

В этой статье мы поговорим о функциональных зависимостях в базах данных — что это такое, где применяются и какие алгоритмы существуют для их поиска.
Рассматривать функциональные зависимости мы будем в контексте реляционных баз данных. Если говорить совсем грубо, то в таких базах данных информациях хранится в виде таблиц. Далее мы используем приближенные понятия, которые в строгой реляционной теории не являются взаимозаменяемыми: саму таблицу будем называть отношением, столбцы — атрибутами (их множество — схемой отношения), а набор значений строки на подмножестве атрибутов — кортежем.
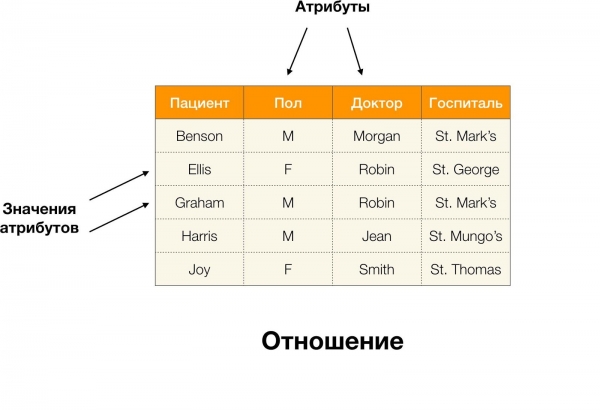
Например, в таблице выше, (Benson, M, M organ) является кортежем по атрибутам (Пациент, Пол, Доктор).
Более формально это записывается в следующем виде:  [Пациент, Пол, Доктор] = (Benson, M, M organ).
[Пациент, Пол, Доктор] = (Benson, M, M organ).
Теперь мы можем ввести понятие функциональной зависимости (ФЗ):
Определение 1. Отношение R удовлетворяет ФЗ X → Y (где X, Y ⊆ R) тогда и только тогда, когда для любых кортежей  ,
,  ∈ R выполняется: если
∈ R выполняется: если  [X] =
[X] =  [X], то
[X], то  [Y ] =
[Y ] =  [Y ]. В таком случае говорят, что X (детерминант, или определяющее множество атрибутов) функционально определяет Y (зависимое множество).
[Y ]. В таком случае говорят, что X (детерминант, или определяющее множество атрибутов) функционально определяет Y (зависимое множество).
Иными словами, наличие ФЗ X → Y означает, что если мы имеем два кортежа в R и они совпадают по атрибутам X, то они будут совпадать и по атрибутам Y.
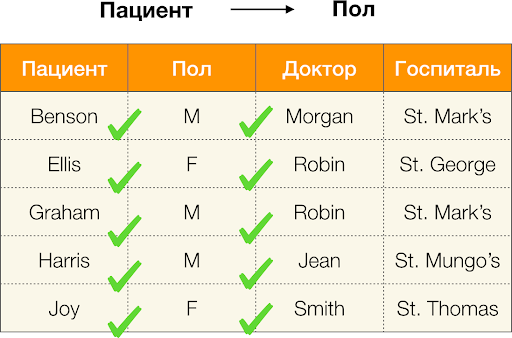
А теперь по порядку. Рассмотрим атрибуты Пациент dhe Пол для которых хотим узнать, есть ли между ними зависимости или нет. Для такого множества атрибутов могут существовать следующие зависимости:
- Пациент → Пол
- Пол → Пациент
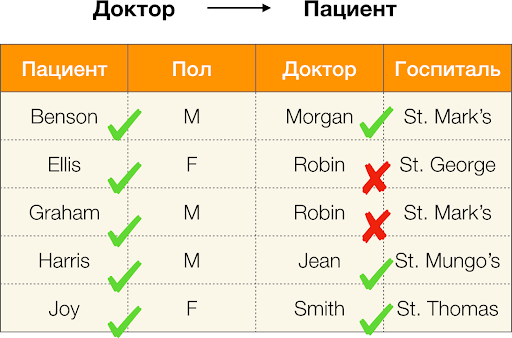
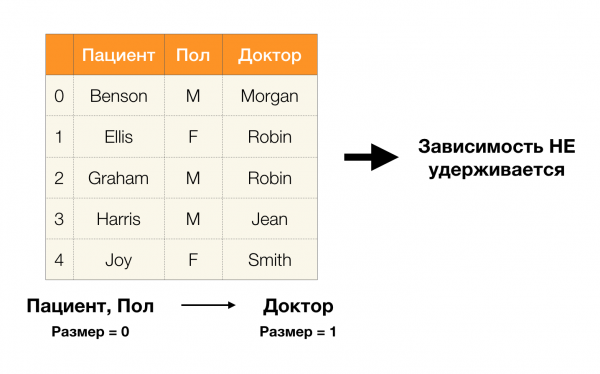
Согласно определению выше, для того чтобы удержалась первая зависимость, каждому уникальному значению столбца Пациент должно соответствовать только одно значение столбца Пол. И для таблицы-примера это действительно так. Однако в обратную сторону это не работает, то есть вторая зависимость не выполняется, а атрибут Пол не является детерминантом для Пациента. Аналогично, если взять зависимость Доктор → Пациент, можно заметить, что она нарушается, так как значение Robin по этому атрибуту имеет несколько разных значений — Ellis и Graham.
Таким образом, функциональные зависимости позволяют определить имеющиеся связи между множествами атрибутов таблицы. Отсюда и впредь мы будем рассматривать наиболее интересные связи, а точнее такие X → Y, что они являются:
- нетривиальными, то есть правая часть зависимости не является подмножеством левой (Y ̸⊆ X);
- минимальными, то есть нет такой зависимости Z → Y, что Z ⊂ X.
Рассматриваемые до этого момента зависимости были строгими, то есть не предусматривающими никаких нарушений на таблице, но помимо них есть и такие, которые допускают некоторую несогласованность между значениями кортежей. Такие зависимости выносят в отдельный класс, называют приближенными и разрешают им нарушаться на определенном количестве кортежей. Это количество регулируется показателем максимальной ошибки emax. Например, доля ошибки  = 0.01 может означать, что зависимость может нарушаться на 1% от имеющихся кортежей на рассматриваемом множестве атрибутов. То есть для 1000 записей максимум 10 кортежей могут нарушать ФЗ. Мы же будем рассматривать немного иную метрику, основанную на попарно-различных значениях сравниваемых кортежей. Для зависимости X → Y на отношении r она считается так:
= 0.01 может означать, что зависимость может нарушаться на 1% от имеющихся кортежей на рассматриваемом множестве атрибутов. То есть для 1000 записей максимум 10 кортежей могут нарушать ФЗ. Мы же будем рассматривать немного иную метрику, основанную на попарно-различных значениях сравниваемых кортежей. Для зависимости X → Y на отношении r она считается так:

Посчитаем ошибку для Доктор → Пациент из примера выше. Имеем два кортежа, значения которых разнятся на атрибуте Пациент, но совпадают на Докторе:  [Доктор, Пациент] = (Robin, Ellis) dhe
[Доктор, Пациент] = (Robin, Ellis) dhe  [Доктор, Пациент] = (Robin, Graham). Следуя определению ошибки, мы должны учитывать все конфликтующие пары, а значит таковых будет две: (
[Доктор, Пациент] = (Robin, Graham). Следуя определению ошибки, мы должны учитывать все конфликтующие пары, а значит таковых будет две: ( ,
,  ) и ее инверсия (
) и ее инверсия ( ,
,  ). Подставим в формулу и получим:
). Подставим в формулу и получим:

А теперь попытаемся ответить на вопрос: «А зачем оно все?». На самом деле, ФЗ бывают разные. Первый тип — это такие зависимости, которые определяются администратором на этапе проектирования базы данных. Их обычно немного, они строгие, а основное применение — нормализация данных и дизайн схемы отношения.
Второй тип — зависимости, представляющие «скрытые» данные и ранее неизвестные связи между атрибутами. То есть о таких зависимостях не думали в момент проектирования и их находят уже для имеющегося набора данных, чтобы потом на основе множества выявленных ФЗ сделать какие-либо выводы о хранимой информации. Как раз с такими зависимостями мы и работаем. Ими занимается целая область дата майнинга с различными техниками поиска и построенными на их основе алгоритмами. Давайте разбираться, чем могут быть полезны найденные функциональные зависимости (точные или приближенные) в каких-либо данных.

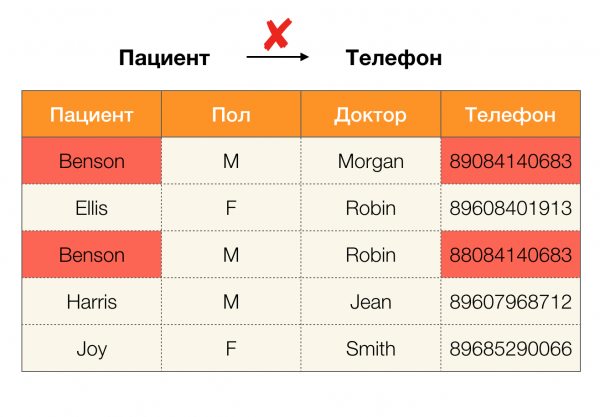
Сегодня среди основных областей применения зависимостей выделяют очистку данных. Она подразумевает разработку процессов выявления «грязных данных» с последующим их исправлением. Яркими представителями «грязных данных» являются дубликаты, ошибки в данных или опечатки, пропущенные значения, устаревшие данные, лишние пробелы и тому подобное.
Пример ошибки в данных:
Пример дубликатов в данных:
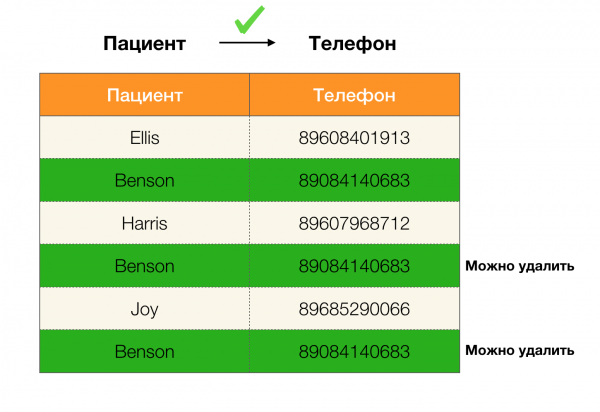
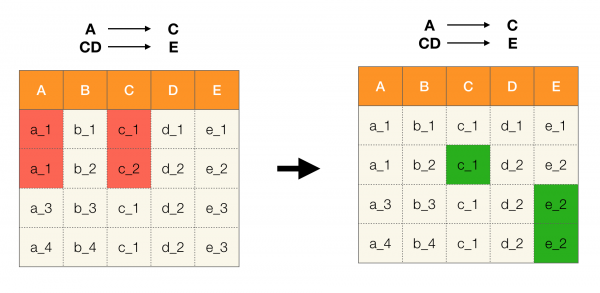
Например, мы имеем таблицу и набор ФЗ, которые должны выполняться. Очистка данных в данном случае предполагает изменить данные таким образом, чтобы ФЗ стали верны. При этом число модификаций должно быть минимально (для данной процедуры существуют свои алгоритмы, на которых мы не будем сосредотачивать внимание в данной статье). Ниже приведен пример такого преобразования данных. Слева исходное отношение, в котором, очевидно, не выполняются необходимые ФЗ (красным цветом выделен пример нарушения одной из ФЗ). Справа представлено обновленное отношение, в котором зеленые ячейки показывают измененные значения. После проведения такой процедуры необходимые зависимости стали удерживаться.
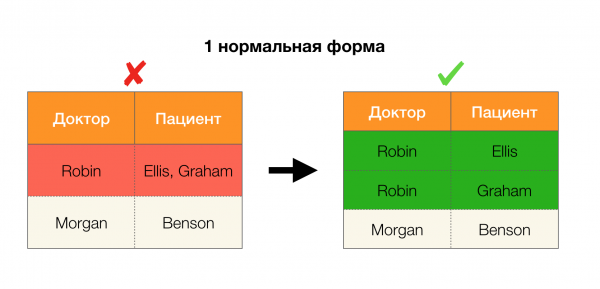
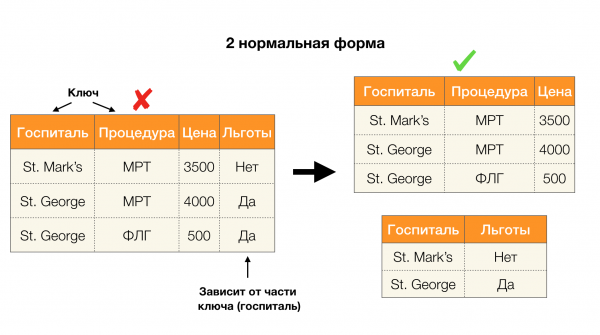
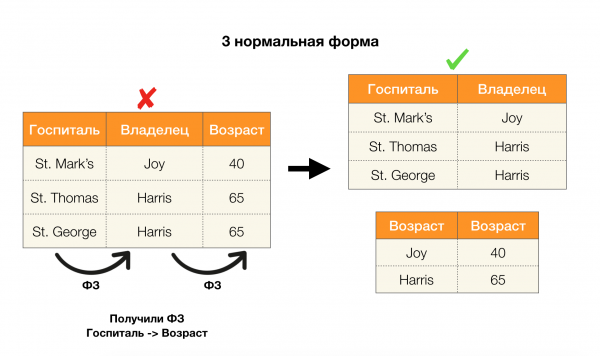
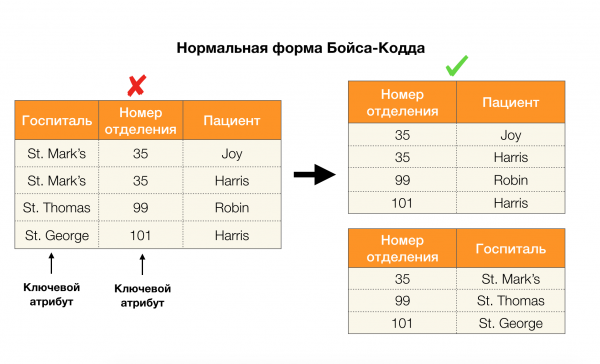
Другой популярной областью применения является дизайн базы данных. Здесь стоит напомнить про нормальные формы и нормализацию. Нормализация — это процесс приведения отношения в соответствие некоторому набору требований, каждый из которых определяется нормальной формой по-своему. Расписывать требования различных нормальных форм мы не станем (это делается в любой книге по курсу БД для начинающих), а лишь заметим, что каждая из них по-своему использует концепцию функциональных зависимостей. Ведь ФЗ по своей сути являются ограничениями целостности, которые учитываются при проектировании базы данных (в контексте этой задачи ФЗ иногда называют суперключами).
Рассмотрим их применение для четырех нормальных форм на картинке ниже. Напомним, что нормальная форма Бойса-Кодда является более строгой, чем третья форма, но при этом менее строгой, чем четвертая. Последнюю пока не рассматриваем, поскольку для ее постановки нужно понимание многозначных зависимостей, которые в данной статье нам не интересны.
Еще одной областью, в которой зависимости нашли свое применение, является понижение размерности пространства признаков в таких задачах как построение наивного байесовского классификатора, выделение значимых признаков и репараметризация регрессионной модели. В оригинальных статьях эта задача называется определением избыточных признаков (feature redundancy) и релевантных (feature relevancy) [5, 6], и решается она с активным использованием концепций баз данных. С появлением таких работ мы можем говорить, что сегодня наблюдается запрос на решения, позволяющие объединить базу данных, аналитику и реализацию вышеперечисленных проблем оптимизации в один инструмент [7, 8, 9].
Для поиска ФЗ в наборе данных существует множество алгоритмов (как современных, так и не очень).Такие алгоритмы можно разделить на три группы:
- Алгоритмы, использующие обход алгебраических решеток (Lattice traversal algorithms)
- Алгоритмы, основанные на поиске согласованных значений (Difference- and agree-set algorithms)
- Алгоритмы, основанные на попарных сравнениях (Dependency induction algorithms)
Краткое описание каждого типа алгоритмов представлено в таблице ниже:
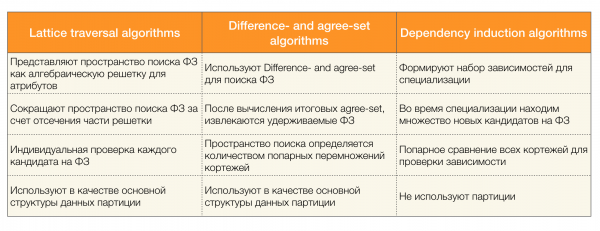
Подробнее о данной классификации можно почитать [4]. Ниже представлены примеры алгоритмов на каждый из типов:
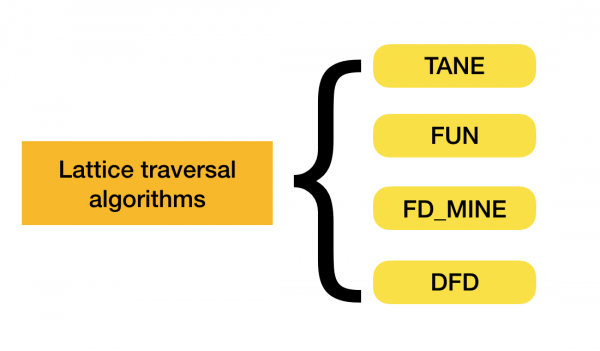
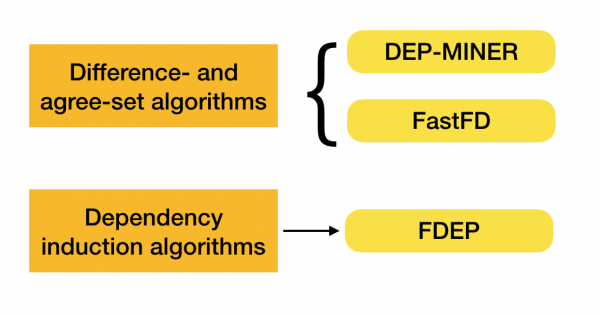
В настоящее время появляются новые алгоритмы, которые сочетают в себе сразу несколько подходов к поиску функциональных зависимостей. Примерами таких алгоритмов являются Pyro [2] и HyFD [3]. Разбор их работы предполагается в следующих статьях данного цикла. В этой статье мы лишь разберем основные понятия и лемму, которые необходимы для понимания техник выявления зависимостей.
Начнем с простого — difference- и agree-set, используемые во втором типе алгоритмов. Difference-set представляет собой множество кортежей, которые не совпадают по значениям, а agree-set наоборот — кортежи, совпадающие по значениям. Стоить отметить, что в данном случае мы рассматриваем только левую часть зависимости.
Также важным понятием, которое встречалось выше, является алгебраическая решетка. Так как многие современные алгоритмы оперируют данным понятием, нам нужно иметь представление о том, что это такое.
Для того чтобы ввести понятие решетки, необходимо определение частично упорядоченного множества (или partially ordered set, сокращенно — poset).
Определение 2. Говорят, что множество S частично упорядочено бинарным отношением ⩽, если для всяких a, b, c ∈ S выполнены свойства:
- Рефлексивность, то есть a ⩽ a
- Антисимметричность, то есть, если a ⩽ b и b ⩽ a, то a = b
- Транзитивность, то есть для a ⩽ b и b ⩽ c следует, что a ⩽ c
Такое отношение называется отношением (нестрогого) частичного порядка, а само множество — частично упорядоченным множеством. Формальное обозначение: ⟨S, ⩽⟩.
В качестве простейшего примера частично упорядоченного множества можно взять множество всех натуральных чисел N с обычным отношением порядка ⩽. Нетрудно проверить, что все необходимые аксиомы выполняются.
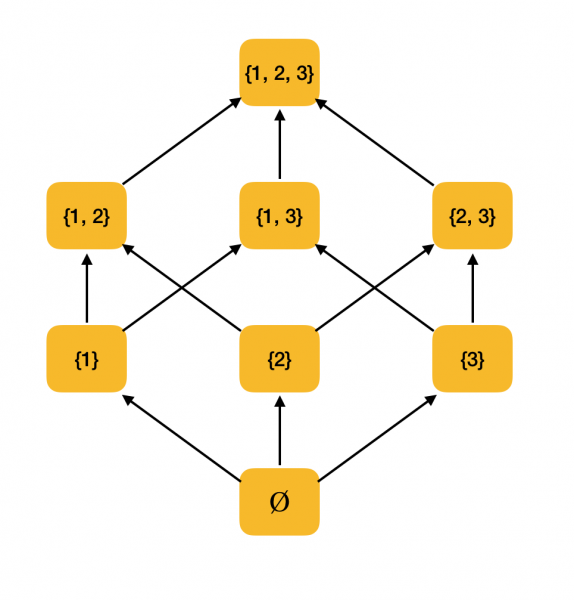
Более содержательный пример. Рассмотрим множество всех подмножеств {1, 2, 3}, упорядоченное отношением включения ⊆. Действительно, это отношение удовлетворяет всем условиям частичного порядка, поэтому ⟨P ({1, 2, 3}), ⊆⟩ — частично упорядоченное множество. На рисунке ниже изображена структура этого множества: если из одного элемента можно дойти по стрелочкам до другого элемента, то они находятся в отношении порядка.
Нам потребуются еще два простых определения из области математики — супремум (supremum) и инфимум (infimum).
Определение 3. Пусть ⟨S, ⩽⟩ — частично упорядоченное множество, A ⊆ S. Верхняя граница A — это такой элемент u ∈ S, что ∀x ∈ S: x ⩽ u. Пусть U — множество всех верхних границ S. Если в U существует наименьший элемент, тогда он называется супремумом и обозначается как sup A.
Аналогично вводится понятие точной нижней границы.
Определение 4. Пусть ⟨S, ⩽⟩ — частично упорядоченное множество, A ⊆ S. Нижняя граница A — это такой элемент l ∈ S, что ∀x ∈ S: l ⩽ x. Пусть L — множество всех нижних границ S. Если в L существует наибольший элемент, тогда он называется инфимумом и обозначается как inf A.
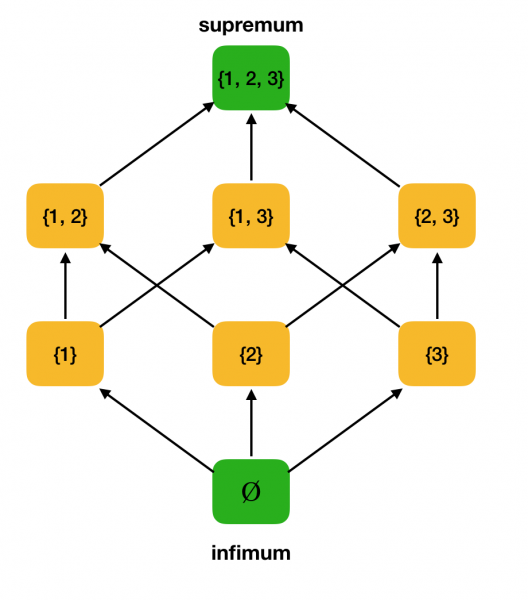
Рассмотрим в качестве примера приведенное выше частично упорядоченное множество ⟨P ({1, 2, 3}), ⊆⟩ и найдем в нем супремум и инфимум:
Теперь можно сформулировать определение алгебраической решетки.
Определение 5. Пусть ⟨P, ⩽⟩ — частично упорядоченное множество, такое что всякое двухэлементное подмножество имеет точные верхнюю и нижнюю границы. Тогда P называется алгебраической решеткой. При этом sup{x, y} записывают как x ∨ y, а inf {x, y} — как x ∧ y.
Проверим, что наш рабочий пример ⟨P ({1, 2, 3}), ⊆⟩ является решеткой. Действительно, для всяких a, b ∈ P ({1, 2, 3}), a∨b = a∪b, а a∧b = a∩b. Например, рассмотрим множества {1, 2} и {1, 3} и найдем их инфимум и супремум. Если мы их пересечем, то получим множество {1}, которое и будет являться инфимумом. Супремум же получим их объединением — {1, 2, 3}.
В алгоритмах выявления ФЗ пространство поиска зачастую представляется в форме решетки, где множества из одного элемента (читай первый уровень решетки поиска, где левая часть зависимостей состоит из одного атрибута) являют собой каждый атрибут исходного отношения.
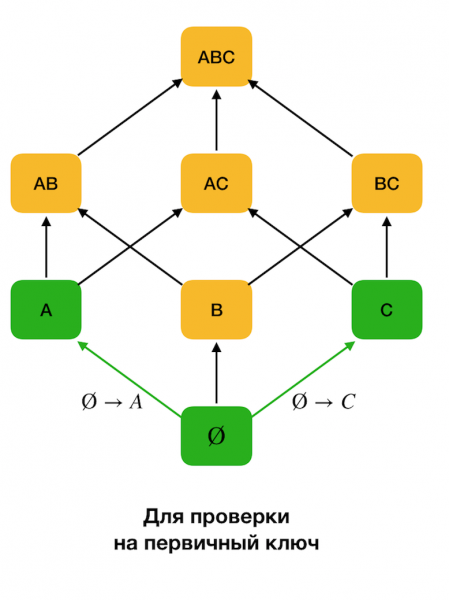
В начале рассматриваются зависимости вида ∅ → Одиночный атрибут. Данный шаг позволяет определить, какие атрибуты являются первичными ключами (для таких атрибутов не бывает детерминантов, а потому левая часть пуста). Далее такие алгоритмы двигаются по решетке вверх. При этом стоит отметить, что решетку можно обходить не всю, то есть если на вход передать желаемый максимальный размер левой части, то дальше уровня с таким размером алгоритм идти не будет.
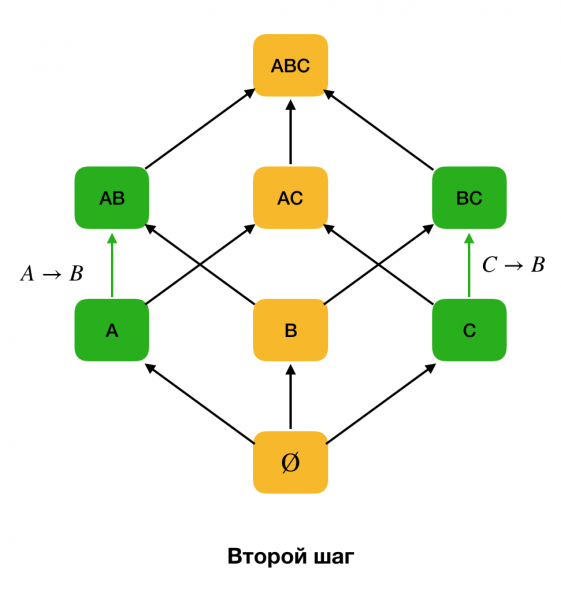
На рисунке ниже показано, как можно использовать алгебраическую решетку в задаче поиска ФЗ. Здесь каждое ребро (X, XY) представляет собой зависимость X → Y. Например, мы прошли первый уровень и знаем, что удерживается зависимость A → B (отобразим это зеленой связью между вершинами A dhe B). Значит далее, когда будем продвигаться по решетке вверх, мы можем не проверять зависимость A, C → B, потому что она будет уже не минимальной. Аналогично мы бы не стали ее проверять, если бы удерживалась зависимость C → B.
Кроме того, как правило, все современные алгоритмы по поиску ФЗ используют такую структуру данных, как партиция (в первоисточнике — stripped partition [1]). Формальное определение партиции выглядит следующим образом:
Определение 6. Пусть X ⊆ R — набор атрибутов для отношения r. Кластер представляет собой набор индексов кортежей из r, которые имеют одинаковое значение для X, то есть c(t) = {i|ti[X] = t[X]}. Партиция представляет собой множество кластеров, исключающее кластеры единичной длины:

Простыми словами, партиция для атрибута X представляет собой набор списков, где каждый список содержит номера строк с одинаковыми значениями для X. В современной литературе структура, представляющая партиции, называется position list index (PLI). Кластеры единичной длины исключаются в целях сжатия PLI, потому что это кластеры, содержащие лишь номер записи с уникальным значением, которое всегда будет легко установить.
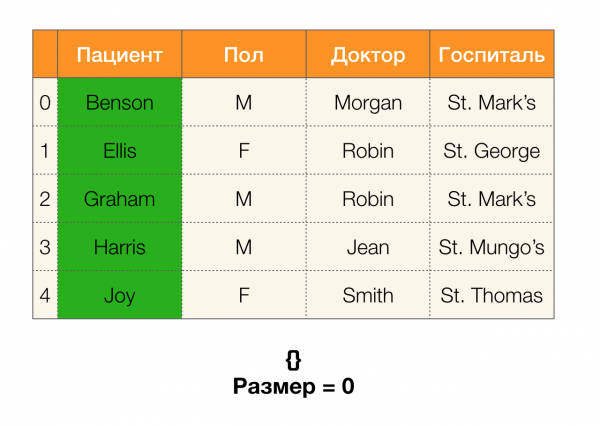
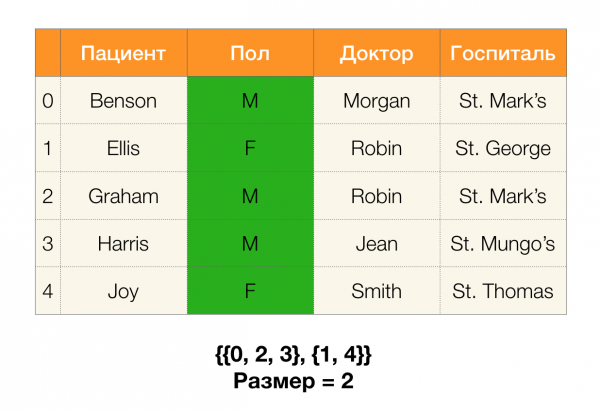
Рассмотрим пример. Вернемся все к той же таблице с пациентами и построим партиции для столбцов Пациент dhe Пол (слева появился новый столбец, в котором отмечены номера строк таблицы):
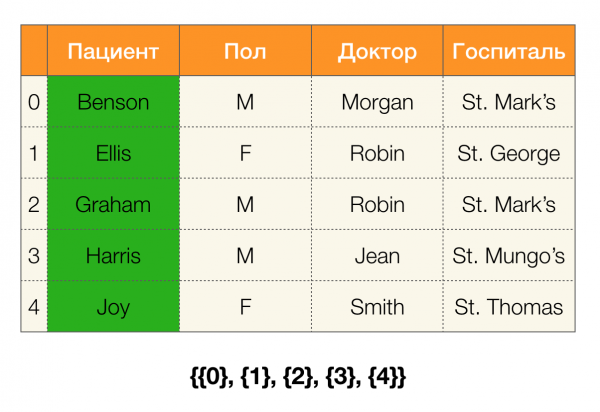
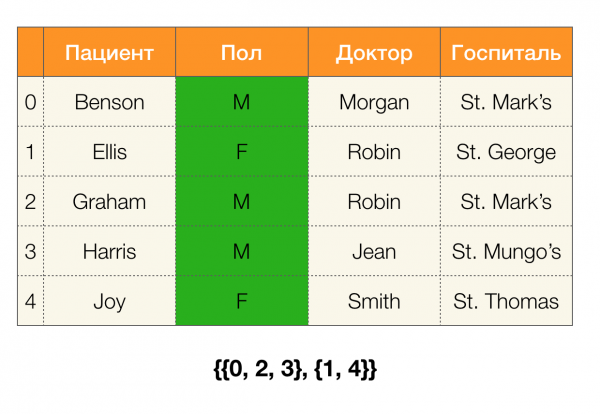
При этом, согласно определению, партиция для столбца Пациент на самом деле будет пустая, так как одиночные кластеры исключаются из партиции.
Партиции можно получать по нескольким атрибутам. И для этого существует два пути: пройдясь по таблице, построить партицию сразу по всем необходимым атрибутам, или же построить ее с помощью операции пересечения партиций по подмножеству атрибутов. Алгоритмы поиска ФЗ используют второй вариант.
Простыми словами, чтобы, например, получить партицию по столбцам ABC, можно взять партиции для AC dhe B (или любой другой набор непересекающихся подмножеств) и пересечь их между собой. Операция пересечения двух партиций выделяет кластеры наибольшей длины, общие для обеих партиций.
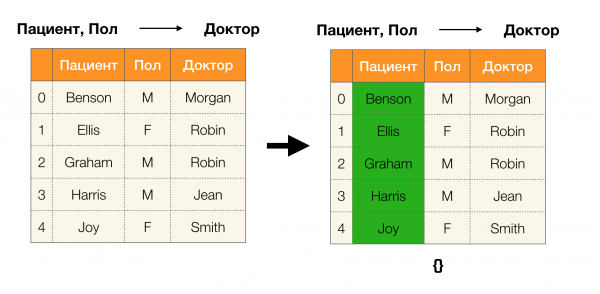
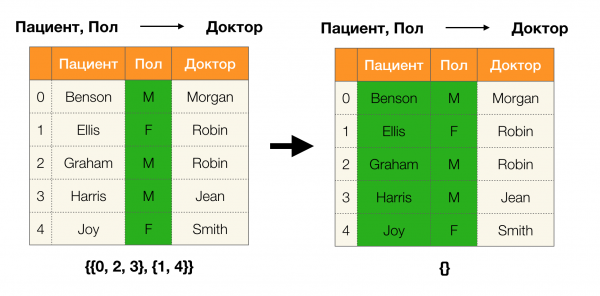
Давайте рассмотрим пример:
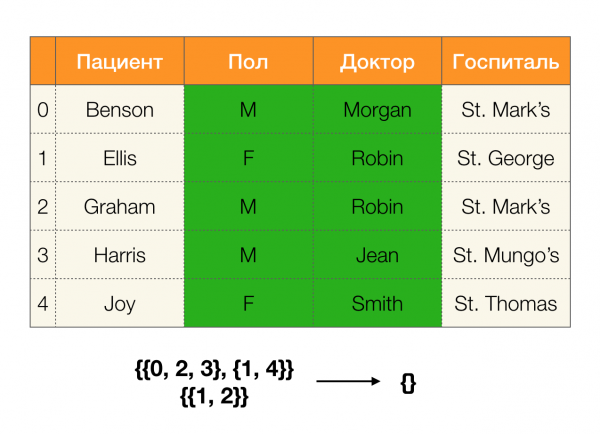

В первом случае мы получили пустую партицию. Если присмотреться к таблице, то действительно, одинаковых значений по двум атрибутам там нет. Если же мы немного модифицируем таблицу (случай справа), то уже получим непустое пересечение. При этом строки 1 и 2 и правда содержат одинаковые значения по атрибутам Пол dhe Доктор.
Далее нам понадобится такое понятие, как размер партиции. Формально:

Проще говоря, размер партиции представляет собой количество кластеров, входящих в партицию (помним, что единичные кластеры в партицию не входят!):
Теперь мы можем определить одну из ключевых лемм, которая для заданных партиций позволяет установить, удерживается зависимость или нет:
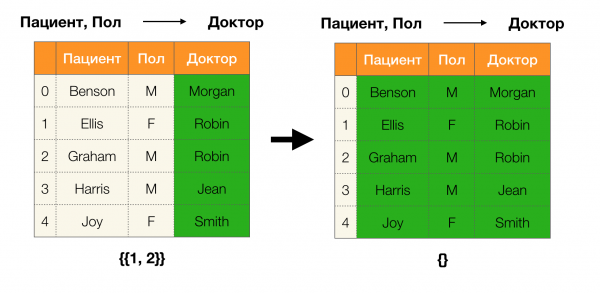
Лемма 1. Зависимость A, B → C удерживается, если и только если

Согласно лемме, для определения, удерживается ли зависимость, необходимо выполнить четыре шага:
- Вычислить партицию для левой части зависимости
- Вычислить партицию для правой части зависимости
- Вычислить произведение первого и второго шага
- Сравнить размеры партиций, полученных на первом и третьем шаге
Ниже представлен пример проверки, удерживается ли зависимость по данной лемме:
В данной статье мы разобрали такие понятия, как функциональная зависимость, приближенная функциональная зависимость, рассмотрели, где они применяются, а также какие алгоритмы поиска ФЗ существуют. Также мы подробно разобрали базовые, но важные понятия, активно используемые в современных алгоритмах по поиску ФЗ.
Ссылки на литературу:
- Huhtala Y. et al. TANE: An efficient algorithm for discovering functional and approximate dependencies //The computer journal. – 1999. – Т. 42. – №. 2. – С. 100-111.
- Kruse S., Naumann F. Efficient discovery of approximate dependencies //Proceedings of the VLDB Endowment. – 2018. – Т. 11. – №. 7. – С. 759-772.
- Papenbrock T., Naumann F. A hybrid approach to functional dependency discovery //Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – С. 821-833.
- Papenbrock T. et al. Functional dependency discovery: An experimental evaluation of seven algorithms //Proceedings of the VLDB Endowment. – 2015. – Т. 8. – №. 10. – С. 1082-1093.
- Kumar A. et al. To join or not to join?: Thinking twice about joins before feature selection //Proceedings of the 2016 International Conference on Management of Data. – ACM, 2016. – С. 19-34.
- Abo Khamis M. et al. In-database learning with sparse tensors //Proceedings of the 37th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. – ACM, 2018. – С. 325-340.
- Hellerstein J. M. et al. The MADlib analytics library: or MAD skills, the SQL //Proceedings of the VLDB Endowment. – 2012. – Т. 5. – №. 12. – С. 1700-1711.
- Qin C., Rusu F. Speculative approximations for terascale distributed gradient descent optimization //Proceedings of the Fourth Workshop on Data analytics in the Cloud. – ACM, 2015. – С. 1.
- Meng X. et al. Mllib: Machine learning in apache spark //The Journal of Machine Learning Research. – 2016. – Т. 17. – №. 1. – С. 1235-1241.
Авторы статьи: , исследователь в , dhe , исследователь в
Burimi: habr.com
