


Не так давно я столкнулся с весьма нестандартной задачей настройки маршрутищации для MetalLB. Всё бы ничего, т.к. обычно для MetalLB не требуется никаких дополнительных действий, но в нашем случае имеется достаточно большой кластер с весьма нехитрой конфигурацией сети.
В данной статье я расскажу как настроить source-based и policy-based routing для внешней сети вашего кластера.
Я не буду подробно останавливаться на установке и настройке MetalLB, так как предполагаю вы уже имеете некоторый опыт. Предлагаю сразу перейти к делу, а именно к настройке маршрутизации. Итак мы имеем четыре кейса:
Случай 1: Когда настройка не требуется
Разберём простой кейс.
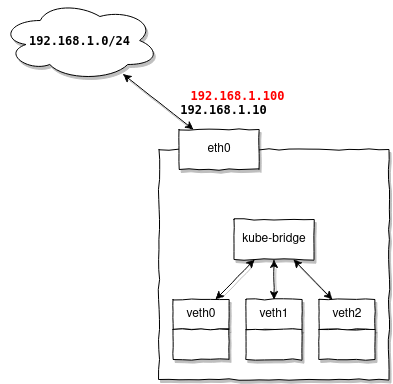
Дополнительная настройка маршрутизации не требуется, когда выдаваемые MetalLB адреса находятся в той же подсети что и адреса ваших нод.
Например вы имеете подсеть 192.168.1.0/24, в ней имеется маршрутизатор 192.168.1.1, и ваши ноды получают адреса: 192.168.1.10-30, тогда для MetalLB вы можете настроить рейндж 192.168.1.100-120 и быть уверенным что они будут работать без какой либо дополнительной настройки.
Почему так? Потому что ваши ноды уже имеют настроенные маршруты:
# ip route
default via 192.168.1.1 dev eth0 onlink
192.168.1.0/24 dev eth0 proto kernel scope link src 192.168.1.10И адреса из того же рейджа будут переиспользовать их без каких-либо дополнительных телодвижений.
Случай 2: Когда требуется дополнительная настройка
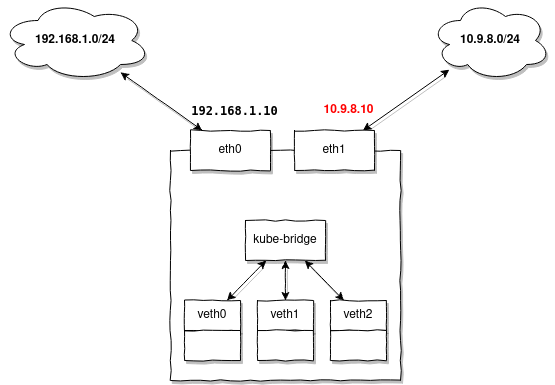
Вам следует настроить дополнительные маршруты всякий раз тогда, когда ваши ноды не имеют настроенного IP-адреса или маршрута в подсеть для которой MetalLB выдаёт адреса.
Объясню чуть подробней. Всякий раз когда MetalLB выдёт адрес, это можно сравнить с простым назначением вида:
ip addr add 10.9.8.7/32 dev loОбратите внимание, на:
- a) Адрес назначается с префиксом
/32то есть маршрут в подсеть для него автоматически не добавится (это просто адрес) - b) Адрес вешается на любой интерфейс ноды (например loopback). Здесь стоит упомянуть, об особенности сетевого стека Linux. Не важно на какой интерфейс вы добавите адрес, ядро всегда будет обрабатывать arp-запросы и отправлять arp-ответы на любой из них, это поведение считается коректным и, кроме того, достаточно широко используется в такой динамической среде как Kubernetes.
Данное поведение можно настраивать, например включив strict arp:
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announceВ этом случае arp-ответы будут отправляться только в том случае, если интерфейс явно содержит конкретный IP-адрес. Данная настройка является обязательной в случае если вы планируете использовать MetalLB и ваш kube-proxy работает в режиме IPVS.
Тем не менее MetalLB не использует ядро для обработки arp-запросов, а делает это самостоятельно в user-space, таким образом данная опция не повлияет на работу MetalLB.
Вернёмся к нашей задаче. Если маршрута для выдаваемых адресов на ваших нодах не существует, добавьте его заранее на все ноды:
ip route add 10.9.8.0/24 dev eth1Случай 3: Когда понадобится source-based routing
Source-based routing вам потребуется настроить тогда, когда вы получаете пакеты через отдельный gateway, не тот что настроен у вас по умолчанию, соответственно ответные пакеты также должы уходить через этот же gateway.
Например, у вас есть всё таже подсеть 192.168.1.0/24 выделенная для ваших нод, но вы хотите выдавать внешние адреса с помощью MetalLB. Предположим, у вас есть несколько адресов из подсети 1.2.3.0/24 находящихся во VLAN 100, и вы хотите использовать их для доступа Kubernetes-служб извне.
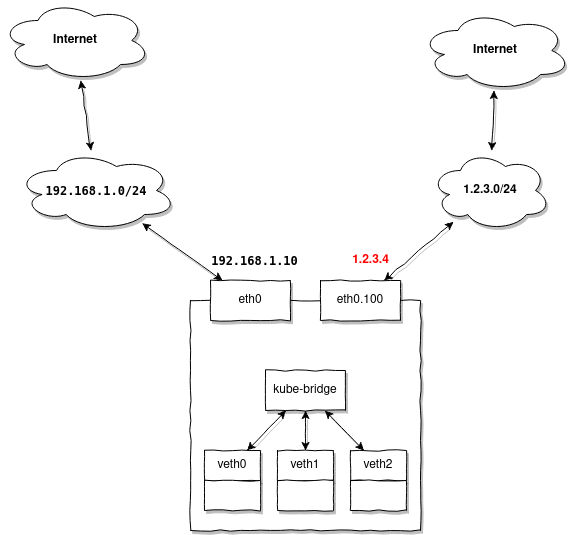
При обращении на 1.2.3.4 вы будете совершать запросы из другой подсети нежели 1.2.3.0/24 и ожидать ответ. Нода, которая в данный момент является мастером для выданного MetalLB адреса 1.2.3.4, получит пакет от маршрутизатора 1.2.3.1, но ответ для него обязательно должен уйти тем же маршрутом, через 1.2.3.1.
Так как наша нода уже имеет настроенный default gateway 192.168.1.1, то по умолчанию ответ пойдёт к нему, а не к 1.2.3.1, через который мы получили пакет.
Как же справиться с данной ситуацией?
В этом случае вам необходимо подготовить все ваши ноды таким образом, чтобы они были готовы обслуживать внешние адреса без дополнительной настройки. То есть для вышеприведённого примера вам нужно заранее создать VLAN-интерфейс на ноде:
ip link add link eth0 name eth0.100 type vlan id 100
ip link set eth0.100 upА затем добавить маршруты:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Обратите внимание маршруты мы добавляем в отдельную табицу маршрутизации 100 она будет содержать только два маршрута необходимых для отправки ответного пакета через гейтвей 1.2.3.1, находящийся за интерфейсом eth0.100.
Теперь нам нужно добавить простое правило:
ip rule add from 1.2.3.0/24 lookup 100которое явно говорит: если адрес источника пакета находится в 1.2.3.0/24, то нужно использовать табицу маршрутизации 100. В ней у нас уже описан маршрут который отправит его через 1.2.3.1
Случай 4: Когда понадобится policy-based routing
Топология сети как и в предыдущем примере, но допустим вы хотите также иметь возиможность обращаться к внешним адресам пула 1.2.3.0/24 из ваших подов:
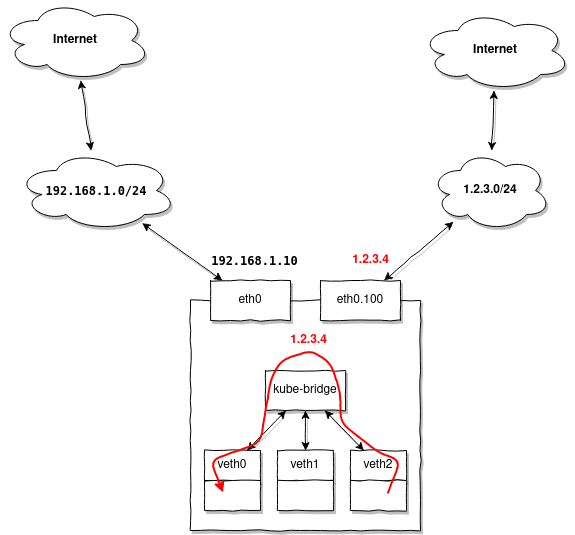
Особенность заключается в том что при обращении к любому адресу в 1.2.3.0/24, ответный пакет попадая на ноду и имея адрес источника в диапазоне 1.2.3.0/24 будет послушно отправлен в eth0.100, но мы-то хотим чтобы Kubernetes перенаправил его в наш первый под, который и сгенерировал изначальный запрос.
Решить данную проблему оказалось непросто, но это стало возможным благодаря policy-based routing:
Для большего понимания процесса приведу блок схему netfilter:
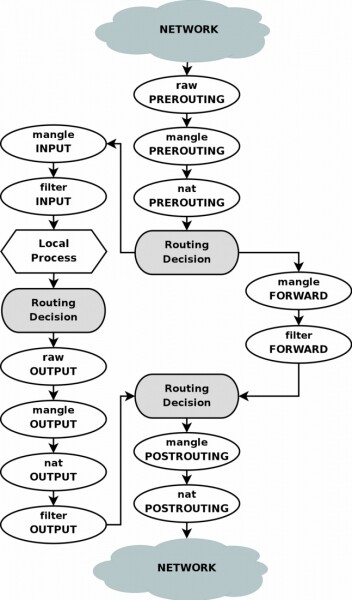
Для начала, как и в предыдущем примере, создадим дополнительную таблицу маршрутизации:
ip route add 1.2.3.0/24 dev eth0.100 table 100
ip route add default via 1.2.3.1 table 100Теперь добавим несколько правил в iptables:
iptables -t mangle -A PREROUTING -i eth0.100 -j CONNMARK --set-mark 0x100
iptables -t mangle -A PREROUTING -j CONNMARK --restore-mark
iptables -t mangle -A PREROUTING -m mark ! --mark 0 -j RETURN
iptables -t mangle -A POSTROUTING -j CONNMARK --save-markЭти правила будут маркировать входящие подключения на интерфейс eth0.100, помечая все пакеты тэгом 0x100, этим же тэгом будут помечены и ответы в рамках одного подключения.
Теперь мы можем добавить правило роутинга:
ip rule add from 1.2.3.0/24 fwmark 0x100 lookup 100То есть все пакеты с адресом источника 1.2.3.0/24 и тэгом 0x100 должны быть смаршрутизированны используя таблицу 100.
Таким образом другие пакеты, полученные на другой интерфейс, под это правило не попадают, что позволит им быть смаршрутизированными стандартными средствами Kubernetes.
Есть ещё одно но, в Linux существует так называемый reverse path filter, который портит всю малину осуществляет простую проверку: для всех входящих пакетов он меняет адрес источника пакета с адресом отправителя и проверяет может-ли пакет уйти через тот-же интерфейс на который был получен, если нет, то отфильтровывет его.
Проблема в том что в нашем случае он будет работать некорректно, но мы можем отключить его:
echo 0 > /proc/sys/net/ipv4/conf/all/rp_filter
echo 0 > /proc/sys/net/ipv4/conf/eth0.100/rp_filterОбратите внимание, первая команда котролирует глобальное поведение rp_filter, если его не отключить, то вторая команда не будет иметь никакого эфекта. Тем не менее остальные интерфейсы останутся со включённым rp_filter.
Чтобы не ограничивать работу фильтра полностью мы можем воспользоваться реализацией rp_filter для netfilter. Используя rpfilter в качестве модуля iptables можно настроить достаточно гибкие правила, например:
iptables -t raw -A PREROUTING -i eth0.100 -d 1.2.3.0/24 -j RETURN
iptables -t raw -A PREROUTING -i eth0.100 -m rpfilter --invert -j DROPвключат rp_filter на интерфейсе eth0.100 для всех адресов кроме 1.2.3.0/24.
Источник: habr.com
