


Всем привет. Я работаю ведущим системным администратором в ОК и отвечаю за стабильную работу портала. Хочу рассказать о том, как мы выстроили процесс автоматической замены дисков, а затем, как исключили из этого процесса администратора и заменили его ботом.
Эта статья является своего рода транслитерацией на HighLoad+ 2018
Построение процесса по замене дисков
Сначала немного цифр
ОК — это гигантский сервис, которым пользуются миллионы людей. Его обслуживают около 7 тыс. серверов, которые расположены в 4 разных дата-центрах. В серверах стоит более 70 тыс. дисков. Если сложить их друг на друга, то получится башня высотой более 1 км.
Жёсткие диски — это компонент сервера, который выходит из строя чаще всего. При таких объемах нам приходится менять около 30 дисков в неделю, и эта процедура стала не очень приятной рутиной.

Инциденты
У нас в компании введен полноценный инцидент-менеджмент. Каждый инцидент мы фиксируем в Jira, а затем решаем и разбираем. Если инцидент был с эффектом для пользователей, то мы обязательно собираемся и думаем, как быстрее реагировать в таких случаях, как снизить эффект и конечно же как предотвратить повторение.
Накопители не исключение. За их состоянием следит Zabbix. Мы мониторим сообщения в Syslog на предмет ошибок записи/чтения, анализируем состояние HW/SW-рейдов, следим за SMART, для SSD вычисляем износ.
Как менялись диски раньше
Когда в Zabbix загорается какой-то триггер, в Jira создаётся инцидент и автоматически ставится на соответствующих инженеров в дата-центрах. Мы так делаем со всеми HW-инцидентами, то есть такими, которые требуют какой-либо физической работы с оборудованием в дата-центре.
Инженер дата-центра — это человек, который решает вопросы, связанные с железом, отвечает за установку, обслуживание, демонтаж серверов. Получив тикет, инженер приступает к работе. В дисковых полках он меняет диски самостоятельно. Но если у него нет доступа к нужному устройству, инженер обращается к дежурным системным администраторам за помощью. В первую очередь нужно вывести диск из ротации. Для этого нужно сделать необходимые изменения на сервере, остановить приложения, отмонтировать диск.
Дежурный системный администратор в течение рабочей смены отвечает за работу всего портала. Он расследует инциденты, занимается ремонтом, помогает разработчикам выполнять небольшие задачи. Не занимается он только жёсткими дисками.
Раньше инженеры дата-центров общались с системным администратором в чате. Инженеры слали ссылки на Jira-тикеты, администратор проходил по ним, вёл лог работ в каком-нибудь блокноте. Но для таких задач чаты неудобны: информация там не структурирована и быстро теряется. Да и администратор мог просто отойти от компьютера и какое-то время не отвечать на запросы, а инженер стоял у сервера с пачкой дисков и ждал.
Но самое плохое было в том, что администраторы не видели картины целиком: какие существуют дисковые инциденты, где потенциально может возникнуть проблема. Это связано с тем, что мы все HW-инциденты отдаём инженерам. Да, можно было отобразить все инциденты на дэшборде администратора. Но их очень много, и администратор привлекался лишь по некоторым из них.
Кроме того, инженер не мог корректно расставить приоритеты, потому что он ничего не знает о назначении конкретных серверов, о распределении информации по накопителям.
Новая процедура замены
Первое, что мы сделали, это вынесли все дисковые инциденты в отдельный тип «HW-диск» и добавили к нему поля «имя блочного устройства», «размер» и «тип диска», чтобы эта информация сохранялась в тикете, и не приходилось ей постоянно обмениваться в чате.
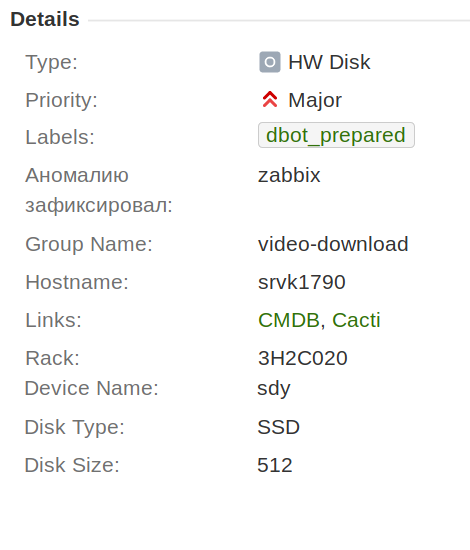
Также мы договорились, что в рамках одного инцидента будем менять только один диск. Это существенно упростило в дальнейшем процесс автоматизации, сбор статистики и работу.
Кроме этого добавили поле «ответственный администратор». Туда автоматически подставляется дежурный сисадмин. Это очень удобно, потому что теперь инженер всегда видит, кто ответственный. Не нужно идти в календарь и искать. Именно это поле позволило вынести на дэшборд администратора тикеты, в которых, возможно, понадобится его помощь.
Чтобы все участники получали максимум выгоды от нововведений, мы создали фильтры и дэшборды, рассказали о них ребятам. Когда люди понимают изменения, они не дистанцируются от них, как от чего-то ненужного. Инженеру важно знать номер стойки, где располагается сервер, размер и тип диска. Администратору нужно, в первую очередь, понимать, что это за группа серверов, какой может быть эффект при замене диска.
Наличие полей и их отображение — это удобно, но от необходимости использовать чаты нас это не избавило. Для этого пришлось менять рабочий процесс.
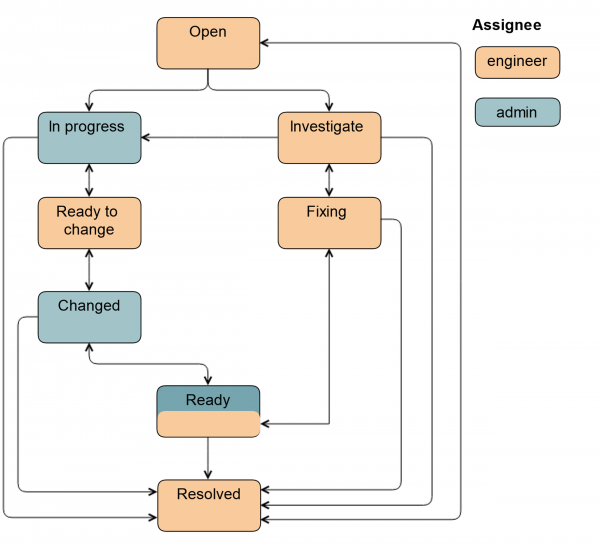
Раньше он был таким:
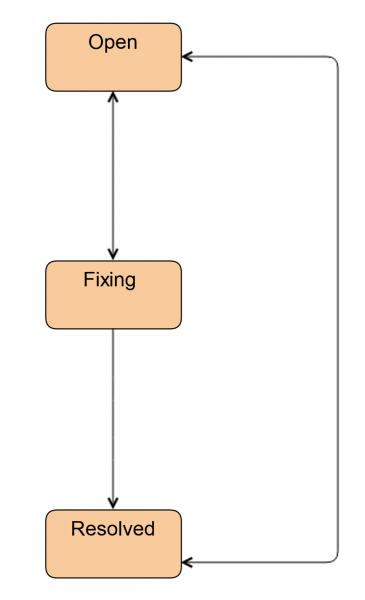
Сегодня так продолжают работать инженеры, когда им не требуется помощь администратора.
Первое, что мы сделали, — ввели новый статус Investigate. В этом статусе тикет находится, когда инженер ещё не решил, нужен ему будет администратор или нет. Через этот статус инженер может передать тикет администратору. Кроме того, этим статусом мы помечаем тикеты, когда требуется замена диска, но самого диска на площадке нет. Такое бывает в случае CDN и удаленных площадок.
Также мы добавили статус Ready. В него тикет переводится после замены диска. То есть всё уже сделано, но на сервере синхронизируется HW/SW RAID. Это может занимать довольно много времени.
Если к работе привлекается администратор, схема немного усложняется.
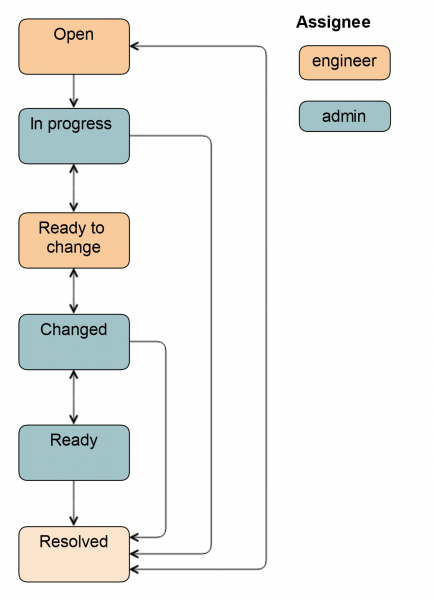
Из статуса Open тикет может перевести как системный администратор, так и инженер. В статусе In progress администратор выводит диск из ротации, чтобы инженер мог его просто вытащить: включает подсветку, отмонтирует диск, останавливает приложения, в зависимости от конкретной группы серверов.
Затем тикет переводится в Ready to change: это сигнал инженеру, что диск можно вытаскивать. Все поля в Jira уже заполнены, инженер знает, какой тип и размер диска. Эти данные проставляются либо на предыдущем статусе автоматически или администратором.
После замены диска тикет переводится в статус Changed. Проверяется, что вставили нужный диск, делается разметка, запускается приложение и какие-то задачи по восстановлению данных. Также тикет может быть переведён в статус Ready, в этом случае ответственным останется администратор, потому что он заводил диск в ротацию. Полная схема выглядит так.
Добавление новых полей существенно облегчило нам жизнь. Ребята стали работать со структурированной информацией, стало ясно, что и на каком этапе нужно делать. Приоритеты стали намного релевантнее, так как теперь их выставляет администратор.
Отпала необходимость в чатах. Конечно, администратор может написать инженеру «здесь нужно заменить быстрее», или «уже вечер, успеешь заменить?». Но мы уже не общаемся ежедневно в чатах по этим вопросам.
Диски стали менять пачками. Если администратор пришел на работу чуть пораньше, у него есть свободное время, и еще ничего не случилось, он может подготовить ряд серверов к замене: проставить поля, вывести диски из ротации и передать задачу инженеру. Инженер чуть позже приходит в дата-центр, видит задачу, берёт со склада нужные накопители и сразу меняет. В результате скорость замены увеличилась.
Вынесенный опыт при построении Workflow
- При построении процедуры нужно собирать информацию из разных источников.
Некоторые наши администраторы не знали, что инженер меняет диски самостоятельно. Некоторые считали, что за синхронизацией MD RAID следят инженеры, хотя у кого-то из них даже не было доступа для этого. Некоторые ведущие инженеры это делали, но не всегда, потому что процесс нигде не был описан. - Процедура должна быть простой и понятной.
Человеку тяжело держать в голове множество шагов. Самые главные соседние статусы в Jira нужно выносить на главный экран. Можно их переименовать, например, In progress мы называем Ready to change. А остальные статусы можно прятать в выпадающее меню, чтобы они не мозолили глаза. Но лучше не ограничивать людей, дать возможность сделать переход.
Разъясняйте ценность нововведений. Когда люди понимают, они лучше принимают новую процедуру. Для нас было очень важно, чтобы люди не прокликивали весь процесс, а шли по нему. Потом мы строили на этом автоматизацию. - Ждать, анализировать, разбираться.
У нас ушло около месяца на построение процедуры, техническую реализацию, встречи и обсуждения. А на внедрение — больше трёх месяцев. Я видел, как люди потихоньку начинают пользоваться нововведением. На первых этапах было много негатива. Но он совершенно не зависел от самой процедуры, её технической реализации. Например, один администратор пользовался не Jira, а Jira-плагином в Confluence, и некоторые вещи были ему недоступны. Показали ему Jira, у админа выросла продуктивность и по общим задачам, и по заменам дисков.
Автоматизация замены дисков
К автоматизации замены дисков мы подступались несколько раз. У нас уже были наработки, скрипты, но все они работали либо в интерактивном, либо в ручном режиме, требовали запуска. И только после внедрения новой процедуры мы поняли, что как раз её нам не хватало.
Так как теперь процесс замены у нас разбит на этапы, за каждым из которых определён исполнитель и список действий, мы можем включать автоматизацию поэтапно, а не сразу целиком. Например, самый простой этап — Ready (проверка синхронизации RAID/данных) можно легко делегировать боту. Когда бот чуть обучится, можно ему дать более ответственную задачу — ввод диска в ротацию итд.
Зоопарк сетапов
Прежде чем рассказывать про бота, совершим небольшой экскурс в наш зоопарк инсталляций. В первую очередь он обусловлен гигантским размером нашей инфраструктуры. Во-вторых, под каждый сервис мы стараемся подобрать оптимальную конфигурацию железа. У нас около 20 моделей аппаратных RAID, в основном LSI и Adaptec, но встречаются и HP, и DELL разных версий. Каждый RAID-контроллер имеет свою утилиту управления. Набор команда и выдача по ним может отличаться от версии к версии у каждого RAID-контроллера. Там, где не используются HW-RAID, может быть mdraid.
Практически все новые инсталляции мы делаем без дискового резервирования. Мы стараемся больше не использовать аппаратные и софтовые RAID, так как резервируем наши системы на уровне дата-центров, а не серверов. Но конечно есть много legacy-серверов, которые нужно поддерживать.
Где-то диски в RAID-контроллерах прокидываются raw устройства, где-то используются JBOD. Есть конфигурации с одним системным диском в сервере, и если его нужно заменить, то приходится перераскатывать сервер с установкой ОС и приложений, причем тех же версий, потом добавлять конфигурационные файлы, запускать приложения. Также очень много групп серверов, где резервирование осуществляется не на уровне дисковой подсистемы, а непосредственно в самих приложениях.
В общей сложности у нас более 400 уникальных групп серверов, на которых работает около 100 различных приложений. Чтобы покрыть такое огромное количество вариантов, нам нужен был многофункциональный инструмент автоматизации. Желательно с простым DSL, чтобы поддерживать мог не только тот, кто это написал.
Мы выбрали Ansible, потому что он agentless: не нужно было подготавливать инфраструктуру, быстрый старт. К тому же, он написан на Python, который принят как стандарт в команде.
Общая схема
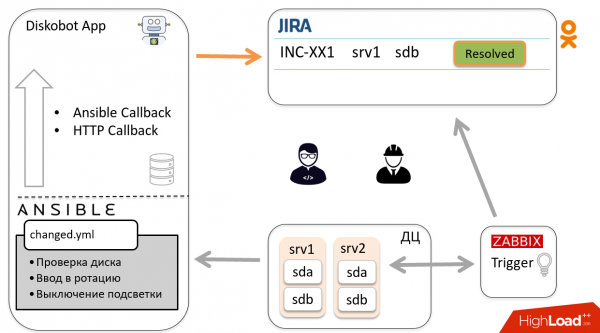
Давайте рассмотрим общую схему автоматизации на примере одного инцидента. Zabbix детектирует, что диск sdb вышел из строя, загорается триггер, создаётся тикет в Jira. Администратор посмотрел его, понял, что это не дубликат и не false positive, то есть нужно менять диск, и переводит тикет в In progress.
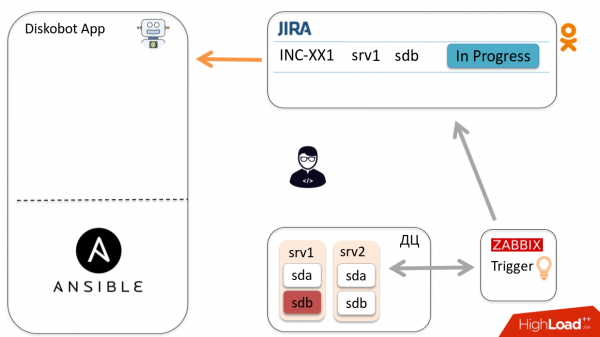
Приложение DiskoBot, написанное на Python, периодически опрашивает Jira на предмет новых тикетов. Оно замечает, что появился новый тикет In progress, срабатывает соответствующий thread, который запускает playbook в Ansible (это делается для каждого статуса в Jira). В данном случае запускается Prepare2change.
Ansible отправляется на хост, выводит диск из ротации и репортит статус приложению через Callbacks.
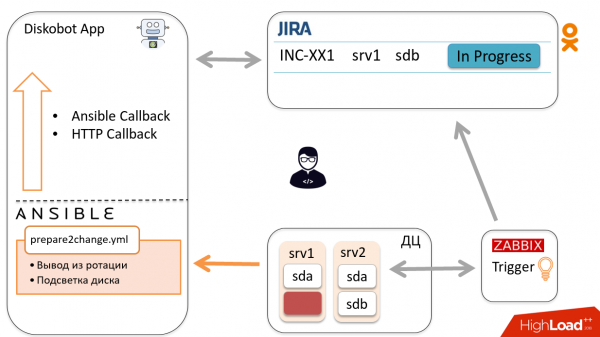
По результатам бот автоматически переводит тикет в Ready to change. Инженер получает уведомление и отправляется менять диск, после чего переводит тикет в Changed.
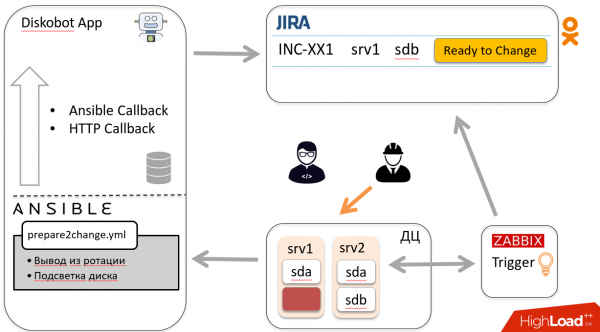
По вышеописанной схеме тикет попадает обратно к боту, тот запускает другой playbook, идет на хост и вводит диск в ротацию. Бот закрывает тикет. Ура!
Теперь поговорим о некоторых компонентах системы.
Diskobot
Это приложение написано на Python. Оно выбирает тикеты из Jira в соответствии с JQL. В зависимости от статуса тикета последний попадает к соответствующему обработчику, который в свою очередь запускает соответствующий статусу Ansible playbook.
JQL и интервалы опроса определены в файле конфигурации приложения.
jira_states:
investigate:
jql: '… status = Open and "Disk Size" is EMPTY'
interval: 180
inprogress:
jql: '… and "Disk Size" is not EMPTY and "Device Name" is not EMPTY'
ready:
jql: '… and (labels not in ("dbot_ignore") or labels is EMPTY)'
interval: 7200
Например, среди тикетов в статусе In progress, выбираются только те у которых заполнены поля Disk size и Device name. Device name — это имя блочного устройства, нужного для выполнения playbook’а. Disk size нужен для того, чтобы инженер знал какого размера диск необходим.
А среди тикетов со статусом Ready отфильтровываются тикеты с лейблом dbot_ignore. К слову, Jira лейблы мы используем как для подобной фильтрации, так и для маркирования дубликатов тикетов, и сбора статистики.
В случае сбоя playbook’а Jira присваивает лейбл dbot_failed, чтобы впоследствии можно было разобраться.
Взаимодействие с Ansible
Приложение взаимодействует с Ansible через . В playbook_executor мы передаем имя файла и набор переменных. Это позволяет держать Ansible-проект в виде обычных yml-файлов, а не описывать его в Python-коде.
Также в Ansible через *extra_vars* передаются имя блочного устройства, статус тикета, а также callback_url, в котором зашит issue key — он используется для callback в HTTP.
Для каждого запуска генерируется временный inventory, состоящий из одного хоста и группы, в которую входит этот хост, чтобы применились group_vars.
Вот пример таска, в котором реализован HTTP callback.
Результат выполнения playbook’ов мы получаем с помощью callaback(-ов). Они двух типов:
- , он предоставляет данные по результатам выполнения playbook’а. Там описаны задачи, которые были запущены, выполнены удачно или неудачно. Этот callback вызывается по окончанию проигрывания playbook’а.
- HTTP callback для получения информации во время проигрывания playbook’а. В Ansible таске выполняем POST/GET запроc в строну нашего приложения.
Через HTTP callback(-и) передаются переменные, которые были определены при выполнении playbook’а и которые мы хотим сохранить и использовать в последующих запусках. Эти данные мы пишем в sqlite.
Также через HTTP callback мы оставляем комментарии и изменяем статус тикета.
HTTP callback
# Make callback to Diskobot App
# Variables:
# callback_post_body: # A dict with follow keys. All keys are optional
# msg: If exist it would be posted to Jira as comment
# data: If exist it would be saved in Incident.variables
# desire_state: Set desire_state for incident
# status: If exist Proceed issue to that status
- name: Callback to Diskobot app (jira comment/status)
uri:
url: "{{ callback_url }}/{{ devname }}"
user: "{{ diskobot_user }}"
password: "{{ diskobot_pass }}"
force_basic_auth: True
method: POST
body: "{{ callback_post_body | to_json }}"
body_format: json
delegate_to: 127.0.0.1
Как и многие однотипные таски, мы вынесли его в отдельный common file и включаем при необходимости, чтобы не повторять постоянно в playbook’ах. Здесь фигурирует callback_ url, в котором зашиты issue key и host name. Когда Ansible выполняет этот POST-запрос, бот понимает, что он пришел в рамках такого-то инцидента.
А вот пример из playbook’а, в котором мы выводили диск из MD-устройства:
# Save mdadm configuration
- include: common/callback.yml
vars:
callback_post_body:
status: 'Ready to change'
msg: "Removed disk from mdraid {{ mdadm_remove_disk.msg | comment_jira }}"
data:
mdadm_data: "{{ mdadm_remove_disk.removed }}"
parted_info: "{{ parted_info | default() }}"
when:
- mdadm_remove_disk | changed
- mdadm_remove_disk.removed
Данный таск переводит Jira тикет в статус «Ready to change» и добавляет комментарий. Также в переменной mdam_data сохраняется список md-устройств, из которых был удален диск, а в parted_info — дамп партиции от parted.
Когда инженер вставит новый диск, мы сможем использовать эти переменные, чтобы восстановить дамп партиций, а также завести диск в те md-устройства, из которых он был удален.
Ansible check mode
Включать автоматику было страшно. Поэтому мы решили запускать все playbook’и в режиме
, в котором Ansible не выполняет на серверах никаких действий, а только эмулирует их.
Такой запуск прогоняется через отдельный callback-модуль, а результат выполнения playbook’а сохраняем в Jira в виде комментария.
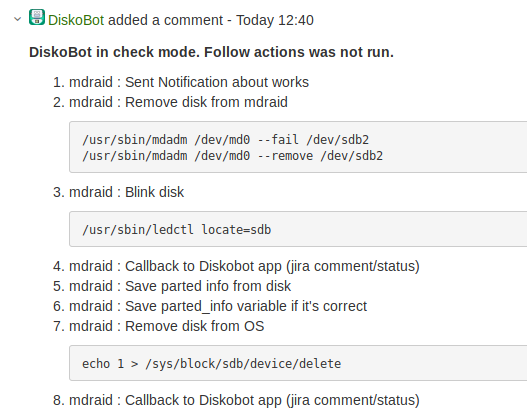
Во-первых, это позволило валидировать работу бота и playbook’ов. Во-вторых, повысило доверие администраторов к боту.
Когда мы прошли валидацию и поняли, что можно запускать Ansible не только в режиме dry run, то сделали в Jira кнопку Run Diskobot для запуска того же playbook’а с теми же самыми переменными на том же самом хосте, но в обычном режиме.
Кроме того, кнопка используется для повторного запуска playbook’а в случае его сбоя.
Структура Playbooks
Я уже упоминал, что в зависимости от статуса Jira-тикета, бот запускает разные playbook’и.
Во-первых, так намного проще организовать вход.
Во-вторых, в некоторых случаях это просто необходимо.
К примеру, при замене системного диска нужно в первую очередь пойти в систему развёртывания, создать задачу, и после корректного развёртывания сервер станет доступен по ssh, и можно на него накатить приложение. Если бы мы делали всё это в одном плейбуке, то Ansible не смог бы его выполнить из-за недоступности хоста.
Мы используем Ansible-роли для каждой группы серверов. Здесь видно, как организованны playbook(-и) в одной из них.
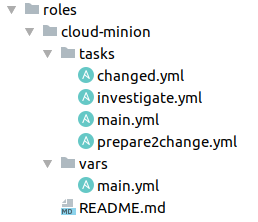
Это удобно, потому что сразу понятно, где какие таски расположены. В main.yml, который является входом для Ansible-роли, у нас может быть просто include по статусу тикета или общие таски, необходимые для всех, например, прохождение идентификации или получение токена.
Investigation.yml
Запускается для тикетов в статусе Investigation и Open. Самое важное для этого playbook’а — имя блочного устройства. Эта информация не всегда доступна.
Для её получения мы анализируем Jira summary, последнее значение от Zabbix-триггера. Там может содержаться имя блочного устройства — повезло. А может содержаться mount point, — тогда нужно пойти на сервер, пропарсить и вычислить нужный диск. Также триггер может передать scsi-адрес или какую-то другую информацию. Но бывает и так, что никаких зацепок нет, и приходится анализировать.
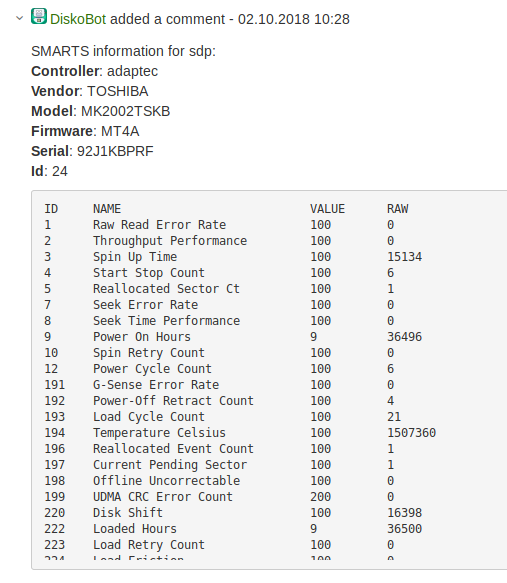
Выяснив имя блочного устройства, мы собираем по нему информацию о типе и размере диска для заполнения полей в Jira. Также снимаем информацию о вендоре, модели, прошивке, ID, SMART, и всё это вставляем в комментарий в Jira-тикете. Администратору и инженеру теперь не нужно искать эти данные. 🙂
prepare2change.yml
Вывод диска из ротации, подготовка к замене. Cамый сложный, ответственный этап. Именно здесь можно остановить приложение, когда его нельзя останавливать. Или вытащить диск, у которого не хватало реплик, и тем самым оказать эффект на пользователей, потерять какие-то данные. Здесь у нас больше всего проверок и нотификаций в чате.
В самом простом случае речь идёт об удалении диска из HW/MD RAID.
В более сложных ситуациях (в наших системах хранения), когда резервирование выполняется на уровне приложения, необходимо пойти в приложение по API, сообщить о выводе диска, деактивировать его и запустить восстановление.
Мы сейчас массово мигрируем в , и если сервер облачный, то Diskobot обращается к API облака, говорит, что он собирается работать с этим миньоном — сервером, на котором запущены контейнеры, — и просит «смигрируй все контейнеры с этого миньона». И заодно включает подсветку диска, чтобы инженер сразу увидел, какой нужно вытаскивать.
changed.yml
После замены диска мы в первую очередь проверяем его доступность.
Инженеры не всегда ставят новые диски, поэтому мы добавили проверку удовлетворяющих нас значений SMART.
Какие атрибуты мы смотримReallocated Sectors Count (5) < 100
Current Pending Sector Count (107) == 0
Если диск не проходит проверку, инженеру сообщается о повторной замене. Если всё в порядке, подсветка выключается, наносится разметка и диск вводится в ротацию.
ready.yml
Cамый простой случай: проверка синхронизации HW/SW raid или окончание синхроназации данных в приложении.
API приложений
Я несколько раз упоминал о том, что часто бот обращается к API приложений. Конечно, не у всех приложений были необходимые методы, поэтому пришлось их доработать. Вот самые важные методы, которые мы используем:
- Status. Статус кластера или диска, чтобы понять можно ли с ним работать;
- Start/stop. Активация-деактивация диска;
- Migrate/restore. Миграция и восстановление данных во время и после замены.
Вынесенный опыт по Ansible
Я очень люблю Ansible. Но часто, когда смотрю на разные opensource-проекты и вижу, как люди пишут playbook’и, мне становится немного страшно. Сложные логические переплетения из when/loop, отсутствие гибкости и идемпотентности из-за частого использования shell/command.
Мы решили максимально всё упростить, воспользовавшись преимуществом Ansible — модульностью. На самом верхнем уровне находятся playbook’и, их может писать любой администратор, сторонний разработчик, который чуть-чуть знает Ansible.
- name: Blink disk
become: True
register: locate_action
disk_locate:
locate: '{{ locate }}'
devname: '{{ devname }}'
ids: '{{ locate_ids | default(pd_id) | default(omit) }}'
Если какую-то логику сложно реализовать в playbook’ах, мы выносим её в Ansible-модуль или фильтр. Скрипты могут быть написаны как на Python, так и на любом другом языке.
Их легко и быстро писать. Например, модуль подсветки диска, пример использования которого приведен выше, состоит из 265 строк.

На самом нижнем уровне находится библиотека. Для этого проекта мы написали отдельное приложение, своего рода абстракцию над аппаратными и софтовыми RAID, которые выполняют соответствующие запросы.
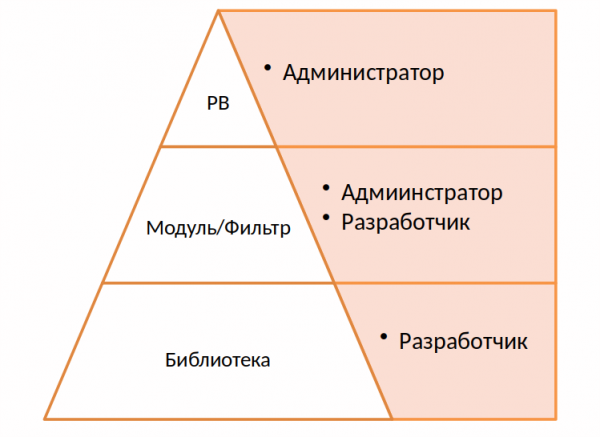
Самые сильные стороны Ansible — это простота и понятные playbook’и. Я считаю, что нужно этим пользоваться и не генерировать страшные yaml-файлы и огромное количество условий, shell-кода и лупов.
Если вы захотите повторить наш опыт с Ansible API, имейте в виду две вещи:
- Playbook_executor и вообще playbook’у нельзя передать таймаут. Есть таймаут на ssh-сессии, но нет таймаута на playbook. Если мы пытаемся отмонтировать диск, который в системе уже не существует, playbook будет выполняться бесконечно, поэтому пришлось обернуть его запуск в отдельный wrapper и убивать по таймауту.
- Ansible работает на базе fork-процессов, поэтому его API не потокобезопасно. Мы запускаем все наши playbook’и однопоточно.
В итоге нам удалось автоматизировать замену около 80 % дисков. В целом скорость замены выросла в два раза. Сегодня администратор лишь смотрит на инцидент и принимает решение, нужно ли менять диск или нет, а затем делает один клик.
Но теперь мы начинаем сталкиваться с другой проблемой: некоторые новые администраторы не знают, как менять диски. 🙂
Источник: habr.com
