

Когда мы говорим о стеганографии, люди представляют террористов, педофилов, шпионов, ну в лучшем случае криптоанархистов и прочих ученых. И действительно, кому еще может понадобиться скрывать что-то от внешних взоров? Какая вообще от этого может быть польза простому человеку?
Оказывается, какая-то есть. Именно поэтому мы сегодня будем сжимать данные с помощью методов стеганографии. А в конце читатель даже сможет использовать свои драгоценные фотоархивы в JPEG`ах для увеличения количества свободных гигабайт на файловой системе.

Что?
Если читатель помнит, то стеганография — это такие странные алгоритмы, позволяющие скрыть наличие одной информации внутри другой. Еще более простым языком: картинка + файл == примерно та же картинка, но не совсем (вместо картинок может быть что угодно, но обычно на них все понятнее). При этом не должно быть простого способа определения, есть ли что-то внутри или нет.
Но если отличить одно от другого нельзя, то есть ли вообще разница? С точки зрения потребителя, пользователя не волнует математическая точность (отраженная конкретным набором бит), лишь воспринимаемая им.
Например, посмотрим на три изображения милой собаки:
Осторожно, JPEG!



Несмотря на колоссальную разницу в размере, мало кто выберет третью версию. С другой стороны, между первыми двумя фотографиями разница не столь заметна, и количества информации в них (с моей точки зрения) можно приравнять.
Сам по себе этот принцип уже стар и много лет активно эксплуатируется методами сжатия информации с потерями. Но ломать — не строить, нас интересует более продвинутая сторона вопроса. Можно ли встроить дополнительную информацию размера N в файл так, чтобы его размер увеличился на M < N, а изменения не были заметны пользователю?
Конечно же, можно. Но стоит сразу сделать пару оговорок:
- Во-первых, метод должен быть универсальным и давать положительный результат на большинстве входных данных. То есть, в среднем, для произвольного входа, должно происходить фактическое уменьшение хранимого количества информации. «В среднем» означает, что противоположные случаи происходить могут, но не должны преобладать.
- Во-вторых, размер сжатого контейнера до встраивания информации должен быть большим, нежели сжатый аналогичным образом его модификация. Просто встроить в BMP картинки методом LSB кучу бит — не стеганографическое сжатие, так как, будучи прогнанным через какой-нибудь DEFLATE, оригинальное изображение, скорее всего, будет заметно меньше.
- В третьих, проводить и сравнивать результат нужно относительно уже сжатых классическими методами данных. Это позволит убрать вероятностный эффект различия их избыточности и провести более эффективное сжатие в общем случае.
Где?
Использование стеганографии подразумевает, что, помимо сжимаемой информации, нам потребуются контейнеры, в которые она будет встроена. Максимальное количество встраиваемой информации во многом зависит от отдельных свойств, но куда проще масштабируется с их количеством. Поэтому формат контейнеров должен быть распространенным, чтобы у пользователя было достаточное их количество для получения хоть какой отдачи от процесса «сжатия».
В таком контексте хорошими кандидатами становятся графические, аудио- и видеофайлы. Но, из-за разнообразия различных форматов, кодеков и пр, на практике нам остается выбор из не такого уж и большого числа вариантов.
Учитывая все это, мой выбор пал на JPEG, Он есть практически у всех, широко используется как в личных, так и в целях бизнесов, являясь чуть ли не форматом де-факто для большинства изображений.

К̶о̶г̶д̶а̶ Как?
Дальше идут около- и технические схемы и описания без особых объяснений, поэтому желающие могут их пропустить, промотав до раздела «Высокие технологии».
Общие черты
Чтобы встроить данные куда-то, надо сначала определить, куда. На файловой системе может находиться сколько угодно различных фотографий, среди которых пользователь может хотеть использовать лишь некоторые. Такое желаемое множество контейнеров будем звать библиотекой.
Она формируется в двух случаях: до сжатия и до распаковки. В первом случае можно просто использовать набор имен (а лучше, регулярное выражение для них) файлов, но во втором требуется что-то более надежное: пользователь может копировать и перемещать их в пределах файловой системы, тем самым не давая корректно их определить. Поэтому требуется хранить их хэши (md5 хватит) после проведения всех модификаций.
Изначальный поиск по регулярному выражению при этом нет смысла проводить по всей ФС, достаточно указать некоторую корневую директорию. В нее же будет сохраняться специальный файл-архив, в котором будут находиться те хэши, наравне с другой мета-информацией, необходимой для последующего восстановления сжимаемой информации.
Все это применимо в равной степени к любой реализации любого алгоритма стеганографического сжатия данных. Сами процессы сжатия и восстановления данных можно звать упаковкой и распаковкой.
F5
Теперь, когда стало понятно(/ее), что делаем и зачем, осталось описать сам алгоритм достижения цели. Вспомним процесс кодирования JPEG-файла (спасибо вики национальной библиотеки им. Баумана):

Смотря на него, лучше сразу сделать несколько замечаний:
- Размер JPEG-файла можно считать оптимальным, даже не пробуя сжать каким-нибудь винраром;
- Изменять можно только хранимую информацию (ту, что на выходе дискретно-косинусоидального преобразования, DCT), чтобы обеспечить хоть сколько-нибудь приемлемую производительность.
- Чтобы не терять данные в заметных пользователю промышленных масштабах, требуется вносить минимум модификаций в каждое отдельное изображение;
Под такие условия подходит целое семейство алгоритмов, с которым можно ознакомиться . Самым продвинутым из них является алгоритм за авторством Андреаса Вестфелда, работающий с коэффициентами DCT компоненты яркости (человеческий глаз наименее чувствителен именно к ее изменением). Его общая схема при работе с существующим JPEG-файлом отображается следующей схемой:
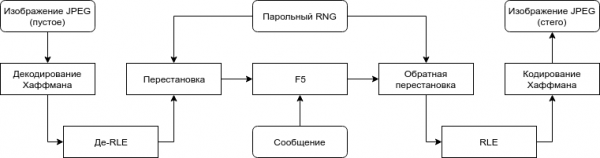
Блок F5 использует продвинутую методику встраивания, основанную на кодировании матрицы. Подробнее с ней и самим алгоритмом читатель может ознакомиться по ссылке выше, нас же интересует в первую очередь тот факт, что с его помощью можно совершать тем меньше изменений при встраивании одного и того же количества информации, чем больше размер используемого контейнера, а для проведения самого алгоритма требуется провести лишь простые операции (де)кодирования Хаффмана и RLE.
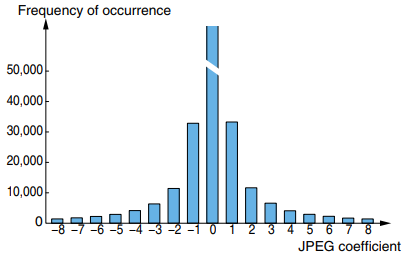
Сами изменения при этом производятся над целочисленными коэффициентами и сводятся к уменьшению их абсолютного значения на единицу, что и позволяет, вообще говоря, использовать F5 для сжатия данных. Дело в том, что уменьшенный по абсолютному значению коэффициент, скорее всего, будет занимать меньшее число бит после проведения кодирования Хаффмана из-за статистического распределения значений в JPEG.
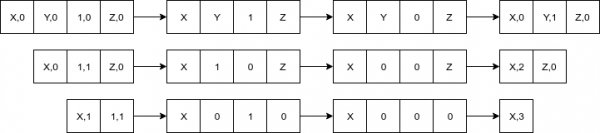
В случае же образования нуля (т.н. сокращения), число хранимой информации сократится на его размер, так как бывший самостоятельный коэффициент станет частью закодированной RLE последовательности нулей:
Модификации
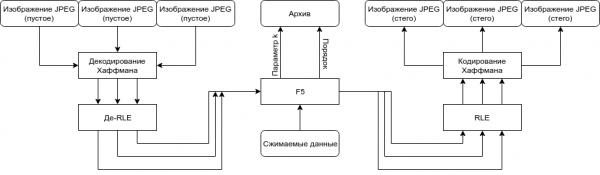
Защита данных и их сжатие — задачи ортогональные, поэтому можно пренебречь секретной парольной перестановкой из оригинального алгоритма. Более того, нам нужно точно знать, как извлечь данные, поэтому вся необходимая для этого информация (какие контейнеры были использованы, в каком порядке и пр.) должна записываться в отдельный файл и быть открыта для свободного чтения архиватором.
Оригинальный алгоритм рассчитан на передачу секретных сообщений, поэтому работает за раз лишь с одним контейнером, предполагая, что пользователь сам будет разбивать его на части при необходимости, если таковая вообще возникнет. Более того, при независимом встраивании в каждый контейнер потребуется заранее знать, сколько бит данных поместить в каждый. Поэтому коэффициенты каждого элемента библиотеки стоит объединить в один абстрактный большой и работать с ним по исходному алгоритму.
Так как оригинальный F5 позволяет использовать до 12% размера контейнера, такая модификация также увеличит максимальную емкость: «до 12%» от размера всей библиотеки больше либо равно сумме «до 12%» от каждого из ее элементов.
Кодифицированная общая схема выглядит следующим образом:
Сам алгоритм
Теперь пора описать сам алгоритм от начала до конца, чтобы не держать читателя в неведении:
- Пользователь определяет бинарные сжимаемые данные M и библиотеку L с помощью регулярного выражения и корневой директории поиска;
- В порядке следования на ФС элементы библиотеки формируют MC:
- Из данных файла декодируется серия коэффициентов C;
- MC <- MC | C;
- Определяется параметр k исходя из страшного неравенства:
|M| * 8 / (count_full(MC) + count_ones(MC) * k_rate(k)) < k / ((1 << k) - 1); - Очередно берется
n = (1 << k) - 1младших бит ненулевых элементов из MC и записывается вa:- Считается магическая хэш-функция
f, отображающая n-битное словоaв k-битноеs; - Если
s == 0, то ничего изменять и не надо и алгоритм переходит к следующим коэффициентам; - Уменьшить абсолютное значение коэффициента, отвечающего за
s-эй бит в словеa; - Если в результате уменьшения произошло сокращение (коэффициент стал 0), то повторить шаг с начала;
- Считается магическая хэш-функция
- Все коэффициенты кодируются RLE и Хаффманом, записываются в исходные файлы;
- В файл архива записывается параметр k;
- От каждого файла L в порядке их исходного нахождения считается MD5-хэш и записывается в файл архива.
Высокие технологии
Наивная форма алгоритма и реализации на других высокоуровневых (особенно, со сборкой мусора) языках дали бы ужасную производительность, поэтому все эти сложности я реализовал на чистом Си и провел ряд оптимизаций как по скорости выполнения, так и по памяти (вы не представляете, сколько эти картиночки весят без сжатия даже до DCT). Но и так, поначалу скорость исполнения оставляла желать сильно лучшего, поэтому я не буду описывать весь процесс и использованные методы.
Кросс-платформенность достигнута использованием комбинации библиотек libjpeg, pcre и tinydir, за что им спасибо. По умолчанию все компилируется через обычный make, поэтому пользователи Windows хотят установить себе какой-нибудь Cygwin, либо разбираться с Visual Studio и библиотеками самостоятельно.
Реализация доступна в форме консольной утилиты и библиотеки. Подробнее про использование последней желающие могут ознакомиться в ридми в репозитории на гитхабе, ссылку на который я приложу в конце поста. А тут перейдем к описанию и демонстрации работы.
Как использовать?
С осторожностью. Использованные изображения можно перемещать, переименовывать и копировать по желанию. Однако, стоит быть крайне аккуратным и никак не изменять их содержимое. Изменение одного бита приведет к нарушению хэша и невозможности восстановления информации.
Пусть после компиляции мы получили исполняемый файл f5ar. Можно анализировать размер библиотеки для расчета возможностей ее использования с помощью флага -a: ./f5ar -a [папка поиска] [Perl-совместимое регулярное выражение]. Упаковка производится командой ./f5ar -p [папка поиска] [Perl-совместимое регулярное выражение] [упаковываемый файл] [имя архива], а распаковка с помощью ./f5ar -u [файл архива] [имя восстановленного файла].
Демонстрация работы
Чтобы показать эффективность работы метода, я загрузил коллекцию из 225 абсолютно бесплатных фотографий собак с сервиса . Каждая из них обладает чуть более высоким качеством, нежели обычные пользовательские фотографии, но тем не менее. Каждая из них была перекодирована с помощью libjpeg, чтобы нивелировать влияние особенностей кодирования библиотеки на общий размер. Для обозначения худшего примера сжимаемых данных с помощью dd был сгенерирован случайный 36-метровый (немногим больше 5% от общего размера) равномерно-распределенный файл.
Процесс тестирования довольно прост:
$ ls
binary_data dogs f5ar
$ du -sh dogs/
633M dogs/
$ du -h binary_data
36M binary_data
$ ./f5ar -p dogs/ .*jpg binary_data dogs.f5ar
Reading compressing file... ok
Initializing the archive... ok
Analysing library capacity... done in 16.8s
Detected somewhat guaranteed capacity of 48439359 bytes
Detected possible capacity of upto 102618787 bytes
Compressing... done in 32.6s
Saving the archive... ok
$ ./f5ar -u dogs/dogs.f5ar unpacked
Initializing the archive... ok
Reading the archive file... ok
Filling the archive with files... done in 1.2s
Decompressing... done in 17.5s
Writing extracted data... ok
$ sha1sum binary_data unpacked
ba7ade4bc77881ab463121e77bbd4d41ee181ae9 binary_data
ba7ade4bc77881ab463121e77bbd4d41ee181ae9 unpacked
$ du -sh dogs/
563M dogs/Или скриншотом для любителей
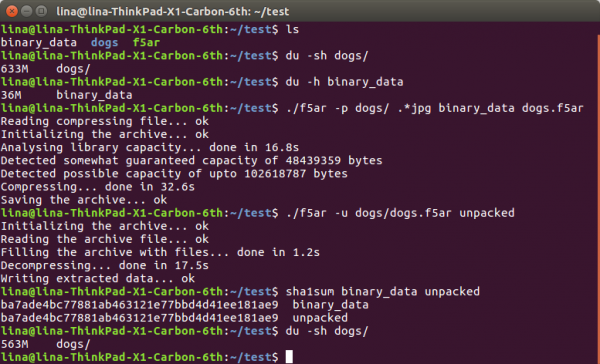
Как видно, с исходных 633 + 36 == 669 мегабайт данных на жестком диске мы пришли к более приятным 563, дающим нам коэффициент сжатия ~1,188. Такая радикальная разница объясняется крайне небольшими потерями, аналогичными получаемыми при оптимизации JPEG-файлов классическими методами (типа tinyjpg). Естественно, при использовании стеганографического сжатия информация не просто «теряется», но используется для кодирования других данных, Более того, количество «оптимизированных» коэффициентов за счет использования F5 куда меньше, нежели при традиционной оптимизации.
Какие бы модификации не были, для глаза они не заметны абсолютно. Под спойлером ниже читатель может оценить разницу как на глаз, так и полученную вычитанием значений измененной компоненты из оригинальной (чем более приглушен цвет, тем меньше разница):
Ссылки на изображения, не поместившиеся на habrastorage
Оригинал —
Модифицированный —
Разница —
Вместо заключения
Надеюсь, я смог убедить читателя, что такие методы возможны и имеют право на жизнь. Тем не менее, купить жесткий диск или дополнительный канал (для сетевой передачи) может показаться куда более простым выходом, чем пытаться экономить таким образом. С одной стороны, это и правда так, экстенсивное развитие часто более простое и надежное. Но с другой, не стоит забывать про и интенсивное. Ведь нет никаких гарантий, что завтра можно будет придти в магазин и купить себе очередной жесткий диск на тысячу терабайт, а вот использовать уже лежащие дома можно всегда.
->
Источник: habr.com
