
Ne bëjmë një llogaritje, domethënë me një milion e gjysmë metrikë, dhe tashmë jemi afër tyre, në fazën e projektimit marrim 35-37 gigabajt memorie. Por tashmë 4 milionë metrikë kërkojnë rreth 90 gigabajt memorie. Kjo do të thotë, ajo u llogarit duke përdorur formulën e dhënë nga zhvilluesit e Prometheus. Ne shikuam korrelacionin dhe kuptuam se nuk donim të paguanim nja dy milionë për një server vetëm për monitorim.
Ne jo vetëm që do të rrisim numrin e makinave, por po monitorojmë edhe vetë makinat virtuale. Prandaj, sa më shumë makina virtuale, aq më shumë metrika të llojeve të ndryshme, etj. Do të kemi një rritje të veçantë të grupit tonë për sa i përket metrikës.
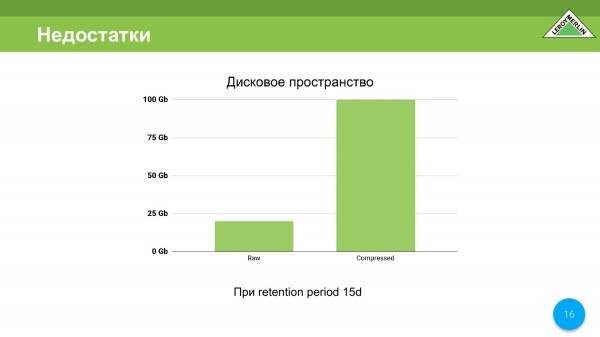
Me hapësirën në disk, jo gjithçka është aq e keqe këtu, por do të doja ta përmirësoja. Ne kemi marrë gjithsej 15 gigabajt në 120 ditë, nga të cilat 100 janë të dhëna të ngjeshura, 20 janë të dhëna të pakompresuara, por gjithmonë duam më pak.

Prandaj, ne shkruajmë një pikë tjetër - ky është një konsum i madh i burimeve, të cilin ne ende duam ta kursejmë, sepse nuk duam që grupi ynë i monitorimit të konsumojë më shumë burime sesa grupi ynë, i cili menaxhon OpenStack.

Ekziston edhe një pengesë tjetër e Prometeut, të cilën e kemi identifikuar vetë, ky është të paktën një lloj kufizimi i kujtesës. Me Prometheun, gjithçka është shumë më keq këtu, sepse nuk ka fare kthesa të tilla. Përdorimi i një kufiri në docker nuk është gjithashtu një opsion. Nëse papritmas RAF juaj ra dhe ka 20-30 gigabajt, atëherë do të duhet një kohë shumë e gjatë për t'u ngritur.

Kjo është një arsye tjetër pse Prometheus nuk është i përshtatshëm për ne, pra nuk mund të kufizojmë konsumin e kujtesës.
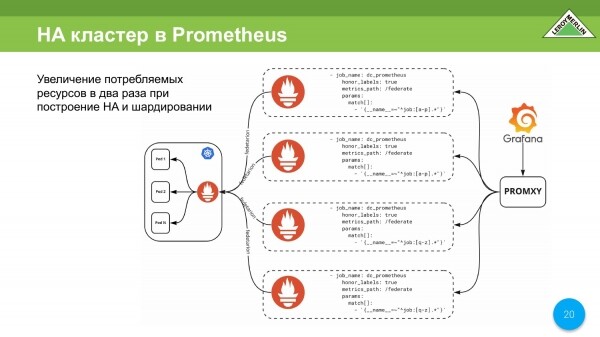
Do të ishte e mundur të dilte me një skemë të tillë. Ne kemi nevojë për këtë skemë për të organizuar një grup HA. Ne duam që metrikat tona të jenë të disponueshme gjithmonë dhe kudo, edhe nëse serveri që ruan këto metrika prishet. Dhe kështu do të na duhet të ndërtojmë një skemë të tillë.
Kjo skemë thotë se do të kemi dyfishim të copëzave, dhe rrjedhimisht, dyfishim të kostove të burimeve të konsumuara. Mund të shkallëzohet pothuajse horizontalisht, por megjithatë konsumi i burimeve do të jetë djallëzor.

Disavantazhet sipas rendit në formën në të cilën i kemi shkruar ato për veten tonë:
- Kërkon ngarkim të metrikës nga jashtë.
- Konsumi i lartë i burimeve.
- Nuk ka asnjë mënyrë për të kufizuar konsumin e kujtesës.
- Zbatimi kompleks dhe me burime intensive të HA.

Për veten tonë, vendosëm që të largoheshim nga Prometeu si një depo.
Ne kemi identifikuar kërkesa shtesë për veten tonë që na duhen. Kjo:
- Kjo është mbështetje promql, sepse shumë gjëra janë shkruar tashmë për Prometheun: pyetje, alarme.
- Dhe më pas kemi Grafanën, e cila tashmë është shkruar pikërisht në të njëjtën mënyrë për Prometheun si një fund. Nuk dua të rishkruaj panelet.
- Ne duam të ndërtojmë një arkitekturë normale HA.
- Ne duam të reduktojmë konsumin e çdo burimi.
- Ekziston një nuancë tjetër e vogël. Ne nuk mund të përdorim lloje të ndryshme të sistemeve të grumbullimit të metrikës së resë kompjuterike. Ne nuk e dimë ende se çfarë do të përfshihet në këto metrika. Dhe duke qenë se çdo gjë mund të fluturojë atje, ne duhet të kufizohemi në vendosjen lokale.

Kishte pak zgjedhje. Ne mblodhëm gjithçka që kishim përvojë. Ne shikuam faqen Prometheus në seksionin e integrimit, lexuam një sërë artikujsh dhe pamë se çfarë kishte atje. Dhe për veten tonë, ne zgjodhëm VictoriaMetrics si një zëvendësim për Prometheus.
Pse? Sepse:
- Mund të bëjë promql.
- Ekziston një arkitekturë modulare.
- Nuk kërkon ndryshime në Grafana.
- Dhe më e rëndësishmja, ne ndoshta do të ofrojmë ruajtjen e metrikës brenda kompanisë sonë si një shërbim, kështu që ne po shikojmë paraprakisht drejt kufizimeve të llojeve të ndryshme në mënyrë që përdoruesit të mund të përdorin të gjitha burimet e grupit në një mënyrë të kufizuar, sepse ka një shans se ajo do të shumëfishtë.
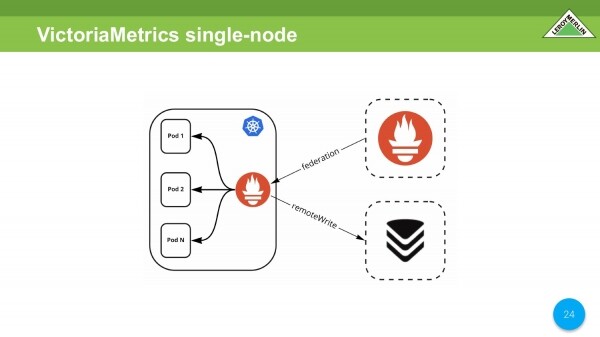
Le të bëjmë krahasimin e parë. Ne marrim të njëjtin Prometheus brenda grupit, Prometeu i jashtëm shkon tek ai. Shto me anë të telekomandësWrite VictoriaMetrics.
Do të bëj menjëherë një rezervim që këtu kemi kapur një rritje të lehtë të konsumit të CPU nga VictoriaMetrics. Wiki VictoriaMetrics ju tregon se cilët parametra janë më të mirët. Ne i kontrolluam ato. Ata kanë ulur shumë mirë konsumin e CPU-së.
Në rastin tonë, konsumi i kujtesës i Prometheus, i cili ndodhet në grupin Kubernetes, nuk u rrit ndjeshëm.
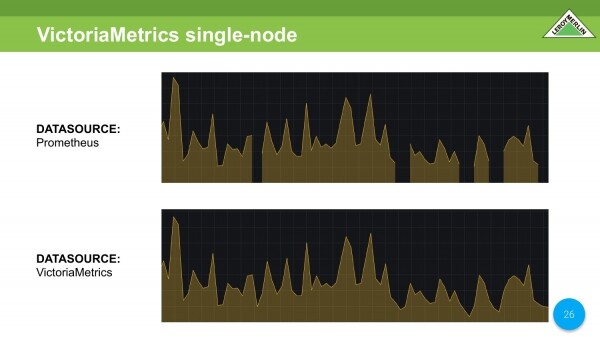
Ne krahasojmë dy burime të dhënash të të njëjtave të dhëna. Te Prometeu shohim të njëjtat të dhëna që mungojnë. Gjithçka është në rregull në VictoriaMetrics.

Rezultatet e testit të hapësirës në disk. Ne në Prometheus morëm gjithsej 120 gigabajt. Në VictoriaMetrics ne marrim tashmë 4 gigabajt në ditë. Ekziston një mekanizëm pak më ndryshe nga ai që jemi mësuar të shohim te Prometeu. Kjo do të thotë, të dhënat tashmë janë ngjeshur mjaft mirë në një ditë, në gjysmë ore. Ata tashmë janë korrur mirë në një ditë, në gjysmë ore, pavarësisht se të dhënat do të humbasin akoma më vonë. Si rezultat, ne kemi kursyer hapësirën në disk.
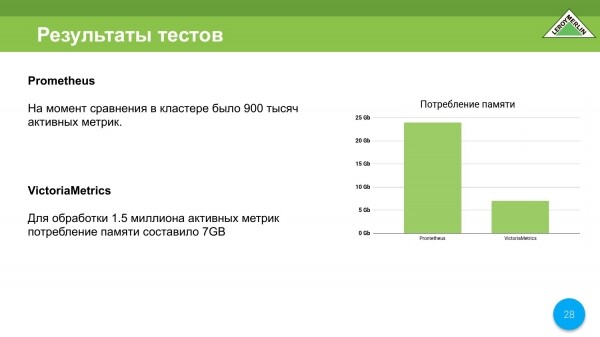
Ne gjithashtu kursejmë në konsumin e burimeve të kujtesës. Në kohën e testimit, ne kishim Prometheus të vendosur në një makinë virtuale - 8 bërthama, 24 gigabajt. Prometeu ha pothuajse gjithçka. Ai ra mbi OOM Killer. Në të njëjtën kohë, vetëm 900 metrikë aktive u derdhën në të. Kjo është rreth 000-25 metrikë në sekondë.
Ne ekzekutuam VictoriaMetrics në një makinë virtuale me dy bërthama me 8 gigabajt RAM. Ne ia dolëm që VictoriaMetrics të funksiononte mirë duke u përpunuar me disa gjëra në një makinë 8 GB. Në fund e mbajtëm në 7 gigabajt. Në të njëjtën kohë, shpejtësia e shpërndarjes së përmbajtjes, pra metrikës, ishte edhe më e lartë se ajo e Prometeut.
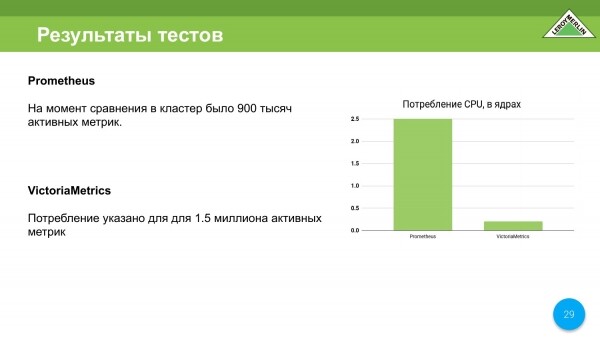
CPU është bërë shumë më i mirë në krahasim me Prometheus. Këtu Prometheus konsumon 2,5 bërthama, dhe VictoriaMetrics konsumon vetëm 0,25 bërthama. Në fillim - 0,5 bërthama. Ndërsa bashkohet, arrin një bërthamë, por kjo është jashtëzakonisht, jashtëzakonisht e rrallë.
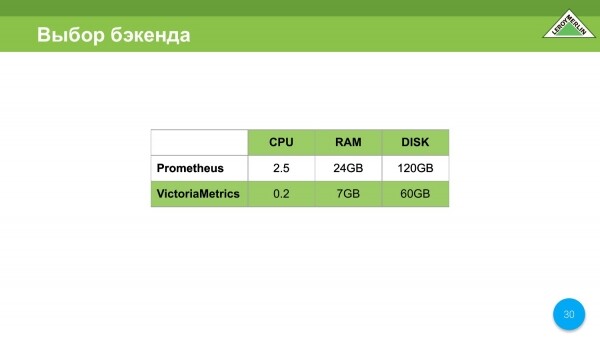
Në rastin tonë, zgjedhja ra në VictoriaMetrics për arsye të dukshme; ne donim të kursenim para dhe e bëmë.

Le të kalojmë menjëherë dy pika - ngarkimin e metrikës dhe konsumin e lartë të burimeve. Dhe ne vetëm duhet të vendosim dy pika që na kanë mbetur ende për vete.

Këtu do të bëj një rezervim menjëherë, ne e konsiderojmë VictoriaMetrics si një ruajtje të metrikës. Por meqenëse ka shumë të ngjarë të ofrojmë VictoriaMetrics si ruajtje për të gjithë Leroy, duhet të kufizojmë ata që do ta përdorin këtë grup në mënyrë që të mos na e japin atë.
Ekziston një parametër i mrekullueshëm që ju lejon të kufizoni sipas kohës, vëllimit të të dhënave dhe kohës së ekzekutimit.
Ekziston gjithashtu një opsion i shkëlqyeshëm që na lejon të kufizojmë konsumin e kujtesës, në këtë mënyrë ne mund të gjejmë vetë ekuilibrin që do të na lejojë të marrim shpejtësinë normale të funksionimit dhe konsumin e duhur të burimeve.

Minus një pikë më shumë, domethënë kaloni pikën - nuk mund të kufizoni konsumin e kujtesës.
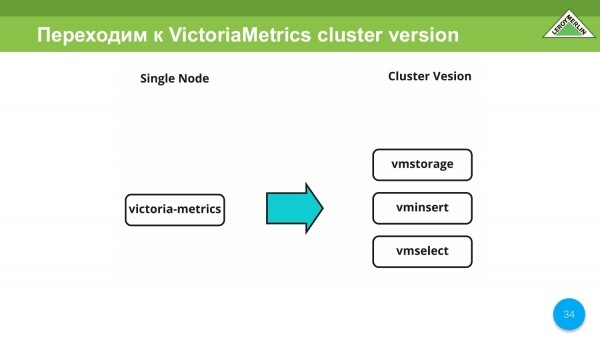
Në përsëritjet e para, ne testuam VictoriaMetrics Single Node. Më pas kalojmë te versioni i grupit VictoriaMetrics.
Këtu kemi një dorë të lirë për të ndarë shërbime të ndryshme në VictoriaMetrics në varësi të asaj me çfarë do të funksionojnë dhe çfarë burimesh do të konsumojnë. Kjo është një zgjidhje shumë fleksibël dhe e përshtatshme. Ne e kemi përdorur këtë për veten tonë.
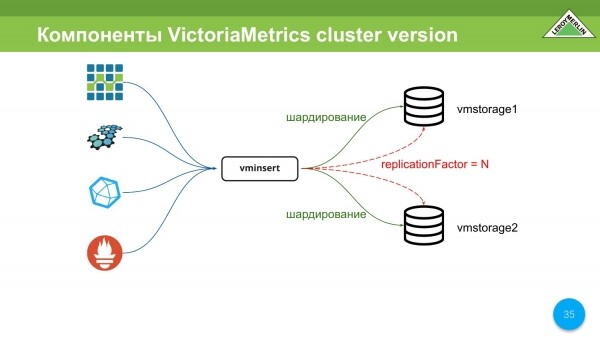
Përbërësit kryesorë të versionit VictoriaMetrics Cluster janë vmstsorage. Mund të ketë N numër prej tyre. Në rastin tonë janë 2 prej tyre deri më tani.
Dhe ka vminsert. Ky është një server proxy që na lejon: të organizojmë ndarjen midis të gjitha ruajtjeve për të cilat i thamë, dhe gjithashtu lejon një kopje, d.m.th. do të keni edhe ndarjen dhe një kopje.
Vminsert mbështet protokollet OpenTSDB, Graphite, InfluxDB dhe remoteWrite nga Prometheus.
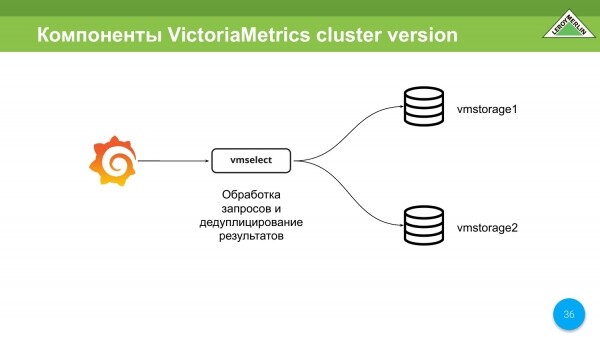
Ekziston edhe vmselect. Detyra e tij kryesore është të shkojë në vmstorage, të marrë të dhëna prej tyre, të fshijë këto të dhëna dhe t'ia japë klientit.
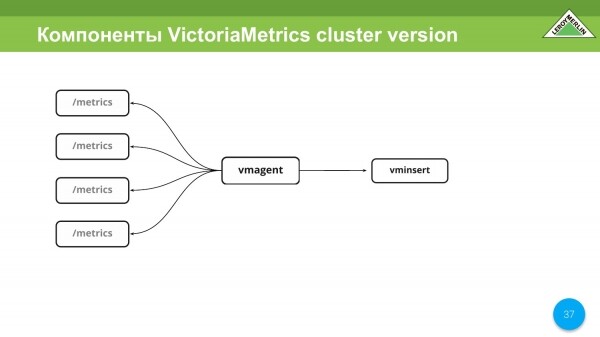
Ekziston një gjë e mrekullueshme që quhet vmagent. Ajo na pëlqen vërtet. Kjo ju lejon të konfiguroni saktësisht si Prometheus dhe ende të bëni gjithçka saktësisht si Prometheus. Kjo do të thotë, ai mbledh metrikë nga entitete dhe shërbime të ndryshme dhe i dërgon ato në vminsert. Atëherë gjithçka varet nga ju.
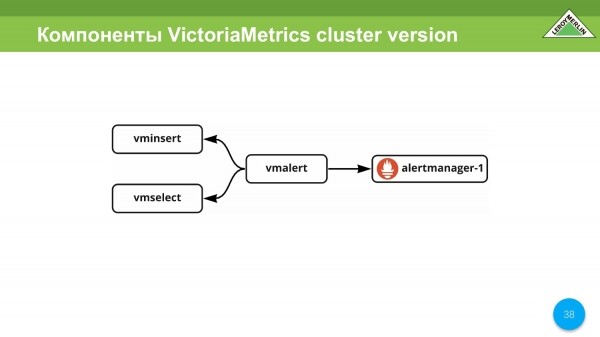
Një tjetër shërbim i shkëlqyer është vmalert, i cili ju lejon të përdorni VictoriaMetrics si një backend, të merrni të dhëna të përpunuara nga vminsert dhe t'i dërgoni ato në vmselect. Ai përpunon vetë sinjalizimet, si dhe rregullat. Në rastin e sinjalizimeve, ne e marrim sinjalizimin përmes alertmanager.
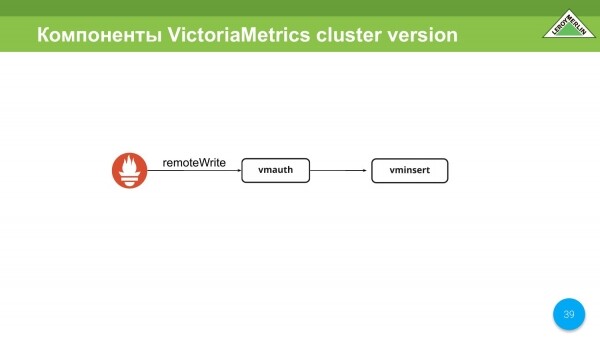
Ekziston një komponent wmauth. Ne mund ose jo (nuk kemi vendosur ende për këtë) ta përdorim atë si një sistem autorizimi për versionin me shumë qira të grupimeve. Ai mbështet remoteWrite për Prometheus dhe mund të autorizojë në bazë të url-së, ose më saktë në pjesën e dytë të saj, ku mund ose nuk mund të shkruani.
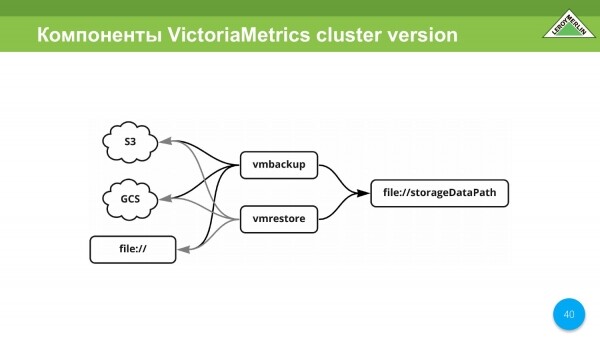
Ekziston edhe vmbackup, vmrestore. Ky është, në thelb, restaurimi dhe kopjimi i të gjitha të dhënave. Mund të bëjë skedarë S3, GCS.
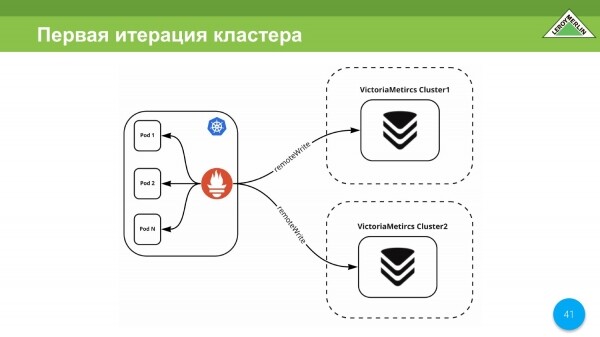
Përsëritja e parë e grupit tonë u bë gjatë karantinës. Në atë kohë, nuk kishte asnjë kopje, kështu që përsëritja jonë përbëhej nga dy grupime të ndryshme dhe të pavarura në të cilat merrnim të dhëna përmes remoteWrite.
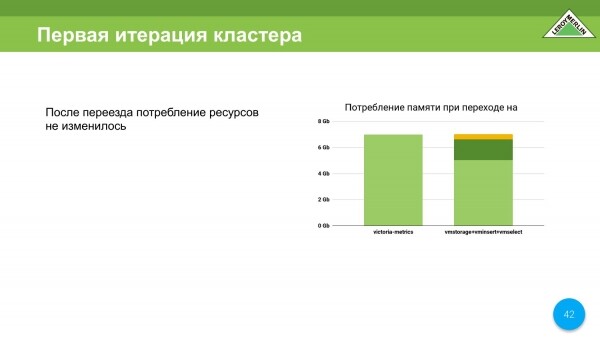
Këtu do të bëj një rezervim që kur kaluam nga VictoriaMetrics Single Node në VictoriaMetrics Cluster Version, ne mbetëm me të njëjtat burime të konsumuara, pra kryesorja është memoria. Kështu janë shpërndarë afërsisht të dhënat tona, pra konsumi i burimeve.
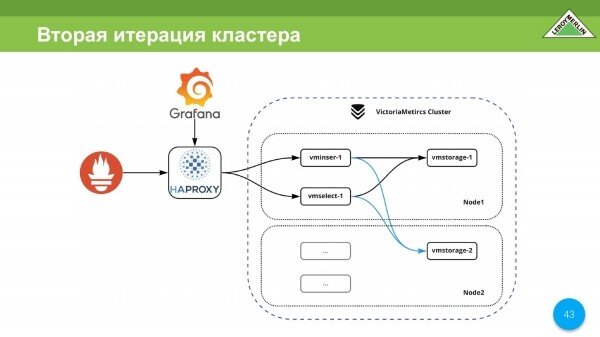
Këtu tashmë është shtuar një kopje. Ne i kombinuam të gjitha këto në një grup relativisht të madh. Të gjitha të dhënat tona janë të copëtuara dhe të përsëritura.
I gjithë grupi ka N pika hyrje, që do të thotë Prometheus mund të shtojë të dhëna nëpërmjet HAPROXY. Këtu kemi këtë pikë hyrëse. Dhe përmes kësaj pike hyrëse mund të identifikoheni nga Grafana.
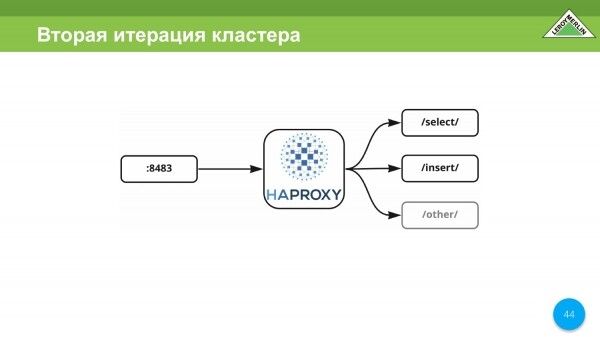
Në rastin tonë, HAPROXY është porti i vetëm që proxy-et zgjedhin, futin dhe shërbime të tjera brenda këtij grupi. Në rastin tonë, ishte e pamundur të bënim një adresë; ne duhej të bënim disa pika hyrjeje, sepse vetë makinat virtuale në të cilat funksionon grupi VictoriaMetrics ndodhen në zona të ndryshme të të njëjtit ofrues të resë kompjuterike, d.m.th. jo brenda resë sonë, por jashtë. .
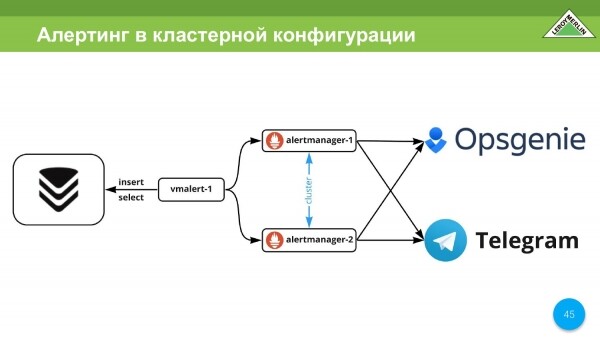
Ne kemi alarm. Ne e përdorim atë. Ne përdorim alertmanager nga Prometheus. Ne përdorim Opsgenie dhe Telegram si një kanal shpërndarjeje alarmi. Në Telegram ato derdhen nga dev, ndoshta diçka nga prod, por kryesisht diçka statistikore, e nevojshme nga inxhinierët. Dhe Opsgenie është kritike. Këto janë thirrje, menaxhim incidentesh.
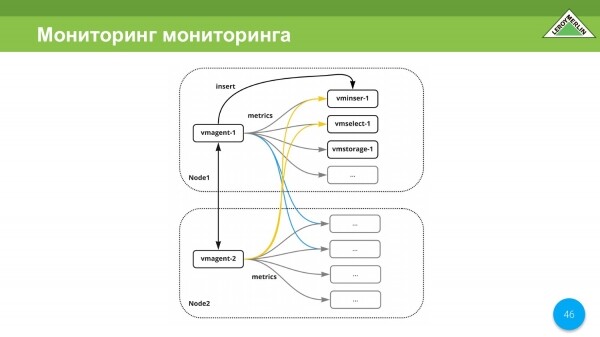
Pyetja e përjetshme: "Kush e monitoron monitorimin?" Në rastin tonë, monitorimi monitoron vetë monitorimin, sepse ne përdorim vmagent në secilën nyje. Dhe meqenëse nyjet tona shpërndahen nëpër qendra të ndryshme të të dhënave të të njëjtit ofrues, secila qendër e të dhënave ka kanalin e vet, ato janë të pavarura, dhe edhe nëse vjen një tru i ndarë, ne do të marrim ende sinjalizime. Po, do të ketë më shumë, por është më mirë të merrni më shumë sinjalizime sesa asnjë.

Ne e përfundojmë listën tonë me një zbatim të HA.

Dhe më tej do të doja të shënoja përvojën e komunikimit me komunitetin VictoriaMetrics. Doli shumë pozitive. Djemtë janë të përgjegjshëm. Ata përpiqen të thellohen në çdo rast që ofrohet.
Fillova problemet në GitHub. Ato u zgjidhën shumë shpejt. Janë edhe disa çështje të tjera që nuk janë mbyllur plotësisht, por tashmë nga kodi mund të shoh që puna në këtë drejtim është duke u zhvilluar.
Dhimbja kryesore për mua gjatë përsëritjeve ishte se nëse mbyllja një nyje, atëherë për 30 sekondat e para vminsert nuk mund të kuptonte se nuk kishte prapambetje. Kjo tani është vendosur. Dhe fjalë për fjalë në një ose dy sekondë, të dhënat merren nga të gjitha nyjet e mbetura, dhe kërkesa ndalon së prituri atë nyje që mungon.

Në një moment ne donim që VictoriaMetrics të ishte një operator VictoriaMetrics. Ne e prisnim atë. Tani po ndërtojmë në mënyrë aktive një kornizë për operatorin VictoriaMetrics për të marrë të gjitha rregullat e parallogaritjes, etj. Prometheus, sepse ne po përdorim mjaft aktivisht rregullat që vijnë me operatorin Prometheus.
Ka propozime për të përmirësuar zbatimin e grupimeve. I përshkrova më lart.
Dhe unë me të vërtetë dua të zvogëloj mostrën. Në rastin tonë, zvogëlimi i mostrave nevojitet ekskluzivisht për të parë tendencat. Përafërsisht, një metrikë më mjafton gjatë ditës. Këto tendenca duhen për një vit, tre, pesë, dhjetë vjet. Dhe një vlerë metrike është mjaft e mjaftueshme.
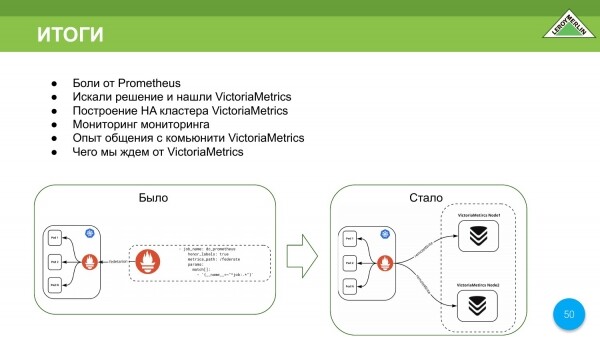
- Ne kemi njohur dhimbje, ashtu si disa nga kolegët tanë, kur përdorim Prometheus.
- Ne zgjodhëm VictoriaMetrics për veten tonë.
- Shkallohet mjaft mirë si vertikalisht ashtu edhe horizontalisht.
- Ne mund të shpërndajmë komponentë të ndryshëm në numër të ndryshëm nyjesh në grup, t'i kufizojmë ato sipas memories, të shtojmë memorie, etj.
Ne do të përdorim VictoriaMetrics në shtëpi sepse na pëlqeu shumë. Kjo është ajo që ishte dhe ajo që është bërë.

Disa kode QR për bisedën VictoriaMetrics, kontaktet e mia, radarin teknik LeroyMerlin.
Burimi: www.habr.com
