


Artikulli përshkruan se si të zbatohet WMS-sistem, u përballëm me nevojën për të zgjidhur një problem jo standard të grupimit dhe çfarë algoritmesh kemi përdorur për ta zgjidhur atë. Ne do t'ju tregojmë se si kemi aplikuar një qasje sistematike, shkencore për zgjidhjen e problemit, çfarë vështirësish kemi hasur dhe çfarë mësimesh kemi nxjerrë.
Ky publikim fillon një seri artikujsh në të cilët ne ndajmë përvojën tonë të suksesshme në zbatimin e algoritmeve të optimizimit në proceset e magazinës. Qëllimi i serisë së artikujve është të njohë audiencën me llojet e problemeve të optimizimit të operacioneve të magazinës që lindin pothuajse në çdo depo të mesme dhe të madhe, si dhe të tregojë për përvojën tonë në zgjidhjen e problemeve të tilla dhe kurthet e hasura gjatë rrugës. . Artikujt do të jenë të dobishëm për ata që punojnë në industrinë e logjistikës së depove, zbatojnë WMS-sistemet, si dhe programuesit që janë të interesuar për aplikimet e matematikës në biznes dhe optimizimin e proceseve në një ndërmarrje.
Ngushtim në procese
Në vitin 2018 kemi përfunduar një projekt për t'u zbatuar WMS- sistemet në depon e kompanisë "Trading House "LD" në Chelyabinsk. Ne implementuam produktin "1C-Logistics: Warehouse Management 3" për 20 vende pune: operatorë WMS, magazinierë, shoferë kamionçinë. Magazina mesatare është rreth 4 mijë m2, numri i qelive është 5000 dhe numri i SKU-ve është 4500. Magazina ruan valvola topi të prodhimit tonë të madhësive të ndryshme nga 1 kg deri në 400 kg. Inventari në magazinë ruhet në tufa, pasi ekziston nevoja për të zgjedhur mallrat sipas FIFO.
Gjatë projektimit të skemave të automatizimit të procesit të magazinës, ne u përballëm me problemin ekzistues të ruajtjes jo optimale të inventarit. Specifikat e ruajtjes dhe vendosjes së vinçave janë të tilla që një qelizë magazinimi njësi mund të përmbajë vetëm artikuj nga një grumbull. Produktet mbërrijnë në magazinë çdo ditë dhe çdo mbërritje është një grup i veçantë. Në total, si rezultat i funksionimit 1 mujor të magazinës, krijohen 30 tufa të veçanta, pavarësisht se secila duhet të ruhet në një qeli të veçantë. Produktet shpesh përzgjidhen jo në paleta të tëra, por në copa, dhe si rezultat, në zonën e përzgjedhjes së pjesëve në shumë qeliza vërehet fotografia e mëposhtme: në një qeli me vëllim më shumë se 1 m3 ka disa copa vinçash që zënë më pak se 5-10% të vëllimit të qelizës.
 Fig 1. Foto e disa pjesëve të mallrave në një qeli
Fig 1. Foto e disa pjesëve të mallrave në një qeli
Është e qartë se kapaciteti i ruajtjes nuk po përdoret në mënyrë optimale. Për të imagjinuar shkallën e fatkeqësisë, mund të jap shifra: mesatarisht, ka nga 1 deri në 3 qeliza të tilla me një vëllim më shumë se 100 m300 me ekuilibra "të vegjël" gjatë periudhave të ndryshme të funksionimit të magazinës. Meqenëse magazina është relativisht e vogël, gjatë sezoneve të ngarkuara të magazinës ky faktor bëhet një "blloqe" dhe ngadalëson shumë proceset e magazinës.
Ideja e zgjidhjes së problemit
Lindi një ide: grupet e mbetjeve me datat më të afërta duhet të reduktohen në një grumbull të vetëm dhe mbetjet e tilla me një grumbull të unifikuar duhet të vendosen kompakt së bashku në një qelizë, ose në disa, nëse nuk ka hapësirë të mjaftueshme në një për të akomoduar të gjithë sasinë e mbetjeve.
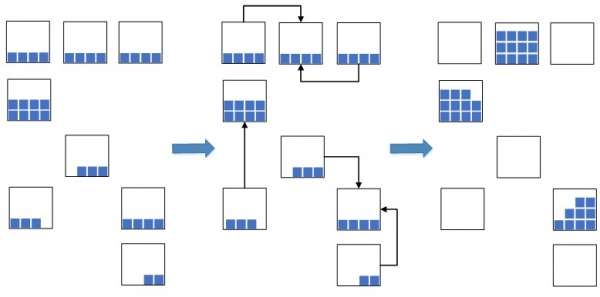
Fig.2. Skema për ngjeshjen e mbetjeve në qeliza
Kjo ju lejon të reduktoni ndjeshëm hapësirën e zënë të magazinës që do të përdoret për vendosjen e mallrave të reja. Në një situatë ku kapaciteti i magazinës është i mbingarkuar, një masë e tillë është jashtëzakonisht e nevojshme, përndryshe thjesht mund të mos ketë hapësirë të lirë të mjaftueshme për të akomoduar mallra të reja, gjë që do të çojë në ndalimin e proceseve të vendosjes dhe rimbushjes së magazinës. Më parë përpara zbatimit WMS-Sistemet e kryen këtë operacion me dorë, i cili ishte joefektiv, pasi procesi i kërkimit të mbetjeve të përshtatshme në qeliza ishte mjaft i gjatë. Tani, me prezantimin e një sistemi WMS, vendosëm të automatizojmë procesin, ta përshpejtojmë dhe ta bëjmë atë inteligjent.
Procesi i zgjidhjes së një problemi të tillë ndahet në 2 faza:
- në fazën e parë gjejmë grupe tufash afër datës së kompresimit;
- në fazën e dytë, për secilin grup tufash llogarisim vendosjen më kompakte të mallrave të mbetur në qeliza.
Në artikullin aktual do të fokusohemi në fazën e parë të algoritmit dhe do ta lëmë mbulimin e fazës së dytë për artikullin tjetër.
Kërkoni për një model matematikor të problemit
Përpara se të uleshim të shkruanim kodin dhe të rishpiknim rrotën tonë, vendosëm t'i qasemi shkencërisht këtij problemi, domethënë: ta formulojmë atë matematikisht, ta reduktojmë në një problem të mirënjohur optimizimi diskret dhe të përdorim algoritme ekzistuese efektive për ta zgjidhur atë, ose të marrim këto algoritme ekzistuese. si bazë dhe t'i modifikojë ato në specifikat e problemit praktik që zgjidhet.
Duke qenë se nga formulimi i biznesit të problemit del qartë se kemi të bëjmë me bashkësi, një problem të tillë do ta formulojmë në aspektin e teorisë së bashkësive.
Le të  – grupi i të gjitha grupeve të mbetjes së një produkti të caktuar në një magazinë. Le
– grupi i të gjitha grupeve të mbetjes së një produkti të caktuar në një magazinë. Le  – jepet konstanta e ditëve. Le
– jepet konstanta e ditëve. Le  – një nëngrup grupesh, ku diferenca në data për të gjitha palët e grupeve në nëngrup nuk kalon një konstante
– një nëngrup grupesh, ku diferenca në data për të gjitha palët e grupeve në nëngrup nuk kalon një konstante  . Duhet të gjejmë numrin minimal të nëngrupeve të shkëputura
. Duhet të gjejmë numrin minimal të nëngrupeve të shkëputura  , i tillë që të gjitha nëngrupet
, i tillë që të gjitha nëngrupet  të marra së bashku do të jepnin shumë
të marra së bashku do të jepnin shumë  .
.
Me fjalë të tjera, ne duhet të gjejmë grupe ose grupime partish të ngjashme, ku kriteri i ngjashmërisë përcaktohet nga konstantja  . Kjo detyrë na kujton problemin e njohur të grupimit. Është e rëndësishme të thuhet se problemi në shqyrtim ndryshon nga problemi i grupimit në atë që problemi ynë ka një kusht të përcaktuar rreptësisht për kriterin e ngjashmërisë së elementeve të grupimit, të përcaktuar nga konstantja
. Kjo detyrë na kujton problemin e njohur të grupimit. Është e rëndësishme të thuhet se problemi në shqyrtim ndryshon nga problemi i grupimit në atë që problemi ynë ka një kusht të përcaktuar rreptësisht për kriterin e ngjashmërisë së elementeve të grupimit, të përcaktuar nga konstantja  , por në problemin e grupimit nuk ekziston një kusht i tillë. Deklarata e problemit të grupimit dhe informacioni mbi këtë problem mund të gjenden
, por në problemin e grupimit nuk ekziston një kusht i tillë. Deklarata e problemit të grupimit dhe informacioni mbi këtë problem mund të gjenden
Pra, arritëm të formulojmë problemin dhe të gjejmë një problem klasik me një formulim të ngjashëm. Tani është e nevojshme të merren parasysh algoritme të njohura për zgjidhjen e tij, në mënyrë që të mos rishpikni timonin, por të merrni praktikat më të mira dhe t'i zbatoni ato. Për të zgjidhur problemin e grupimit, ne konsideruam algoritmet më të njohura, përkatësisht:  -do të thotë
-do të thotë  -mjetet, algoritmi për identifikimin e komponentëve të lidhur, algoritmi i pemës me shtrirje minimale. Mund të gjendet një përshkrim dhe analizë e algoritmeve të tilla
-mjetet, algoritmi për identifikimin e komponentëve të lidhur, algoritmi i pemës me shtrirje minimale. Mund të gjendet një përshkrim dhe analizë e algoritmeve të tilla
Për të zgjidhur problemin tonë, algoritmet e grupimit  -do të thotë dhe
-do të thotë dhe  - mjetet nuk janë fare të zbatueshme, pasi numri i grupimeve nuk dihet kurrë paraprakisht
- mjetet nuk janë fare të zbatueshme, pasi numri i grupimeve nuk dihet kurrë paraprakisht  dhe algoritme të tilla nuk marrin parasysh kufizimin e ditëve konstante. Algoritme të tilla fillimisht u hoqën nga shqyrtimi.
dhe algoritme të tilla nuk marrin parasysh kufizimin e ditëve konstante. Algoritme të tilla fillimisht u hoqën nga shqyrtimi.
Për të zgjidhur problemin tonë, algoritmi për identifikimin e komponentëve të lidhur dhe algoritmi i pemës së shtrirjes minimale janë më të përshtatshme, por, siç doli, ato nuk mund të zbatohen "kokë më parë" për problemin që zgjidhet dhe të marrin një zgjidhje të mirë. Për ta shpjeguar këtë, le të shqyrtojmë logjikën e funksionimit të algoritmeve të tilla në lidhje me problemin tonë.
Merrni parasysh grafikun  , në të cilën kulmet janë bashkësia e palëve
, në të cilën kulmet janë bashkësia e palëve  , dhe skaji midis kulmeve
, dhe skaji midis kulmeve  и
и  ka një peshë të barabartë me diferencën e ditëve ndërmjet tufave
ka një peshë të barabartë me diferencën e ditëve ndërmjet tufave  и
и  . Në algoritmin për identifikimin e komponentëve të lidhur, specifikohet parametri i hyrjes
. Në algoritmin për identifikimin e komponentëve të lidhur, specifikohet parametri i hyrjes  Ku
Ku  , dhe në grafik
, dhe në grafik  hiqen të gjitha skajet për të cilat pesha është më e madhe
hiqen të gjitha skajet për të cilat pesha është më e madhe  . Vetëm çiftet më të afërta të objekteve mbeten të lidhura. Qëllimi i algoritmit është të zgjedhë një vlerë të tillë
. Vetëm çiftet më të afërta të objekteve mbeten të lidhura. Qëllimi i algoritmit është të zgjedhë një vlerë të tillë  , në të cilin grafiku "shpëtohet" në disa komponentë të lidhur, ku palët që i përkasin këtyre komponentëve do të plotësojnë kriterin tonë të ngjashmërisë, të përcaktuar nga konstantja
, në të cilin grafiku "shpëtohet" në disa komponentë të lidhur, ku palët që i përkasin këtyre komponentëve do të plotësojnë kriterin tonë të ngjashmërisë, të përcaktuar nga konstantja  . Komponentët që rezultojnë janë grupime.
. Komponentët që rezultojnë janë grupime.
Algoritmi i pemës me shtrirje minimale fillimisht bazohet në një grafik  pema me shtrirje minimale, dhe më pas heq në mënyrë sekuenciale skajet me peshën më të madhe derisa grafiku të "shkëputet" në disa komponentë të lidhur, ku palët që u përkasin këtyre komponentëve do të plotësojnë gjithashtu kriterin tonë të ngjashmërisë. Komponentët që rezultojnë do të jenë grupime.
pema me shtrirje minimale, dhe më pas heq në mënyrë sekuenciale skajet me peshën më të madhe derisa grafiku të "shkëputet" në disa komponentë të lidhur, ku palët që u përkasin këtyre komponentëve do të plotësojnë gjithashtu kriterin tonë të ngjashmërisë. Komponentët që rezultojnë do të jenë grupime.
Kur përdorni algoritme të tilla për të zgjidhur problemin në shqyrtim, mund të lindë një situatë si në Figurën 3.
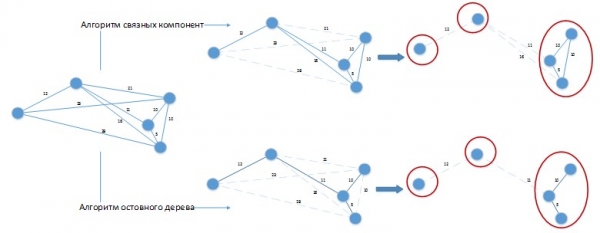
Fig 3. Zbatimi i algoritmeve të grupimit në problemin që zgjidhet
Le të themi se konstanta jonë për diferencën midis ditëve të grupit është 20 ditë. Grafiku  u përshkrua në formë hapësinore për lehtësinë e perceptimit vizual. Të dy algoritmet prodhuan një zgjidhje me 3 grupe, e cila mund të përmirësohet lehtësisht duke kombinuar grupet e vendosura në grupe të veçanta me njëra-tjetrën! Është e qartë se algoritme të tilla duhet të modifikohen për t'iu përshtatur specifikave të problemit që zgjidhet dhe aplikimi i tyre në formën e tij të pastër për zgjidhjen e problemit tonë do të japë rezultate të dobëta.
u përshkrua në formë hapësinore për lehtësinë e perceptimit vizual. Të dy algoritmet prodhuan një zgjidhje me 3 grupe, e cila mund të përmirësohet lehtësisht duke kombinuar grupet e vendosura në grupe të veçanta me njëra-tjetrën! Është e qartë se algoritme të tilla duhet të modifikohen për t'iu përshtatur specifikave të problemit që zgjidhet dhe aplikimi i tyre në formën e tij të pastër për zgjidhjen e problemit tonë do të japë rezultate të dobëta.

Pra, përpara se të fillonim të shkruanim kodin për algoritmet e grafikut të modifikuar për detyrën tonë dhe të rishpiknim biçikletën tonë (në siluetat e së cilës tashmë mund të dallonim skicat e rrotave katrore), ne, përsëri, vendosëm t'i qasemi shkencërisht një problemi të tillë, domethënë: përpiquni ta reduktoni atë në një optimizim tjetër diskret të problemit, me shpresën se algoritmet ekzistuese për zgjidhjen e tij mund të aplikohen pa modifikime.
Një kërkim tjetër për një problem të ngjashëm klasik ka qenë i suksesshëm! Ne arritëm të gjenim një problem diskret optimizimi, formulimi i të cilit përkon 1 në 1 me formulimin e problemit tonë. Kjo detyrë doli të ishte problemi i mbulimit të vendosur. Le të paraqesim formulimin e problemit në lidhje me specifikat tona.
Ekziston një grup i kufizuar  dhe FAMILJA
dhe FAMILJA  e të gjitha nëngrupeve të saj të pandara të palëve, të tilla që diferenca në data për të gjitha palët e çdo nëngrupi
e të gjitha nëngrupeve të saj të pandara të palëve, të tilla që diferenca në data për të gjitha palët e çdo nëngrupi  nga familja
nga familja  nuk i kalon konstantet
nuk i kalon konstantet  . Mbulesa quhet familje
. Mbulesa quhet familje  të fuqisë më të vogël, elementet e së cilës i përkasin
të fuqisë më të vogël, elementet e së cilës i përkasin  , i tillë që bashkimi i bashkësive
, i tillë që bashkimi i bashkësive  nga familja
nga familja  duhet të japë grupin e të gjitha palëve
duhet të japë grupin e të gjitha palëve  .
.
Mund të gjendet një analizë e hollësishme e këtij problemi и Mund të gjenden opsione të tjera për zbatimin praktik të problemit të mbulimit dhe modifikimet e tij
Algoritmi për zgjidhjen e problemit
Ne kemi vendosur për modelin matematikor të problemit që do të zgjidhet. Tani le të shohim algoritmin për zgjidhjen e tij. Nëngrupet  nga familja
nga familja  mund të gjendet lehtësisht me procedurën e mëposhtme.
mund të gjendet lehtësisht me procedurën e mëposhtme.
- Organizoni tufa nga një grup
 në rend zbritës të datave të tyre.
në rend zbritës të datave të tyre. - Gjeni datat minimale dhe maksimale të grumbullimit.
- Për çdo ditë nga data minimale në maksimum, gjeni të gjitha grupet, datat e të cilave ndryshojnë jo me shume se (pra vlera Është më mirë të marrësh numrin çift).
 në rend zbritës të datave të tyre.
në rend zbritës të datave të tyre. nga data minimale në maksimum, gjeni të gjitha grupet, datat e të cilave ndryshojnë
nga data minimale në maksimum, gjeni të gjitha grupet, datat e të cilave ndryshojnë  jo me shume se
jo me shume se  (pra vlera
(pra vlera  Është më mirë të marrësh numrin çift).
Është më mirë të marrësh numrin çift). Logjika e procedurës për formimin e një familjeje grupesh  при
при  ditët janë paraqitur në figurën 4.
ditët janë paraqitur në figurën 4.

Fig.4. Formimi i nëngrupeve të partive
Kjo procedurë nuk është e nevojshme për të gjithë  kaloni nëpër të gjitha grupet e tjera dhe kontrolloni ndryshimin në datat e tyre, ose nga vlera aktuale
kaloni nëpër të gjitha grupet e tjera dhe kontrolloni ndryshimin në datat e tyre, ose nga vlera aktuale  lëvizni majtas ose djathtas derisa të gjeni një grup data e së cilës është e ndryshme nga
lëvizni majtas ose djathtas derisa të gjeni një grup data e së cilës është e ndryshme nga  me më shumë se gjysmën e vlerës së konstantës. Të gjithë elementët pasues, kur lëvizin djathtas dhe majtas, nuk do të jenë interesantë për ne, pasi për ta ndryshimi në ditë vetëm do të rritet, pasi elementët në grup fillimisht u renditën. Kjo qasje do të kursejë ndjeshëm kohë kur numri i partive dhe përhapja e datave të tyre janë dukshëm të mëdha.
me më shumë se gjysmën e vlerës së konstantës. Të gjithë elementët pasues, kur lëvizin djathtas dhe majtas, nuk do të jenë interesantë për ne, pasi për ta ndryshimi në ditë vetëm do të rritet, pasi elementët në grup fillimisht u renditën. Kjo qasje do të kursejë ndjeshëm kohë kur numri i partive dhe përhapja e datave të tyre janë dukshëm të mëdha.
Problemi i mbulimit të grupit është  -vështirë, që do të thotë se nuk ka algoritëm të shpejtë (me kohë funksionimi të barabartë me një polinom të të dhënave hyrëse) dhe të saktë për zgjidhjen e tij. Prandaj, për të zgjidhur problemin e mbulimit të grupit, u zgjodh një algoritëm i shpejtë i babëzitur, i cili, natyrisht, nuk është i saktë, por ka avantazhet e mëposhtme:
-vështirë, që do të thotë se nuk ka algoritëm të shpejtë (me kohë funksionimi të barabartë me një polinom të të dhënave hyrëse) dhe të saktë për zgjidhjen e tij. Prandaj, për të zgjidhur problemin e mbulimit të grupit, u zgjodh një algoritëm i shpejtë i babëzitur, i cili, natyrisht, nuk është i saktë, por ka avantazhet e mëposhtme:
- Për problemet me përmasa të vogla (dhe pikërisht ky është rasti ynë), ai llogarit zgjidhje që janë mjaft afër optimumit. Ndërsa madhësia e problemit rritet, cilësia e zgjidhjes përkeqësohet, por gjithsesi mjaft ngadalë;
- Shumë e lehtë për t'u zbatuar;
- I shpejtë, pasi vlerësimi i kohës së funksionimit të tij është .
 .
.Algoritmi i pangopur zgjedh grupe bazuar në rregullin e mëposhtëm: në çdo fazë, zgjidhet një grup që mbulon numrin maksimal të elementeve që nuk janë mbuluar ende. Mund të gjendet një përshkrim i detajuar i algoritmit dhe pseudokodit të tij
Nuk është bërë një krahasim i saktësisë së një algoritmi të tillë të babëzitur në të dhënat e testit të problemit që zgjidhet me algoritme të tjera të njohura, si algoritmi probabilist i babëzitur, algoritmi i kolonisë së milingonave, etj. Rezultatet e krahasimit të algoritmeve të tilla në të dhëna të rastësishme të krijuara mund të gjenden
Zbatimi dhe zbatimi i algoritmit
Ky algoritëm u implementua në gjuhë 1S dhe u përfshi në një përpunim të jashtëm të quajtur "Ngjeshja e mbetjeve" i cili ishte i lidhur me WMS-sistemi. Ne nuk e zbatuam algoritmin në gjuhë C ++ dhe përdorni atë nga një komponent i jashtëm Native, i cili do të ishte më i saktë, pasi shpejtësia e kodit është më e ulët C + + herë dhe në disa shembuj edhe dhjetëra herë më e shpejtë se shpejtësia e kodit të ngjashëm 1S. Në gjuhë 1S Algoritmi u zbatua për të kursyer kohën e zhvillimit dhe lehtësinë e korrigjimit në bazën e prodhimit të klientit. Rezultati i algoritmit është paraqitur në Figurën 5.
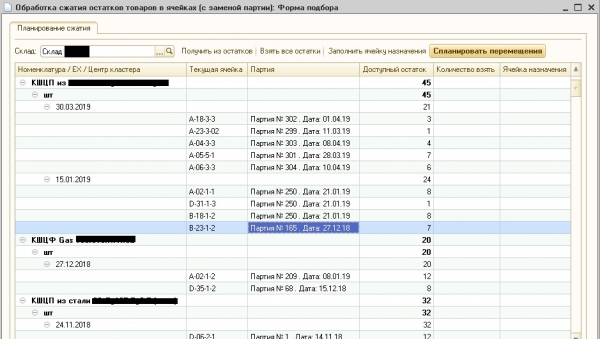
Fig.5. Përpunimi për të "kompresuar" mbetjet
Figura 5 tregon se në magazinën e specifikuar, bilancet aktuale të mallrave në qelitë e magazinimit ndahen në grupe, brenda të cilave datat e grupeve të mallrave ndryshojnë nga njëra-tjetra jo më shumë se 30 ditë. Meqenëse klienti prodhon dhe ruan valvulat metalike të topit në magazinë, jetëgjatësia e të cilave llogaritet në vite, një ndryshim i tillë datash mund të neglizhohet. Vini re se përpunimi i tillë aktualisht përdoret sistematikisht në prodhim dhe operatorë WMS konfirmojnë cilësinë e mirë të grupimit të partive.
Konkluzione dhe vazhdim
Përvoja kryesore që kemi fituar nga zgjidhja e një problemi të tillë praktik është konfirmimi i efektivitetit të përdorimit të paradigmës: matematika. deklaratë problemi  dyshek i famshëm. model
dyshek i famshëm. model  algoritmi i famshëm
algoritmi i famshëm  algoritmi duke marrë parasysh specifikat e problemit. Optimizimi diskret ka ekzistuar për më shumë se 300 vjet, dhe gjatë kësaj kohe njerëzit kanë arritur të marrin në konsideratë shumë probleme dhe të grumbullojnë shumë përvojë në zgjidhjen e tyre. Para së gjithash, është më e këshillueshme që t'i drejtoheni kësaj përvoje dhe vetëm atëherë të filloni të rishpikni timonin tuaj.
algoritmi duke marrë parasysh specifikat e problemit. Optimizimi diskret ka ekzistuar për më shumë se 300 vjet, dhe gjatë kësaj kohe njerëzit kanë arritur të marrin në konsideratë shumë probleme dhe të grumbullojnë shumë përvojë në zgjidhjen e tyre. Para së gjithash, është më e këshillueshme që t'i drejtoheni kësaj përvoje dhe vetëm atëherë të filloni të rishpikni timonin tuaj.
Në artikullin tjetër do të vazhdojmë historinë rreth algoritmeve të optimizimit dhe do të shohim më interesantet dhe shumë më komplekset: një algoritëm për "ngjeshjen" optimale të mbetjeve të qelizave, i cili përdor të dhënat e marra nga algoritmi i grumbullimit të grupeve si hyrje.
Përgatiti artikullin
Roman Shangin, programues i departamentit të projekteve,
Kompania e parë BIT, Chelyabinsk
Burimi: www.habr.com
