

Эта заметка будет интересна для тех, кто использует библиотеку обработки табличных данных для R — data.table, и, возможно, будет рад увидеть гибкость ее применения на различных примерах.
Вдохновившись хорошим примером , и надеясь, что вы уже почитали его статью, предлагаю глубже копнуть в сторону оптимизации кода и производительности на основе data.table.
Введение: откуда идет data.table?
Лучше всего начать знакомство с библиотекой немного издалека, а именно, со структур данных, из которых может быть получен объект data.table (далее, ДТ).
Массив
Код
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
Одна из таких структур — это массив (?base::array). Как и в других языках массивы здесь многомерны. Однако интересным является то, что, например, двумерный массив начинает наследовать свойства от класса матрицы (?base::matrix), а одномерный массив, что тоже важно, не наследует от вектора (?base::vector).
При этом надо понимать, что тип данных, содержащихся в каком-либо объекте следует проверять функцией base::typeof, которая возвращает внутреннее описание типа согласно R Internals — общим протоколом языка, связанным с первородным C.
Еще одна команда, для определения класса объекта, base::class, возвращает в случае векторов векторный тип (он отличается названием от внутреннего, но позволяет также понять тип данных).
Список
Из двумерного массива, он же матрица, можно перейти к списку (?base::list).
Код
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
При этом происходят несколько вещей сразу:
- Схлопывается второе измерение матрицы, то есть, мы получаем одновременно и список и вектор.
- Список, таким образом, наследует от этих классов. Надо иметь в виду, что элементу списка будет соответствовать одно (скалярное) значение из ячейки матрицы-массива.
Благодаря тому, что список это также и вектор, к нему можно применять некоторые функции для векторов.
Датафрейм
От списка, матрицы или вектора можно перейти к датафрейму (?base::data.frame).
Код
## data.frames ------------
df <- as.data.frame(arrmatr)
df2 <- as.data.frame(mylist)
is.list(df)
df$V6 <- df$V1 + df$V2
Что в нем интересно: датафрейм наследует от списка! Колонки датафрейма являются ячейками списка. Это будет важно в дальнейшем, когда мы будем использовать функции, применяемые к спискам.
data.table
Получить ДТ (?data.table::data.table) можно из датафрейма, списка, вектора или матрицы. Например, вот так (in place).
Код
## data.tables -----------------------
library(data.table)
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
Полезно то, что, как и датафрейм, ДТ наследует свойства списка.
ДТ и память
В отличие от всех остальных объектов в R base, ДТ передаются по ссылке. Если нужно сделать копирование в новую область памяти, нужна функция data.table::copy либо нужно сделать выборку из старого объекта.
Код
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
На этом введение подходит к концу. ДТ — это продолжение развития структур данных в R, которое преимущественно происходит за счет расширения и ускорения операций, производимых над объектами класса датафрейм. При этом сохраняется наследование от других примитивов.
Некоторые примеры использования свойств data.table
Как список…
Итерировать по строкам датафрейма или ДТ не лучшая идея, так как код цикла на языке R гораздно медленее C, а пройтись в цикле по столбцам, которых, обычно, гораздно меньше, вполне можно. Идя по столбцам, помним, что каждый столбец это элемент списка, содержащий, как правило, вектор. А операции над векторами хорошо векторизованы в базовых функциях языка. Также можно использовать операторы выборки, свойственные спискам и векторам: `[[`, `$`.
Код
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
Векторизация
Если есть необходимость пройти по строкам большого ДТ, лучшим решением будет написание функции с векторизацией. Но если это не получается, то следует помнить, что цикл внутри ДТ все равно быстрее цикла в R, так как выполняется на C.
Попробуем на бОльшем примере со 100К строк. Будем вытаскивать первую букву из слов, входящих в вектор-колонку w.
Updated
Код
library(magrittr)
library(microbenchmark)
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
Первый прогон с итерацией по строкам:
Unit: milliseconds
expr min
{ dt[, `:=`(first_l, unlist(strsplit(w, split = " ", fixed = T))[1]), by = 1:nrow(dt)] } 439.6217
lq mean median uq max neval
451.9998 460.1593 456.2505 460.9147 621.4042 100
Второй прогон, где векторизация идет через обращение списка в матрицу и взятие элементов на срезе с индексом 1 (последнее и есть собственно векторизация). Поправлюсь: векторизация на уровне функции strsplit, которая умеет принимать вектор на вход. Оказывается, процедура превращения списка в матрицу намного тяжелее самой векторизации, но и в этом случае намного быстрее невекторизованного варианта.
Unit: milliseconds
expr min lq mean median uq max neval
{ dt[, `:=`(first_l, .(first_l_f(w)))] } 93.07916 112.1381 161.9267 149.6863 185.9893 442.5199 100
Ускорение по медиане в 3 раз.
Третий прогон, где изменена схема превращения в матрицу.
Unit: milliseconds
expr min lq mean median uq max neval
{ dt[, `:=`(first_l, .(first_l_f2(w)))] } 32.60481 34.13679 40.4544 35.57115 42.11975 222.972 100
Ускорение по медиане в 13 раз.
С этим делом надо экспериментировать, чем больше — тем лучше будет.
Еще один пример с векторизацией, где также текст, но он приближен к реальным условиям: разная длина слов, разное количество слов. Требуется достать первые 3 слова. Вот так:
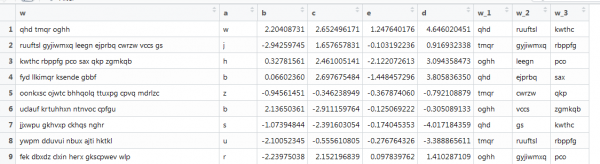
Здесь уже предыдущая функция не работает, так как векторы разной длины, а мы задавали размер матрицы. Переделаем это, покопавшись в интернетах.
Код
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
Unit: milliseconds
expr min lq mean median
{ dt[, `:=`((paste0(«w_», 1:3)), strsplit(w, split = " ", fixed = T))] } 851.7623 916.071 1054.5 1035.199
uq max neval
1178.738 1356.816 100
Скрипт отработал со средней скоростью 1 секунда. Неплохо.
Связанные одной цепью…
С объектами ДТ можно работать, используя chaining. Выглядит это как прицепление синтаксиса скобок справа, по сути, сахарок.
Код
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
Течет по трубам…
Такие же операции можно сделать через piping, выглядит похоже, но функционально богаче, так как можно использовать любые методы, а не только ДТ. Выведем коээфициенты логистической регрессии для наших синтетических данных с рядом фильтров на ДТ.
Код
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
Статистика, машинное обучение и прочее внутри ДТ
Можно использовать лямбда-функции, но иногда лучше создать их отдельно, прописать весь пайплайн анализа данных, и вперед — они работают внутри ДТ. Пример обогащен всеми вышеперечисленными фичами, плюс несколько полезных вещей из арсенала ДТ (таких как обращение к самому ДТ внутри ДТ по ссылке, вставленных иногда не последовательно, но чтобы было).
Код
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
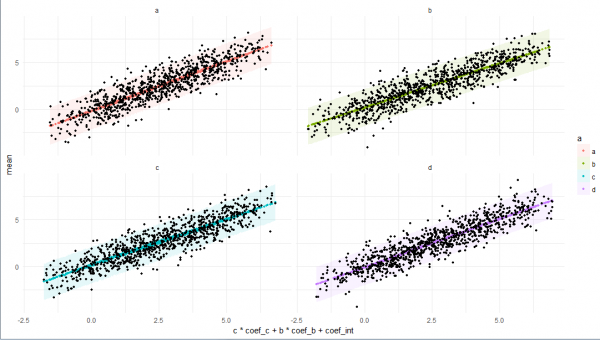
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Заключение
Я надеюсь, что смог создать цельную, но, конечно, не полную, картину такого объекта как data.table, начиная от его свойств связанных с наследованием от классов R и заканчивая его собственными фишками и окружением из элементов tidyverse. Надеюсь, это поможет вам лучше изучить и применять эту библиотеку для работы и развлечения.
Спасибо!
Полный код
Код
## load libs ----------------
library(data.table)
library(ggplot2)
library(magrittr)
library(microbenchmark)
## arrays ---------
arrmatr <- array(1:20, c(4,5))
class(arrmatr)
typeof(arrmatr)
is.array(arrmatr)
is.matrix(arrmatr)
## lists ------------------
mylist <- as.list(arrmatr)
is.vector(mylist)
is.list(mylist)
## data.frames ------------
df <- as.data.frame(arrmatr)
is.list(df)
df$V6 <- df$V1 + df$V2
## data.tables -----------------------
data.table::setDT(df)
is.list(df)
is.data.frame(df)
is.data.table(df)
df2 <- df
df[V1 == 1, V2 := 999]
data.table::fsetdiff(df, df2)
df2 <- data.table::copy(df)
df[V1 == 2, V2 := 999]
data.table::fsetdiff(df, df2)
## operations on data.tables ------------
#using list properties
df$'V1'[1]
df[['V1']]
df[[1]][1]
sapply(df, class)
sapply(df, function(x) sum(is.na(x)))
## Bigger example ----
rown <- 100000
dt <-
data.table(
w = sapply(seq_len(rown), function(x) paste(sample(letters, 3, replace = T), collapse = ' '))
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
# vectorization
# zero - for loop
microbenchmark({
for(i in 1:nrow(dt))
{
dt[
i
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
]
}
})
# first
microbenchmark({
dt[
, first_l := unlist(strsplit(w, split = ' ', fixed = T))[1]
, by = 1:nrow(dt)
]
})
# second
first_l_f <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
do.call(rbind, .) %>%
`[`(,1)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f(w))
]
})
# third
first_l_f2 <- function(sd)
{
strsplit(sd, split = ' ', fixed = T) %>%
unlist %>%
matrix(nrow = 3) %>%
`[`(1,)
}
dt[, first_l := NULL]
microbenchmark({
dt[
, first_l := .(first_l_f2(w))
]
})
# fourth
rown <- 100000
words <-
sapply(
seq_len(rown)
, function(x){
nwords <- rbinom(1, 10, 0.5)
paste(
sapply(
seq_len(nwords)
, function(x){
paste(sample(letters, rbinom(1, 10, 0.5), replace = T), collapse = '')
}
)
, collapse = ' '
)
}
)
dt <-
data.table(
w = words
, a = sample(letters, rown, replace = T)
, b = runif(rown, -3, 3)
, c = runif(rown, -3, 3)
, e = rnorm(rown)
) %>%
.[, d := 1 + b + c + rnorm(nrow(.))]
first_l_f3 <- function(sd, n)
{
l <- strsplit(sd, split = ' ', fixed = T)
maxl <- max(lengths(l))
sapply(l, "length<-", maxl) %>%
`[`(n,) %>%
as.character
}
microbenchmark({
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
})
dt[
, (paste0('w_', 1:3)) := lapply(1:3, function(x) first_l_f3(w, x))
]
# chaining
res1 <- dt[a == 'a'][sample(.N, 100)]
res2 <- dt[, .N, a][, N]
res3 <- dt[, coefficients(lm(e ~ d))[1], a][, .(letter = a, coef = V1)]
# piping
samplpe_b <- dt[a %in% head(letters), sample(b, 1)]
res4 <-
dt %>%
.[a %in% head(letters)] %>%
.[,
{
dt0 <- .SD[1:100]
quants <-
dt0[, c] %>%
quantile(seq(0.1, 1, 0.1), na.rm = T)
.(q = quants)
}
, .(cond = b > samplpe_b)
] %>%
glm(
cond ~ q -1
, family = binomial(link = "logit")
, data = .
) %>%
summary %>%
.[[12]]
# function
rm(lm_preds)
lm_preds <- function(
sd, by, n
)
{
if(
n < 100 |
!by[['a']] %in% head(letters, 4)
)
{
res <-
list(
low = NA
, mean = NA
, high = NA
, coefs = NA
)
} else {
lmm <-
lm(
d ~ c + b
, data = sd
)
preds <-
stats::predict.lm(
lmm
, sd
, interval = "prediction"
)
res <-
list(
low = preds[, 2]
, mean = preds[, 1]
, high = preds[, 3]
, coefs = coefficients(lmm)
)
}
res
}
res5 <-
dt %>%
.[e < 0] %>%
.[.[, .I[b > 0]]] %>%
.[, `:=` (
low = as.numeric(lm_preds(.SD, .BY, .N)[[1]])
, mean = as.numeric(lm_preds(.SD, .BY, .N)[[2]])
, high = as.numeric(lm_preds(.SD, .BY, .N)[[3]])
, coef_c = as.numeric(lm_preds(.SD, .BY, .N)[[4]][1])
, coef_b = as.numeric(lm_preds(.SD, .BY, .N)[[4]][2])
, coef_int = as.numeric(lm_preds(.SD, .BY, .N)[[4]][3])
)
, a
] %>%
.[!is.na(mean), -'e', with = F]
# plot
plo <-
res5 %>%
ggplot +
facet_wrap(~ a) +
geom_ribbon(
aes(
x = c * coef_c + b * coef_b + coef_int
, ymin = low
, ymax = high
, fill = a
)
, size = 0.1
, alpha = 0.1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = mean
, color = a
)
, size = 1
) +
geom_point(
aes(
x = c * coef_c + b * coef_b + coef_int
, y = d
)
, size = 1
, color = 'black'
) +
theme_minimal()
print(plo)
Источник: habr.com
