

KDB+, продукт компании — это широко известная в узких кругах, исключительно быстрая, колоночная база данных, предназначенная для хранения временных рядов и аналитических вычислений на их основе. Изначально она пользовалась (и пользуется) большой популярностью в индустрии финансов — ее используют все топ-10 инвестиционных банков и многие известные хедж-фонды, биржи и другие организации. В последнее время в KX решили расширить клиентскую базу и теперь предлагают решения и в других областях, где имеется большое количество данных, упорядоченных по времени или иным образом — телеком, биоинформатика, производство и т.д. В том числе они стали партнером команды Aston Martin Red Bull Racing в «Формуле 1», где помогают собирать и обрабатывать данные с датчиков болидов и анализировать тесты в аэродинамической трубе. В этой статье я хочу рассказать, какие особенности KDB+ делают ее сверхпроизводительной, почему компании готовы тратить на нее большие деньги, наконец, почему это на самом деле не база данных.

В этой статье я постараюсь рассказать в целом, что представляет из себя KDB+, какие возможности и ограничения имеет, в чем ее польза для компаний, желающих обрабатывать большие объемы данных. Я не буду вдаваться в детали реализации KDB+ и в детали ее языка программирования Q. Обе эти темы очень обширны и заслуживают отдельных статей. Много информации по этим темам можно найти на сайте code.kx.com, в том числе книгу по Q — Q For Mortals (см. ссылку ниже).
Некоторые термины
- In-memory база данных. База данных, которая хранит данные в оперативной памяти для ускорения доступа. Достоинства такой базы понятны, а недостатки — возможность потери данных, необходимость иметь много памяти на сервере.
- Колоночная база данных. База данных, где данные хранятся поколоночно, а не запись за записью. Основное достоинство такой базы в том, что данные из одной колонки хранятся вместе на диске и в памяти, что значительно ускоряет доступ к ним. Нет необходимости грузить колонки, которые не используются в запросе. Основной недостаток — сложно модифицировать и удалять записи.
- Временной ряд. Данные с колонкой типа дата или время. Как правило, для таких данных важна упорядоченность по времени, чтобы можно было легко определить, какая запись предшествует или следует за текущей, или чтобы применять функции, результат которых зависит от порядка записей. Классические базы данных построены на совершенно другом принципе — представлении совокупности записей как множества, где порядок записей в принципе не определен.
- Вектор. В контексте KDB+ — это список элементов одного атомарного типа, например, чисел. Другими словами, массив элементов. Массивы, в отличие от списков, можно хранить компактно и обрабатывать, используя векторные инструкции процессора.
Историческая справка
Компания KX была основана в 1993 году Артуром Уитни, который до этого работал в банке Морган Стэнли над языком A+, наследником APL — очень оригинальным и в свое время популярным языком в финансовом мире. Разумеется, в KX Артур продолжил в том же духе и создал векторно-функциональный язык K, руководствуясь идеями радикального минимализма. Программы на K выглядят как беспорядочный набор знаков препинания и специальных символов, смысл знаков и функций зависит от контекста, и каждая операция несет в себе намного больше смысла, чем это бывает в привычных языках программирования. За счет этого программа на K занимает минимум места — несколько строчек могут заменить страницы текста многословного языка типа Java — и является сверхконцентрированной реализацией алгоритма.
Функция на K, реализующая большую часть генератора LL1 парсера по заданной грамматике:
1. pp:{q:{(x;p3(),y)};r:$[-11=@x;$x;11=@x;q[`N;$*x];10=abs@@x;q[`N;x]
2. ($)~*x;(`P;p3 x 1);(1=#x)&11=@*x;pp[{(1#x;$[2=#x;;,:]1_x)}@*x]
3. (?)~*x;(`Q;pp[x 1]);(*)~*x;(`M;pp[x 1]);(+)~*x;(`MP;pp[x 1]);(!)~*x;(`Y;p3 x 1)
4. (2=#x)&(@x 1)in 100 101 107 7 -7h;($[(@x 1)in 100 101 107h;`Ff;`Fi];p3 x 1;pp[*x])
5. (|)~*x;`S,(pp'1_x);2=#x;`C,{@[@[x;-1+#x;{x,")"}];0;"(",]}({$[".s.C"~4#x;6_-2_x;x]}'pp'x);'`pp];
6. $[@r;r;($[1<#r;".s.";""],$*r),$[1<#r;"[",(";"/:1_r),"]";""]]}
Эту философию экстремальной эффективности при минимуме телодвижений Артур воплотил и в KDB+, которая появилась в 2003 году (думаю, теперь понятно откуда буква K в названии) и есть ни что иное, как интерпретатор четвертой версии языка K. Поверх K добавлена более приятная взгляду пользователя версия K под названием Q. В Q также добавлена поддержка специфического диалекта SQL — QSQL, а в интерпретатор — поддержка таблиц, как системного типа данных, средств работы с таблицами в памяти и на диске и т.п.
Таким образом, с точки зрения пользователя KDB+ — это просто интерпретатор языка Q с поддержкой таблиц и похожих на SQL выражений в стиле LINQ из C#. Это важнейшее отличие KDB+ от других баз данных и главное ее конкурентное преимущество, которое часто упускают из вида. Это не база данных + вспомогательный язык-инвалид, а полноценный мощный язык программирования + встроенная поддержка функций базы данных. Это различие будет играть определяющую роль при перечислении всех преимуществ KDB+. Например…
Размер
По современным меркам KDB+ имеет просто микроскопический размер. Это в буквальном смысле один исполняемый файл размером меньше мегабайта и один небольшой текстовый файл с некоторыми системными функциями. Реально — меньше одного мегабайта и за эту программу компании платят десятки тысяч долларов в год за один процессор на сервере.
- Такой размер позволяет KDB+ прекрасно себя чувствовать на любом железе — от микрокомпьютера Pi до серверов с терабайтами памяти. На функциональность это никак не влияет, более того стартует Q мгновенно, что позволяет его использовать в том числе как скриптовой язык.
- При таком размере интерпретатор Q полностью помещается в кеш процессора, что ускоряет выполнение программ.
- При таком размере исполняемого файла процесс Q занимает ничтожно мало места в памяти, можно запускать их сотнями. При этом при необходимости Q может оперировать и десятками-сотнями гигабайт памяти в рамках одного процесса.
Универсальность
Q прекрасно подходит для самых разных задач. Процесс Q может выполнять роль исторической базы данных и предоставлять быстрый доступ к терабайтам информации. У нас, например, есть десятки исторических баз, в некоторых из которых один несжатый день данных занимает больше 100 гигабайт. Тем не менее, при разумных ограничениях запрос к базе будет выполнен за десятки-сотни миллисекунд. В целом на запросы пользователей у нас есть универсальный таймаут — 30 секунд — и он срабатывает очень редко.
С той же легкостью Q может быть in-memory базой данных. Добавление новых данных к таблицам в памяти происходит настолько быстро, что лимитирующим фактором являются запросы пользователей. Данные в таблицах хранятся по колонкам, а значит любая операция по колонке будет использовать кеш процессора на полную мощность. В добавление к этому в KX постарались реализовать все базовые операции типа арифметических через векторные инструкции процессора, максимизируя их скорость. Q может выполнять и задачи не свойственные базам данным — например, обрабатывать потоковые данные и вычислять в «реальном времени» (с задержкой от десятков миллисекунд до нескольких секунд в зависимости задачи) различные агрегирующие функции для финансовых инструментов для разных временных интервалов или строить модель влияния совершенной сделки на рынок и проводить ее профилирование практически сразу после ее совершения. В таких задачах чаще всего основную временную задержку вносит не Q, а необходимость синхронизации данных из разных источников. Высокая скорость достигается благодаря тому, что данные и функции, которые их обрабатывают, находятся в одном процессе, а обработка сводится к выполнению нескольких QSQL выражений и джойнов, которые не интерпретируются, а выполняются бинарным кодом.
Наконец, на Q можно писать и любые сервисные процессы. Например, Gateway процессы, которые автоматически распределяют запросы пользователей по нужным базам и серверам. Программист имеет полную свободу реализовать любой алгоритм для балансирования, приоритизации, отказоустойчивости, прав доступа, квот и вообще чего душе угодно. Главная проблема тут, что придется все это реализовывать самому.
Для примера я перечислю, какие типы процессов есть у нас. Все они активно используются и работают совместно, объединяя в одно целое десятки различных баз, обрабатывая данные из множества источников и обслуживая сотни пользователей и приложений.
- Коннекторы (feedhandler) к источникам данных. Эти процессы используют как правило внешние библиотеки, которые грузятся в Q. С-интерфейс в Q исключительно прост и позволяет без труда создать прокси функции для любой С/C++ библиотеки. Q достаточно быстр, чтобы справиться, например, с обработкой потока FIX сообщений со всех европейских стоковых бирж одновременно.
- Распределители данных (tickerplant), которые служат промежуточным звеном между коннекторами и потребителями. Одновременно, они пишут входящие данные в специальный бинарный лог, обеспечивая устойчивость для потребителей к потерям соединения или перезапускам.
- In-memory базы данных (rdb). Эти базы обеспечивают максимально быстрый доступ к сырым свежим данным, храня их в памяти. Как правило, они накапливают данные в таблицах в течение дня и обнуляют их ночью.
- Persist базы данных (pdb). Эти базы обеспечивают сохранение данных за сегодняшний день в историческую базу. Как правило, в отличие от rdb, они не хранят данные в памяти, а используют специальный кеш на диске в течении дня и копируют данные в полночь в историческую базу.
- Исторические базы (hdb). Эти базы обеспечивают доступ к данным за предыдущие дни, месяцы и годы. Размер их (в днях) ограничен только размером жестких дисков. Данные могут располагаться где угодно, в частности на разных дисках для ускорения доступа. Есть возможность сжимать данные, используя несколько алгоритмов на выбор. Структура базы хорошо документирована и проста, данные хранятся поколоночно в обычных файлах, так что их можно обрабатывать в том числе средствами операционной системы.
- Базы с агрегированной информацией. Хранят различные агрегации, как правило с, группированные по названию инструмента и интервалу времени. In-memory базы обновляют свое состояние при каждом входящем сообщении, а исторические хранят предвычисленные данные для ускорения доступа к историческим данным.
- Наконец, gateway процессы, обслуживающие приложения и пользователей. Q позволяет реализовать полностью асинхронную обработку входящих сообщений, распределение их по базам, проверку прав доступа и т.п. Замечу, что сообщения не ограничиваются и чаще всего не являются SQL выражениями, как это бывает в других базах данных. Чаще всего SQL выражение скрыто в специальной функции и конструируется исходя из параметров, запрошенных пользователем — проводится конвертация времени, фильтрация, данные нормализуются (например, цена акций выравнивается, если была выплата дивидендов) и т.п.
Типичная архитектура для одного типа данных:
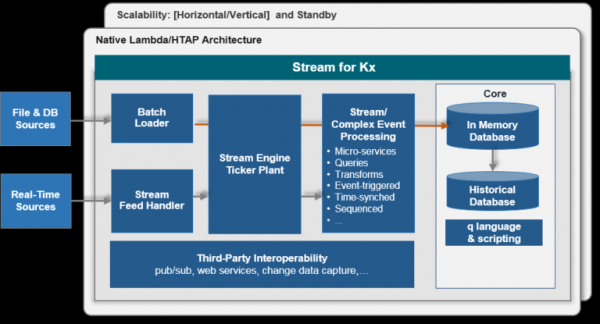
Скорость
Хотя Q является интерпретируемым языком, это одновременно векторный язык. Это означает, что многие встроенные функции, в частности, арифметические, принимают аргументы любой формы — числа, вектора, матрицы, списки, а от программиста ожидается, что он будет реализовывать программу как операции над массивами. В таком языке, если вы складываете два вектора по миллиону элементов, уже не играет роли, что язык интерпретируемый, сложение будет производиться супероптимизированной бинарной функцией. Поскольку львиная доля времени в программах на Q уходит на операции с таблицами, использующими эти базовые векторизованные функции, то на выходе имеем весьма приличную скорость работы, позволяющую обрабатывать огромный объем данных даже в одном процессе. Это похоже на математические библиотеки в питоне — хотя сам питон язык весьма небыстрый, в нем есть много прекрасных библиотек типа numpy, которые позволяют обрабатывать числовые данные со скоростью компилируемого языка (кстати, numpy идеологически близка к Q).
Помимо этого в KX весьма тщательно подошли к проектированию таблиц и оптимизации работы с ними. Во-первых, поддерживается несколько видов индексов, которые поддерживаются встроенными функциями и могут быть применены не только к колонкам таблиц, но и к любым векторам — группировка, сортировка, атрибут уникальности и специальная группировка для исторических баз. Индекс накладывается элементарно и автоматически корректируется при добавлении элементов в колонку/вектор. Индексы одинаково успешно могут накладываться на колонки таблиц как в памяти, так и на диске. При выполнении QSQL запроса индексы используются автоматически, если это возможно. Во-вторых, работа с историческими данными сделана через механизм отображения файлов ОС (memory map). Большие таблицы никогда не грузятся в память, вместо этого нужные колонки отображаются непосредственно в память и реально грузится только та их часть (тут помогают в том числе индексы), которая необходима. Для программиста нет разницы, находятся данные в памяти или нет, механизм работы с mmap полностью скрыт в недрах Q.
KDB+ не реляционная база данных, таблицы могут содержать произвольные данные, при этом порядок строк в таблице не меняется при добавлении новых элементов и может и должен использоваться при написании запросов. Эта особенность остро необходима для работы с временными рядами (данные с бирж, телеметрия, логи событий), потому что если данные отсортированы по времени, то пользователю не нужно применять никаких SQL трюков, чтобы найти в таблице первую или последнюю по времени строку или N строк, определить какая строка следует за N-й строкой и т.п. Еще больше упрощаются джойны таблиц, например найти для 16000 сделок VOD.L (Водафон) последнюю котировку в таблице из 500 миллионов элементов занимает около секунды на диске и десяток миллисекунд в памяти.
Пример джойна по времени — quote таблица отображается в память, поэтому нет необходимости указывать VOD.L в where, неявно используются индекс на sym колонке и тот факт, что данные отсортированы по времени. Почти все джойны в Q — это обычные функции, а не часть select выражения:
1. aj[`sym`time;select from trade where date=2019.03.26, sym=`VOD.L;select from quote where date=2019.03.26]
Наконец, стоит отметить, что инженеры в KX, начиная с самого Артура Уитни, реально помешаны на эффективности и предпринимают все усилия, чтобы выжать максимум из стандартных функций Q и оптимизировать наиболее частые патерны использования.
Итог
KDB+ популярна у бизнеса в первую очередь благодаря своей исключительной универсальности — она одинаково хорошо служит и как in-memory база, и как база для хранения терабайт исторических данных, и как платформа для анализа данных. Благодаря тому, что обработка данных происходит непосредственно в базе, достигается высокая скорость работы и экономия ресурсов. Полноценный язык программирования, интегрированный с функциями базы данных, позволяет реализовать на одной платформе весь стек необходимых процессов — от получения данных, до обработки запросов пользователей.
Дополнительные сведения
Недостатки
Существенным недостатком KDB+/Q является высокий порог вхождения. Язык имеет странный синтаксис, некоторые функции сильно перегружены (value, например, имеет порядка 11 вариантов использования). Самое главное, он требует радикально другого подхода к написанию программ. В векторном языке необходимо все время мыслить в терминах преобразований массивов, все циклы реализовывать через несколько вариантов функций map/reduce (которые называются adverbs в Q), никогда не пытаться сэкономить, заменяя векторные операции атомарными. Например, для нахождения индекса N-го вхождения элемента в массив следует писать:
1. (where element=vector)[N]
хотя это выглядит жутко неэффективно по меркам C/Java (= создает булевый вектор, where возвращает индексы true элементов в нем). Но такая запись делает смысл выражения более понятным и вы используете быстрые векторные операции вместо медленных атомарных. Концептуальная разница между векторным языком и остальными сравнима с разницей между императивным и функциональным подходами к программированию, и к этому надо быть готовым.
Некоторые пользователи также бывают недовольны QSQL. Дело в том, что он только похож на настоящий SQL. На деле же это просто интерпретатор SQL-подобных выражений, который не поддерживает оптимизацию запросов. Пользователь должен сам писать оптимальные запросы, причем на Q, к чему многие оказываются не готовы. С другой стороны, конечно, всегда можно самому написать оптимальный запрос, а не полагаться на черный ящик-оптимизатор.
Как плюс книга по Q — Q For Mortals доступна бесплатно на , также там собрано много других полезных материалов.
Еще один большой минус — стоимость лицензии. Это десятки тысяч долларов в год за один CPU. Только большие фирмы могут позволить себе такие траты. В последнее время KX сделала лицензионную политику более гибкой и предоставляет возможность платить только за время использования или арендовать KDB+ в облаках Гугл и Амазон. Также KX предлагает для скачивания (32 битная версия или 64-битная по запросу).
Конкуренты
Существует довольно много специализированных баз, построенных на похожих принципах — колоночные, in-memory, ориентированные на очень большие объемы данных. Проблема в том, что это именно специализированные базы данных. Яркий пример — Clickhouse. У этой базы данных очень похожий на KDB+ принцип хранения данных на диске и строения индекса, некоторые запросы она выполняет быстрее KDB+, хотя и не существенно. Но даже как база данных Clickhouse является более специализированной чем KDB+ — web аналитика vs произвольные временные ряды (это различие очень важно — из-за него, например, в Clickhouse нет возможности использовать упорядоченность записей). Но, главное, у Clickhouse нет универсальности KDB+, языка, который позволил бы обрабатывать данные непосредственно в базе, а не грузить их предварительно в отдельное приложение, строить произвольные SQL выражения, применять произвольные функции в запросе, создавать процессы не связанные с исполнением функций исторической базы. Поэтому сложно сравнивать KDB+ с другими базами, они могут быть лучше в отдельных сценариях использования или просто лучше, если речь идет о задачах классических баз данных, но мне неизвестен другой столь же эффективный и универсальный инструмент для обработки временных данных.
Интеграция с Python
Чтобы упростить работу с KDB+ для людей, не знакомых с технологией, KX создали библиотеки для тесной интеграции с Python в рамках одного процесса. Можно как вызывать любую python-функцию из Q, так и наоборот — вызывать любую Q функцию из Python (в частности QSQL выражения). Библиотеки конвертируют при необходимости (ради эффективности не всегда) данные из формата одного языка в формат другого. В итоге Q и Python живут в таком тесном симбиозе, что границы между ними стираются. В результате программист, с одной стороны, имеет полный доступ к многочисленным полезным библиотекам Python, с другой стороны, он получает интегрированную в Python быструю базу для работы с большими данными, что особенно полезно тем, кто занимается машинным обучением или моделированием.
Работа с Q в Python:
1. >>> q()
2.q)trade:([]date:();sym:();qty:())
3. q)
4. >>> q.insert('trade', (date(2006,10,6), 'IBM', 200))
5. k(',0')
6. >>> q.insert('trade', (date(2006,10,6), 'MSFT', 100))
7. k(',1')
Ссылки
Сайт компании —
Сайт для разработчиков —
Книга Q For Mortals (на английском) —
Статьи на тему применений KDB+/Q от сотрудников kx —
Источник: habr.com
