


Алоха, пипл! Меня зовут Олег Анастасьев, я работаю в Одноклассниках в команде Платформы. А кроме меня, в Одноклассниках работает куча железа. У нас есть четыре ЦОДа, в них около 500 стоек более чем с 8 тысячами серверов. В определенный момент мы поняли, что внедрение новой системы управления позволит нам более эффективно загрузить технику, облегчить управление доступами, автоматизировать (пере)распределение вычислительных ресурсов, ускорить запуск новых сервисов, ускорить реакции на масштабные аварии.
Что же из этого получилось?
Кроме меня и кучи железа есть еще люди, которые с этим железом работают: инженеры, которые находятся непосредственно в дата-центрах; сетевики, которые настраивают сетевое обеспечение; админы, или SRE, которые обеспечивают отказоустойчивость инфраструктуры; и команды разработчиков, каждая из них отвечает за часть функций портала. Создаваемый ими софт работает как-то так:
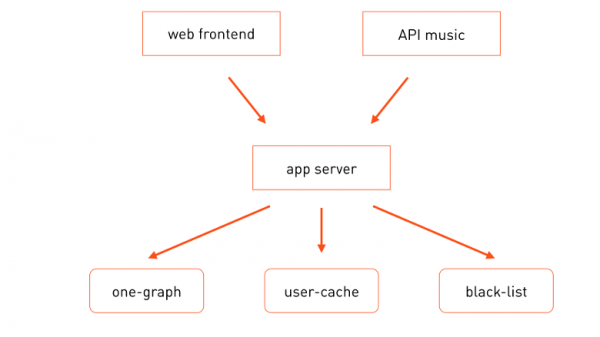
Запросы пользователей поступают как на фронты основного портала , так и на другие, например на фронты API музыки. Они для обработки бизнес-логики вызывают сервер приложений, который при обработке запроса вызывает необходимые специализированные микросервисы — one-graph (граф социальных связей), user-cache (кеш пользовательских профилей) и т. п.
Каждый из этих сервисов развёрнут на множестве машин, и у каждого из них есть ответственные разработчики, отвечающие за функционирование модулей, их эксплуатацию и технологическое развитие. Все эти сервисы запускаются на железных серверах, и до недавнего времени мы запускали ровно по одной задаче на один сервер, т. е. он был специализирован под конкретную задачу.
Почему так? У такого подхода было несколько плюсов:
- Облегчается массовое управление. Допустим, задача требует каких-то библиотек, каких-то настроек. И тогда сервер приписывается ровно к одной определённой группе, описывается политика cfengine для этой группы (или она уже описана), и эта конфигурация централизованно и автоматически раскатывается на все серверы этой группы.
- Упрощается диагностика. Допустим, вы смотрите на повышенную нагрузку центрального процессора и понимаете, что эту нагрузку могла сгенерировать только та задача, которая работает на этом железном процессоре. Поиски виноватого заканчиваются очень быстро.
- Упрощается мониторинг. Если с сервером что-то не так, монитор об этом сообщает, и вы точно знаете, кто виноват.
Сервису, состоящему из нескольких реплик, выделяется несколько серверов — по одному на каждую. Тогда вычислительный ресурс для сервиса выделяется очень просто: сколько у сервиса есть серверов, столько он и может ресурсов максимально потребить. «Просто» тут не в том смысле, что это легко использовать, а в том, что распределение ресурсов происходит вручную.
Такой подход также позволял нам делать специализированные железные конфигурации под задачу, выполняющуюся на этом сервере. Если задача хранит большие объёмы данных, то мы используем 4U-сервер с шасси на 38 дисков. Если задача чисто вычислительная, то можем купить более дешёвый 1U-сервер. Это эффективно с точки зрения вычислительных ресурсов. В том числе такой подход позволяет нам использовать в четыре раза меньше машин при нагрузке, сопоставимой с одной дружественной нам социальной сетью.
Такая эффективность использования вычислительных ресурсов должна обеспечить и эффективность экономическую, если исходить из посылки, что самое дорогое — это серверы. Долгое время дороже всего стоило именно железо, и мы вложили много сил в уменьшение цены железа, придумывая алгоритмы обеспечения отказоустойчивости для снижения требований к надёжности оборудования. И сегодня мы дошли до стадии, на которой цена сервера уже перестала быть определяющей. Если не рассматривать свежайшую экзотику, то конкретная конфигурация серверов в стойке не имеет значения. Сейчас у нас возникла другая проблема — цена занимаемого сервером места в дата-центре, т. е. места в стойке.
Осознав, что это так, мы решили посчитать, насколько эффективно используем стойки.
Взяли цену самого мощного сервера из экономически оправданных, подсчитали, сколько таких серверов можем поместить в стойки, сколько задач мы бы на них запустили исходя из старой модели «один сервер = одна задача» и насколько такие задачи смогли бы утилизировать оборудование. Посчитали — прослезились. Оказалось, что эффективность использования стоек у нас — около 11 %. Вывод очевидный: нужно повышать эффективность использования дата-центров. Казалось бы, решение очевидно: надо на одном сервере запускать сразу несколько задач. Но тут начинаются сложности.
Массовая конфигурация резко усложняется — теперь невозможно назначить серверу какую-то одну группу. Ведь теперь на одном сервере могут быть запущены несколько задач разных команд. Кроме того, конфигурация может быть конфликтующей для разных приложений. Диагностика тоже усложняется: если вы видите повышенное потребление процессоров или дисков на сервере, то не знаете, какая из задач доставляет неприятности.
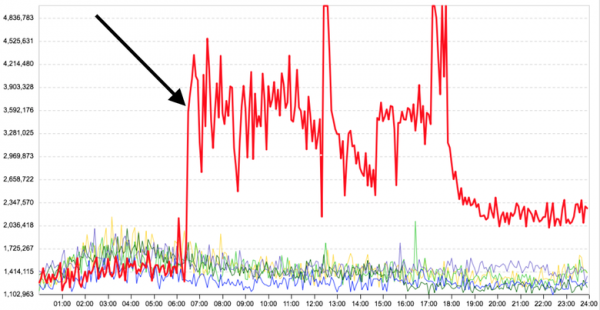
Но главное — это то, что между задачами, запущенными на одной машине, нет изоляции. Вот, например, график среднего времени ответа серверной задачи до и после того, как на том же сервере запустили ещё одно, никак не связанное с первым расчётное приложение — время получения отклика у основной задачи сильно увеличилось.
Очевидно, нужно запускать задачи либо в контейнерах, либо в виртуальных машинах. Поскольку практически все задачи у нас запускаются под управлением одной ОС (Linux) или адаптированы под неё, поддерживать множество различных операционных систем нам не требуется. Соответственно, виртуализация не нужна, из-за дополнительных накладных расходов она будет менее эффективна, чем контейнеризация.
В качестве реализации контейнеров для запуска задач непосредственно на серверах Docker — неплохой кандидат: образы файловых систем хорошо решают проблемы с конфликтующими конфигурациями. То, что образы можно составлять из нескольких слоёв, позволяет нам значительно сократить объём данных, необходимый для их развёртывания на инфраструктуре, выделив общие части в отдельные базовые слои. Тогда базовые (и самые объёмные) слои достаточно быстро будут кешированы на всей инфраструктуре, и для доставки множества различных типов приложений и версий понадобится передавать только небольшие по объёму слои.
Плюс, готовый реестр и тегирование образов в Docker дают нам готовые примитивы для версионирования и доставки кода в production.
Docker, как и любая другая подобная технология, предоставляет нам некоторый уровень изоляции контейнеров из коробки. Например, изоляция по памяти — каждому контейнеру выдаётся лимит на использование памяти машины, выше которого он не потребит. Также можно изолировать контейнеры по использованию CPU. Для нас, правда, стандартной изоляции было недостаточно. Но об этом — ниже.
Непосредственный запуск контейнеров на серверах — это только часть проблем. Другая часть связана с размещением контейнеров на серверах. Нужно понять, какой контейнер на какой сервер можно поставить. Это не такая простая задача, потому что контейнеры надо разместить на серверах как можно плотнее, при этом не снизив скорость их работы. Такое размещение может быть сложным и с точки зрения отказоустойчивости. Часто мы хотим размещать реплики одного и того же сервиса в разных стойках или даже в разных залах дата-центра, чтобы при отказе стойки или зала мы не теряли сразу все реплики сервиса.
Распределять контейнеры вручную — не вариант, когда у тебя 8 тысяч серверов и 8—16 тысяч контейнеров.
Кроме того, мы хотели дать разработчикам больше самостоятельности в распределении ресурсов, чтобы они могли сами размещать свои сервисы на production, без помощи администратора. При этом мы хотели сохранить контроль, чтобы какой-нибудь второстепенный сервис не потребил все ресурсы наших дата-центров.
Очевидно, что нужен управляющий слой, который занимался бы этим автоматически.
Вот мы и пришли к простой и понятной картинке, которую обожают все архитекторы: три квадратика.
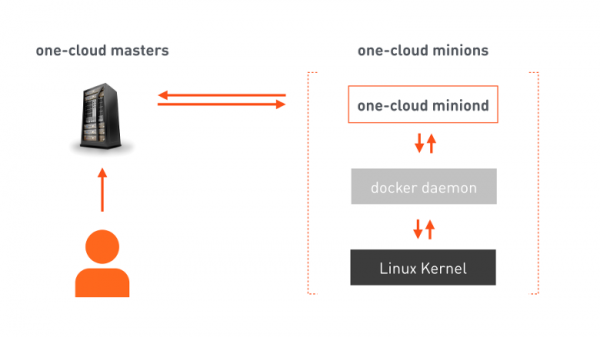
one-cloud masters — отказоустойчивый кластер, отвечающий за оркестрацию облака. Разработчик отправляет в мастер манифест, в котором содержится вся необходимая для размещения сервиса информация. Мастер на её основании даёт команды выбранным миньонам (машинам, предназначенным для запуска контейнеров). На миньонах есть наш агент, который получает команду, отдаёт уже свои команды Docker, а Docker конфигурирует linux kernel для запуска соответствующего контейнера. Кроме исполнения команд, агент непрерывно сообщает мастеру об изменениях состояния как машины-миньона, так и запущенных на ней контейнеров.
Распределение ресурсов
А теперь разберёмся с задачей более сложного распределения ресурсов для множества миньонов.
Вычислительный ресурс в one-cloud — это:
- Вычислительная мощность процессора, потребляемая конкретной задачей.
- Объём памяти, доступный задаче.
- Сетевой трафик. Каждый из миньонов имеет конкретный сетевой интерфейс с ограниченной пропускной способностью, поэтому нельзя распределять задачи без учёта передаваемого ими по сети объёма данных.
- Диски. Кроме, очевидно, места под данные задачи мы также выделяем тип диска: HDD или SSD. Диски могут обслужить конечное количество запросов в секунду — IOPS. Поэтому для задач, генерирующих больше IOPS, чем может обслужить один диск, мы также выделяем «шпиндели» — т. е. дисковые устройства, которые необходимо исключительно зарезервировать под задачу.
Тогда для какого-нибудь сервиса, например для user-cache, мы можем записать потребляемые ресурсы таким способом: 400 процессорных ядер, 2,5 Tб памяти, 50 Гбит/с трафика в обе стороны, 6 Тб места на HDD, размещенного на 100 шпинделях. Или в более привычной нам форме так:
alloc:
cpu: 400
mem: 2500
lan_in: 50g
lan_out: 50g
hdd:100x6TРесурсы сервиса user-cache потребляют лишь часть всех доступных ресурсов в production-инфраструктуре. Поэтому хочется сделать так, чтобы внезапно, из-за ошибки оператора или нет, user-cache не потребил больше ресурсов, чем ему выделено. То есть мы должны лимитировать ресурсы. Но к чему мы могли бы привязать квоту?
Давайте вернёмся к нашей сильно упрощённой схеме взаимодействия компонентов и перерисуем с бо́льшим количеством деталей — вот так:
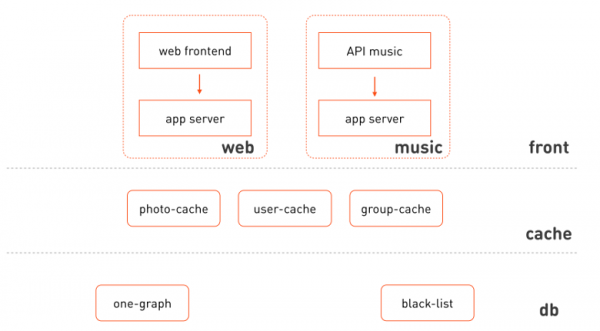
Что бросается в глаза:
- Веб-фронтенд и музыка используют изолированные кластеры одного и того же сервера приложений.
- Можно выделить логические слои, к которым относятся эти кластеры: фронты, кеши, слой хранения и управления данными.
- Фронтенд неоднороден, это разные функциональные подсистемы.
- Кеши тоже можно раскидать по подсистеме, данные которой они кешируют.
Ещё раз перерисуем картинку:
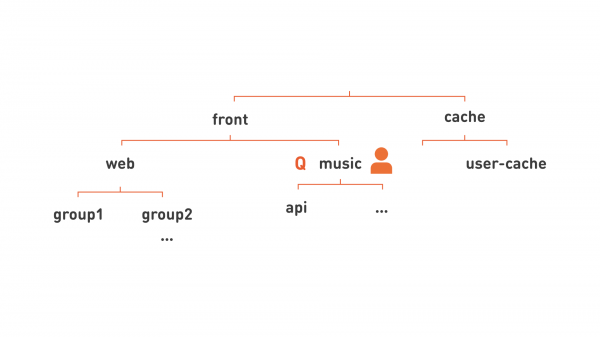
Ба! Да мы видим иерархию! А значит, можно распределять ресурсы более крупными кусками: назначить ответственного разработчика на узел этой иерархии, соответствующий функциональной подсистеме (как «music» на картинке), и к этому же уровню иерархии привязать квоту. Такая иерархия также позволяет нам более гибко организовывать сервисы для удобства управления. Например, все web, поскольку это очень большая группировка серверов, мы подразделяем на несколько более мелких групп, показанных на картинке как group1, group2.
Убрав лишние линии, мы можем записать каждый узел нашей картинки в более плоском виде: group1.web.front, api.music.front, user-cache.cache.
Так мы приходим к понятию «иерархическая очередь». У неё есть имя, как «group1.web.front». На неё назначается квота на ресурсы и права пользователей. Человеку из DevOps мы дадим права на отправку сервиса в очередь, и такой сотрудник может запускать что-то в очереди, а человеку из OpsDev — админские права, и теперь он может управлять очередью, назначать туда людей, давать этим людям права и т. д. Сервисы, запускаемые в этой очереди, будут выполняться в рамках квоты очереди. Если вычислительной квоты очереди недостаточно для единовременного выполнения всех сервисов, то они будут выполняться последовательно, формируя таким образом собственно очередь.
Рассмотрим сервисы подробнее. У сервиса есть полное имя, которое всегда включает в себя имя очереди. Тогда сервис web фронта будет иметь имя ok-web.group1.web.front. А сервис сервера приложений, к которому он обращается, станет именоваться ok-app.group1.web.front. У каждого сервиса есть манифест, в котором указывается вся необходимая информация для размещения на конкретных машинах: сколько ресурсов потребляет эта задача, какая для неё нужна конфигурация, сколько реплик должно быть, свойства для обработки отказов этого сервиса. И после размещения сервиса непосредственно на машинах появляются его экземпляры. Они тоже именуются однозначно — как номер экземпляра и имя сервиса: 1.ok-web.group1.web.front, 2.ok-web.group1.web.front, …
Это очень удобно: глядя только на имя запущенного контейнера, мы сразу можем многое выяснить.
А теперь ближе познакомимся с тем, что же эти экземпляры, собственно, выполняют: с задачами.
Классы изоляции задач
Все задачи в ОК (да и, наверное, везде) можно поделить на группы:
- Задачи с короткой задержкой — prod. Для таких задач и сервисов очень важна задержка ответа (latency), как быстро каждый из запросов будет обработан системой. Примеры задач: web фронты, кеши, серверы приложений, OLTP хранилища и т. п.
- Задачи расчетные — batch. Здесь скорость обработки каждого конкретного запроса неважна. Для них важно, сколько всего вычислений за определённый (большой) промежуток времени эта задача сделает (throughput). Такими будут любые задачи MapReduce, Hadoop, машинное обучение, статистика.
- Задачи фоновые — idle. Для таких задач не очень важны ни latency, ни throughput. Сюда входят различные тесты, миграции, пересчёты, конвертации данных из одного формата в другой. С одной стороны, они похожи на расчётные, с другой — нам не очень важно, как быстро они завершатся.
Посмотрим, как такие задачи потребляют ресурсы, например, центрального процессора.
Задачи с короткой задержкой. У такой задачи паттерн потребления ЦП будет похож на этот:
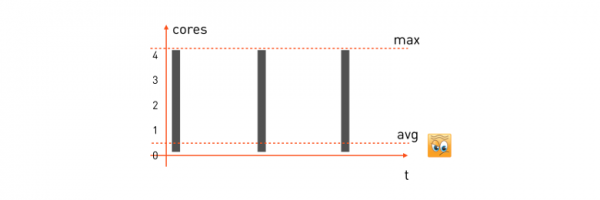
На обработку поступает запрос от пользователя, задача начинает использовать все доступные ядра ЦП, отрабатывает, возвращает ответ, ждёт следующего запроса и стоит. Поступил следующий запрос — опять выбрали всё, что было, обсчитали, ждём следующего.
Чтобы гарантировать минимальную задержку для такой задачи, мы должны взять максимум потребляемых ею ресурсов и зарезервировать нужное количество ядер на миньоне (машине, которая будет выполнять задачу). Тогда формула резервации для нашей задачи окажется такой:
alloc: cpu = 4 (max)и если у нас есть машина-миньон с 16 ядрами, то на ней можно разместить ровно четыре таких задачи. Особо отметим, что среднее потребление процессора у таких задач часто очень низкое — что очевидно, так как значительную часть времени задача находится в ожидании запроса и ничего не делает.
Расчётные задачи. У них паттерн будет несколько другим:
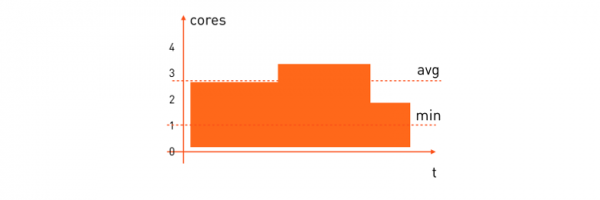
Среднее потребление ресурсов процессора у таких задач достаточно высокое. Часто мы хотим, чтобы расчётная задача выполнялась за определённое время, поэтому нужно зарезервировать минимальное количество процессоров, которое ей необходимо, чтобы весь расчёт закончился за приемлемое время. Её формула резервирования будет выглядеть так:
alloc: cpu = [1,*)«Размести, пожалуйста, на миньоне, где есть хотя бы одно свободное ядро, а дальше сколько есть — всё сожрет».
Тут с эффективностью использования уже значительно лучше, чем на задачах с короткой задержкой. Но выигрыш будет гораздо больше, если совместить оба типа задач на одной машине-миньоне и распределять её ресурсы на ходу. Когда задача с короткой задержкой требует процессор — она его получает немедленно, а когда ресурсы становятся не нужны — они передаются расчётной задаче, т. е. как-то так:
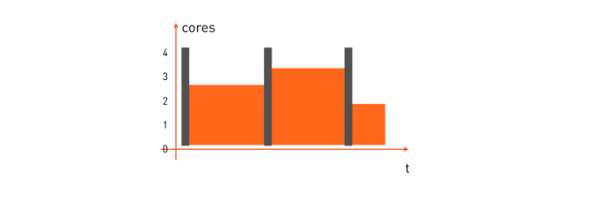
Но как это сделать?
Для начала разберемся с prod и его alloc: cpu = 4. Нам нужно зарезервировать четыре ядра. В Docker run это можно сделать двумя способами:
- С помощью опции
--cpuset=1-4, т. е. выделить задаче четыре определённых ядра на машине. - Использовать
--cpuquota=400_000 --cpuperiod=100_000, назначить квоту на процессорное время, т. е. указать, что каждые 100 мс реального времени задача потребляет не более 400 мс процессорного времени. Получаются те же самые четыре ядра.
Но какой из этих способов подойдёт?
Довольно привлекательно выглядит cpuset. У задачи четыре выделенных ядра, значит, процессорные кеши будут работать максимально эффективно. У этого есть и оборотная сторона: нам пришлось бы взять на себя задачу распределением вычислений по незагруженным ядрам машины вместо ОС, а это довольно нетривиальная задача, особенно если мы попробуем размещать на такой машине batch-задачи. Тесты показали, что здесь лучше подходит вариант с квотой: так у операционной системы больше свободы в выборе ядра для выполнения задачи в текущий момент и процессорное время распределяется более эффективно.
Разберёмся, как в docker сделать резервирование по минимальному количеству ядер. Квота для batch-задач уже неприменима, потому что ограничивать максимум не нужно, достаточно только гарантировать минимум. И тут хорошо подходит опция docker run --cpushares.
Мы договорились, что если batch требует гарантию минимум на одно ядро, то мы указываем --cpushares=1024, а если минимум на два ядра, то указываем --cpushares=2048. Cpu shares никак не вмешиваются в распределение процессорного времени до тех пор, пока его хватает. Таким образом, если prod не использует в данный момент все свои четыре ядра — ничто не ограничивает batch-задачи, и они могут использовать дополнительное процессорное время. А вот в ситуации нехватки процессора, если prod потребил все свои четыре коры и упёрся в квоту — оставшееся процессорное время будет поделено пропорционально cpushares, т. е. в ситуации трёх свободных ядер одно получит задача с 1024 cpushares, а остальные два — задача с 2048 cpushares.
Но использования quota и shares недостаточно. Нам нужно сделать так, чтобы задача с короткой задержкой получала приоритет перед batch-задачей при распределении процессорного времени. Без такой приоритизации batch-задача будет забирать всё процессорное время в момент, когда оно необходимо prod. В Docker run нет никаких опций приоритизации контейнеров, но на помощь приходят политики планировщика центрального процессора в Linux. Подробно о них можно прочитать , а в рамках этой статьи мы по ним пройдёмся кратко:
- SCHED_OTHER
По умолчанию получают все обычные пользовательские процессы на Linux-машине. - SCHED_BATCH
Предназначена для ресурсоёмких процессов. При размещении задачи в процессоре вводится так называемый штраф за активацию: такая задача с меньшей вероятностью получит ресурсы процессора, если его в данный момент использует задача с SCHED_OTHER - SCHED_IDLE
Фоновый процесс с очень низким приоритетом, даже ниже, чем nice –19. Мы используем нашу библиотеку с открытым кодом , для того чтобы поставить необходимую политику при запуске контейнера вызовом
one.nio.os.Proc.sched_setscheduler( pid, Proc.SCHED_IDLE )Но даже если вы не программируете на Java, то же самое можно сделать с помощью команды chrt:
chrt -i 0 $pidСведём все наши уровни изоляции в одну табличку для наглядности:
Класс изоляции
Пример alloc
Опции Docker run
sched_setscheduler chrt*
Prod
cpu = 4
--cpuquota=400000 --cpuperiod=100000
SCHED_OTHER
Batch
Cpu = [1, * )
--cpushares=1024
SCHED_BATCH
Idle
Cpu= [2, *)
--cpushares=2048
SCHED_IDLE
*Если вы делаете chrt изнутри контейнера, может понадобиться capability sys_nice, потому что по умолчанию Docker этот capability отнимает при запуске контейнера.
Но задачи потребляют не только процессор, но и трафик, который влияет на задержку сетевой задачи ещё больше, чем неправильное распределение ресурсов процессора. Поэтому мы, естественно, хотим получить точно такую же картинку и для трафика. То есть, когда prod-задача отсылает какие-то пакеты в сеть, мы квотируем максимальную скорость (формула alloc: lan=[*,500mbps) ), с которой prod может это делать. А для batch мы гарантируем только минимальную пропускную способность, но не ограничиваем максимальную (формула alloc: lan=[10Mbps,*) ) При этом трафик prod должен получить приоритет перед batch-задачами.
Здесь Docker не имеет никаких примитивов, которые мы могли бы использовать. Но нам на помощь приходит . Мы смогли добиться нужного результата с помощью дисциплины . С её помощью мы выделяем два класса трафика: высокоприоритетный prod и низкоприоритетный batch/idle. В итоге конфигурация для исходящего трафика получается вот такая:
здесь 1:0 — «корневой qdisc» дисциплины hsfc; 1:1 — дочерний класс hsfc с общим лимитом пропускной способности в 8 Gbit/s, под который помещаются дочерние классы всех контейнеров; 1:2 — дочерний класс hsfc общий для всех batch и idle задач с «динамическим» лимитом, о котором ниже. Остальные дочерние классы hsfc — это выделенные классы для работающих в данный момент prod-контейнеров с лимитами, соответствующими их манифестам, — 450 и 400 Mbit/s. Каждому классу hsfc назначена qdisc очередь fq или fq_codel, в зависимости от версии ядра linux, для избежания потерь пакетов при всплесках трафика.
Обычно дисциплины tc служат для приоритизации только исходящего трафика. Но мы хотим приоритизировать и входящий трафик тоже — ведь какая-нибудь batch-задача может запросто выбрать весь входящий канал, получая, например, большой пакет входных данных для map&reduce. Для этого мы используем модуль , который создаёт виртуальный интерфейс ifbX для каждого сетевого интерфейса и перенаправляет входящий трафик с интерфейса в исходящий на ifbX. Далее для ifbX работают все те же дисциплины для контроля исходящего трафика, для которого конфигурация hsfc будет очень похожей:
В ходе экспериментов мы выяснили, что лучшие результаты hsfc показывает тогда, когда класс 1:2 неприоритетного batch/idle трафика ограничивается на машинах-миньонах не более чем до некоторой свободной полосы. В противном случае неприоритетный трафик слишком сильно влияет на задержку prod-задач. Текущую величину свободной полосы miniond определяет каждую секунду, измеряя среднее потребление трафика всеми prod-задачами данного миньона  и вычитая её из пропускной способности сетевого интерфейса
и вычитая её из пропускной способности сетевого интерфейса  c небольшим запасом, т. е.
c небольшим запасом, т. е.

Полосы определяются для входящего и исходящего трафика независимо. И в соответствии с новыми значениями miniond переконфигурирует лимит неприоритетного класса 1:2.
Таким образом мы реализовали все три класса изоляции: prod, batch и idle. Эти классы сильно влияют на характеристики исполнения задач. Поэтому мы решили поместить этот признак наверх иерархии, чтобы при взгляде на имя иерархической очереди сразу было понятно, с чем мы имеем дело:
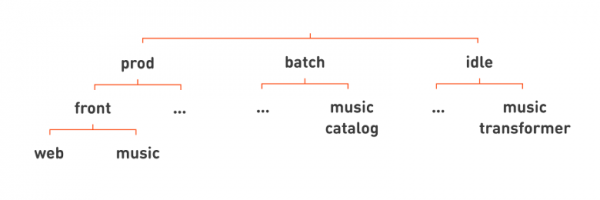
Все наши знакомые web и music фронты тогда помещаются в иерархии под prod. Для примера под batch давайте поместим сервис music catalog, который периодически составляет каталог треков из набора загруженных в «Одноклассники» mp3-файлов. А примером сервиса под idle может служить music transformer, нормализующий уровень громкости музыки.
Снова убрав лишние линии, мы можем записать имена наших сервисов более плоско, дописав класс изоляции задачи в конец полного имени сервиса: web.front.prod, catalog.music.batch, transformer.music.idle.
И теперь, глядя на имя сервиса, мы понимаем не только то, какую функцию он выполняет, но и его класс изоляции, а значит, его критичность и т. п.
Всё замечательно, но есть одна горькая правда. Полностью изолировать задачи, работающие на одной машине, невозможно.
Чего нам удалось добиться: если batch интенсивно потребляет только ресурсы процессора, то встроенный планировщик ЦП Linux очень хорошо справляется со своей задачей, и влияния на prod-задачу практически нет. Но если эта batch-задача начинает активно работать с памятью, то взаимное влияние уже проявляется. Это происходит потому, что у prod-задачи «вымываются» процессорные кеши памяти — в итоге в кеше возрастают промахи, и процессор обрабатывает prod-задачу медленнее. Такая batch-задача может на 10 % повысить задержки нашего типичного prod-контейнера.
Изолировать трафик ещё сложнее из-за того, что у современных сетевых карт есть внутренняя очередь пакетов. Если пакет от batch-задачи туда попал первым, значит, он первым и будет передан по кабелю, и тут ничего не поделаешь.
К тому же нам пока удалось решить только задачу приоритизации TCP-трафика: для UDP подход с hsfc не работает. И даже в случае с TCP-трафиком, если batch-задача генерирует много трафика, это тоже дает около 10 % увеличения задержки prod-задачи.
Отказоустойчивость
Одной из целей при разработке one-cloud было улучшение отказоустойчивости Одноклассников. Поэтому далее я хотел бы поподробнее рассмотреть возможные сценарии отказов и аварий. Давайте начнём с простого сценария — с отказа контейнера.
Контейнер сам по себе может отказать несколькими способами. Это может быть какой-то эксперимент, баг или ошибка в манифесте, из-за которой prod-задача начинает потреблять больше ресурсов, чем указано в манифесте. У нас был случай: разработчик реализовал один сложный алгоритм, много раз его переделывал, сам себя перемудрил и запутался так, что в конечном счёте задача весьма нетривиально зацикливалась. А поскольку prod-задача более приоритетная, чем все остальные на тех же миньонах, она начала потреблять все доступные ресурсы процессора. В этой ситуации спасла изоляция, а точнее квота на процессорное время. Если задаче выделена квота, задача не потребит больше. Поэтому batch- и другие prod-задачи, которые работали на той же машине, ничего не заметили.
Вторая возможная неприятность — падение контейнера. И здесь нас спасают политики рестарта, все их знают, Docker сам прекрасно справляется. Практически все prod-задачи имеют политику рестарта always. Иногда мы используем on_failure для batch-задач или для отладки prod-контейнеров.
А что можно сделать при недоступности целого миньона?
Очевидно, запустить контейнер на другой машине. Самое интересное здесь — что происходит с IP-адресом (адресами), назначенными на контейнер.
Мы можем назначать контейнерам такие же IP-адреса, как и у машин-миньонов, на которых эти контейнеры запускаются. Тогда при запуске контейнера на другой машине его IP-адрес меняется, и все клиенты должны понять, что контейнер переехал, теперь надо ходить на другой адрес, что требует отдельного сервиса Service Discovery.
Service Discovery — это удобно. На рынке много решений разной степени отказоустойчивости для организации реестра сервисов. Часто в таких решениях реализуется логика балансировщика нагрузки, хранение дополнительной конфигурации в виде KV-стораджа и т. п.
Однако, нам хотелось бы обойтись без необходимости внедрения отдельного реестра, ведь это означало бы ввод критической системы, которая используется всеми сервисами в production. А значит, это потенциальная точка отказа, и нужно выбирать или разрабатывать очень отказоустойчивое решение, что, очевидно, очень непросто, долго и дорого.
И ещё один большой недостаток: чтобы наша старая инфраструктура работала с новой, пришлось бы переписать абсолютно все задачи под использование какой-то Service Discovery системы. Работы ОЧЕНЬ много, а местами до невозможности, когда речь заходит о низкоуровневых устройствах, работающих на уровне ядра ОС или непосредственно с железом. Реализация же этой функциональности с помощью устоявшихся паттернов решений, как например означала бы местами дополнительную нагрузку, местами — усложнение эксплуатации и дополнительные сценарии отказов. Усложнять же нам не хотелось, поэтому решили сделать использование Service Discovery опциональным.
В one-cloud IP следует за контейнером, т. е. у каждого экземпляра задачи есть свой собственный IP-адрес. Этот адрес «статический»: он закрепляется за каждым экземпляром в момент первой отправки сервиса в облако. Если в течение жизни сервис имел различное количество экземпляров — то в итоге за ним будет закреплено столько IP-адресов, сколько максимально было экземпляров.
Впоследствии эти адреса не изменяются: они присвоены единожды и продолжают существовать в течение всей жизни сервиса в production. IP-адреса следует за контейнерами по сети. Если контейнер переносится на другой миньон, то и адрес перейдёт за ним.
Таким образом, сопоставление имени сервиса со списком его IP-адресов меняется очень редко. Если ещё раз посмотреть на имена экземпляров сервиса, которые мы упоминали в начале статьи (1.ok-web.group1.web.front.prod, 2.ok-web.group1.web.front.prod, …), то мы заметим, что они напоминают FQDN, использующиеся в DNS. Так и есть, для отображения имён экземпляров сервисов в их IP-адресах мы используем DNS-протокол. Причём этот DNS возвращает все зарезервированные IP-адреса всех контейнеров — и работающих, и остановленных (допустим, используется три реплики, а у нас там пять адресов зарезервированы — все пять будут возвращаться). Клиенты, получив эту информацию, попытаются установить соединение со всеми пятью репликами — и определят таким образом тех, которые работают. Такой вариант определения доступности значительно более надёжен, в нём не участвуют ни DNS, ни Service Discovery, а значит, нет и трудно решаемых задач с обеспечением актуальности информации и отказоустойчивости этих систем. Более того, в критических сервисах, от которых зависит работа всего портала, мы можем вообще не использовать DNS, а просто забивать в конфигурацию IP-адреса.
Реализация такого переноса IP за контейнерами может быть нетривиальной — и мы остановимся на том, как это работает, на следующем примере:
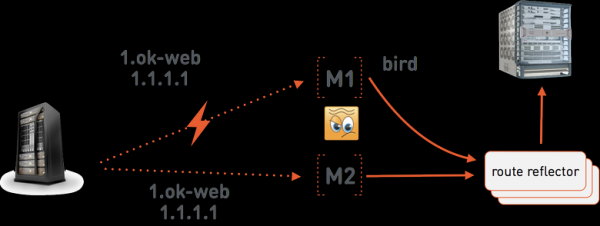
Допустим, one-cloud мастер даёт команду миньону M1 запустить 1.ok-web.group1.web.front.prod с адресом 1.1.1.1. На миньоне работает , который анонсирует этот адрес в специальные серверы . У последних есть BGP-сессия с сетевой железкой, в которую и транслируется маршрут адреса 1.1.1.1 на M1. M1 же маршрутизирует пакеты внутрь контейнера уже средствами Linux. Серверов route reflector три, так как это очень критичная часть инфраструктуры one-cloud — без них сеть в one-cloud работать не будет. Мы размещаем их в разных стойках, по возможности расположенных в разных залах дата-центра, чтобы уменьшить вероятность единовременного отказа всех трёх.
Давайте теперь предположим, что связь между мастером one-cloud и миньоном М1 пропала. Мастер one-cloud теперь будет действовать, исходя из предположения, что М1 отказал полностью. То есть даст команду миньону М2 запустить web.group1.web.front.prod с тем же самым адресом 1.1.1.1. Теперь у нас есть два конфликтующих маршрута в сети для 1.1.1.1: на М1 и на М2. Для того чтобы разрешать подобные конфликты, мы используем Multi Exit Discriminator, который указывается в BGP-анонсе. Это число, которое показывает вес анонсируемого маршрута. Из конфликтующих будет выбран маршрут с меньшим значением MED. Мастер one-cloud поддерживает MED как интегральную часть IP-адресов контейнеров. В первый раз адрес выписывается с достаточно большим MED = 1 000 000. В ситуации же такого аварийного переноса контейнера мастер уменьшает MED, и М2 уже получит команду анонсировать адрес 1.1.1.1 c MED = 999 999. Экземпляр же, работающий на M1, останется при этом без связи, и его дальнейшая судьба нас мало интересует до момента восстановления связи с мастером, когда он и будет остановлен как старый дубль.
Аварии
Все системы управления дата-центрами всегда приемлемо отрабатывают мелкие отказы. Вылет контейнера — это норма практически везде.
Давайте рассмотрим, как мы отрабатываем аварию, например отказ питания в одном или более залах дата-центра.
Что означает авария для системы управления дата-центром? В первую очередь это массированный единовременный отказ множества машин, и системе управления нужно одновременно мигрировать очень много контейнеров. Но если авария очень масштабна, то может случиться так, что все задачи не смогут быть переразмещены на других миньонах, потому что ресурсная емкость дата-центра падает ниже 100 % нагрузки.
Часто аварии сопровождаются отказом и управляющего слоя. Это может случиться из-за выхода из строя его оборудования, но чаще из-за того, что аварии не тестируются, и управляющий слой сам падает от возросшей нагрузки.
Что можно со всем этим сделать?
Массовые миграции означают, что в инфраструктуре возникает большое количество действий, миграций и размещений. Каждая из миграций может занимать какое-то время, необходимое для доставки и распаковки образов контейнеров до миньонов, запуск и инициализацию контейнеров и т. п. Поэтому желательно, чтобы более важные задачи запускались перед менее важными.
Давайте снова посмотрим на знакомую нам иерархию сервисов и попробуем решить, какие задачи мы хотим запустить в первую очередь.
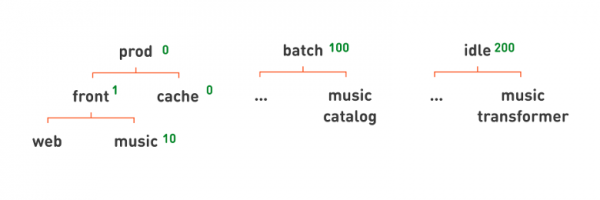
Конечно, это те процессы, которые непосредственно участвуют в обработке запросов пользователей, т. е. prod. Мы это указываем это с помощью приоритета размещения — числа, которое может быть назначено очереди. Если у какой-то очереди приоритет выше, её сервисы размещаются в первую очередь.
На prod мы назначаем приоритеты повыше, 0; на batch — чуть пониже, 100; на idle — ещё ниже, 200. Приоритеты применяются иерархически. У всех задач ниже по иерархии будет соответствующий приоритет. Если хотим, чтобы внутри prod кеши запускались перед фронтендами, то назначаем приоритеты на cache = 0 и на front подочереди = 1. Если же, например, мы хотим, чтобы из фронтов в первую очередь запускался основной портал, а music фронт уже потом, то последнему можем назначить приоритет пониже — 10.
Следующая проблема — нехватка ресурсов. Итак, у нас отказало большое количество оборудования, целые залы дата-центра, а мы поназапускали сервисов столько, что теперь на всех не хватает ресурсов. Нужно решить, какими задачами пожертвовать, чтобы работали основные критичные сервисы.
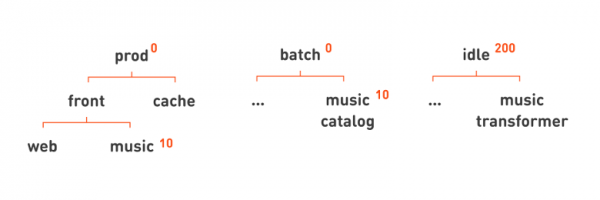
В отличие от приоритета размещения, мы не можем огульно пожертвовать всеми batch-задачами, некоторые из них важны для работы портала. Поэтому мы выделили отдельно приоритет вытеснения задачи. При размещении задача с более высоким приоритетом может вытеснить, т. е. остановить задачу с более низким приоритетом, если более нет свободных миньонов. При этом задача с низким приоритетом, вероятно, так и останется неразмещённой, т. е. для неё больше не будет подходящего миньона с достаточным количеством свободных ресурсов.
В нашей иерархии очень просто указать такой приоритет вытеснения, чтобы prod- и batch-задачи вытесняли или останавливали idle-задачи, но не друг друга, указав для idle приоритет, равный 200. Так же, как и в случае с приоритетом размещения, можем использовать нашу иерархию для того, чтобы описывать более сложные правила. Например, укажем, что функцией музыки мы жертвуем, если нам не хватит ресурсов для основного веб-портала, установив для соответствующих узлов приоритет пониже: 10.
Аварии ДЦ целиком
Почему может отказать весь дата-центр? Стихия. Был хороший пост, как . Стихией можно считать бомжей, которые спалили как-то раз в коллекторе оптику, и дата-центр полностью потерял связь с остальными площадками. Причиной выхода из строя бывает и человеческий фактор: оператор выдаст такую команду, что весь дата-центр упадёт. Такое может случиться из-за большого бага. В общем, дата-центры падают — это не редкость. У нас такое происходит раз в несколько месяцев.
И вот что мы делаем, чтобы никто #окживи не постил в твиттерах.
Первая стратегия — изоляция. Каждый инстанс one-cloud изолирован и может управлять машинами только одного дата-центра. То есть потеря облака из-за багов или неправильной команды оператора — это потеря лишь одного дата-центра. Мы к этому готовы: есть политика резервирования, при которой реплики приложения и данных размещаются во всех дата-центрах. Мы используем отказоустойчивые базы данных и периодически тестируем отказы.
Поскольку сегодня у нас четыре дата-центра, то есть и четыре отдельных, полностью изолированных экземпляра one-cloud.
Такой подход не только защищает от физического отказа, но может защитить и от ошибок оператора.
А что ещё можно сделать с человеческим фактором? Когда оператор даёт облаку какую-то странную или потенциально опасную команду, от него могут внезапно потребовать решить небольшую задачу, чтобы проверить, насколько хорошо он подумал. Например, если это какая-то массовая остановка многих реплик или просто странная команда — уменьшение количества реплик или смена имени образа, а не только номера версии в новом манифесте.
Итоги
Отличительные особенности one-cloud:
- Иерархическая и наглядная схема именования сервисов и контейнеров, которая позволяет очень быстро узнать, что это за задача, к чему она относится и как работает и кто отвечает за нее.
- Мы применяем свою технику совмещения prod- и batch-задач на миньонах, чтобы повысить эффективность совместного использования машин. Вместо cpuset мы используем CPU quotas, shares, политики планировщика CPU и Linux QoS.
- Полностью изолировать контейнеры, работающие на одной машине, так и не получилось, но их взаимное влияние остаётся в пределах до 20 %.
- Организация сервисов в иерархию помогает при автоматической ликвидации аварий при помощи приоритетов размещения и вытеснения.
ЧАВО
Почему мы не взяли готовое решение.
- Разные классы изоляции задач требуют различной логики при размещении на миньонах. Если prod-задачи можно размещать простым резервированием ресурсов, то batch и idle необходимо размещать, отслеживая реальную утилизацию ресурсов на машинах-миньонах.
- Необходимость учёта таких потребляемых задачами ресурсов, как:
- пропускная способность сети;
- типы и «шпиндели» дисков.
- Необходимость указывать приоритеты сервисов при ликвидации аварий, права и квоты команд на ресурсы, что решается с помощью иерархических очередей в one-cloud.
- Необходимость иметь человеческое именование контейнеров для уменьшения времени реакций на аварии и инциденты
- Невозможность единовременного повсеместного внедрения Service Discovery; необходимость долгое время сосуществовать с задачами, размещёнными на железных хостах, — то, что решается «статическими» IP-адресами, следующими за контейнерами, и, как следствие, необходимость уникальной интеграции с большой сетевой инфраструктурой.
Все эти функции потребовали бы значительных переделок существующих решений под себя, и, оценив количество работы, мы поняли, что сможем разработать своё решение приблизительно с теми же трудозатратами. Но своё решение будет значительно проще эксплуатировать и развивать — в нём нет ненужных абстракций, поддерживающих ненужный нам функционал.
Тем, кто читает последние строки, — спасибо за выдержку и внимание!
Источник: habr.com
