

Предлагаю ознакомиться с расшифровкой доклада Романа Хавроненко "ExtendedPromQL"

Кратко обо мне. Меня зовут Роман. Я работаю в CloudFlare, живу в Лондоне. Но также я мейтенер VictoriaMetrics.
И я автор для Grafana и – это маленький прокси для ClickHouse.

Мы начнем с первой части, которая называется «Сложности перевода» и в ней я буду рассказывать о том, что любой язык или даже просто язык общения – это очень важно. Потому что это то, как вы передаете другому человеку или системе свои мысли, как вы формулируете запрос. Люди в интернете спорят о том, какой язык лучше – java или какой-то другой. Для себя я решил, что надо выбирать под задачу, потому что все это специфично.

Начнем с самого начала. Что такое PromQL? PromQL – это Prometheus Query Language. Это то, как мы формируем запросы в Prometheus, чтобы получить time series данные, временные ряды.

Что такое time series данные? Если буквально, то это три параметра.
Это:
- На что мы смотрим.
- Когда мы на это смотрим.
- И какое значение показывает.
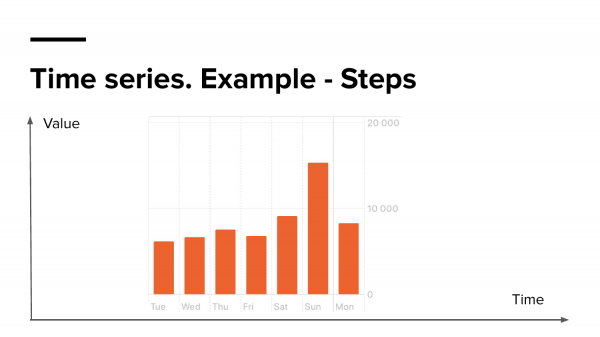
Если посмотреть на эту диаграмму (эта диаграмма с моего телефона, которая показывает статистику моих шагов), то здесь можно быстро ответить на эти вопросы.
Мы смотрим на шаги. Мы видим значение и видим время, когда мы смотрим на это. Т. е. смотря на эту диаграмму легко можно сказать, что в воскресенье я прошел около 15 000 шагов. Это time series данные.
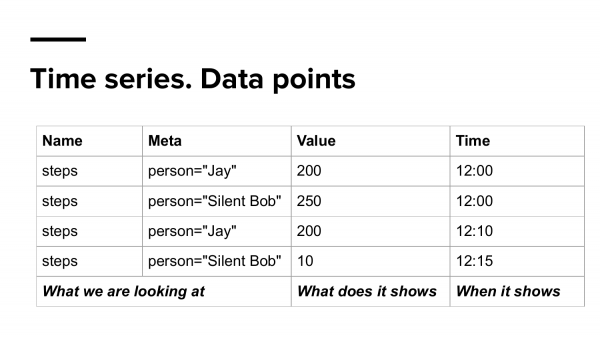
Теперь давайте "разобьем" (преобразуем) их в другую модель данных в виде таблицы. Здесь у нас тоже есть то, на что мы смотрим. Тут я немного добавил дополнительные данные, которые мы будем называть мета-данными, т. е. это прошел не я, а два человека, допустим, Jay и Silent Bob. Вот это то, на что мы смотрим; что это показывает и когда оно показывает это значение.

Теперь давайте попытаемся сохранить все эти данные в базе данных. Для примера я взял ClickHouse синтаксис. И здесь мы создаем одну таблицу, которая называется «Steps», т. е. на что мы смотрим. Тут есть время, когда мы на это смотрим; что оно показывает и какие-то мета-данные, где мы будем хранить, кто это: Jay и Silent Bob.
И для того чтобы попытаться визуализировать это все, мы будем использовать Grafana, потому что, во-первых, это красиво.

Также мы будем использовать этот плагин. На это есть две причины. Первая – потому что я его написал. И я точно знаю, как тяжело вытаскивать time series данные из ClickHouse, чтобы показать в Grafana.
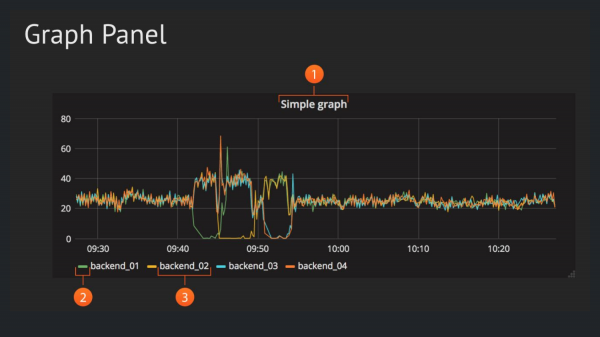
Отображать мы будем в Graph Panel. Это самая популярная панель в Grafana, которая показывает зависимость значения от времени, поэтому нам надо всего лишь два параметра.

Давайте напишем самый простой запрос — как показать статистику шагов в Grafana, храня эти данные в ClickHouse, в той таблице, что мы создали. И мы пишем вот такой простой запрос. Мы выбираем из шагов. Мы выбираем значение и выбираем время этих значений, т. е. те же три параметра, о которых мы говорили.
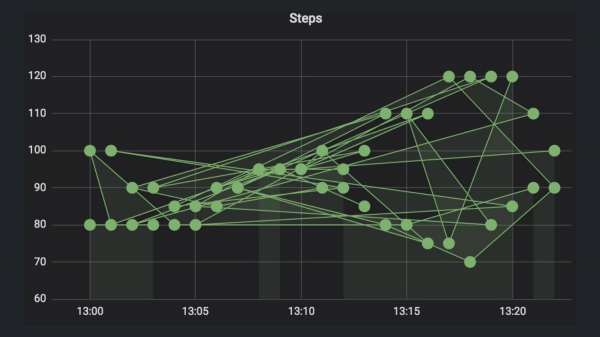
И в результате мы получим вот такой график. Кто знает, почему он такой странный?

Правильно, надо отсортировать по времени.
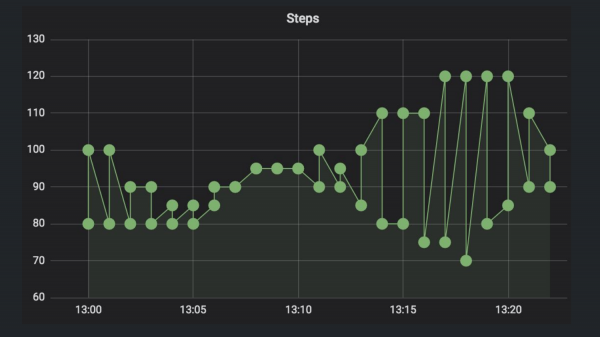
И в итоге мы получим уже получше, но все еще странный график. Кто знает, почему? Правильно, там два участника, и мы в Grafana отдаем два time series, потому что если разобраться с дата-моделью еще раз, то каждая time series – это уникальная комбинация имени и всех ключ-значений labels.

Поэтому нам надо выбрать конкретного человека. Мы выбираем Jay.

И рисуем еще раз. Теперь уже график похож на правду. Теперь это нормальный график и все работает хорошо.

И, наверное, вы знаете, как сделать примерно то же самое, но в Prometheus через PromQL. Примерно вот так вот. Немного проще. И еще разобьем это все. Мы брали Steps. И фильтруем по Jay. Мы здесь не указываем, что нам надо получить значение и мы не выбираем время.

А теперь попробуем посчитать скорость передвижения Jay или Silent Bob. В ClickHouse нам надо будет сделать runningDifference, т. е. посчитать различие между парами точек и разделить их на время, чтобы получить точную скорость. Запрос будет выглядеть примерно вот так.
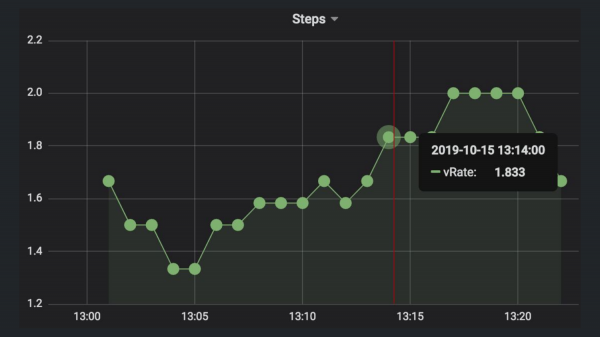
И покажет он примерно вот такие значения, т. е. примерно 1,8 шага в секунду делает Silent Bob или Jay.

И в Prometheus вы знаете, как это сделать тоже. Намного проще, чем было до этого.
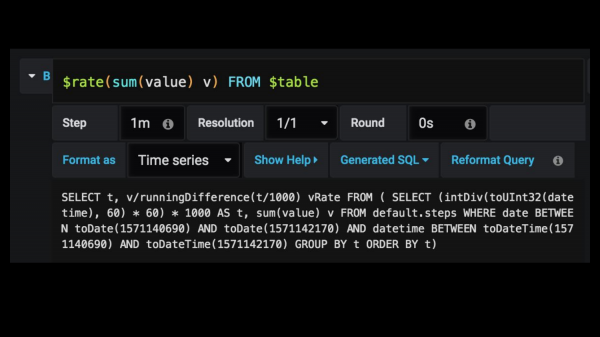 И чтобы это оставалось также просто делать в Grafana я добавил вот такую обертку, которая очень похоже выглядит на PromQL. Она называется Rate Macros или как хотите ее называйте. В Grafana вы пишите просто «rate», но где-то в глубине она трансформируется вот в такой большой запрос. И вам не надо даже на него смотреть, он где-то там есть, но вы экономите кучу времени, потому что писать такие огромные SQL-запросы – это всегда затратно. Вы можете легко ошибиться и потом долго не понимать, что происходит.
И чтобы это оставалось также просто делать в Grafana я добавил вот такую обертку, которая очень похоже выглядит на PromQL. Она называется Rate Macros или как хотите ее называйте. В Grafana вы пишите просто «rate», но где-то в глубине она трансформируется вот в такой большой запрос. И вам не надо даже на него смотреть, он где-то там есть, но вы экономите кучу времени, потому что писать такие огромные SQL-запросы – это всегда затратно. Вы можете легко ошибиться и потом долго не понимать, что происходит.

А это запрос, который не поместился даже в один слайд и мне пришлось его даже разбить на две колонки. Это тоже запрос в ClickHouse, который делает тот же самое rate, но по обеим time series: и Silent Bob, и по Jay, чтобы у нас на панели были две time series. И это уже очень сложно, на мой взгляд.

И по Prometheus это будет sum (rate). Для ClickHouse я сделал отдельный макрос, который называется RateColumns, который выглядит, как запрос в Prometheus.

Мы посмотрели и вроде бы PromQL весь такой классный, но у него есть, конечно, ограничения.
Это:
- Limited SELECT.
- Пограничные JOIN.
- Нет поддержки HAVING.
И если вы проработали с ним долго, то вы знаете, что иногда очень тяжело сделать что-то в PromQL, а в SQL можно делать практически все, потому что все эти варианты, которые мы сейчас проговорили, можно было сделать в SQL. Но было бы удобно этим пользоваться? И это наталкивает меня на мысль, что не всегда самый мощный язык может быть самым удобным.

Поэтому иногда надо выбирать язык под задачи. Это как битва Бэтмена с Суперменом. Понятно, что Супермен сильнее, но Бэтмен смог его победить, потому что он более практичен и точно знал, что он делает.

И следующая часть – это Extending PromQL.

Еще раз про VictoriaMetrics. Что такое VictoriaMetrics? Это time series базы данных, она в OpenSource, мы дистрибьютим ее single и cluster-версии. По нашим бенчмаркам она быстрее всего, что есть на рынке сейчас и по компрессии аналогично, т. е. живые люди репортят компрессию где-то в 0,4 байт на точку, когда у Prometheus – это 1,2-1,4.
Мы поддерживаем не только Prometheus. Мы поддерживаем InfluxDB, Graphite, OpenTSDB.
В нас можно "писать", т. е. можно переносить старые данные.
И еще мы идеально работаем с Prometheus и Grafana, т. е. мы поддерживаем PromQL engine. И в Grafana вы можете просто поменять Prometheus endpoint на VictoriaMetrics и у вас все дашборды будут работать, как и работали.
Но вы можете использовать и дополнительные фишки, которая дает VictoriaMetrics.
Мы быстро пройдем по функциям, которые мы добавили.

Omit interval param – вы можете пропускать интервал параметров в Grafana. Когда вы не хотите получать странные графики при zoom-in/out в панели, то рекомендуется использовать переменную $__interval. Это внутренняя перемена Grafana и она сама выбирает диапазон данных. И VictoriaMetrics может сама понимать, каким этот диапазон доложен быть. И вам не надо апдейтить все ваши запросы. Будет намного проще.

Вторая функция – это interval referencing. Вы можете использовать этот интервал в своих выражениях. Вы можете умножать, делить, передавать, ссылаться на него.

Далее семейство rollup function. Rollup function трансформирует любой ваш time series в три отдельные time series. Это min, max и avg. Я считаю, что это очень удобно, потому что иногда это может показать какие-то outliers (аномалии ) и неточности.
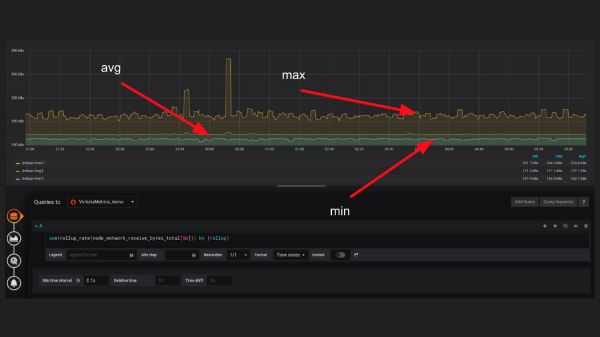
И если вы просто делаете irate или rate, то вероятно вы можете пропустить какие-то случаи, когда time series ведет себя не так, как вы предполагали. С этой функцией намного проще увидеть, допустим, что max очень сильно от avg.
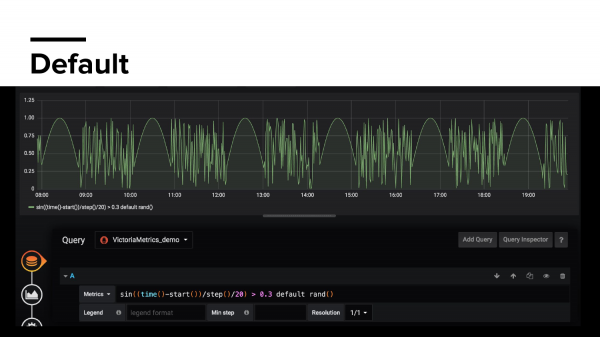
Дальше переменная default. Default – это значит, какое значение нам нужно отрисовать в Grafana, если у нас нет time series в данный момент. Когда это происходит? Допустим вы экспортируете какую-то метрику по ошибкам. И у вас такое классное приложение, что когда вы стартовали, то у вас нет ошибок и даже нет ошибок в следующие три часа или даже день. И у вас есть дашборды, которые показывают отношения с success к error. И они будут вам показывать ничего, потому что у вас нет метрики error. А в default вы можете указать что угодно.
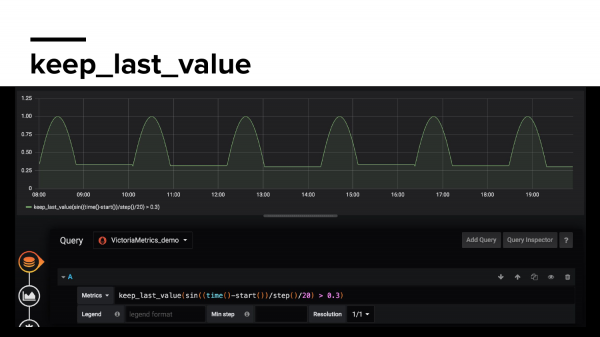
Keep_last_Value – сохраняет последнее значение метрики, если она пропала. Если Prometheus после следующего скрейпа не нашел ее в течении 5 минут, то здесь мы будем запоминать ее последнее значение и ваши графики снова не сломаются.
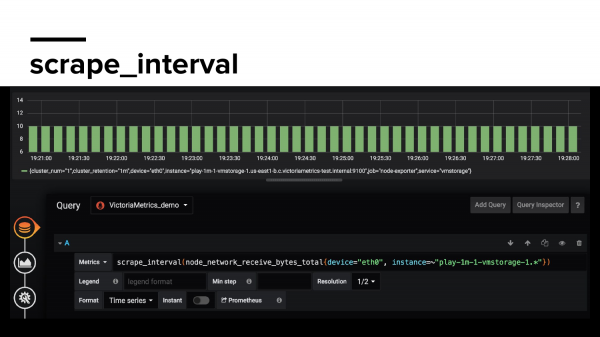
Scrape_interval – показывает, как часто Prometheus собирает данные по ваше метрике, с какой частотой. Здесь можно увидеть пропуск, например.

Label replace – популярная функция. Но мы считаем, что она немного сложная, потому что она принимает целых аргументов. И вам надо не только помнить 5 аргументов, но еще и помнить их последовательность.

Поэтому, почему бы не сделать их попроще? Т. е. разбить на мелкие функции с понятным синтаксисом.

И теперь самое интересное. Почему мы считаем, что это extended PromQL? Потому что мы поддерживаем Common Table Expressions. Вы можете перейти по QR-коду (), посмотреть ссылки с примерами, с playground, где можете выполнить запросы непосредственно в VictoriaMetrics без ее установки просто в браузере.

И что же это такое? Вот этот запрос сверху – это довольно популярный запрос. Я думаю, в любом дашборде во многих компаний вы используете один и тот же фильтр для всего. Обычно так. Но когда вам нужно добавить какой-то новый фильтр, то приходится обновлять каждую панель, либо скачивать дашборд, открывать в JSON, делать find replace, что тоже занимает время. Почему бы не сохранять это значение в переменной и переиспользовать его? Это выглядит, на мой взгляд, на много проще и понятней.
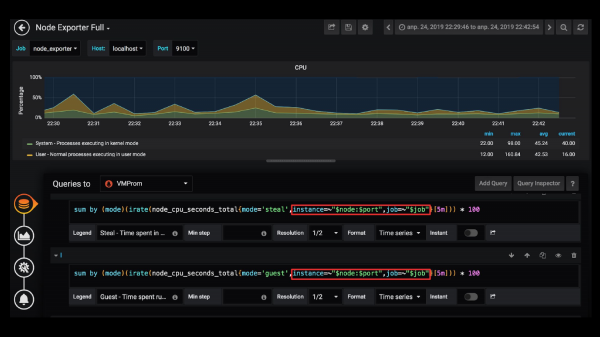
Например, когда мне надо обновлять фильтры в Grafana во всех запросах, а дашборд при этом может быть огромный или их может быть даже несколько. И как бы я хотел решать эту проблему в Grafana?
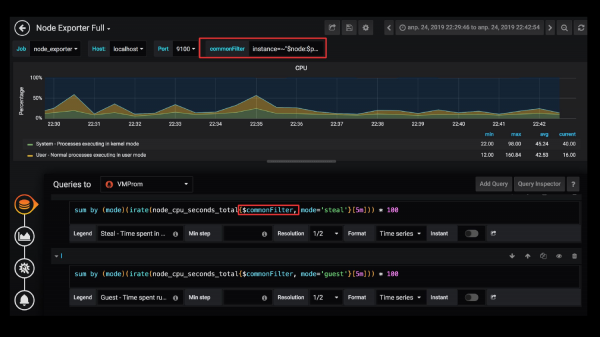
Я решаю эту проблему так: я делаю commonFilter и в нем определяю этот фильтр, а потом его переиспользую в запросах. Но если вы сделаете сейчас так же, это не будет работать, потому что Grafana не разрешает вам использовать переменные внутри переменных запросов. И это немного странно.
И поэтому я сделал такой вариант, который разрешает это делать. И если вам интересно или вы хотите такую фичу, то поддержите или дизлайкните, если вам не нравится такая идея.

Дальше про PromQL extended. Здесь мы определяем не только переменную, но прямо целую функцию. И называем ее ru (resource usage). И принимает эта функция свободные ресурсы, ограничение по ресурсу и фильтр. Вроде бы синтаксис весь простой. И очень легко использовать эту функцию и посчитать процент свободной памяти у нас. Т. е. сколько у нас есть памяти, какое ограничение и как фильтровать. Это выглядит намного удобнее, если бы вы писали это все, переиспользуя одни и те же фильтры, потому что это бы превратилось в большой-большой запрос.

И вот пример такого большого-большого запроса. Он из официального дашборда NodeExporter для Grafana. Но я слабо понимаю, что здесь происходит. Т. е., конечно, понимаю, если присмотреться, но количество скобок может сразу понизить мотивацию разбираться в том, что здесь происходит. И почему бы не сделать его проще и понятней?

Например, вот так, выделив значимые вещи или части в переменные. И потом произвести свою базовую математику. Это уже более похоже на программирование, это то, что я бы и хотел видеть в будущем в Grafana.

Вот второй пример, как мы можем сделать это еще проще, если бы у нас уже была эта функция ru, а она уже есть непосредственно в VictoriaMetrics. И вы тогда просто передаете закэшированное значение, которое вы обьявили в CTE.
Я уже говорил, о том, как важно использовать нужный язык программирования. И, наверное, в каждой компании в Grafana творится что-нибудь свое. И, наверное, вы еще даете доступ к Grafana своим разработчикам, и разработчики делают что-то свое. И все они делают это как-то по-разному. А хотелось, чтобы как-то одинаково, т. е. свести к общему стандарту.
Допустим, у вас есть даже не просто системные инженеры, может быть у вас даже есть эксперты, девопсы или SRE. Может у вас есть эксперты, которые знают, что такое мониторинг, знают, что такое Grafana, т. е. они работают с этим годами и они точно знают, как делать правильно. И они уже писали это 100 раз и всем объясняли, но почему-то никто не слушает.
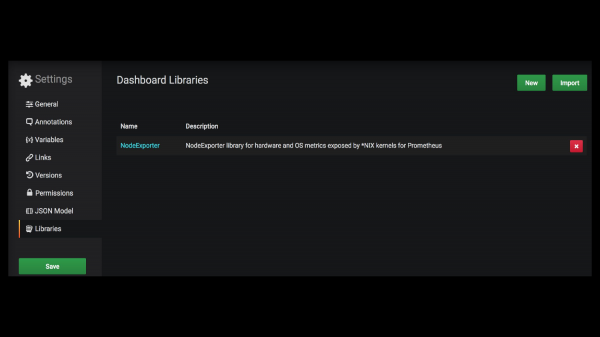
А что, если бы они смогли эти знания непосредственно положить в Grafana, чтобы другие пользователи могли переиспользовать функции? И если бы надо было бы посчитать процент свободной памяти, то они бы просто применили функцию. А что, если создатели экспортеров, вместе со своим продуктом предоставляли также и набор функций, как работать с их метриками, потому что они точно знают, что это за метрики и как их правильно считать?
Вот этого на самом деле не существует. Вот это я сделал сам. Это поддержка библиотек в Grafana. Допустим, ребята, которые сделали NodeExporter, сделали то, о чем я рассказал. И предоставили также набор функций.
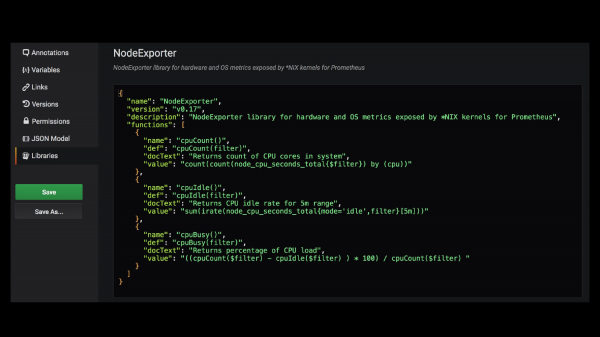
Т. е. выглядит это примерно так. Вы подключаете эту библиотеку в Grafana, вы заходите в редактирование и тут очень просто в JSON написано, как работать с этой метрикой. Т. е. какой-то набор функций, их описание и во что они разворачиваются.
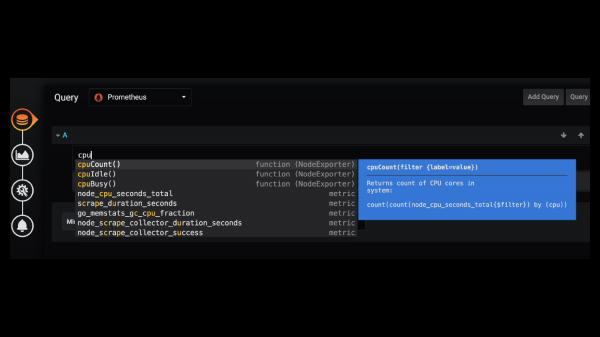
По-моему, это могло бы быть полезным, потому что тогда в Grafana вы бы писали просто так. И вам Grafana "говорит", что есть вот такая-то функция с такой-то библиотеки – давайте ее использовать. Мне кажется, что это было бы очень здорово.

Немного про VictoriaMetrics. Мы делаем очень много интересных вещей. Почитайте наши статьи про compression, про наши соревнования с другими time series приложениями данных, наше пояснение как работать с PromQL, потому что в этом много еще новичков, а также про vertical scalability и про противостояние с Thanos.

Вопросы:
Я начну свой вопрос с простой жизненной истории. Когда я впервые начал использовать Grafana, я написал очень убедительный запрос длиной в 5 строк. В итоге получился очень убедительный график. Этот график почти уехал в production. Но при ближайшем рассмотрении оказалось, что этот график показывает абсолютную ахинею, не имеющую никакого отношения к реальности, хотя цифры попадают в диапазон, который мы ожидали увидеть. И мой вопрос. У нас есть библиотеки, у нас есть функции, а как мы пишем тесты для Grafana? Вы написали сложный запрос, от которого зависит бизнес-решение – заказать настоящий контейнер серверов или не заказывать. И как мы знаем, эта функция, которая рисует график похожа на правду. Спасибо.
Спасибо за вопрос. Тут две части. Первая – у меня складывается впечатление, исходя из моей практики, что большинство пользователей, когда смотрят на свои графики, не понимают, что они им показывают. Почему-то люди очень хороши в том, чтобы придумать оправдание любой аномалии, которая происходит на графиках, даже если это ошибка внутри функции. И вторая часть – мне кажется, что использование вот таких функций намного лучше подошло бы к решению вашей проблемы, вместо того, чтобы каждый из ваших разработчиков делал свой capacity planning и ошибался с какой-то вероятностью.
Как проверить?
Как проверить? Наверное, никак.
В виде теста в Grafana.
Причем тут Grafana? Grafana транслирует этот запрос непосредственно в DataSource.
Добавляя чуть-чуть в параметры.
Нет, в Grafana ничего не добавляют. Там могут быть GET-параметры, как, допустим, step. Он явно не указывается, но вы его можете переопределить, можете не переопределять, но он добавляется автоматически. Вы здесь не напишите тесты. Я думаю, что не стоит полагаться здесь на Grafana, как на источник правды.
Спасибо за доклад! Спасибо за компрессию! Вы вспоминали про mapping переменной в графике, что в Grafana нельзя использовать переменную в переменной. Понимаете, о чем я?
Да.
Это было изначально головной болью, когда я хотел сделать alert в Grafana. И там нужно alert делать для каждого хоста отдельно. Вот эта штука, которую вы сделали, она работает для alerts в Grafana?
Если Grafana не обращается к переменным как-то по-другому, то – да, она будет работать. Но мой совет не использовать алертинг в Grafana вообще, вам лучше использовать alertmanager.
Да, я его использую, но просто это в Grafana показалось легче в настройке, но спасибо за совет!
Источник: habr.com
