

Всем привет! У нас отличные новости, в июне OTUS снова запускает курс , в связи с чем мы традиционно делимся с вами полезным материалом.

Если вы столкнулись со всей этой историей с микросервисами без какого-либо контекста, то вам простительно считать ее немного странной. Разбиение приложения на фрагменты, связанные между собой сетью, непременно означает добавление сложных режимов отказоустойчивости в получившуюся распределенную систему.
Несмотря на то, что такой подход включает в себя разбиение на множество независимых сервисов, конечная цель куда больше, чем просто работа этих сервисов на разных машинах. Речь здесь идет о взаимодействии с окружающим миром, который по своей сути тоже распределенный. Не в техническом смысле, а скорее в смысле экосистемы, которая состоит из множества людей, команд, программ, и каждая из этих частей так или иначе должна выполнять свою работу.
Компании, например, представляют из себя набор распределенных систем, которые в совокупности способствуют достижению некоторой цели. Мы игнорировали этот факт на протяжении десятилетий, пытаясь добиться объединения, передавая файлы по FTP или пользуясь инструментами корпоративной интеграции, при этом сосредотачиваясь на своих личных обособленных целях. Но с приходом сервисов все изменилось. Сервисы помогли нам заглянуть за горизонт и увидеть мир взаимозависимых программ, которые работают сообща. Однако, чтобы работать успешно, необходимо осознать и спроектировать два принципиально разных мира: внешний мир, где мы живем в экосистеме множества других сервисов, и наш личный, внутренний мир, где мы правим в одиночку.
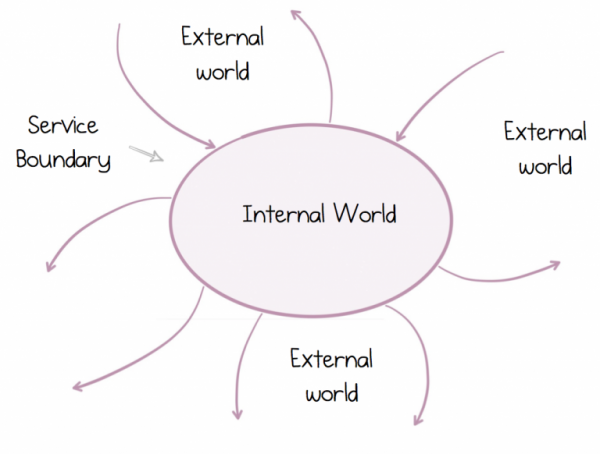
Такой распределенный мир отличается от того, в котором мы выросли и к которому привыкли. Принципы построения традиционной монолитной архитектуры не выдерживают никакой критики. Поэтому правильное понимание таких систем – это нечто большее, чем создание классной схемы на белой маркерной доске или крутое доказательство концепции. Речь идет о том, чтобы такая система успешно работала в течение долгого времени. К счастью, сервисы существуют уже довольно давно, хотя и выглядят по-разному. все еще актуальны, даже приправленные Docker, Kubernetes и слегка потрепанные хипстерскими бородами.
Итак, сегодня мы посмотрим на то, как изменились правила, почему нам нужно переосмыслить наш подход к сервисам и данным, которые они передают друг другу, и почему нам для этого понадобится совершенно другой инструментарий.
Инкапсуляция не всегда будет вам другом
Микросервисы могут работать независимо друг от друга. Именно это свойство придает им наибольшую ценность. Это же свойство позволяет сервисам масштабироваться и расти. Не столько в смысле масштабирования до квадриллионов пользователей или петабайт данных (хотя и тут они могут помочь), сколько в смысле масштабирования с точки зрения людей, поскольку команды и организации растут непрерывно.
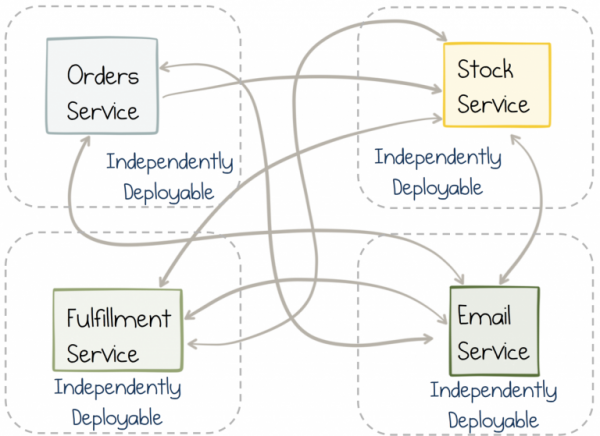
Однако независимость – это палка о двух концах. То есть сервис сам по себе может крутиться легко и непринужденно. Но если внутри сервиса реализуется функция, которая требует задействовать другой сервис, то в конечном итоге нам приходится вносить изменения в оба сервиса почти одновременно. В монолите это сделать легко, вы просто вносите изменение и отправляете в релиз, а вот в случае синхронизации независимых сервисов проблем будет больше. Координация между командами и релизными циклами разрушает гибкость.
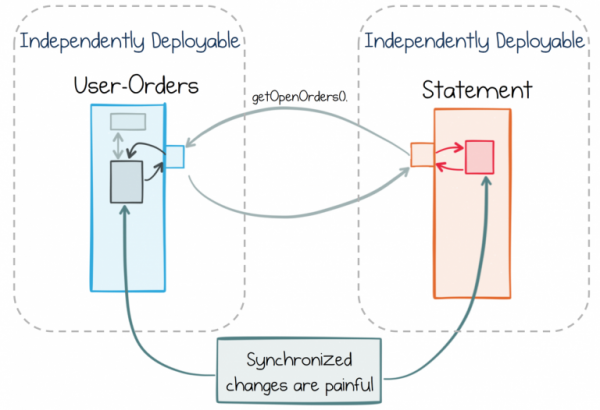
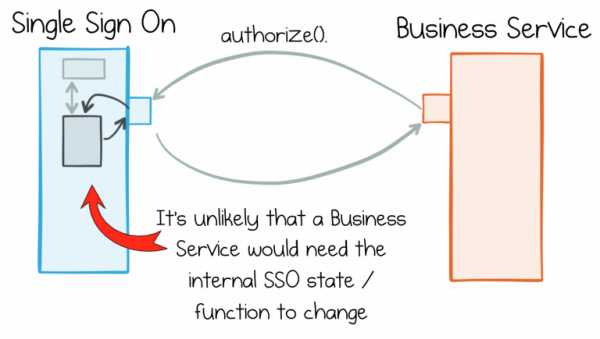
В рамках стандартного подхода досадных сквозных изменений стараются просто избегать, четко разделяя функционал между сервисами. Сервис единого входа в систему здесь может быть хорошим примером. У него есть четко определенная роль, которая отличает его от других сервисов. Такое четкое разделение означает, что в мире быстро меняющихся требований к окружающим его сервисам, сервис единого входа в систему вряд ли будет меняться. Он существует в рамках строго ограниченного контекста.
Проблема заключается в том, что в реальном мире бизнес-сервисы не могут постоянно сохранять одинаково чистое разделение ролей. Например, те же бизнес-сервисы в большей степени работают с данными, поступающими от других таких же сервисов. Если вы занимаетесь онлайн-ритейлом, то обработка потока заказов, каталога продукции или информации о пользователях станет требованием ко многим вашим сервисам. Каждому из сервисов для работы понадобится доступ к этим данным.
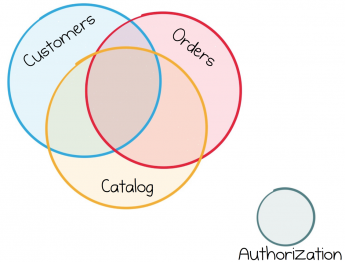
Большинство бизнес-сервисов используют один и тот же поток данных, поэтому их работа неизменно переплетается.
Таким образом мы подошли к важному моменту, о котором стоит поговорить. В то время как сервисы хорошо работают для компонентов инфраструктуры, которые работают в значительной степени обособленно, большинство бизнес-сервисов оказываются переплетенными куда более тесно.
Дихотомия данных
Подходы, ориентированные на сервисы, возможно, уже существуют, однако в них все еще мало информации о том, как обмениваться большими объемами данных между сервисами.
Основная проблема заключается в том, что данные и сервисы неразлучны. С одной стороны, инкапсуляция призывает нас скрывать данные, чтобы сервисы можно было отделить друг от друга и облегчить их рост и дальнейшие изменения. С другой стороны, нам нужно иметь возможность свободно разделять и властвовать над общими данными, как и над любыми другими. Речь идет о том, чтобы иметь возможность сразу же начать работу, также свободно, как и в любой другой информационной системе.
Однако у информационных систем мало общего с инкапсуляцией. На самом деле даже наоборот. Базы данных делают все, что могут, чтобы дать доступ к хранящимся в них данным. Они поставляются с мощным декларативным интерфейсом, который позволяет видоизменять данные как вам нужно. Такой функционал важен на этапе предварительных исследований, но не для управления растущей сложностью постоянно развивающегося сервиса.
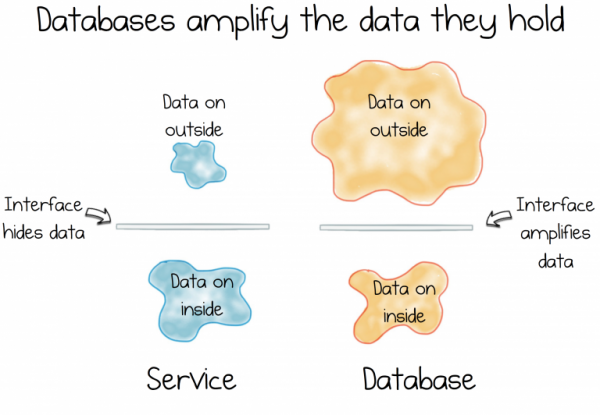
И тут возникает дилемма. Противоречие. Дихотомия. Ведь информационные системы – это про предоставление данных, а сервисы – про сокрытие.
Эти две силы фундаментальны. Они лежат в основе большей части нашей работы, постоянно борясь за превосходство в системах, которые мы создаем.
По мере того, как растут и эволюционируют системы сервисов, мы видим разные проявления последствий дихотомии данных. Либо интерфейс сервиса будет расти, предоставляя все более широкий набор функций и начнет выглядеть как очень чудная доморощенная база данных, либо нас постигнет разочарование, и мы реализуем какой-нибудь способ извлекать или перемещать массово целые наборы данных из сервиса в сервис.
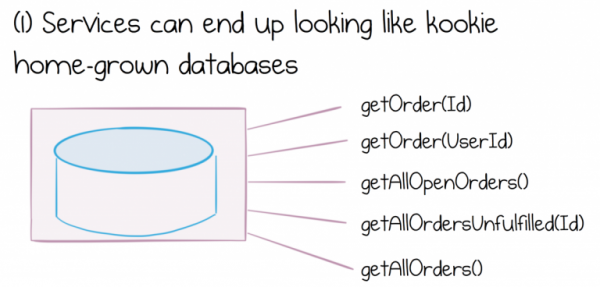
В свою очередь создание чего-либо, что выглядит как чудная доморощенная база данных приведет к целому ряду проблем. Мы не будем вдаваться в подробности того, чем опасна shared database, просто скажем, что она представляет из себя значительные дорогостоящие инженерные и операционные для компании, которая пытается ее использовать.
Хуже то, что объемы данных преумножают проблемы с границами сервисов. Чем больше общих данных лежит внутри сервиса, тем сложнее станет интерфейс и тем сложнее будет объединить наборы данных, поступающие из различных сервисов.
Альтернативный подход с извлечением и перемещением целых наборов данных тоже имеет свои проблемы. Распространенный поход к этому вопросу выглядит как простое извлечение и хранение набора данных целиком, а затем хранение его локально в каждом сервисе-потребителе.
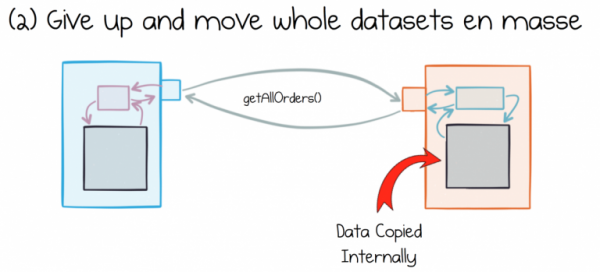
Проблема заключается в том, что разные сервисы по-разному интерпретируют данные, которое они потребляют. Эти данные всегда под рукой. Они изменяются и обрабатываются локально. Довольно быстро они перестают иметь что-либо общее с данными в источнике.
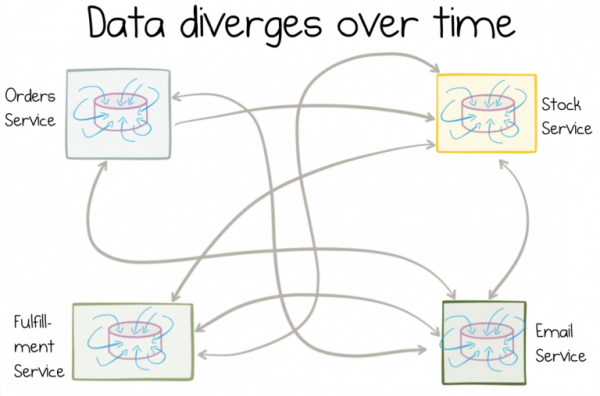
Чем более мутабельны копии, тем больше данные будут разниться с течением времени.
Что еще хуже, такие данные сложно исправить в ретроспективе ( тут и вправду может прийти на помощь). На самом деле некоторые из трудноразрешимых технологических проблем, с которыми сталкивается бизнес, возникают из-за разнородных данных, множащихся от приложения к приложению.
Чтобы найти решение этой проблемы об общих данных нужно думать иначе. Они должны стать объектами первого класса в архитектурах, которые мы строим. называет такие данные «внешними», и это очень важная особенность. Нам нужна инкапсуляция, чтобы не раскрывать внутреннее устройство сервиса, но мы должны облегчить сервисам доступ к совместно используемым данным, чтобы они могли корректно выполнять свою работу.
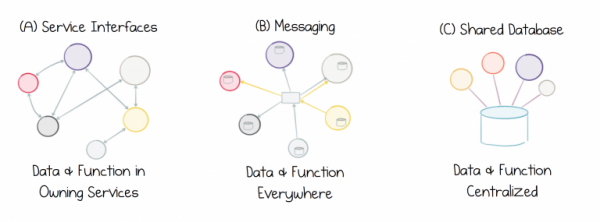
Проблема заключается в том, что ни один из подходов сегодня уже не актуален, поскольку ни интерфейсы сервиса, ни обмен сообщениями, ни Shared Database не предлагают хорошего решения для работы с внешними данными. Интерфейсы сервиса плохо подходят для обмена данными в любом масштабе. Обмен сообщениями перемещает данные, но не хранит их историю, поэтому со временем данные повреждаются. Shared Databases слишком сильно фокусируются в одной точке, что сдерживает развитие прогресса. Мы неизбежно застреваем в цикле несостоятельности данных:
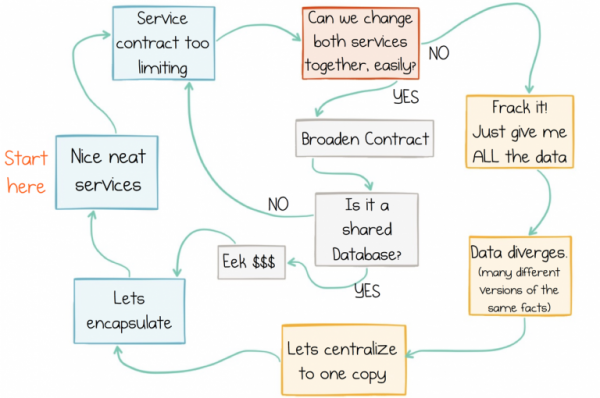
Цикл несостоятельности данных
Потоки: децентрализованный подход к данным и сервисам
В идеале нам нужно изменить подход к тому, как сервисы работают с общими данными. На данный момент любой подход сталкивается с вышеупомянутой дихотомией, поскольку не существует никакой волшебной пыльцы, которой можно было бы ее щедро посыпать и сделать так, чтобы она исчезла. Однако мы можем переосмыслить проблему и прийти к компромиссу.
Этот компромисс предполагает определенную степень централизации. Мы можем воспользоваться механизмом распределенных логов, поскольку он обеспечивает надежные масштабируемые потоки. Теперь нужно, чтобы сервисы могли присоединяться и работать этими общими потоками, однако мы хотим избежать сложных централизованных God Service’ов, которые выполняют такую обработку. Поэтому лучший вариант – это встроить потоковую обработку в каждый сервис-потребитель. Так сервисы смогут объединять наборы данных из разных источников и работать с ними так, как им нужно.
Один из способов достичь такого подхода — это использование стриминговой платформы. Существует множество вариантов, но сегодня мы рассмотрим именно Kafka, поскольку использование ее Stateful Stream Processing, позволяет эффективно решать представленную проблему.
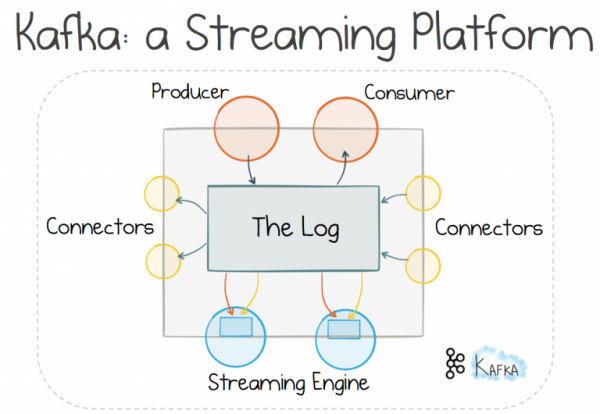
Использование механизма распределенного логирования позволяет нам идти по протоптанной тропинке, и использовать обмен сообщениями, чтобы работать с . Считается, что такой подход обеспечивает лучшее масштабирование и разделение, чем механизм «запрос-ответ», поскольку он отдает управление потоком получателю, а не отправителю. Однако за все в этой жизни приходится платить, и тут вам понадобится брокер. Но для больших систем этот компромисс того стоит (чего не скажешь о ваших среднестатистических веб-приложениях).
Если за распределенное логирование отвечает брокер, а не традиционная система обмена сообщениями, можно воспользоваться дополнительными особенностями. Транспорт можно линейно масштабировать почти также хорошо, как распределенную файловую систему. Данные могут храниться в логах достаточно долго, поэтому мы получаем не только обмен сообщениями, но и хранилище информации. Масштабируемое хранилище без страха получить изменяемое общее состояние.
Затем можно использовать механизм stateful stream processing (обработка потока с сохранением состояния) для добавление декларативных инструментов базы данных в сервисы-потребители. Это очень важная мысль. Пока данные хранятся в общих потоках, к которым могут получать доступ все сервисы, объединение и обработка, которую делает сервис, являются приватными. Они оказываются изолированными внутри строго ограниченного контекста.
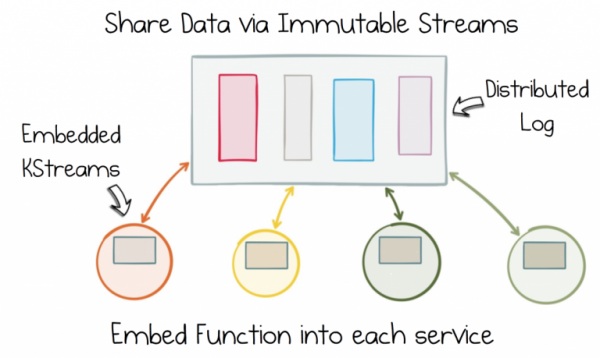
Избавьтесь от дихотомии данных, разделив иммутабельный поток состояний. Затем добавьте эту функцию в каждый сервис с помощью Stateful Stream Processing.
Таким образом, если ваш сервис должен работать с заказами, каталогом продуктов, складом, у него будет полный доступ: только вы будете решать, какие данные объединять, где их обрабатывать и как они должны меняться с течением времени. Несмотря на то, что данные общие, работа с ними полностью децентрализована. Она производится внутри каждого сервиса, в мире, где все идет по вашим правилам.
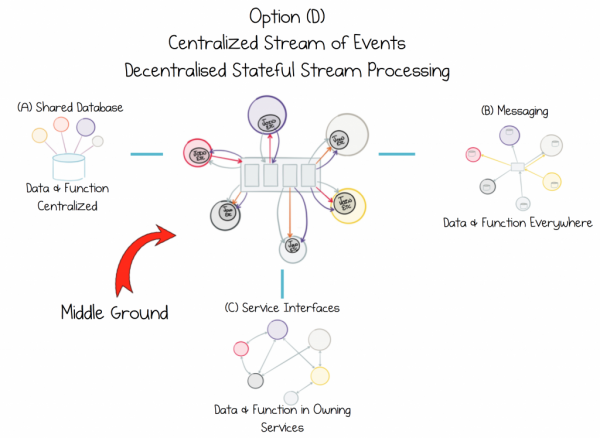
Делитесь данными так, чтобы не нарушалась их целостность. Инкапсулируйте функцию, а не источник, в каждом сервисе, которому он нужен.
Так случается, что данные нужно массово переместить. Порой сервису требуется локальный исторический набор данных в выбранном движке базы данных. Фокус в том, что можно гарантировать, что при надобности копия может быть восстановлена из источника с помощью обращения в механизм распределённого логирования. Коннекторы в Kafka отлично справляются с этой задачей.
Итак, у рассмотренного сегодня подхода имеется несколько преимуществ:
- Данные используются в виде общих потоков, которые могут долго храниться в логах, а сам механизм работы с общими данными зашит в каждом отдельном контексте, что позволяет сервисам работать легко и быстро. Таким способом можно уравновесить дихотомию данных.
- Данные, поступающие из различных сервисов, могут с легкостью объединяться в наборы. Таким образом упрощается взаимодействие с общими данными и исчезает необходимость в поддержке локальных наборов данных в базе данных.
- Stateful Stream Processing только кэширует данные, а источником истины остаются общие логи, поэтому проблема повреждения данных с течением времени стоит не так остро.
- По своей сути, сервисы управляются данными, то есть несмотря на постоянный рост объемов данных, сервисы все еще могут быстро реагировать на бизнес-события.
- Проблемы масштабируемости ложатся на брокера, а не на сервисы. Таким образом значительно уменьшается сложность написания сервисов, поскольку отсутствует необходимость задумываться о масштабируемости.
- Добавление новых сервисов не требует изменения старых, поэтому подключение новых сервисов становится легче.
Как видите, это больше, чем просто REST. Мы получили набор инструментов, который позволяет работать с общими данными децентрализовано.
В сегодняшней статье были раскрыты далеко не все аспекты. Нам все еще нужно определиться с тем, как балансировать между парадигмой «запрос-ответ» и событийно-ориентированной парадигмой. Но с этим мы разберемся в следующий раз. Есть темы, с которыми нужно познакомиться получше, например, чем так хорош Stateful Stream Processing. Об этом мы поговорим в третьей статье. А еще существуют другие мощные конструкции, которыми мы можем воспользоваться, если прибегнем к ним, например, . С ее помощью меняются правила игры для распределенных бизнес-систем, поскольку эта конструкция обеспечивает транзакционные гарантии для в масштабируемой форме. Об этом речь пойдет в четвертой статье. И наконец, нам нужно будет пробежаться по деталям реализации этих принципов.
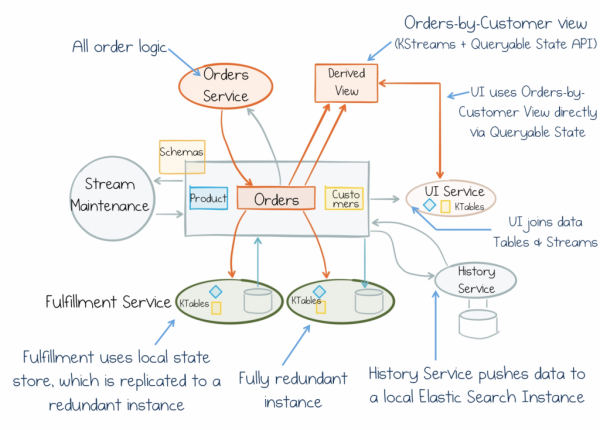
Но пока просто запомните следующее: дихотомия данных – это та сила, с которой мы сталкиваемся при создании бизнес-сервисов. И мы должны об этом помнить. Фокус в том, чтобы перевернуть все с ног на голову и начать считать общие данные объектами первого класса. Stateful Stream Processing предоставляет для этого уникальный компромисс. Он избегает централизованных “God Components” сдерживающих развитие прогресса. Более того, он обеспечивает оперативность, масштабируемость и отказоустойчивость пайплайнов стриминга данных и добавляет их в каждый сервис. Поэтому мы можем сфокусироваться на общем потоке сознания, к которому может подключиться любой сервис и работать с его данными. Так сервисы получаются более масштабируемыми, взаимозаменяемыми и автономными. Поэтому они будут не только хорошо выглядеть на маркерных досках и при проверке гипотез, но и работать и развиваться десятилетиями.
Источник: habr.com
