

Привет, Хабр! Сегодня мы построим систему, которая будет при помощи Spark Streaming обрабатывать потоки сообщений Apache Kafka и записывать результат обработки в облачную базу данных AWS RDS.
Представим, что некая кредитная организация ставит перед нами задачу обработки входящих транзакций «на лету» по всем своим филиалам. Это может быть сделано с целью оперативного расчета открытой валютой позиции для казначейства, лимитов или финансового результата по сделкам и т.д.
Как реализовать этот кейс без применения магии и волшебных заклинаний — читаем под катом! Поехали!

Введение
Безусловно, обработка большого массива данных в реальном времени предоставляет широкие возможности для использования в современных системах. Одной из популярнейших комбинаций для этого является тандем Apache Kafka и Spark Streaming, где Kafka — создает поток пакетов входящих сообщений, а Spark Streaming обрабатывает эти пакеты через заданный интервал времени.
Для повышения отказоустойчивости приложения, будем использовать контрольные точки — чекпоинты (checkpoints). При помощи этого механизма, когда модулю Spark Streaming потребуется восстановить утраченные данные, ему нужно будет только вернуться к последней контрольной точке и возобновить вычисления от нее.
Архитектура разрабатываемой системы
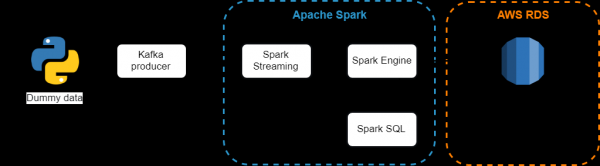
Используемые компоненты:
- — это распределенная система обмена сообщениями с публикацией и подпиской. Подходит как для автономного, так и для онлайнового потребления сообщений. Для предотвращения потери данных сообщения Kafka сохраняются на диске и реплицируются внутри кластера. Система Kafka построена поверх службы синхронизации ZooKeeper;
- — компонент Spark для обработки потоковых данных. Модуль Spark Streaming построен с применением «микропакетной» архитектуры (micro-batch architecture), когда поток данных интерпретируется как непрерывная последовательность маленьких пакетов данных. Spark Streaming принимает данные из разных источников и объединяет их в небольшие пакеты. Новые пакеты создаются через регулярные интервалы времени. В начале каждого интервала времени создается новый пакет, и любые данные, поступившие в течение этого интервала, включаются в пакет. В конце интервала увеличение пакета прекращается. Размер интервала определяется параметром, который называется интервал пакетирования (batch interval);
- — объединяет реляционную обработку с функциональным программированием Spark. Под структурированными данными подразумеваются данные, имеющие схему, то есть единый набор полей для всех записей. Spark SQL поддерживает ввод из множества источников структурированных данных и, благодаря наличию информации о схеме, он может эффективно извлекать только необходимые поля записей, а также предоставляет API-интерфейсы DataFrame;
- — это cравнительно недорогая облачная реляционная база данных, веб-сервис, который упрощает настройку, эксплуатацию и масштабирование, администрируется непосредcтвенно Amazon.
Установка и запуск сервера Kafka
Перед непосредственным использованием Kafka, необходимо убедиться в наличии Java, т.к. для работы используется JVM:
sudo apt-get update
sudo apt-get install default-jre
java -version
Создадим нового пользователя для работы с Kafka:
sudo useradd kafka -m
sudo passwd kafka
sudo adduser kafka sudo
Далее скачиваем дистрибутив с официального сайта Apache Kafka:
wget -P /YOUR_PATH "http://apache-mirror.rbc.ru/pub/apache/kafka/2.2.0/kafka_2.12-2.2.0.tgz"Распаковываем скаченный архив:
tar -xvzf /YOUR_PATH/kafka_2.12-2.2.0.tgz
ln -s /YOUR_PATH/kafka_2.12-2.2.0 kafka
Следующий шаг — опциональный. Дело в том, что настройки по умолчанию не позволяют полноценно использовать все возможности Apache Kafka. Например, удалять тему, категорию, группу, на которые могут быть опубликованы сообщения. Чтобы изменить это, отредактируем файл конфигурации:
vim ~/kafka/config/server.propertiesДобавьте в конец файла следующее:
delete.topic.enable = trueПеред запуском сервера Kafka, необходимо стартовать сервер ZooKeeper, будем использовать вспомогательный скрипт, который поставляется вместе с дистрибутивом Kafka:
Cd ~/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
После того, как ZooKeeper успешно стартовал, в отдельном терминале запускаем сервер Kafka:
bin/kafka-server-start.sh config/server.propertiesСоздадим новый топик под названием Transaction:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic transactionУбедимся, что топик с нужным количеством партиций и репликацией был создан:
bin/kafka-topics.sh --describe --zookeeper localhost:2181 
Упустим моменты тестирования продюсера и консьюмера для вновь созданного топика. Более подробно о том, как можно протестировать отправку и прием сообщений, написано в официальной документации — . Ну а мы переходим к написанию продюсера на Python с использованием KafkaProducer API.
Написание продюсера
Продюсер будет генерить случайные данные — по 100 сообщений каждую секунду. Под случайными данными будем понимать словарь, состоящий из трех полей:
- Branch — наименование точки продаж кредитной организации;
- Currency — валюта сделки;
- Amount — сумма сделки. Сумма будет положительным числом, если это покупка валюты Банком, и отрицательным — если продажа.
Код для продюсера выглядит следующим образом:
from numpy.random import choice, randint
def get_random_value():
new_dict = {}
branch_list = ['Kazan', 'SPB', 'Novosibirsk', 'Surgut']
currency_list = ['RUB', 'USD', 'EUR', 'GBP']
new_dict['branch'] = choice(branch_list)
new_dict['currency'] = choice(currency_list)
new_dict['amount'] = randint(-100, 100)
return new_dict
Далее, используя метод send, отправляем сообщение на сервер, в нужный нам топик, в формате JSON:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers=['localhost:9092'],
value_serializer=lambda x:dumps(x).encode('utf-8'),
compression_type='gzip')
my_topic = 'transaction'
data = get_random_value()
try:
future = producer.send(topic = my_topic, value = data)
record_metadata = future.get(timeout=10)
print('--> The message has been sent to a topic:
{}, partition: {}, offset: {}'
.format(record_metadata.topic,
record_metadata.partition,
record_metadata.offset ))
except Exception as e:
print('--> It seems an Error occurred: {}'.format(e))
finally:
producer.flush()
При запуске скрипта получаем в терминале следующие сообщения:
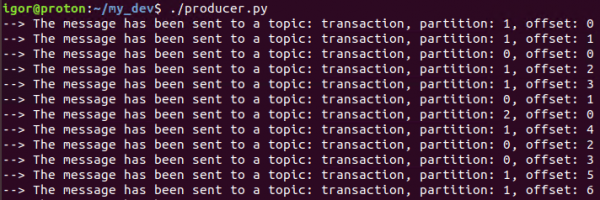
Это означает, что все работает как мы хотели — продюсер генерит и отправляет сообщения в нужный нам топик.
Следующим шагом будет установка Spark и обработка этого потока сообщений.
Установка Apache Spark
Apache Spark — это универсальная и высокопроизводительная кластерная вычислительная платформа.
По производительности Spark превосходит популярные реализации модели MapReduce, попутно обеспечивая поддержку более широкого диапазона типов вычислений, включая интерактивные запросы и потоковую обработку. Скорость играет важную роль при обработке больших объемов данных, так как именно скорость позволяет работать в интерактивном режиме, не тратя минуты или часы на ожидание. Одно из важнейших достоинств Spark, обеспечивающих столь высокую скорость, — способность выполнять вычисления в памяти.
Данный фреймворк написан на Scala, поэтому необходимо установить ее в первую очередь:
sudo apt-get install scalaСкачиваем с официального сайта дистрибутив Spark:
wget "http://mirror.linux-ia64.org/apache/spark/spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz"Распаковываем архив:
sudo tar xvf spark-2.4.2/spark-2.4.2-bin-hadoop2.7.tgz -C /usr/local/sparkДобавляем путь к Spark в bash-файл:
vim ~/.bashrcДобавляем через редактор следующие строчки:
SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
Выполняем команду ниже после внесения правок в bashrc:
source ~/.bashrcРазвертывание AWS PostgreSQL
Осталось развернуть базу данных, куда будем заливать обработанную информацию из потоков. Для этого будем использовать сервис AWS RDS.
Заходим в консоль AWS —> AWS RDS —> Databases —> Create database:
Выбираем PostgreSQL и нажимаем кнопку Next:

Т.к. данный пример разбирается исключительно в образовательных целях, будем использовать бесплатный сервер «на минималках» (Free Tier):
Далее, ставим галочку в блоке Free Tier, и после этого нам автоматом будет предложен инстанс класса t2.micro — хоть и слабенький, но бесплатный и вполне подойдет для нашей задачи:
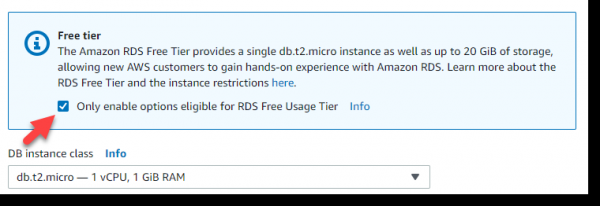
Следом идут очень важные вещи: наименование инстанса БД, имя мастер-пользователя и его пароль. Назовем инстанст: myHabrTest, мастер-пользователь: habr, пароль: habr12345 и нажимаем на кнопку Next:
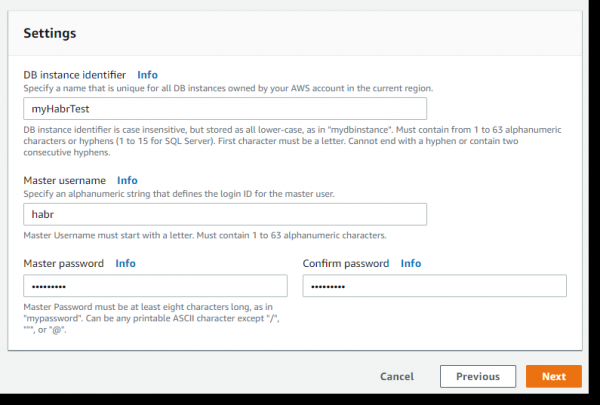
На следующей странице находятся параметры, отвечающие за доступность нашего сервера БД извне (Public accessibility) и доступность портов:
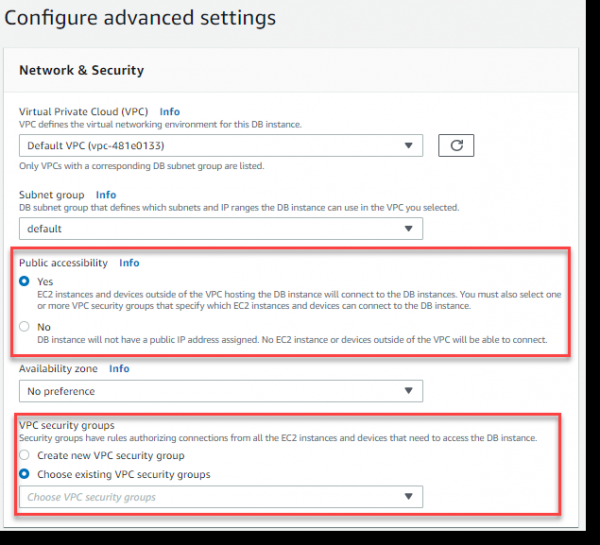
Давайте создадим новую настройку для VPC security group, которая позволит извне обращаться к нашему серверу БД через порт 5432 (PostgreSQL).
Перейдем в отдельном окне браузера к консоли AWS в раздел VPC Dashboard —> Security Groups —> Create security group:

Задаем имя для Security group — PostgreSQL, описание, указываем к какой VPC данная группа должна быть ассоциирована и нажимаем кнопку Create:

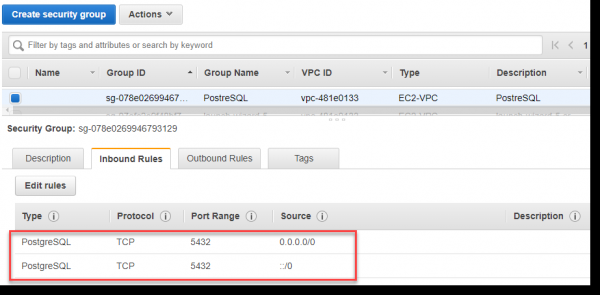
Заполняем для свежесозданной группы Inbound rules для порта 5432, как показано на картинке ниже. Вручную порт можно не указывать, а выбрать PostgreSQL из раскрывающегося списка Type.
Строго говоря, значение ::/0 означает доступность входящего траффика для сервера со всего мира, что канонически не совсем верно, но для разбора примера позволим себе использовать такой подход:
Возвращаемся к странице браузера, где у нас открыто «Configure advanced settings» и выбираем в разделе VPC security groups —> Choose existing VPC security groups —> PostgreSQL:
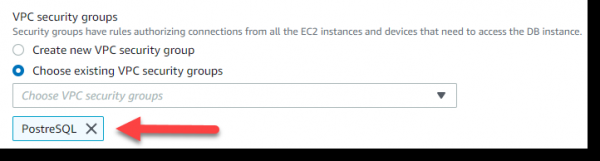
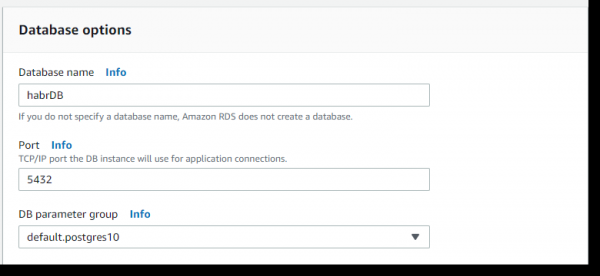
Далее, в разделе Database options —> Database name —> задаем имя — habrDB.
Остальные параметры, за исключением разве что отключения бэкапирования (backup retention period — 0 days), мониторинга и Performance Insights, можем оставить по умолчанию. Нажимаем на кнопку Create database:
Обработчик потоков
Завершающим этапом будет разработка Spark-джобы, которая будет каждые две секунды обрабатывать новые данные, пришедшие от Kafka и заносить результат в базу данных.
Как было отмечено выше, контрольные точки (сheckpoints) — это основной механизм в SparkStreaming, который должен быть настроен для обеспечения отказоустойчивости. Будем использовать контрольные точки и, в случае падения процедуры, модулю Spark Streaming для восстановления утраченных данных нужно будет только вернуться к последней контрольной точке и возобновить вычисления от нее.
Контрольную точку можно включить, установив каталог в отказоустойчивой, надежной файловой системе (например, HDFS, S3 и т. Д.), в которой будет сохранена информация контрольной точки. Это делается с помощью, например:
streamingContext.checkpoint(checkpointDirectory)В нашем примере будем использовать следующий подход, а именно, если checkpointDirectory существует, то контекст будет воссоздан из данных контрольной точки. Если каталог не существует (т.е. выполняется в первый раз), то вызывается функция functionToCreateContext для создания нового контекста и настройки DStreams:
from pyspark.streaming import StreamingContext
context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext)
Создаем объект DirectStream с целью подключения к топику «transaction» при помощи метода createDirectStream библиотеки KafkaUtils:
from pyspark.streaming.kafka import KafkaUtils
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 2)
broker_list = 'localhost:9092'
topic = 'transaction'
directKafkaStream = KafkaUtils.createDirectStream(ssc,
[topic],
{"metadata.broker.list": broker_list})
Парсим входящие данные в формате JSON:
rowRdd = rdd.map(lambda w: Row(branch=w['branch'],
currency=w['currency'],
amount=w['amount']))
testDataFrame = spark.createDataFrame(rowRdd)
testDataFrame.createOrReplaceTempView("treasury_stream")
Используя Spark SQL, делаем несложную группировку и выводим результат в консоль:
select
from_unixtime(unix_timestamp()) as curr_time,
t.branch as branch_name,
t.currency as currency_code,
sum(amount) as batch_value
from treasury_stream t
group by
t.branch,
t.currency
Получение текста запроса и запуск его через Spark SQL:
sql_query = get_sql_query()
testResultDataFrame = spark.sql(sql_query)
testResultDataFrame.show(n=5)
А затем сохраняем полученные агрегированные данные в таблицу в AWS RDS. Чтобы сохранить результаты агрегации в таблицу базы данных, будем использовать метод write объекта DataFrame:
testResultDataFrame.write
.format("jdbc")
.mode("append")
.option("driver", 'org.postgresql.Driver')
.option("url","jdbc:postgresql://myhabrtest.ciny8bykwxeg.us-east-1.rds.amazonaws.com:5432/habrDB")
.option("dbtable", "transaction_flow")
.option("user", "habr")
.option("password", "habr12345")
.save()
Несколько слов о настройке подключения к AWS RDS. Пользователя и пароль к нему мы создавали на шаге «Развертывание AWS PostgreSQL». В качестве url сервера баз данных следует использовать Endpoint, который отображается в разделе Connectivity & security:
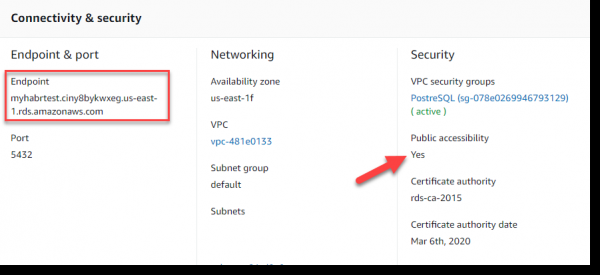
В целях корректной связки Spark и Kafka, следует запускать джобу через smark-submit с использованием артефакта spark-streaming-kafka-0-8_2.11. Дополнительно применим также артефакт для взаимодействия с базой данных PostgreSQL, их будем передавать через —packages.
Для гибкости скрипта, вынесем в качестве входных параметров также наименование сервера сообщений и топик, из которого хотим получать данные.
Итак, пришло время запустить и проверить работоспособность системы:
spark-submit
--packages org.apache.spark:spark-streaming-kafka-0-8_2.11:2.0.2,
org.postgresql:postgresql:9.4.1207
spark_job.py localhost:9092 transaction
Все получилось! Как видно на картинке ниже — в процессе работы приложения новые результаты агрегации выводятся каждые 2 секунды, потому что мы установили интервал пакетирования равным 2 секундам, когда создавали объект StreamingContext:
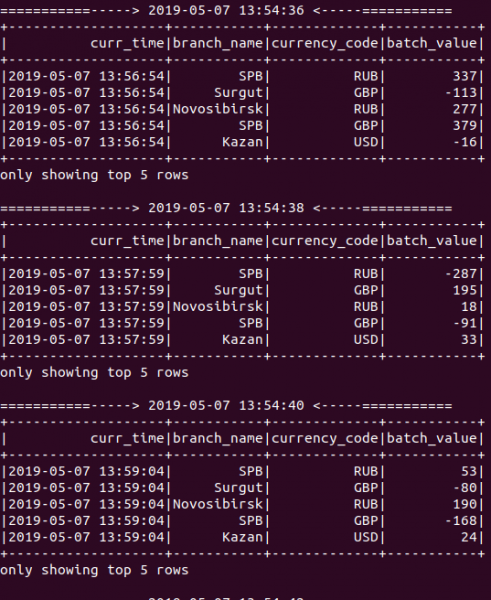
Далее, делаем нехитрый запрос к базе данных, чтобы проверить наличие записей в таблице transaction_flow:
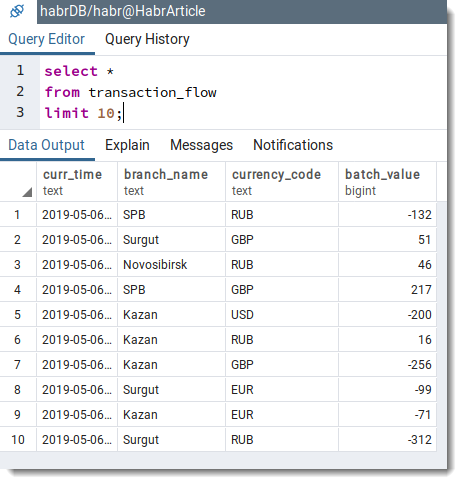
Заключение
В данной статье был рассмотрен пример поточной обработки информации с использованием Spark Streaming в связке с Apache Kafka и PostgreSQL. С ростом объемов данных из различных источников, сложно переоценить практическую ценность Spark Streaming для создания потоковых приложений и приложений, действующих в масштабе реального времени.
Полный исходный код вы можете найти в моем репозитории на .
С удовольствием готов обсудить данную статью, жду Ваших комментариев, а также, надеюсь на конструктивную критику всех неравнодушных читателей.
Желаю успехов!
Ps. Первоначально планировалось использовать локальную БД PostgreSQL, но учитывая мою любовь к AWS, я решил вынести базу данных в облако. В следующей статье по этой теме я покажу, как реализовать целиком вышеописанную систему в AWS при помощи AWS Kinesis и AWS EMR. Следите за новостями!
Источник: habr.com
