

Прим. перев.: Этот материал продолжает замечательный цикл статей от технологического евангелиста из AWS — Adrian Hornsby, — задавшегося целью просто и понятно объяснить важность экспериментов, призванных смягчить последствия сбоев в ИТ-системах.

«Если провалил подготовку плана, то планируешь провал». — Бенджамин Франклин
В данной серии статей я представил концепцию chaos engineering’а и объяснил, как он помогает находить и исправлять изъяны в системе до того, как они приведут к сбоям production. Также было рассказано о том, как хаос-инжиниринг способствует позитивным культурным изменениям внутри организаций.
В конце первой части я пообещал рассказать об «инструментах и способах внедрения сбоев в системы». Увы, у моей головы на сей счет имелись собственные планы, и в этой статье я попытаюсь ответить на самый популярный вопрос, возникающий и людей, желающих заняться хаос-инжинирингом: Что ломать в первую очередь?
Отличный вопрос! Впрочем, эту панду он, похоже, не особо беспокоит…

Не связывайтесь с хаос-пандой!
Краткий ответ: Цельтесь в критические сервисы на пути запроса.
Длинный, но более вразумительный ответ: Чтобы понять, с чего следует начинать эксперименты с хаосом, обратите внимание на три области:
- Посмотрите на историю сбоев и выявите закономерности;
- Определитесь с критическими зависимостями;
- Воспользуйтесь т. н. эффектом сверхуверенности.
Забавно, но эту часть с тем же успехом можно было назвать «Путешествие к самопознанию и просвещению». В ней же мы начнем «играть» с некоторым прикольными инструментами.
1. Ответ лежит в прошлом
Если помните, в первой части я ввел понятие Correction-of-Errors (COE) — метода, с помощью которого мы анализируем наши промахи: промахи в технологии, процессе или организации, — чтобы понять их причину(-ы) и предотвратить повторение в будущем. В общем, с этого и следует начинать.
«Чтобы понять настоящее, нужно знать прошлое». — Карл Саган
Посмотрите на историю сбоев, проставьте теги в СОЕ или postmortem’ах и классифицируйте их. Выявите общие закономерности, которые часто приводят к проблемам, и для каждого СОЕ задайте себе следующий вопрос:
«Можно ли это было предвидеть, а следовательно, предотвратить с помощью внедрения неисправности?»
Я вспоминаю один сбой в самом начале моей карьеры. Его можно было бы легко предотвратить, если бы мы провели пару простейших хаос-экспериментов:
В нормальных условиях экземпляры backend’а отвечают на health check’и от ). ELB использует эти проверки для перенаправления запросов на «здоровые» экземпляры. Когда оказывается, что некий экземпляр «нездоров», ELB перестает направлять на него запросы. Однажды, после успешной маркетинговой кампании, объем трафика вырос, и backend’ы начали отвечать на health check’и медленнее, чем обычно. Следует сказать, что эти health check’и были , то есть проводилась проверка состояния зависимостей.
Тем не менее, некоторое время все было в порядке.
Затем, уже находясь в довольно напряженных условиях, один из экземпляров приступил к выполнению некритической, регулярной cron-задачи из разряда ETL. Комбинация высокого трафика и cronjob’а подстегнула загрузку ЦПУ почти на 100%. Перегрузка процессора еще сильнее замедлила ответы на health check’и — настолько, что ELB решил, что экземпляр испытывает проблемы в работе. Как и ожидалось, балансировщик перестал распределять трафик на него, что, в свою очередь, привело к возрастанию нагрузки на остальные экземпляры в группе.
Внезапно все остальные экземпляры также начали проваливать health check.
Запуск нового экземпляра требовал загрузки и установки пакетов и занимал гораздо больше времени, чем требовалось ELB на их отключение — одного за другим — в группе автомасштабирования. Понятно, что вскоре весь процесс достиг критической отметки и приложение упало.
Тогда мы навсегда уяснили следующие моменты:
- Устанавливать ПО при создании нового экземпляра долго, лучше отдать предпочтение неизменному (immutable) подходу и .
- В сложных ситуациях ответы на health-check’и ELB должны иметь приоритет — меньше всего вы хотите усложнить жизнь оставшимся экземплярам.
- Хорошо помогает локальное кэширование health-check’ов (даже на несколько секунд).
- В сложной ситуации не запускайте cron-задачи и другие некритические процессы — берегите ресурсы для самых важных задач.
- При автомасштабировании используйте меньшие по размеру экземпляры. Группа из 10 малых экземпляров лучше, чем из 4 больших; если один экземпляр упадет, в первом случае 10% трафика распределятся по 9 точкам, во втором — 25% трафика по трем точкам.
Итак, можно ли это было предвидеть, а следовательно — предотвратить с помощью внедрения проблемы?
Да, и несколькими способами.
Во-первых, имитацией высокой загрузки CPU с помощью таких инструментов, как или :
❯ stress-ng --matrix 1 -t 60s 
stress-ng
Во-вторых, перегрузкой экземпляра с помощью и других похожих утилит:
❯ wrk -t12 -c400 -d20s http://127.0.0.1/api/health 
Эксперименты сравнительно простые, но могут дать неплохую пищу для размышлений без необходимости переживать стресс реального сбоя.
Однако не останавливайтесь на достигнутом. Попробуйте воспроизвести сбой в тестовой среде и проверить свой ответ на вопрос «Можно ли это было предвидеть, а следовательно — предотвратить с помощью внедрения неисправности?». Это мини хаос-эксперимент внутри хаос-эксперимента для проверки предположений, но начиная со сбоя.

Это был сон, или все случилось на самом деле?
Так что изучайте историю сбоев, анализируйте COE, тегируйте и классифицируйте их по «радиусу поражения» — или, точнее, по числу затронутых клиентов, — а затем ищите закономерности. Спрашивайте себя, можно ли это было предвидеть и предотвратить путем внедрения проблемы. Проверяйте свой ответ.
Затем переключайтесь на самые распространенные паттерны с наибольшим радиусом поражения.
2. Постройте карту зависимостей
Выберите минутку, чтобы подумать о своем приложении. Есть ли четкая карта его зависимостей? Знаете ли вы, какое влияние они окажут в случае сбоя?
Если вы не очень хорошо знакомы с кодом своего приложения или оно стало слишком большим, может быть трудно понять, что делает код и каковы его зависимости. Понимание этих зависимостей и их возможного влияния на приложение и пользователей критически важно для представления о том, с чего начать хаос-инжиниринг: отправной точкой будет выступать компонент с наибольшим радиусом поражения.
Выявление и документирование зависимостей именуют «построением карты зависимостей» (dependency mapping). Обычно оно проводится для приложений с обширной базой кода с использованием инструментов для профилирования кода (code profiling) и инструментирования (instrumentation). Также можно проводить построение карты, отслеживая сетевой трафик.
При этом не все зависимости одинаковы (что еще сильнее усложняет процесс). Некоторые критически важны, другие — второстепенны (по крайней мере теоретически, поскольку сбои часто возникают из-за проблем с зависимостями, которые считались некритическими).
Без критических зависимости сервис не может работать. Некритические зависимости «не должны» оказывать влияния на сервис в случае своего падения. Чтобы разобраться с зависимостями, необходимо иметь четкое представление об API, используемых приложением. Это может быть намного сложнее, чем кажется — по крайней мере, для крупных приложений.
Начните с перебора всех API. Выделите самые значимые и критические. Возьмите зависимости из репозитория кода, изучите логи подключений, затем просмотрите документацию (конечно, если она существует — иначе у вас еще большие проблемы). Задействуйте инструменты для профилирования и трассировки, отфильтруйте внешние вызовы.
Можно воспользоваться программами вроде netstat — утилитой командной строки, которая выводит список всех сетевых подключений (активных сокетов) в системе. Например, чтобы вывести все текущие соединения, наберите:
❯ netstat -a | more 
В AWS можно использовать (flow logs) VPC — метод, позволяющий собрать информацию об IP-трафике, идущем к сетевым интерфейсам в VPC или от них. Такие логи способны помочь и с другими задачами — например, с поиском ответа на вопрос, почему определенный трафик не достигает экземпляра.
Также можно использовать . X-Ray позволяет получить подробный, «конечный» (end-to-end) обзор запросов по мере их продвижения по приложению, а также строит карту базовых компонентов приложения. Очень удобно, если нужно выявить зависимости.
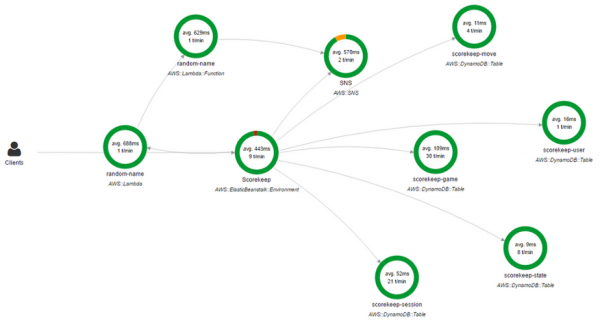
Консоль AWS X-Ray
Карта сетевых зависимостей — лишь частичное решение. Да, она показывает, какое приложение с каким связывается, но ведь есть и другие зависимости.
Многие приложения используют DNS для подключения к зависимостям, в то время как другие могут использовать механизм обнаружения сервисов или даже жестко прописанные IP-адреса в конфигурационных файлах (к примеру, в /etc/hosts).
Например, можно создать с помощью iptables и посмотреть, что сломается. Для этого введите следующую команду:
❯ iptables -I OUTPUT -p udp --dport 53 -j REJECT -m comment --comment "Reject DNS" 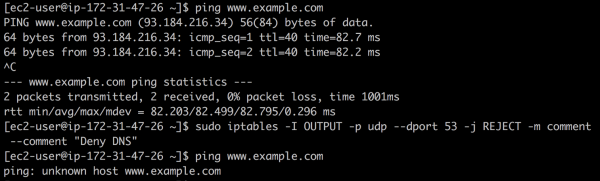
«Черная дыра» DNS
Если в /etc/hosts или других конфигурационных файлах вы обнаружите IP-адреса, о которых ничего не знаете (да, к сожалению, и такое бывает), на выручку снова может прийти iptables. Скажем, вы обнаружили 8.8.8.8 и не знаете, что это адрес общедоступного DNS-сервера Google. С помощью iptables можно закрыть входящий и исходящий трафик к этому адресу с помощью следующих команд:
❯ iptables -A INPUT -s 8.8.8.8 -j DROP -m comment --comment "Reject from 8.8.8.8"
❯ iptables -A OUTPUT -d 8.8.8.8 -j DROP -m comment --comment "Reject to 8.8.8.8" 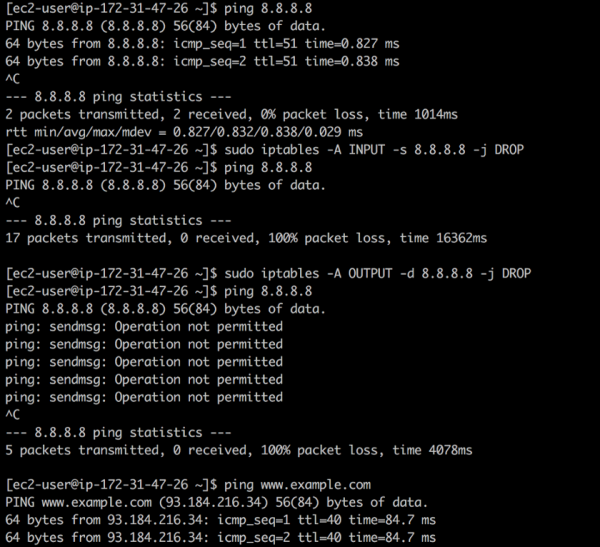
Закрытие доступа
Первое правило отбрасывает все пакеты с публичного DNS Google: ping работает, но пакеты не возвращаются. Второе правило отбрасывает все пакеты, исходящие из вашей системы в направлении публичного DNS Google — в ответ на ping получаем Operation not permitted.
Примечание: в этом конкретном случае было бы лучше использовать whois 8.8.8.8, но это всего лишь пример.
Можно забраться еще глубже в кроличью нору, поскольку все, что использует TCP и UDP, на самом деле зависит и от IP. В большинстве случаев IP завязан на ARP. Не стоит забывать и о firewall’ах…

Выберешь красную пилюлю — останешься в Стране Чудес, и я покажу, насколько глубоко уходит кроличья нора»
Более радикальный подход состоит в том, чтобы отключать машины одну за одной и смотреть, что сломалось… станьте «обезьяной хаоса». Конечно, многие production-системы не рассчитаны на подобную грубую атаку, но по крайней мере ее можно попробовать в тестовой среде.
Построение карты зависимостей — часто весьма долгое мероприятие. Недавно я разговаривал с клиентом, что потратил почти 2 года на разработку инструмента, который в полуавтоматическом режиме генерирует карты зависимостей для сотен микросервисов и команд.
Результат, однако, чрезвычайно интересен и полезен. Вы узнаете много нового о своей системе, ее зависимостях и операциях. Опять же, будьте терпеливы: наибольшее значение имеет само путешествие.
3. Остерегайтесь самонадеянности
«Кто о чем мечтает, тот в то и верит». — Демосфен
Вы когда-нибудь слышали об эффекте сверхуверенности?
Согласно Википедии, эффект сверхуверенности — это «когнитивное искажение, при котором уверенность человека в своих действиях и решениях значительно выше, чем объективная точность этих суждений, особенно когда уровень уверенности относительно высок».
Основываясь на чутье и опыте…
По своему опыту могу сказать, что это искажение — отличный намек на то, с чего следует начинать хаос-инжиниринг.
Остерегайтесь самоуверенного оператора:
Чарли: «Эта штука не падала лет пять, все в норме!»
Сбой: «Ждите… скоро буду!»
Предвзятость как последствие самоуверенности — вещь коварная и даже опасная из-за различных факторов, влияющих на нее. Это особенно справедливо, когда члены команды вложили душу в некую технологию или потратили кучу времени на «исправления».
Подвожу итоги
Поиски отправной точки для хаос-инжиниринга всегда приносят больше результатов, чем ожидалось, и команды, начинающие слишком быстро ломать все вокруг, упускают из виду более глобальную и интересную суть (хаос-)инжиниринга — творческое применение научных методов и эмпирических доказательств для проектирования, разработки, эксплуатации, обслуживания и совершенствования (программных) систем.
На этом вторая часть подходит к концу. Пожалуйста, пишите отзывы, делитесь мнениями или просто хлопайте в ладоши на . В следующей части я действительно рассмотрю инструменты и методы по внедрению сбоев в системы. До тех пор — пока!
P.S. от переводчика
Читайте также в нашем блоге:
- «»;
- «»;
- «»;
- «».
Источник: habr.com
