

Любая операция с большими данными требует больших вычислительных мощностей. Обычное перемещение данных из базы на Hadoop может длиться неделями или стоить, как крыло самолёта. Не хотите ждать и тратиться? Сбалансируйте нагрузку на разные платформы. Один из способов – pushdown-оптимизация.
Я попросил ведущего в России тренера по разработке и администрированию продуктов Informatica Алексея Ананьева рассказать о функции pushdown-оптимизации в Informatica Big Data Management (BDM). Когда-то учились работать с продуктами Informatica? Скорее всего именно Алексей рассказывал вам азы PowerCenter и объяснял, как строить маппинги.
Алексей Ананьев, руководитель направления по обучению DIS Group
Что такое pushdown?
Многие из вас уже знакомы с Informatica Big Data Management (BDM). Продукт умеет интегрировать большие данные из разных источников, перемещать их между разными системами, обеспечивает к ним лёгкий доступ, позволяет профилировать их и многое другое.
В умелых руках BDM способен творить чудеса: задачи будут выполняться быстро и с минимальными вычислительными ресурсами.
Тоже так хотите? Научитесь использовать функцию pushdown в BDM для распределения вычислительной нагрузки между разными платформами. Технология pushdown позволяет превратить маппинг в скрипт и выбрать среду, в которой этот скрипт запуститься. Возможность такого выбора позволяет комбинировать сильные стороны разных платформ и достигать их максимальной производительности.
Для настройки среды исполнения скрипта нужно выбрать тип pushdown. Скрипт может быть полностью запущен на Hadoop или частично распределен между источником и приемником. Есть 4 возможных типа pushdown. Маппинг можно не превращать в скрипт (native). Маппинг можно исполнить максимально на источнике (source) или полностью на источнике (full). Также маппинг можно превратить в скрипт Hadoop (none).
Pushdown-оптимизация
Перечисленные 4 типа можно по-разному комбинировать – оптимизировать pushdown под конкретные нужды системы. Например, часто целесообразнее извлечь данные из базы данных, применяя её собственные возможности. А преобразовать данные – силами Hadoop, чтобы саму базу не перегружать.
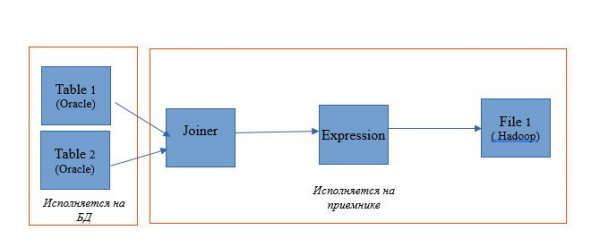
Давайте рассмотрим случай, когда и источник, и приемник находятся в БД, а платформу исполнения преобразований можно выбрать: в зависимости от настроек это будет Informatica, сервер БД или Hadoop. Такой пример позволит наиболее точно понять техническую сторону работы этого механизма. Естественно, в реальной жизни, такая ситуация не возникает, но для демонстрации функционала она подходит наилучшим образом.
Возьмём маппинг для чтения двух таблиц в единой базе данных Oracle. А результаты чтения пусть записываются в таблицу в этой же базе. Схема маппинга будет такая:
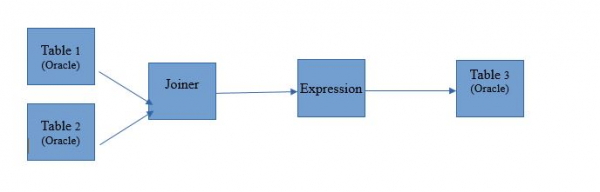
В виде маппинга на Informatica BDM 10.2.1 это выглядит таким образом:
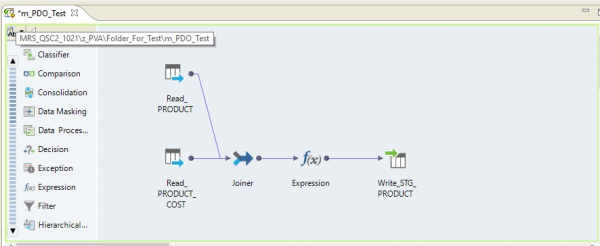
Тип pushdown – native
Если мы выберем тип pushdown native, то маппинг будет выполнен на сервере Informatica. Данные будут прочтены с сервера Oracle, перенесены на сервер Informatica, трансформированы там и переданы в Hadoop. Другими словами, мы получим обычный ETL-процесс.
Тип pushdown – source
При выборе типа source мы получаем возможность распределить наш процесс между сервером базы данных (БД) и Hadoop. При исполнении процесса с этой настройкой в базу полетят запросы на выборку данных из таблиц. А остальное будет выполняться в виде шагов на Hadoop.
Схема исполнения будет выглядеть так:
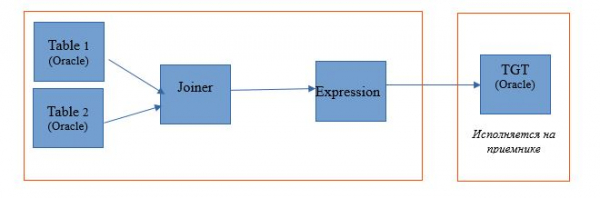
Ниже – пример настройки среды исполнения.
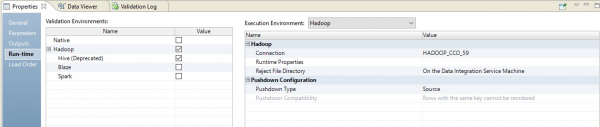
В этом случае маппинг будет выполняться в два шага. В его настройках мы увидим, что он превратился в скрипт, который будет отправлен на источник. Причем объединение таблиц и преобразование данных выполнится в виде переопределенного запроса на источнике.
На картинке ниже, мы видим оптимизированный маппинг на BDM, а на источнике – переопределенный запрос.
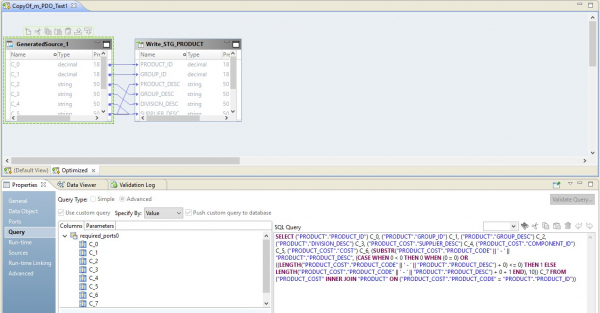
Роль Hadoop в данной конфигурации сведется к управлению потоком данных – дирижированию ими. Результат запроса будет направлен в Hadoop. После завершения чтения файл из Hadoop будет записан в приемник.
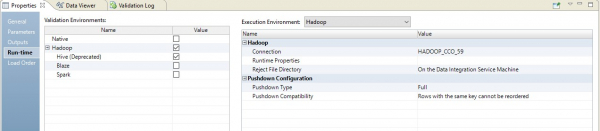
Тип pushdown – full
При выборе типа full маппинг полностью превратиться в запрос на БД. А результат запроса будет направлен на Hadoop. Схема такого процесса представлена ниже.
Пример настройки представлен ниже.
В результате мы получим оптимизированный маппинг похожий на предыдущий. Разница только в том, что вся логика переноситься на приемник в виде переопределения его вставки. Пример оптимизированного маппинга представлен ниже.
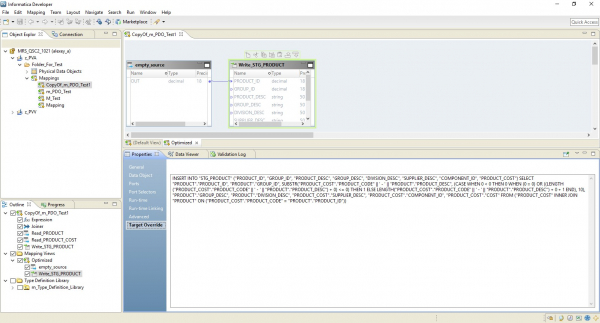
Здесь, как и в предыдущем случае, Hadoop выполняет роль дирижёра. Но здесь чтение источника производиться целиком, а дальше на уровне приемника выполняется логика обработки данных.
Тип pushdown – null
Ну и последний вариант – тип pushdown, в рамках которого наш маппинг превратится в скрипт на Hadoop.
Оптимизированный маппинг теперь будет выглядеть так:
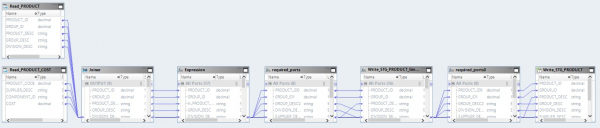
Здесь данные из файлов-источников сначала будут прочтены на Hadoop. Затем его же средствами эти два файла будут объединены. После этого данные будут преобразованы и выгружены в БД.
Понимая принципы pushdown-оптимизации, можно очень эффективно организовать многие процессы работы с большими данными. Так, совсем недавно одна крупная компания всего за несколько недель выгрузила из хранилища в Hadoop большие данные, которые до этого собирала несколько лет.
Источник: habr.com






