


Обсудим почему CI-инструменты и CI – это совсем про разное.
Какую боль CI призвано решить, откуда возникла идея, какие последние подтверждения что оно работает, как понять что у вас есть именно практика, а не просто установленный Jenkins.
Мысль сделать доклад про Continuous Integration появилась еще год назад, когда я ходил по собеседованиям искал работу. Пообщался с 10-15 компаниями, из них только одна смогла вразумительно ответить что такое CI и объяснить как они поняли, что у них этого нет. Остальные же несли невразумительную чушь про Jenkins 🙂 Ну вот у нас есть Jenkins, он делает сборки, CI! За доклад постараюсь объяснить что же такое Continuous Integration на самом деле и почему Jenkins и подобные инструменты имеют очень слабое к этому отношению.

И так, что обычно приходит в голову при слове CI? Большинству людей придет в голову Jenkins, Gitlab CI, Travis и т.п.

Даже если мы загуглим, то нам выдаст эти инструменты.
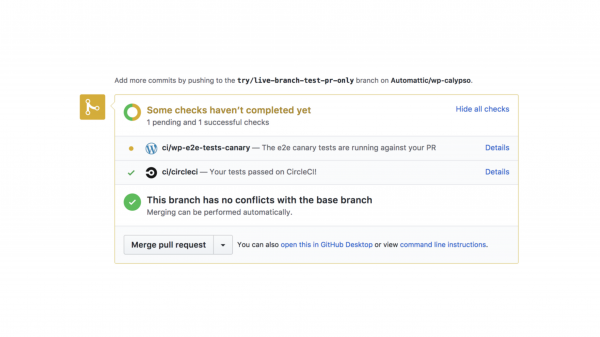
Если спрашивать знакомы, то сразу после перечисления инструментов, вам расскажут что CI это когда у вас в Pull Request на коммит происходит сборка и прогон тестов.
Continuous Integration это не про инструменты, не про сборки с тестами в ветке! Continuous Integration это практика очень частой интеграции нового кода и для ее применения совершенно не обязательно городить Jenkins-ы, GitLab-ы и т.п.

Прежде чем мы разберемся как выглядит полноценный CI, давайте сначала погрузимся в контекст людей, которые это придумали, и прочувствуем ту боль, которую они пытались решить.

А решали они боль совместной работы в команде!

Давайте посмотрим на примерах, с какими сложностями сталкиваются разработчики при командной разработке. Вот у нас есть проект, master-ветка в git и два разработчика.

И пошли они работать как все давно привыкли. Взяли задачу в жире, завели feature branch, пишут код.
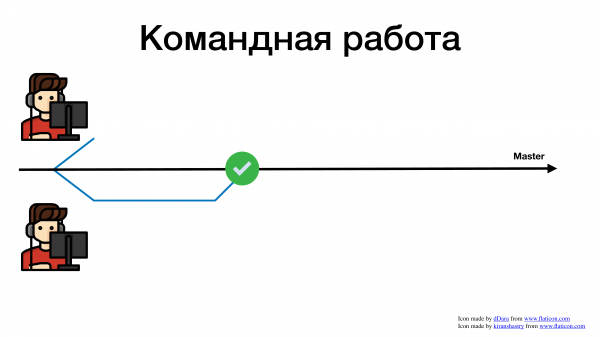
Один закончил фичу быстрее и смержил в мастер.
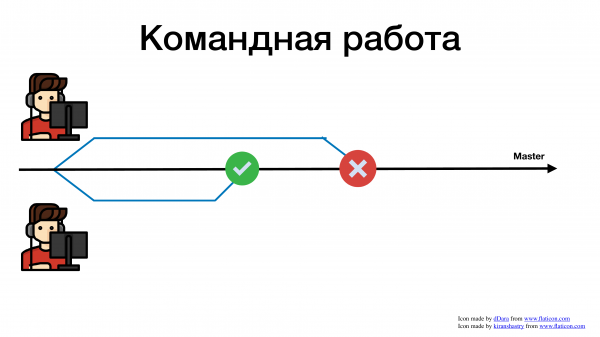
Второму понадобилось больше времени, он смержился позже и получил конфликт. Теперь, вместо того чтобы писать нужные бизнесу фичи, разработчик тратит свое время и силы на разрешение конфликтов.
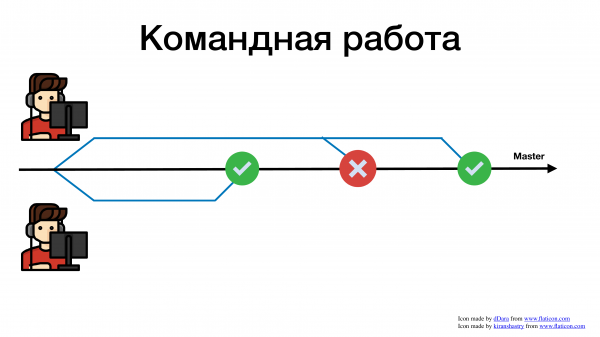
Чем сложнее объединить свою фичу с общим мастером, Тем больше времени мы на это тратим. И это я еще достаточно простой пример показал. Это пример, где разработчиков всего 2. А представьте, если 10 или 15, или 100 человек в компании пишут в один репозиторий. Вы с ума сойдете все эти конфликты разрешать.

Есть чуть-чуть другой случай. У нас есть мастер и несколько разработчиков, которые что-то делают.

Они создали по веточке.
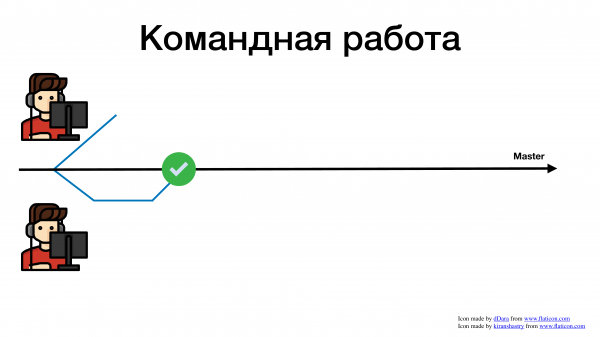
Один смержился, все хорошо, сдал задачу.
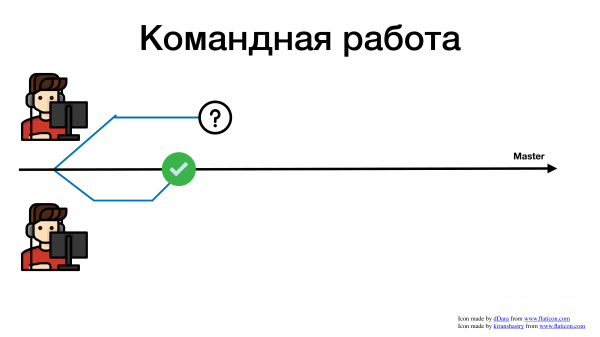
Второй разработчик тем временем сдал свою задачу. Допустим, он отдал ее на ревью. Во многих компаниях есть практика – ревью. С одной стороны, это практика – хорошая и полезная, с другой стороны, это нас во многом где-то тормозит. Не будем в это погружаться, но вот отличный пример, к чему может привести кривая история с ревью. Вы отдали pull request на ревью. Разработчику больше нечего делать. Что он начинает делать? Он начинает брать другие задачи.
За это время второй разработчик еще что-то поделал.
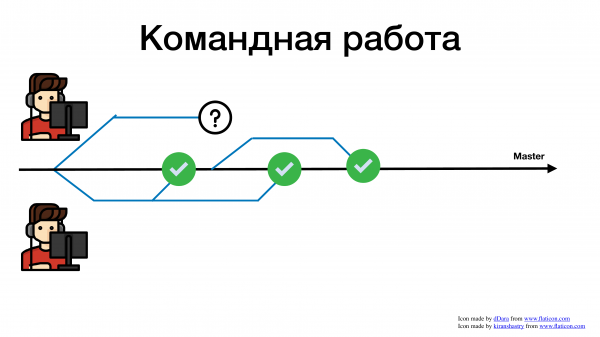
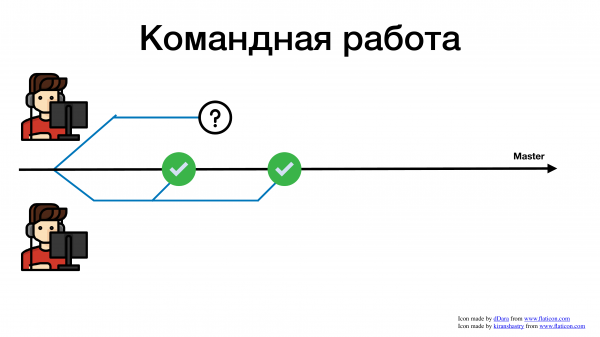
Первый выполнил третью задачу.
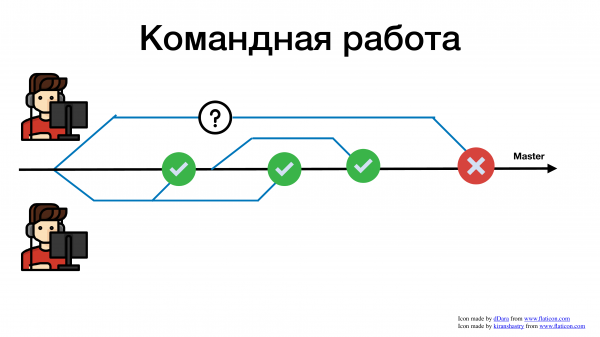
И спустя какое-то продолжительное время, его ревью опробовали, и он пытается смержиться. И что происходит? Он ловит огромное количество конфликтов. Почему? Потому что пока его pull request висел на ревью, в коде уже много чего поменялось.
Помимо истории с конфликтами, есть история с коммуникациями. Пока у вас веточка висит на ревью, пока она чего-то ждет, пока вы долго пилите фичу, вы перестаете отслеживать, что еще в кодовой базе вашего сервиса меняется. Возможно, то, что сейчас вы пытаетесь решить, это уже решили вчера и можно взять и какой-то метод переиспользовать. Но вы этого не увидите, потому что вы работаете всегда с устаревшей веткой. И эта устаревшая ветка всегда приводит к тому, что вам придется разрешать мерж-конфликт.
Получается, что если мы работаем командой, т. е. не один человек в репозитории ковыряется, а человек 5-10, то чем дольше мы не добавляем свой код в мастер, тем больше мы страдаем оттого, что на в конечном итоге нужно что-то смержить. И чем больше у нас конфликтов, и чем с более старой версией мы работаем, тем больше у нас проблем.

Совместно что-то делать – это больно! Мы друг дружке всегда мешаем.

На эту проблему обратили внимание 20 с лишним лет назад. Первое упоминание о практике Continuous Integration я нашел в экстремальном программировании.
Экстремальное программирование – это первый agile framework. Страничка появилась в 96-ом году. И была идея использовать какие-то практики программирования, планирования и прочего, чтобы разработка была как можно более гибкой, чтобы мы могли быстрее реагировать на какие-то изменения, требования от наших клиентов. И они 24 года назад начали с этим сталкиваться, что если ты делаешь что-то очень долго и в стороне, то ты тратишь на это больше времени, потому что у тебя конфликты.

Сейчас мы разберем словосочетание «Continuous Integration» по отдельным словам. Если переводить в лоб, то получается непрерывная интеграция. Но насколько она непрерывная не очень понятно, она очень даже прерывная. Но сколько она integration тоже не очень очевидно.
И поэтому я привожу вам сейчас цитаты из экстремального программирования. И мы оба слова разберем по отдельности.
Integration — Как я уже сказал, мы стремимся к тому, чтобы каждый инженер работал с самой актуальной версией кода, чтобы он свой код стремился добавлять как можно чаще в общую веточку, чтобы это были маленькие веточки. Потому что если они большие, то можем в легкую на неделю застрять с мерж-конфликтами. Особенное, если у нас длинный цикл разработки типа waterfall, где разработчик ушел на месяц пилить какую-то огромную фичу. И он на этапе интеграции застрянет очень надолго.
Integration – это когда мы берем свою веточку и интегрируем ее с мастером, мы ее мержим. Есть ультимативный вариант, когда мы transbase developer, где мы стремимся к тому, что мы сразу в мастер пишем без всяких лишних веточек.
В общем, integration – это взять свой код и дотащить его в мастер.

Что здесь подразумевается под словом «continuous», что называется непрерывностью? Практика подразумевает, что разработчик стремится интегрировать свой код как можно быстрее. Это его цель при выполнении любой задачи – сделать так, чтобы его код появился в мастере, как можно быстрее. В идеальном мире разработчики будут это делать каждые несколько часов. Т. е. ты берешь маленькую задачку, мержишь ее в мастер. Все замечательно. Ты к этому стремишься. И делать это надо непрерывно. Как только ты что-то сделал, ты сразу же это вгоняешь в мастер.
И разработчик, который что-то делает, является ответственным за то, что он сделал, чтобы это работало и ничего не сломало. Вот здесь обычно и вылезает история с тестами. Мы хотим прогнать какие-то тесты на наш коммит, на наш мерж, чтобы убедиться, что это работает. И здесь вам могут как раз помочь Jenkins.
Но с историями: а давайте изменения будут маленькими, а давайте задачки будут маленькими, а давайте мы задачку сделаем и сразу же попытаемся как-то вмержить ее в мастер – вот здесь никакие Jenkins не помогут. Потому что Jenkins вам помогут исключительно запустить тесты.
Вы можете обойтись и без них. Это вам нисколько не помешает. Потому что цель практики – это мержится как можно чаще, чтобы не тратить огромное количество времени на какие-то конфликты в будущем.
Представим, что у нас 2020-ый год почему-то без интернета. И мы локально работаем. У нас нет Jenkins. Это нормально. Вы все еще можете взять и сделать локальную веточку. Вы в ней написали какой-то код. Сделали задачку за 3-4 часика. Переключились на мастер, сделали git pull, вмержили туда свою ветку. Готово. Если вы это делаете часто – поздравляю, у вас есть Continuous Integration!

Какие в современном мире есть пруфы на тему того, что на это стоит тратить силы? Потому что в целом это сложно. Если вы попробуете так поработать, то вы поймете, что у вас сейчас затронется какое-то планирование, вам придется больше времени уделять декомпозированию задач. Потому что если вы будете делать man…, то вы смержиться не сможете быстро и, соответственно, попадете в просак. Практики у вас уже не будет.
И это будет дорого. Работать сразу с завтрашнего дня по Continuous Integration не получится. Вы все будете очень долго привыкать, очень долго будете приучаться декомпозировать задачи, очень долго будете приучаться переделывать практику ревью, если она у вас есть. Потому что наша цель, чтобы оно смержилось сегодня. А если вы ревью делаете в течение трех дней, то у вас проблемы и Continuous Integration у вас не получается.
Но какие-то у нас есть актуальные пруфы прямо сейчас, которые нам говорят, что инвестировать в эту практику имеет смысл?

Первое, что мне пришло в голову – это State of DevOps. Это исследование, которое ребята проводят уже 7 лет. сейчас они это делают как независимая организация, но под Google.
И их исследование в 2018-ом году показало корреляцию между компаниями, которые стараются использовать короткоживущие веточки, которые интегрируются быстро, интегрируются часто, у них более красивые показатели производительности IT.
Что это за показатели? Это 4 метрики, которые они снимают со всех компаниях в своих опросниках: deployment frequency, lead time for changes, time to restore service, change failure rate.
И, во-первых, есть вот эта корреляция, мы знаем, что компании, которые мержатся часто, у них эти метрики сильно лучше. И у них есть разбиение компаний на несколько категорий: это медленные компании, которые производят что-то медленно, medium performer, high performer и элита. Элита – это Netflix, Amazon, которые супершустрые, все делают быстро, красиво и качественно.

Вторая история, которая произошла буквально месяц назад. В Technology Radar появилась замечательная заметка о Gitflow. Gitflow отличается от всех остальных тем, что его ветки живут долго. Есть релизные ветки, которые долго живут, фичи branches, которые тоже долго живут. Эта практика в Technology Radar переместилась в HOLD. Почему? Потому что люди сталкиваются с болью интеграции.
Если у тебя ветка живет очень долго, она встревает, протухает, мы начинаем тратить больше времени на то, чтобы внести в нее какое-то изменение.
И недавно автор Gitflow сказал, что если вы стремитесь к Continuous Integration, если вы стремитесь к тому, что вы хотите катиться как можно чаще, то Gitflow – это плохая идея. Он отдельно в статью дописал, что если у вас бэкенд, где вы можете к этому стремится, то Gitflow для вас лишний, потому что Gitflow вас замедлит, Gitflow вам создаст проблемы с интеграцией.
Это не означает, что Gitflow плохой и им не надо пользоваться. Он для других случаев. Например, когда вам нужно поддерживать несколько версий сервиса, приложения, т. е. где вам нужно саппортить в течение какого-то продолжительного периода времени.
Но если вы пообщаетесь с людьми, которые такие сервисы поддерживают, то вы услышите много боли о том, что эта версия была 3.2, которая была 4 месяца назад, а в нее не попал этот фикс и теперь, чтобы его внести, нужно внести кучу изменений. И вот они снова застряли, и вот они неделю ковыряются с тем, чтобы взять и смержить какую-то новую фичу.
Как Александр Ковалев правильно заметил в чате, корреляция – это не равно причинно-следственной связи. Это так. Т. е. какой-то прямой связи, что если у вас Continuous Integration, то все метрики будут шикарными, нет. Но есть положительная корреляция, что если одно, то, скорее всего, другое тоже. Не факт, но, скорее всего. Это всего лишь корреляция.

Вроде бы мы уже что-то делаем, вроде бы мы уже мержимся, но как понять, что Continuous Integration у нас все-таки есть, что мержимся достаточно часто?
Jez Humble – это автор Handbook, Accelerate, сайта Continuous Delivery и книжки «Continuous Delivery». Он предлагает вот такой тест:
- Код инженера попадает в мастер ежедневно.
- На каждый коммит вы запускаете unit-тесты.
- Билд в мастере упал, его починили примерно за 10 минут.
Он предлагает использовать такой тест, чтобы убедиться, что практика у вас точно есть.
Последнее я нахожу немножко спорным. Т. е. если вы можете починить за 10 минут, значит, у вас есть Continuous Integration, звучит немножко странно, на мой взгляд, но в этом есть смысл. Почему? Потому что, если вы мержитесь часто, это значит, что изменения у вас маленькие. Если маленькое изменение к тому, что у вас сломалась сборка мастера, то вы сможете найти пример быстро, потому что изменение маленькое. Вот у вас был маленький мерж, в нем изменились 20-30 строчек. И, соответственно, вы можете быстро понять, в чем была причина, потому что изменения крохотные, у вас очень маленькая область поиска проблемы.
И даже если у нас после релиза разваливается prod, то если у нас есть практика Continuous Integration, нам сильно проще действовать, потому что изменения крохотные. Да, это затронет планирование. Это будет больно. И, наверное, самое сложное в этой практике – это привыкнуть разбивать задачки, т. е. как сделать так, чтобы взять что-то и сделать это за несколько часов и при этом пройти ревью, если оно у вас есть. Ревью – это отдельная боль.
Unit-тесты – это просто помощник, который вам помогает понять – точно ли ваша интеграция прошла успешно, точно ли ничего не сломалось. На мой взгляд, это тоже не совсем обязательный пункт, потому что смысл практики не в этом.
Это кратенько про Continuous Integration. Это все, что есть в этой практике. Я готов к вопросам.
Кратко только еще раз подведу итоги:
- Continuous Integration – это не Jenkins, это не Gitlab.
- Это не инструмент, это практика о том, что мы как можно чаще мержим наш код в мастер.
- Делаем мы это для того, чтобы избежать огромной боли, которая возникает с мержами в будущем, т. е. мы испытываем маленькую боль сейчас, чтобы не испытывать большую в будущем. В этом весь смысл.
- С боку проходит коммуникация через код, но я этого очень редко вижу, но для этого она тоже задумывалась.
Вопросы
Что делать с недекомпозированием задачами?
Декомпозировать. В чем проблема? Можете привести пример, что есть задача и она не декомпозируется?
Есть такие задачи, которые невозможно декомпозировать от слова «совсем», например, те, которые требуют очень глубокой экспертизы и которые реально могут решаться на протяжении месяца до какого-то удобоваримого результата.
Если я правильно тебя понял, то есть какая-то большая и сложная задача, результат которой будет виден только через месяц?
Да, все верно. Да, оценить результат можно будет не ранее, чем через месяц.
Хорошо. В целом это не проблема. Почему? Потому что в данном случае, когда мы говорим про веточки, мы не говорим про веточку с фичей. Фичи бывают большими и сложными. Они могут затрагивать большое количество компонентов. И, возможно, мы их не можем сделать в одной веточке полностью. Это нормально. Нам нужно всего лишь разбить эту историю. Если фича не готова до конца, то это не означает, что какие-то куски ее кода нельзя мержить. Ты добавил, допустим, миграцию и внутри фичи есть какие-то этапы. У тебя, допустим, есть этап – сделать миграцию, добавить новый метод. И ты эти вещи уже можешь мержить ежедневно.
Хорошо. Какой тогда в этом смысл?
Какой смысл мержить маленькие штуки ежедневно?
Да.
Если они у тебя что-то сломали, ты это видишь сразу. У тебя маленький кусочек, который что-то сломал, тебе проще это исправить. Смысл в том, что смержить маленький кусочек сейчас намного проще, чем смержить что-то большое через несколько недель. И третий смысл в том, что у тебя другие инженеры будут работать с уже актуальной версией кода. Они будут видеть, что тут какие-то миграции добавились, а тут появился какой-то метод, который они тоже, возможно, захотят использовать. У тебя все будут видеть, что у тебя в коде происходит. Именно ради этих трех вещей практика делается.
Спасибо, вопрос закрыт!
(Олег Сорока) Можно я добавлю? Ты все правильно сказал, хочу только одну фразу добавить.
Так.
При Continuous Integration код мержится в общую ветку не тогда, когда фича полностью готова, а тогда, когда перестал ломаться билд. И вы смело коммитете в мастер сколько хотите раз в день. Второй аспект – если вы не можете по какой-то причине разбить месячную задачу на задачи хотя бы по три дня, я молчу про три часа, значит, у вас есть огромная проблема. И тот факт, что у вас нет Continuous Integration – это меньшее из этих проблем. Это значит, что у вас проблемы с архитектурой и инженерные практики на нуле. Потому что даже если это research, то в любом случае его надо оформлять в виде гипотез или цикла.
Мы говорили про 4 метрики, которые отличают успешные компании от отстающих. До этих 4 метрик еще дожить надо. Если у вас средняя задача делается месяц, то я бы сконцентрировался сначала на этой метрике. Опустил бы ее сначала до 3-х дней. И после этого начал думать о Continuous.
Я правильно понял тебя, что ты думаешь, что в целом вкладываться в инженерные практики, если у тебя любая задача делается месяц, смысла еще нет?
У тебя есть Continuous Integration. И там есть такая тема, что ты за 10 минут или фиксишь исправление или откатываешь. Представь, ты его выкатил. Причем у тебя даже continuous deployment, ты его выкатил на prod и только потом заметил, что что-то пошло не так. И тебе его надо откатить, а у тебя уже миграция базы данных произошла. У тебя уже схема базы данных версии следующей, более того, еще и какой-то бэкап прошел, еще туда и данные записались.
И какая у тебя есть альтернатива? Если ты откатываешь назад код, то он уже не может работать с этой базой данных обновленной.
База двигается только вперед, да.
У людей, у которых плохая инженерная практика, скорее всего, они толстую книгу про … тоже не читали. С бэкапом что делать? Если ты восстанавливаешься из бэкапа, то значит, ты теряешь данные, которые за этот момент наработались. Например, работали три часа с новой версией базой данных, туда пользователи зарегистрировались. Ты отказываешь на старый бэкап, потому что с новой версией схема не работает, соответственно, этих пользователей ты потерял. А они недовольные, они ругаются.
Для того чтобы овладеть всем спектром практик, поддерживающихContinuous Integration и Continuous Delivery, не достаточно научиться писать просто …. Во-первых, их может стать очень много, это будет непрактично. Плюс там есть кучу других практик типа Scientific. Есть такая практика, GitHub ее популяризовал в одно время. Это когда у тебя одновременно выполняется и старый код, и новый код. Это когда ты делаешь недоделанную фичу, но она может возвращать какое-то значение: либо как функцию, либо как Rest API. Ты и новый код исполняешь, и старый код исполняешь, и сравниваешь разницу между ними. И если разница есть, то это событие логируешь. Таким образом ты знаешь, что у тебя новая фича готова выкатываться поверх старой, если у тебя в течение определенного времени не было расхождения между этими двумя.
Таких практик сотни. Я бы предложил начать с transbase development. Она не 100 % на Continuous Integration, но практики одни и те же, одно без другого плохо живет.
Ты transbase development привел как пример, где можно посмотреть практики или ты предлагаешь людям начать использовать transbase debelopment?
Посмотреть, т. к. использовать они не смогут. Для того чтобы их использовать, нужно много чего почитать. И когда вопрос у человека: «Что делать с фичей, которая занимает месяц, то это означает, что он не читал про transbase develoopment». Я и бы и не советовал пока что. Я бы посоветовал сконцентрироваться исключительно на теме, как правильно архитектурно разбивать крупные задачи на более мелкие. В этом и суть декомпозиции.
Декомпозиция – это один из инструментов архитектора. Мы сначала делаем анализ, потом декомпозицию, потом синтез, потом интеграцию. И у нас таким образом все складывается. И до Continuous Integration надо еще дорасти через декомпозицию. Вопросы на первом этапе возникают, а мы уже про четвертый этап говорим, т. е. чем чаще делать интеграцию, тем лучше. Ее еще рановато делать, неплохо бы сначала попилить свой монолит.
Нужно сколько-то стрелочек и квадратиков нарисовать на какой-то схеме. Ты не можешь сказать, что сейчас я покажу архитектурную схему нового приложения и показать один квадратик, внутри которого зеленая кнопка на приложение. В любом случае больше будет квадратиков и стрелочек. На любой схеме, которую я видел, их было больше, чем один. И декомпозиция даже на уровне графического представления уже производится. Поэтому квадратики можно делать независимые. Если нет, то у меня большие вопросы к архитектору.
Есть вопрос из чата: «Если ревью обязательно и идет долго, где-то день и более?».
У вас проблемы с практикой. Не должно идти ревью день и более. Это та же история к предыдущему вопросу, только чуть-чуть помягче. Если ревью идет день, значит, скорее всего, это ревью идет какого-то очень большого изменения. Значит, его надо делать меньше. В transbase development, который Олег порекомендовал, есть такая история, которая называется continuous review. Ее идея в том, что мы делаем настолько маленький pull request намеренно, потому что мы стремимся мержится постоянно и по чуть-чуть. И поэтому pull request меняет одну абстракцию или 10 строчек. Благодаря этому ревью у нас занимает пару минут.
Если ревью занимает день и более, значит, что-то не так. Во-первых, возможно, у вас какие-то проблемы с архитектурой. Либо это большой кусок кода, на 1 000 строк, например. Либо у вас настолько сложная архитектура, что человек не может ее понять. Это проблема чуть с бока, но ее тоже придется решать. Возможно, вообще не нужно ревью. Над этим тоже надо подумать. Ревью – эта та штука, которая вас тормозит. Она дает свои плюсы в целом, но нужно понять, зачем вы это делаете. Это для вас способ быстро передать инфу, это для вас способ установить внутри какие-то стандарты или что? Зачем вам это? Потому что ревью нужно делать либо очень быстрым, либо вообще отменить. Это как transbase deveploment – история очень красивая, но только для зрелых ребят.
По поводу 4 метрик, я бы рекомендовал все же их снять, чтобы понять, к чему это приводит. Посмотреть в циферках, посмотреть картинку, насколько все плохо.
(Дмитрий) Я готов вступить в дискуссию по этому поводу с тобой. Циферки и метрики – это все классно, практики – это классно. Но нужно понять – нужно ли это бизнесу. Есть бизнесы, которым не нужна такая скорость изменения. Я знаю компании, в которых нельзя проводить изменения раз в 15 минут. И не потому, что они такие плохие. Это такой жизненный цикл. И чтобы делать фичу branches, фичу toggle, нужны глубокие знания.
Это сложно. Если вы захотите почитать историю про фичу toggle подробнее, то очень рекомендую . И есть замечательная статья у Мартина Фаулера про фичи toggle: о том, какие бывают типы, жизненные циклы и т. д. Фича toggle – это сложно.
И ты все-таки не ответил на вопрос: «Jenkins нужен или не нужен?»
Jenkins не нужен ни в каком случае на самом деле. Если серьезно, то инструменты: Jenkins, Gitlab принесут вам удобство. Вы будете видеть, что сборка собралась или не собралась. Они вам могут помочь, но практику они вам не поставят. Они вам могут только дать кружочек – Ок, не Ок. И то, если вы еще тесты пишите, потому что если нет тестов, то это почти бессмысленно. Поэтому нужен, потому что – это удобнее, но в целом можно и без него жить, не много потеряете.
Т. е. если у вас есть практики, то значит, что он вам не требуется?
Все верно. Я рекомендую тест Jez Humble. Там у меня есть двоякое отношение к последнему пункту. Но в целом, если у вас есть три вещи, вы мержитесь постоянно, вы запускаете тесты на коммиты в мастере, быстро чините билд в мастере, то, возможно, вам больше ничего и не надо.
Пока мы ждем вопросы от участников, у меня есть вопрос. Мы сейчас говорили про продуктовый код. А использовал ли ты для инфраструктурного кода. Это такой же код, у него такие же принципы и такой же жизненный цикл, либо там другие жизненные циклы и принципы? Обычно, когда все говорят про Continuous Integration и Development, то все забывают, что есть еще инфраструктурный код. И в последнее время его все больше и больше. И следует ли туда приносить все эти правила?
Даже не то, чтобы следует, это будет здорово, потому что это точно так же упростит жизнь. Как только мы работаем с кодом, не со скриптами на bash, а у нас есть нормальный код.
Стоп-стоп, скрипт на bash – это тоже код. Не надо трогать мою старую любовь.
Хорошо, я не буду топтать твои воспоминания. У меня к bash личная неприязнь. Он ломается некрасиво и страшно все время. И ломается часто непредсказуемо, поэтому я его недолюбливаю. Но хорошо, предположим, у вас есть код на bash. Может быть, я действительно не разбираюсь и там есть нормальные фреймворки для тестирования. Я просто не в теме. И мы получаем те же самые плюсы.
Как только мы работаем с инфраструктурой как с кодом, мы получаем все те же самые проблемы как разработчики. Несколько месяцев назад я столкнулся с ситуацией, что коллега мне прислал pull request на 1 000 строк на bash. И ты зависаешь на ревью на 4 часа. Проблемы возникают те же самые. Это все еще код. И все еще совместная работа. Мы застреваем с pull request и застреваем с тем, что мы разруливаем те же мерж-конфликты того же bash, например.
Я сейчас очень активно всю эту штуку смотрю на максимально красивом программировании инфры. Я сейчас втащил в инфраструктуру Pulumi. Это программирование в чистом виде. Там это еще более симпатично, потому что у меня есть все возможности языка программирования, т. е. я теми же самими ифами на ровном месте сделал красивые toggle и все хорошо. Т. е. мое изменение есть уже в мастере. Его уже все видят. Другие инженеры о нем в курсе. Оно уже на что-то там повлияло. Но при этом оно включилось не для всех инфраструктур. Оно включилось для моих тестовых стендов, например. Поэтому отвечая на твой вопрос еще раз, нужно. Оно нам, как инженерам, работающим с кодом, точно так же упрощает жизнь.
Если у кого-то еще вопросы?
У меня есть вопрос. Я хочу продолжить дискуссию с Олегом. В целом я думаю, что ты прав, что если задача у тебя делается месяц, то у тебя проблема с архитектурой, у тебя проблема с анализом, декомпозицией, планированием и т. д. Но у меня есть такое ощущение, что если ты начнешь пытаться жить по Continuous Integration, то ты начнешь исправлять боли с планированием, потому что ты никуда больше от этого не денешься.
(Олег) Да, все так. По трудоемкости эта практика сравнима с любой другой серьезной практикой, меняющей культуру. Самое трудное в преодолении – это привычки, особенно, плохие привычки. И если для того, чтобы внедрить эту практику требуется серьезное изменение привычек окружающих: developers, руководства, production-менеджера, то вас ждут сюрпризы.
Какие могут быть сюрпризы? Допустим, вы решили, что будете чаще делать интеграцию. И на интеграции у вас завязаны какие-то еще вещи, допустим, артефакты. А в вашей компании, например, есть политика, что каждый артефакт должен быть неким образом учтен в какой-то системе складирования артефактов. И это занимает какое-то количество времени. Человеку нужно поставить галочку, что он, как релиз-менеджер оп робовал этот артефакт на готовность для выкладки в production. Если это занимает 5-10-15 минут, но при этом вы делаете выкладку раз в неделю, то раз в неделю потратить полчаса – это небольшой налог.
Если вы Continuous Integration делаете 10 раз в день, то 10 раз нужно умножить на 30 минут. И это превышает количество рабочего времени этого релиз-менеджера. Он просто устает это делать. Есть постоянные затраты на какие-то практики. И все.
И вам нужно или отменять это правило, чтобы вы больше не занимаетесь такой фигней, т. е. вы не присваиваете вручную степень на соответствие чего-то чему-то. Вы целиком и полностью полагаетесь на какой-то автоматизированный набор тестов готовности.
И если вам нужно от кого-то пруф, чтобы главный подписал, и вы не лезете в production без того, что Вася не сказал, что он разрешает и т. д. – вся эта ерунда встает на пути практик. Потому что если есть связанные в виде налога какие-то активности, то все в 100 раз увеличивается. Поэтому сдвиг будет зачастую воспринят не всеми радостно. Потому что привычки людей тяжело исправлять.
Когда человек делает привычную работу, он делает ее, практически не задумываясь. У нее когнитивная нагрузка равна нуля. Он просто фигачит по готовому, у него в голове уже есть чек-лист, он тысячу раз это делал. И как только ты приходишь и говоришь ему: «Давай отменим эту практику и с понедельника внедрим новую» для него это становится мощной когнитивной нагрузкой. Причем она для всех сразу наступает.
Поэтому самое простое, правда, эту роскошь не все могут позволить, но я делаю всегда именно так, это следующее. Если стартует новый проект, то обычно сразу в этот проект впихиваются все неопробованные практики. Пока проект молодой, мы особо ничем не рискуем. Prod еще нет, развалить нечего. Поэтому в качестве тренировки можно использовать. Такой подход работает. Но не все компании имеют возможность стартовать такие проекты часто. Хотя это тоже немного странно, потому что сейчас сплошной digital transformation, все должны эксперименты запускать, чтобы угнаться за конкурентами.
Тут ты упираешься в то, что у тебя должно быть сначала понимание того, что тебе нужно делать. Мир не идеальный, prod тоже не идеальный.
Да, эти вещи взаимосвязаны.
У бизнеса тоже не всегда есть понимание, что им нужно идти вот туда-то.
Есть ситуация, при которой вообще никакие изменения невозможны. Это ситуация, когда на команду идет большее давление. Команда довольно подвыгоревшая уже. Она не имеет никакого запасного времени на никакие эксперименты. Они с утра до вечера пилят фичи. А руководству фич все мало и мало. Требуется все больше и больше. В такой ситуации вообще никакие изменения невозможны. Команде могут только сказать, что завтра будем делать так же, как и вчера, просто нужно сделать фич чуть больше. Никакие переходы ни на какие практики в этом смысле невозможны. Это классическая ситуация, когда некогда топор затачивать, надо деревья рубить, поэтому рубят тупым топором. Здесь простых советов нет.
(Дмитрий) Я зачитаю уточнение из чата: «Но нужно большое покрытие тестами на разных уровнях. Сколько времени на тесты уделяется? Как-то дороговато, много времени отнимает».
(Олег) Это классическое заблуждение. Тестов должно быть достаточно для того, чтобы у вас самих была уверенность. Continuous Integration – это не такая штука, где сначала 100 % тестов идет и только потом начинаете эту практику применять. Continuous Integration снижает на вас когнитивную нагрузку за счет того, что каждое из изменений, которое вы видите глазами, оно настолько очевидно, что вы понимаете – сломает оно что-то или нет, даже и без тестов. Вы в голове можете это быстро протестировать, потому что маленькие изменения. Даже если у вас только ручные тестировщики, им тоже проще. Вы выкатили и сказали: «Посмотри, ничего не сломалось?». Они проверили и сказали: «Нет, ничего не сломалось». Потому что тестировщик знает куда смотреть. У вас один коммит связан с одним фрагментом кода. И это эксплоится конкретным поведением.
Тут ты, конечно, приукрасил.
(Дмитрий) Тут я не соглашусь. Имеется практика – разработка через тестирование, которая как раз от этого спасет.
(Олег) Вот, я до этого еще не дошел. Первая иллюзия – это то, что нужно писать именно 100 % тестов или не нужно вообще заниматься Continuous Integration. Это неправда. Это две параллельные практики. И они напрямую не зависят. Ваше покрытие тестами должно быть оптимальным. Оптимальным – это значит, что вы сами уверены в том, что то качество мастера, в котором остался после коммита ваш мастер, позволяет вам с уверенностью нажать кнопку «Deploy» вечером в пятницу в пьяном виде. Как вы этого добиваетесь? Через ревью, через покрытие, через хороший мониторинг.
Хороший мониторинг – неотличим от тестов. Если вы тесты запускаете один раз на pre prod, то они один раз проверяют все ваши пользовательские сценарии и все. А если вы их в бесконечном цикле запускаете, то это ваша развернутая система мониторинга, которая бесконечно все тестирует – упало или не упало. В этом случае разница только в однократности или многократности. Очень хороший набор тестов …, запускаемые бесконечно, это мониторинг. И правильный мониторинг и должен быть таким.
И поэтому как именно вы достигнете это состояние, когда вы в пятницу вечером задеплоитесь и уходите домой, это другой вопрос. Может быть, вы просто смелый отморозок.
Давай назад немного вернемся к Continuous Integration. Мы немного в другую сложную практику убежали.
И вторая иллюзия, что MVP, говорят, надо быстро делать, поэтому там тесты вообще не нужны. Не совсем так. Дело в том, что когда вы в MVP пишите user story, то разрабатывать ее можно либо на шару, т. е. услышал, что есть какая-то user story и сразу кодировать ее побежал, либо работать по TDD. И по TDD, как показывает практика, получается не дольше, т. е. тесты – это побочный эффект. Практика TDD заключается не в том, чтобы тестировать. Несмотря на то, что называется Test Driven Development, там речь вообще не о тестах. Это тоже, скорее, архитектурный подход. Это подход, как писать именно то, что нужно, и не писать то, что не нужно. Эта практика по фокусировке внимания на следующую итерацию вашего развития мысли в плане создания архитектуры приложения.
Поэтому от этих иллюзий не так просто избавиться. MVP и тесты не противоречат друг другу. Даже, скорее, наоборот, если вы MVP делаете по практике TDD, то вы это сделаете лучше и быстрее, чем, если вообще без практики, а на шару.
Это очень неочевидная и сложная мысль. Когда ты слышишь, что теперь я буду писать еще тесты и при этом я что-то сделаю быстрее, оно звучит абсолютно неадекватно.
(Дмитрий) Тут многие, когда называют MVP, это народу лень писать что-то нормальное. И это все-таки разные вещи. Не надо MVP превращать в какую-то плохую штуку, которая не работает.
Да-да, ты прав.
А потом внезапно MVP в prod.
Навсегда.
А TDD звучит очень непривычно, когда слушаешь, что ты пишешь тесты и вроде совершаешь больше работы. Это звучит очень странно, но на самом деле это так получается быстрее и симпатичнее. Когда ты пишешь тест, то уже в голове ты много думаешь о том, какой код и как будет вызываться, а также какое поведение мы от него ожидаем. Ты не просто говоришь, что я написал какую-то функцию, и она что-то делает. Ты сначала подумал, что у нее вот такие-то условия, она так-то будет вызываться. Ты это покрываешь тестами и из этого ты понимаешь, как у тебя будут выглядеть интерфейсы внутри твоего кода. Это очень сильно влияет на архитектуру. У тебя код автоматически становится более модульным, потому что ты сначала пытаешься понять, как ты его будешь тестировать, а только потом его пишешь.
У меня с TDD получилось так, что я в какой-то момент нанимал ментора по Ruby, когда я еще был программистом на Ruby. И он говорит: «Давай ты будешь делать по TDD». Я и думаю: «Блин, сейчас что-то еще писать дополнительно». И мы с ним договорились, что я буду в течение двух недель весь код рабочий на Python писать по TDD. Через две недели я понял, что обратно я уже не хочу. За две недели пытаясь везде это применять, ты понимаешь, насколько тебе стало проще даже просто думать. Но это неочевидно, поэтому я всем рекомендую, что, если у вас есть ощущение, что TDD – это сложно, долго и лишнее, попробуйте придерживаться этому всего две недели. Мне двух хватило для этого.
(Дмитрий) Мы можем эту мысль развернуть с точки зрения эксплуатации инфраструктуры. Прежде чем мы что-то новое запускаем, мы делаем мониторинг, а потом запускаем. В этом случае у нас мониторинг становится нормальным тестированием. И есть разработка через мониторинг. Но почти все говорят, что это долго, мне лень, я сделал черновик временный. Если мы сделали нормально мониторинг, мы пониманием состояние CI системы. А в CI системе много мониторинга. Мы понимаем состояние системы, мы понимаем, что у нее внутри. И во время разработки мы как раз делаем систему, чтобы она пришла к нужному состоянию.
Эти практики известны давно. Мы года 4 назад это обсуждали. Но за 4 года практически ничего не поменялось.
Но этой ноте официальную дискуссию предлагаю заканчивать.
Видео (вставлен как медиаэлемент, но почему то не работает):
Источник: habr.com
