

Привет Хабр! Наборы данных для Big Data и машинного обучения экспоненциально растут и надо успевать их обрабатывать. Наш пост о еще одной инновационной технологии в области высокопроизводительных вычислений (HPC, High Performance Computing), показанной на стенде Kingston на . Это применение Hi-End систем хранения данных (СХД) в серверах с графическими процессорами (GPU) и технологией шины GPUDirect Storage. Благодаря прямому обмену данными между СХД и GPU, минуя CPU, на порядок ускоряется загрузка данных в GPU-ускорители, поэтому приложения Big Data выполняются на максимуме производительности, которую обеспечивают GPU. В свою очередь, разработчиков HPC-систем интересуют достижения в области СХД с высочайшей скоростью ввода/вывода — таких, какие выпускает Kingston.

Производительность GPU опережает загрузку данных
С тех пор, как в 2007 году была создана CUDA — программно-аппаратная архитектура параллельных вычислений на основе GPU для разработки приложений общего назначения, аппаратные возможности самих GPU выросли невероятно. Сегодня GPU находят все большее применение в области HPC-приложений, таких как большие данные (Big Data), машинное обучение (ML, machine learning) и глубокое изучение (DL, deep learning).
Отметим, что несмотря на схожесть терминов, два последних — это алгоритмически разные задачи. ML обучает компьютер на основе структурированных данных, а DL — на основе отклика от нейронной сети. Пример, помогающий понять различия, довольно прост. Предположим, что компьютер должен отличать фото кошек и собак, которые загружаются с СХД. Для ML следует подать набор изображений с множеством тегов, каждый из которых определяет какую-то одну особенность животного. Для DL достаточно загрузить намного большее число изображений, но всего лишь с одним тегом «это кошка» или «это собака». DL очень похоже на то, как учат маленьких детей — им просто показывают изображения собак и кошек в книжках и в жизни (чаще всего, даже не объясняя детальное различие), а мозг ребенка сам начинает определять тип животного после некоторого критического числа картинок для сравнения (по оценкам, речь идет всего о сотне-другой показов за все время раннего детства). Алгоритмы DL еще не настолько совершенны: чтобы также успешно могла работать над определением образов нейронная сеть, необходимо подать и обработать в GPU миллионы изображений.
Итог предисловия: на базе GPU можно строить HPC-приложения в области Big Data, ML и DL, но существует проблема — наборы данных настолько велики, что время, затрачиваемое на загрузку данных из системы хранения в GPU, начинает снижать общую производительность приложения. Иными словами, быстрые графические процессоры остаются недогруженными ввиду медленного ввода-вывода данных, поступающих от других подсистем. Разница в скорости ввода/вывода GPU и шины к CPU/СХД может быть на порядок.
Как работает технология GPUDirect Storage?
Процесс ввода-вывода контролируется CPU, также как и процесс загрузки данных из хранилища в графические процессоры для последующей обработки. Отсюда возник запрос на технологию, которая обеспечила бы прямой доступ между GPU и NVMe-дисками для быстрого взаимодействия друг с другом. Первой такую технология предложила NVIDIA и назвала ее GPUDirect Storage. По сути, это разновидность ранее разработанной ими технологии GPUDirect RDMA (Remote Direct Memory Address).
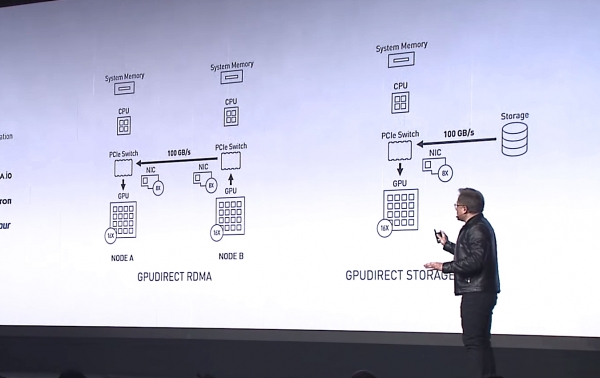
Дженсен Хуанг, генеральный директор NVIDIA, презентует GPUDirect Storage как разновидность GPUDirect RDMA на выставке SС-19. Источник: NVIDIA
Разница между GPUDirect RDMA и GPUDirect Storage — в устройствах, между которыми осуществляется адресация. Технология GPUDirect RDMA переназначена для перемещения данных непосредственно между входной картой сетевого интерфейса (NIC) и памятью GPU, а GPUDirect Storage обеспечивает прямой путь передачи данных между локальным или удаленным хранилищем, таким как NVMe или NVMe через Fabric (NVMe-oF) и памятью GPU.
Оба варианта, GPUDirect RDMA и GPUDirect Storage, избегают лишних перемещений данных через буфер в памяти CPU и позволяют механизму прямого доступа к памяти (DMA) перемещать данные от сетевой карты или хранилища сразу в память GPU или из нее — и все это без нагрузки на центральный процессор. Для GPUDirect Storage местоположение хранилища не имеет значения: это может быть NVME-диск внутри юнита с GPU, внутри стойки или подключен по сети как NVMe-oF.
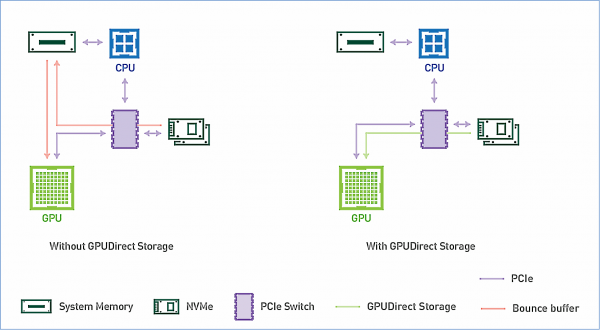
Схема работы GPUDirect Storage. Источник: NVIDIA
Hi-End СХД на NVMe востребованы на рынке HPC-приложений
Понимая, что с появлением GPUDirect Storage интерес крупных клиентов будет обращен на предложение систем хранения со скоростью ввода/вывода, соответствующей пропускной способности GPU, на выставке SC-19 Kingston показал демо системы, состоящей из СХД на базе NVMe-дисков и юнита с GPU, в которой проводился анализ тысяч спутниковых снимков в секунду. О такой СХД на базе 10 накопителей DC1000M U.2 NVMe мы уже писали .

СХД на базе 10 накопителей DC1000M U.2 NVMe достойно дополняет сервер с графическими ускорителями. Источник: Kingston
Такая СХД выполняется в виде стоечного юнита 1U или больше и может масштабироваться в зависимости от числа дисков DC1000M U.2 NVMe, где каждый емкостью 3.84-7.68 ТБ. DC1000M является первой моделью NVMe SSD в форм-факторе U.2 в линейке накопителей Kingston для дата-центров. Он обладает рейтингом выносливости (DWPD, Drive writes per day), позволяющим перезаписывать данные на полную емкость один раз в день в течение гарантированного срока службы накопителя.
В тесте fio v3.13 на операционной системе Ubuntu 18.04.3 LTS, Linux kernel 5.0.0-31-generic выставочный образец СХД показал скорость чтения (Sustained Read) 5.8 млн IOPS при устойчивой пропускной способности (Sustained Bandwidth) 23.8 Гбит/с.
Ариэль Перес, бизнес-менеджер SSD в Kingston, так охарактеризовал новые СХД: «Мы готовы снабдить следующее поколение серверов SSD-решениями U.2 NVMe, чтобы устранить многие узкие места в передаче данных, которые традиционно были связаны с системой хранения. Сочетание накопителей NVMe SSD и нашей премиальной оперативной памяти Server Premier DRAM делает Kingston одним из самых полных в отрасли поставщиков комплексных решений для обработки данных».
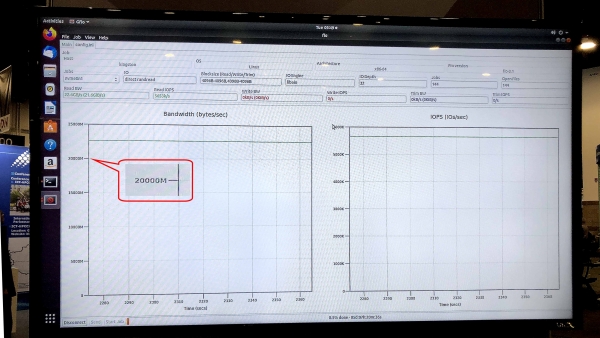
Тест gfio v3.13 показал пропускную способность 23.8 Гбит/с для демонстрационной СХД на дисках DC1000M U.2 NVMe. Источник: Kingston
Как будет выглядеть типичная система для HPC-приложений, где реализована технология GPUDirect Storage или аналогичная ей? Это архитектура с физическим разделением функциональных блоков в пределах стойки: один-два юнита на оперативную память, еще несколько на вычислительные узлы GPU и CPU и один или несколько юнитов под СХД.
С анонсом GPUDirect Storage и возможным появлением аналогичных технологий у других вендоров GPU, для Kingston расширяется спрос на СХД, рассчитанные на применение в высокопроизводительных вычислениях. Маркером будет скорость чтения данных из СХД, сопоставимая с пропускной способностью 40- или 100-Гбитных сетевых карт на входе в вычислительный юнит с GPU. Таким образом, ультраскоростные СХД, в том числе внешние NVMe через Fabric, из экзотики станут мэйнстримом для HPC-приложений. Кроме науки и финансовых расчетов, они найдут применение во многих других практических областях, таких как системы безопасности уровня мегаполиса Safe City или центров наблюдения на транспорте, где требуется скорость распознавания и идентификации на уровне миллионов HD-изображений в секунду», — обозначил рыночную нишу топовых СХД
Дополнительную информацию о продуктах Kingston можно найти на компании.
Источник: habr.com
