

Кадр из фильма «Our Secret Universe: The Hidden Life of the Cell»
Инвестиционный бизнес — это одно из сложнейших направлений в банковском мире, потому что здесь есть не только кредиты, займы и депозиты, но и ценные бумаги, валюта, товары, деривативы и всякие сложности в виде структурных продуктов.
В последнее время мы наблюдаем рост финансовой грамотности населения. Всё больше людей вовлекается в торговлю на рынках ценных бумаг. Индивидуальные инвестиционные счета появились не так давно. Они позволяют вам торговать на рынках ценных бумаг и при этом либо получать налоговые вычеты, либо не платить налоги. И все клиенты, которые к нам приходят, хотят управлять своим портфелем и видеть отчётность в реальном времени. Причем чаще всего этот портфель мультипродуктовый, то есть люди являются клиентами различных направлений бизнеса.
Кроме того, растут и потребности регуляторов, как российских, так и зарубежных.
Чтобы соответствовать текущим потребностям и заложить фундамент для будущих модернизаций, мы разработали ядро инвест-бизнеса на основе Tarantool.
Немного статистики. Инвестиционный бизнес «Альфа-Банка» оказывает брокерские услуги для физических и юридических лиц по предоставлению возможности торговать на различных рынках ценных бумаг, депозитарные услуги по хранению ценных бумаг, услуги по доверительному управлению для лиц с частным и крупным капиталом, услуги по выпуску ценных бумаг для других компаний. Инвестиционный бизнес «Альфа-Банка» — это более 3 тыс. котировок в секунду, которые загружаются с различных торговых площадок. В течение рабочего дня на рынках заключается более 300 тыс. сделок от лица банка или его клиентов. На внешних и внутренних площадках происходит до 5 тыс. исполнений ордеров в секунду. При этом все клиенты, как внутренние, так и внешние, хотят видеть свои позиции в режиме реального времени.
Предыстория
Где-то с начала 2000-х годов наши направления инвестиционного бизнеса развивались независимо: биржевая торговля, брокерские услуги, торговля валютой, внебиржевая торговля ценными бумагами и различными деривативами. В результате мы попали в ловушку функциональных колодцев. Что это такое? У каждого направления бизнеса есть свои системы, которые дублируют функции друг друга. У каждой системы своя модель данных, хотя они оперируют одними и теми же понятиями: сделками, инструментами, контрагентами, котировками и прочим. И поскольку каждая система развивалась независимо, возник разнообразный зоопарк технологий.
Кроме того, кодовая база систем уже порядком устарела, ведь некоторые продукты зародились ещё в середине 1990-х. И на некоторых направлениях это замедляло процесс разработки, имелись проблемы с производительностью.
Требования к новому решению
Бизнес понял, что для дальнейшего развития жизненно необходима технологическая трансформация. Нам поставили задачи:
- Собрать все данные бизнеса в едином быстром хранилище и в единой модели данных.
- Эту информацию мы не должны терять или изменять.
- Нужно версионировать данные, потому что в любой момент регулятор может попросить статистику за прошлые годы.
- Мы должны не просто принести какую-то новую, модную СУБД, а сделать платформу для решения бизнес-задач.
Помимо этого наши архитекторы поставили свои условия:
- Новое решение должно быть корпоративного класса, то есть оно должно быть уже апробировано в каких-то крупных компаниях.
- Режим работы решения должен быть mission critical. Это значит, что мы должны присутствовать одновременно в нескольких дата-центрах и спокойно переживать отключение одного дата-центра.
- Система должна быть горизонтально масштабируемой. Дело в том, что все наши текущие системы только вертикально масштабируемые, и мы уже упираемся в потолок из-за низкого роста мощности железа. Поэтому настал момент, когда нам для выживания нужно иметь горизонтально масштабируемую систему.
- Помимо всего прочего нам сказали, что решение должно быть дешёвым.
Мы пошли стандартным путём: сформулировали требования и обратились в отдел закупок. Оттуда получили список компаний, которые, в целом, готовы для нас это делать. Рассказали всем о задаче, и от шести из них получили оценку решений.
Мы в банке на слово никому не верим, любим всё тестировать самостоятельно. Поэтому обязательным условием нашего тендерного конкурса было прохождение нагрузочных тестов. Сформулировали тестовые задания по нагрузке, и уже три компании из шести согласились за свой счет реализовать прототип решения на базе in-memory-технологий, чтобы протестировать его.
Я не буду рассказывать, как мы всё тестировали и сколько времени это заняло, подведу лишь итог: лучшую производительность в нагрузочных тестах показал прототип решения на базе Tarantool от команды разработчиков Mail.ru Group. Мы подписали договор и начали разработку. Четыре человека было со стороны Mail.ru Group, а от «Альфа-Банка» три разработчика, три системных аналитика, solution-архитектор, владелец продукта и Scrum-мастер.
Дальше расскажу о том, как росла наша система, как она эволюционировала, что мы делали и почему именно так.
Разработка
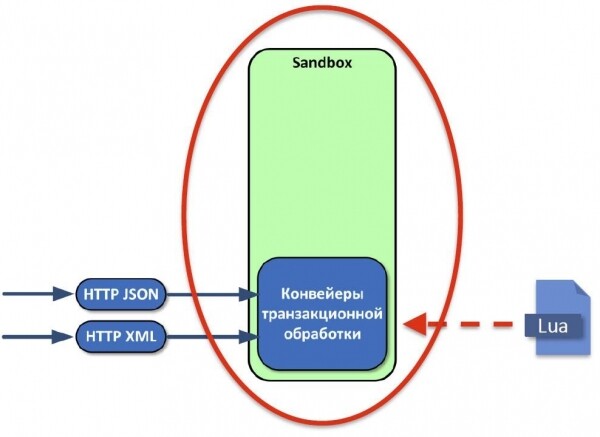
В первую очередь мы задались вопросом, как получать данные из наших текущих систем. Решили, что HTTP нам вполне подходит, потому что все текущие системы общаются между собой, пересылая XML или JSON по HTTP.
Мы используем встроенный в Tarantool HTTP-сервер, потому что у нас нет необходимости терминировать SSL-сессии, и его производительности нам хватает за глаза.
Как я уже говорил, у нас все системы живут в разных моделях данных, и на входе нам нужно привести объект к той модели, которую мы у себя опишем. Необходим был язык, позволяющий трансформировать данные. Мы выбрали императивный Lua. Весь код для преобразования данных мы запускаем в песочнице — это безопасное место, за пределы которого запущенный код не выходит. Для этого просто делаем loadstring нужного кода, создавая окружение с функциями, которые не могут ничего заблокировать или что-то уронить.
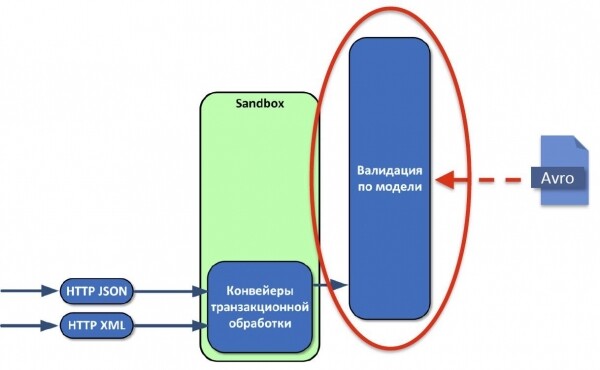
После преобразования данные надо проверить на соответствие той модели, которую мы создаём. Долго обсуждали, что должна представлять собой модель, какой язык использовать для ее описания. Остановились на Apache Avro, потому что язык простой и у него есть поддержка со стороны Tarantool. Новые версии модели и пользовательского кода можно отправлять в эксплуатацию несколько раз в день хоть под нагрузкой, хоть без, в любое время суток, и очень быстро адаптироваться к изменениям.
После проверки данные нужно сохранить. Делаем мы это с помощью vshard (у нас георазнесенные реплики шардов).
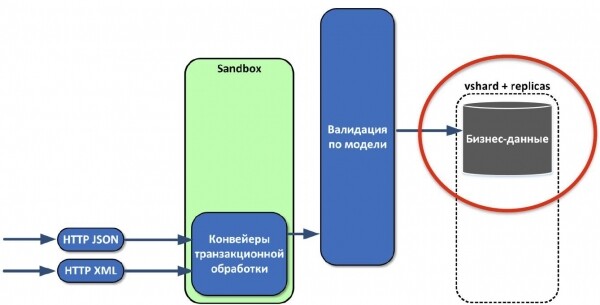
При этом специфика такая, что большинству систем, которые отправляют нам данные, неважно, получили мы их или нет. Поэтому с самого начала мы реализовали ремонтную очередь. Что это такое? Если по каким-то причинам объект не прошел трансформацию данных или проверку, то мы всё равно подтверждаем получение, но при этом сохраняем объект в ремонтную очередь. Она согласована, располагается в основном хранилище с бизнес-данными. Мы сразу написали для неё интерфейс администратора, различные метрики и оповещения. В результате мы не теряем данные. Даже если в источнике что-то поменялось, если изменилась модель данных, мы сразу это обнаружим и можем адаптироваться.
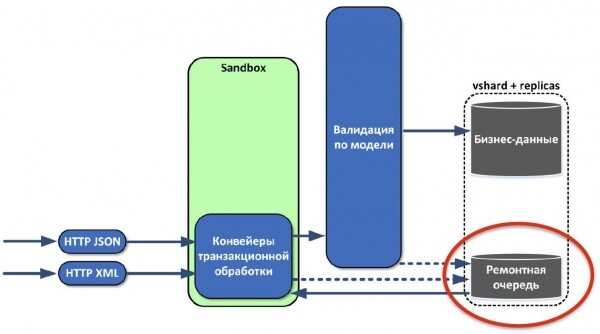
Теперь нужно научиться извлекать сохранённые данные. Мы внимательно проанализировали наши системы и увидели, что на классическом стеке из Java и Oracle обязательно присутствует какая-нибудь ORM, которая преобразует данные из реляционного вида в объектный. Так почему бы сразу не отдавать объекты системам в виде графа? Поэтому мы с радостью взяли GraphQL, который удовлетворял все наши нужды. Он позволяет получать данные в виде графов, вытаскивать только то, что нужно именно сейчас. Можно даже версионировать API с достаточно большой гибкостью.
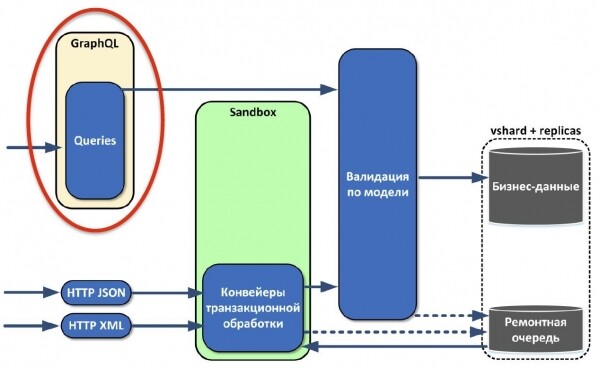
Почти сразу мы поняли, что извлекаемых данных нам мало. Сделали функции, которые можно привязать к объектам в модели — по сути, вычисляемые поля. То есть мы привязываем к полю некую функцию, которая, например, считает среднюю цену котировки. А внешний потребитель, который запрашивает данные, даже не знает, что это поле вычисляемое.
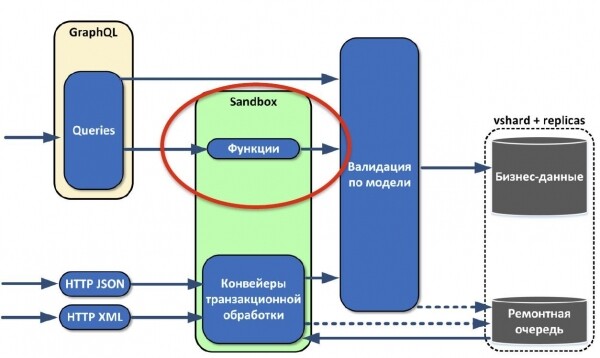
Реализовали систему аутентификации.
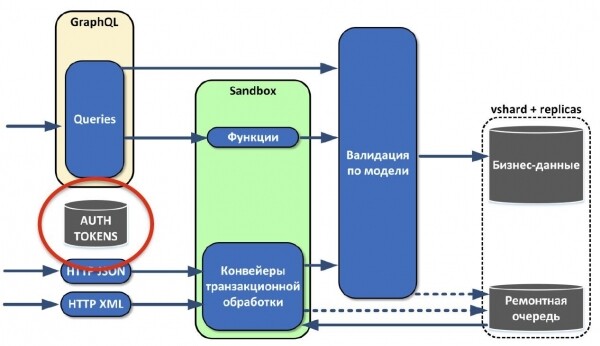
Потом заметили, что в нашем решении выкристаллизовывается несколько ролей. Роль — это некий агрегатор функций. Как правило, у ролей разный профиль использования оборудования:
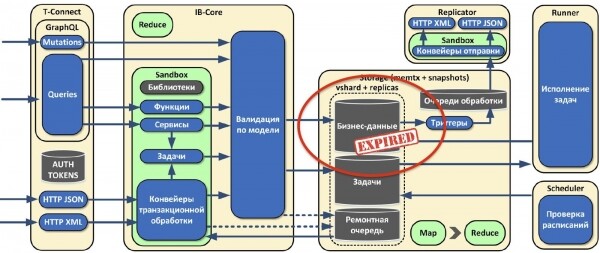
- T-Connect: обрабатывает входящие соединения, ограничена по процессору, потребляет мало памяти, не хранит состояние.
- IB-Core: трансформирует данные, которые получает по протоколу Tarantool, то есть она оперирует табличками. Тоже не хранит состояние и поддаётся масштабированию.
- Storage: только сохраняет данные, никакой логики не использует. В этой роли реализованы простейшие интерфейсы. Масштабируется благодаря vshard.
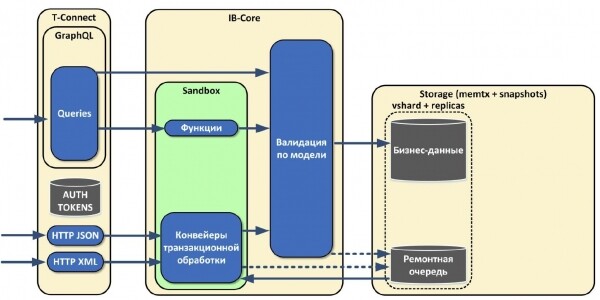
То есть с помощью ролей мы отвязали друг от друга разные части кластера, которые можно масштабировать независимо друг от друга.
Итак, мы создали асинхронную запись транзакционного потока данных и ремонтную очередь с интерфейсом администратора. Запись асинхронна с точки зрения бизнеса: если мы гарантированно записали к себе данные, неважно куда, то мы это подтвердим. Если не подтвердили, значит что-то пошло не так, данные нужно переслать. В этом и заключается асинхронность записи.
Тестирование
С самого начала проекта решили, что будем пытаться насаждать test driven development. Модульные тесты мы пишем на Lua с помощью фреймворка tarantool/tap, интеграционные — на Python с помощью фреймворка pytest. При этом в написание интеграционных тестов у нас вовлечены и разработчики, и аналитики.
Как у нас применяется test driven development?
Если мы хотим какую-то новую фичу, то стараемся сначала написать для неё тест. Обнаружив баг, обязательно сначала пишем на тест, и только потом исправляем. Сначала так работать тяжело, возникает непонимание со стороны сотрудников, даже саботаж: «Давайте сейчас быстро поправим, сделаем что-то новое, а потом покроем тестами». Только это «потом» не наступает почти никогда.
Поэтому надо заставлять себя в первую очередь писать тесты, просить окружающих это делать. Поверьте, test driven development приносит выгоду даже в краткосрочной перспективе. Вы почувствуете, что вам стало легче жить. По нашим ощущениям, сейчас тестами покрыто 99 % кода. Кажется, что это много, но у нас не возникает никаких проблем: тесты запускаются по каждому коммиту.
Однако больше всего мы любим нагрузочное тестирование считаем его самым важным и регулярно проводим.
Расскажу небольшую историю о том, как мы проводили первый этап нагрузочного тестирования одной из первых версий. Поставили систему на ноутбук разработчика, включили нагрузку и получили 4 тыс. транзакций в секунду. Хороший результат для ноутбука. Поставили на виртуальный нагрузочный стенд из четырёх серверов, послабее, чем в production. Развернули по минимуму. Запускаем, и получаем результат хуже, чем на ноутбуке в один поток. Шок-контент.
Мы очень взгрустнули. Смотрим загрузку серверов, а они, оказывается, простаивают.
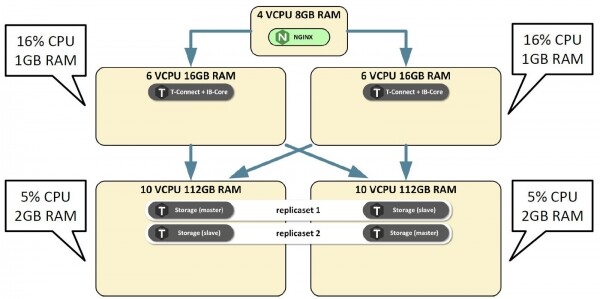
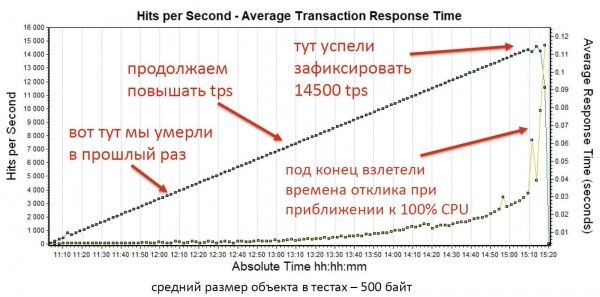
Звоним разработчикам, а они объясняют нам, людям, пришедшим из мира Java, что Tarantool однопоточный. Его может эффективно использовать только одно ядро процессора под нагрузкой. Тогда мы развернули на каждом сервере максимально возможное количество инстансов Tarantool, включили нагрузку и получили уже 14,5 тыс. транзакций в секунду.
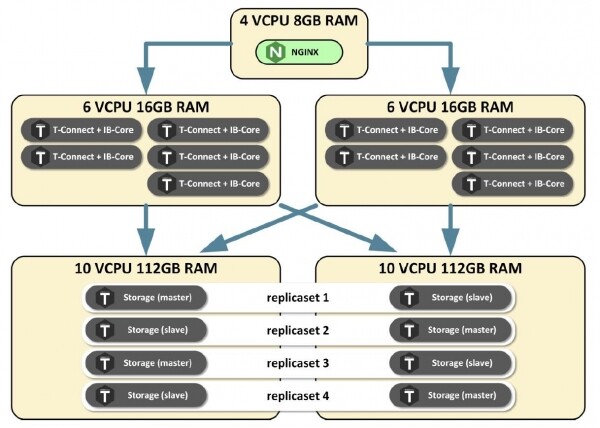
Ещё раз поясню. Из-за деления на роли, которые по-разному используют ресурсы, наши роли, отвечавшие за обработку соединений и трансформацию данных загружали только процессор, причём строго пропорционально нагрузке.
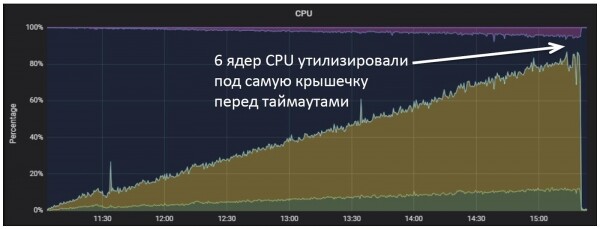
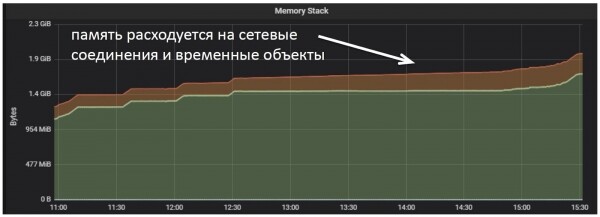
При этом память использовалась только под обработку входящих соединений и временных объектов.
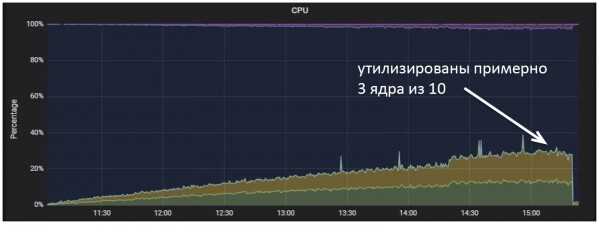
А на серверах хранения наоборот, загрузка процессора росла, но намного медленнее, чем на серверах, которые занимаются обработкой соединений.
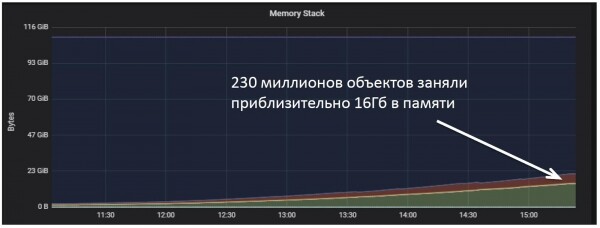
И потребление памяти росло прямо пропорционально загруженному объему данных.
Сервисы
Чтобы развивать наш новый продукт именно как платформу приложений, мы сделали компонент для развёртывания на ней сервисов и библиотек.
Сервисы — это не просто маленькие кусочки кода, которые оперируют какими-то полями. Они могут быть достаточно большими и сложными конструкциями, которые входят в состав кластера, проверяют справочные данные, крутят бизнес-логику и отдают ответы. Схему сервиса мы также экспортируем в GraphQL, а потребитель получает универсальную точку доступа к данным, с интроспекцией по всей модели. Это очень удобно.
Так как сервисы содержат гораздо больше функций, мы решили, что там должны быть библиотеки, в которые мы будем выносить часто используемый код. Их мы добавили в безопасное окружение, предварительно проверив, что это нам ничего не ломает. И теперь можем задавать функциям дополнительные окружения в виде библиотек.
Мы хотели, чтобы у нас была платформа не только для хранения, но и для вычислений. И поскольку у нас уже была куча реплик и шардов, мы реализовали подобие распределенных вычислений и назвали это map reduce, потому что получилось похоже на оригинальный map reduce.
Старые системы
Не все из наших старых систем могут вызывать нас по HTTP и использовать GraphQL, хотя и поддерживают этот протокол. Поэтому мы сделали механизм, позволяющий реплицировать данные в эти системы.
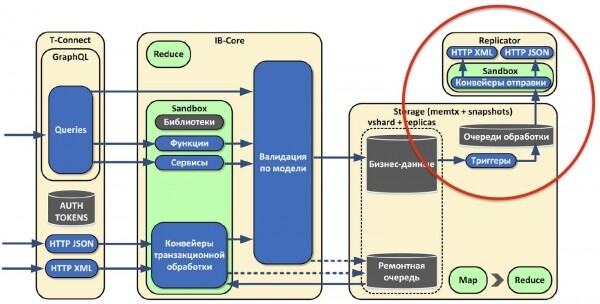
Если у нас что-то меняется, в роли Storage срабатывают своеобразные триггеры и сообщение с изменениями попадает в очередь обработки. Оно с помощью отдельной роли репликатора отправляется во внешнюю систему. Эта роль не хранит состояние.
Новые доработки
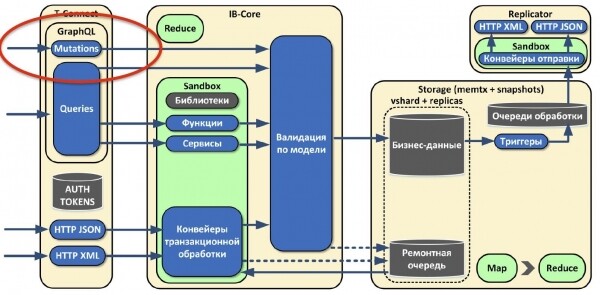
Как вы помните, с точки зрения бизнеса мы сделали асинхронную запись. Но тут поняли, что её будет недостаточно, потому что есть класс систем, которым требуется сразу получать ответ о статусе операции. Поэтому мы расширили наш GraphQL и добавили мутации. Они органично вписались в существующую парадигму работы с данными. У нас это единая точка как чтения, так и записи для другого класса систем.
Также мы поняли, что одних лишь сервисов нам будет недостаточно, потому что бывают довольно тяжелые отчеты, которые нужно строить раз в сутки, в неделю, в месяц. Это может занимать долгое время, причем отчеты могут даже блокировать event loop Tarantool’а. Поэтому мы сделали отдельные роли: scheduler и runner. Runner’ы не хранят состояние. На них запускаются тяжелые задачи, которые мы не можем считать на лету. А роль scheduler следит за расписанием запуска этих задач, которое описано в конфигурации. Сами задачи хранятся там же, где и бизнес-данные. Когда наступает подходящее время, scheduler берет задачу, отдает какому-то runner’у, тот её считает и сохраняет результат.
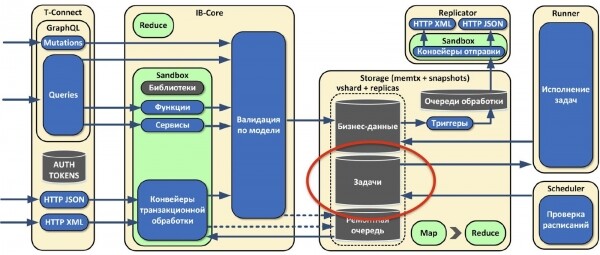
Не все задачи нужно запускать по расписанию. Какие-то отчеты нужно считать по требованию. Как только это требование приходит, в песочнице формируется задача и отправляется на выполнение в runner. Через некоторое время пользователю асинхронно приходит ответ, что всё посчиталось, отчёт готов.
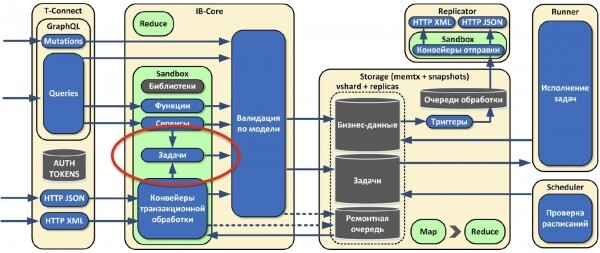
Изначально мы придерживались парадигмы сохранения всех данных, версионируя и не удаляя их. Но в жизни периодически всё-таки приходится что-то удалять, в основном какую-то сырую или промежуточную информацию. На основе expirationd мы сделали механизм очистки хранилища от устаревших данных.
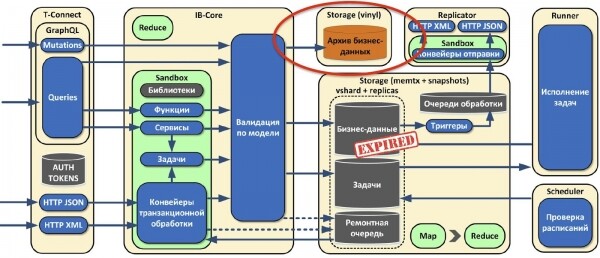
Также мы понимаем, что рано или поздно наступит ситуация, когда места для хранения данных в памяти начнет не хватать, но тем не менее данные надо хранить. Для этих целей мы скоро сделаем дисковое хранилище.
Заключение
Мы начали с задачи по загрузке данных в единую модель, потратили на её разработку три месяца. У нас было шесть систем-поставщиков данных. Весь код трансформации в единую модель составляет около 30 тыс. строк на Lua. А большая часть работы ещё впереди. Порой не хватает мотивации соседних команд, много усложняющих работу обстоятельств. Если перед вами когда-нибудь встанет подобная задача, то время, которое вам покажется нормальным для её реализации, помножьте на три, или даже на четыре.
Также помните, что имеющиеся проблемы в бизнес-процессах невозможно решить с помощью новой СУБД, пусть даже очень производительной. Что я имею в виду? На старте нашего проекта мы создали у заказчиков впечатление, что сейчас мы принесем новую быструю БД, и заживём! Процессы пойдут быстрее, всё будет хорошо. На самом деле, технологии не решают тех проблем, которые есть в бизнес-процессах, потому что бизнес-процессы — это люди. И нужно работать с людьми, а не с технологиями.
Разработка через тестирование на начальных этапах может доставлять боль и отнимать очень много времени. Но положительный эффект от неё будет заметен даже в краткосрочной перспективе, когда для проведения регрессионного тестирования вам не понадобится ничего делать.
Крайне важно проводить нагрузочное тестирование на всех этапах разработки. Чем раньше вы заметите какую-то недоработку в архитектуре, тем легче будет её исправить, это сэкономит вам кучу времени в дальнейшем.
В языке Lua нет ничего страшного. На нем может научиться писать кто угодно: Java-разработчик, JavaScript-разработчик, разработчик на Python, фронтендер или бэкендер. У нас даже аналитики на нём пишут.
Когда мы рассказываем о том, что у нас нет SQL, это приводит людей в ужас. «Как вы достаёте данные без SQL? Разве так можно?» Конечно. В системе класса OLTP SQL не нужен. Есть альтернатива в виде какого-либо языка, который возвращает вам сразу документоориентированный вид. Например, GraphQL. И есть альтернатива в виде распределенных вычислений.
Если вы понимаете, что вам нужно будет масштабироваться, то проектируйте свое решение на Tarantool, сразу таким образом, чтобы оно могло работать параллельно на десятках экземпляров Tarantool. Если вы этого не сделаете, то потом будет сложно и больно, поскольку Tarantool может эффективно использовать только одно ядро процессора.
Источник: habr.com
