

Тема крупных аварий в современных ЦОД вызывает вопросы, на которые в первой статье не было ответов — мы решили ее развить.

Если верить статистике Uptime Institute, большая часть инцидентов в дата-центрах связана с отказами системы электроснабжения — на их долю приходится 39 % происшествий. За ними следует человеческий фактор — это еще 24 % аварий. Третьей по значимости (15 %) причиной стали отказы системы кондиционирования, а на четвертом месте (12 %) оказались природные катаклизмы. Суммарная доля прочих неприятностей составляет лишь 10 %. Не ставя под сомнение данные уважаемой организации, выделим в разных авариях нечто общее и попытаемся понять, можно ли было их избежать. Спойлер: можно в большинстве случаев.
Наука о контактах
Говоря упрощенно, с электропитанием бывает всего две проблемы: либо контакта нет там, где он должен быть, либо он есть там, где контакта быть не должно. Можно долго рассуждать о надежности современных систем бесперебойного электроснабжения, но спасают они далеко не всегда. Взять хотя бы нашумевший случай с используемым British Airways центром обработки данных, принадлежащим материнской компании International Airlines Group. Неподалеку от аэропорта Хитроу расположены два таких объекта — Boadicea House и Comet House. В первом из них 27 мая 2017 года произошло случайное отключение электропитания, которое привело к перегрузке и отказу системы ИБП. В итоге часть ИТ-оборудования была повреждена физически, а на устранение последней аварии ушло три дня.
Авиакомпании пришлось отменить или перенести более тысячи рейсов, около 75 тысяч пассажиров не смогли вылететь вовремя — на выплату компенсаций ушло $128 млн, не считая потребовавшихся на восстановление работоспособности дата-центров затрат. История с причинами блэкаута непонятна. Если верить озвученным генеральным директором International Airlines Group Вилли Уолшем результатам внутреннего расследования, произошло оно из-за ошибки инженеров. Тем не менее, система бесперебойного электроснабжения должна была выдержать такое отключение — для того она и смонтирована. ЦОД управляли специалисты аутсорсинговой компании CBRE Managed Services, поэтому British Airways попыталась взыскать сумму ущерба через суд Лондона.

Аварии с электропитанием происходят по сходным сценариям: сначала идет отключение по вине поставщика электроэнергии, порой из-за плохой погоды или внутренних проблем (включая ошибки персонала), а затем система бесперебойного электроснабжения не справляется с нагрузкой или кратковременное прерывание синусоиды вызывает отказы множества сервисов, на восстановление работоспособности которых уходит прорва времени и денег. Можно ли избежать подобных аварий? Безусловно. Если проектировать систему правильно, однако от ошибок не застрахованы даже создатели крупных ЦОД.
Человеческий фактор
Когда непосредственной причиной инцидента становятся неправильные действия персонала дата-центра, проблемы чаще всего (но не всегда) затрагивают программную часть ИТ-инфраструктуры. Такие аварии происходят даже в крупных корпорациях. В феврале 2017 года из-за неправильно набранной членом группы технической эксплуатации одного из ЦОД команды была отключена часть серверов Amazon Web Services. Ошибка произошла во время отладки процесса выставления счетов клиентам облачного хранилища Amazon Simple Storage Service (S3). Сотрудник пытался удалить некоторое количество используемых биллинговой системой виртуальных серверов, но задел более крупный кластер.

В результате ошибки инженера удалились серверы, на которых были запущены важные программные модули облачного хранилища Amazon. В первую очередь пострадала подсистема индексирования, содержащая информацию о метаданных и расположении всех объектов S3 в американском регионе US-EAST-1. Инцидентом была также затронута используемая для размещения данных и управления доступным для хранения пространством подсистема. После удаления виртуальных машин эти две подсистемы потребовали полного перезапуска, и дальше инженеров Amazon ждал сюрприз — в течение продолжительного времени публичное облачное хранилище не смогло обслуживать запросы клиентов.
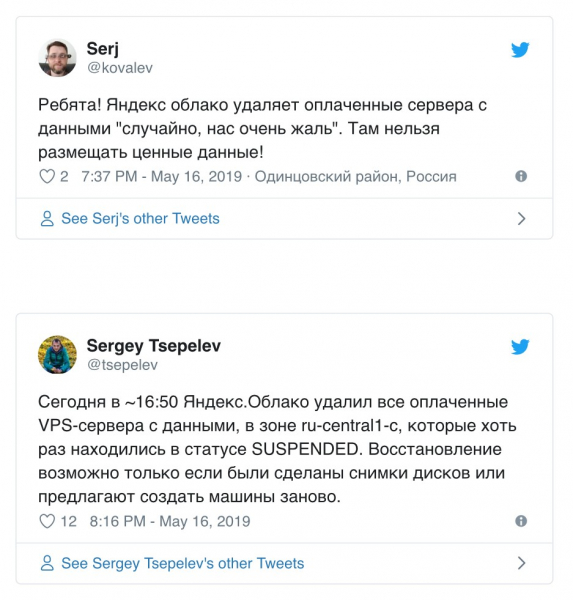
Эффект оказался масштабным, поскольку многие крупные ресурсы используют Amazon S3. Сбои в работе затронули Trello, Coursera, IFTTT и, что самое неприятное, сервисы крупных партнеров Amazon из списка S&P 500. Ущерб в таких случаях сосчитать непросто, но его порядок оказался в районе сотен миллионов долларов США. Как видите, чтобы вывести из строя сервис крупнейшей облачной платформы, достаточно одной неверной команды. Это не единичный случай, 16 мая 2019 года во время профилактических работ сервис Яндекс.Облако виртуальные машины пользователей в зоне ru-central1-c, которые хоть раз находились в статусе SUSPENDED. Здесь уже пострадали клиентские данные, часть которых была безвозвратно утеряна. Конечно, люди несовершенны, но современные системы информационной безопасности давно умеют контролировать действия привилегированных пользователей до выполнения введенных ими команд. Если в Яндекс или Amazon внедрить такие решения, подобных инцидентов можно будет избежать.
Замерзшее охлаждение
В январе 2017 года произошла крупная авария в дмитровском ЦОД компании «Мегафон». Тогда температура в московском регионе снизилась до −35 °С, что привело в выходу из строя системы охлаждения объекта. Пресс-служба оператора особо не распространялась о причинах инцидента — российские компании крайне неохотно говорят об авариях на принадлежащих им объектах, в смысле публичности мы сильно отстаем от Запада. В социальных сетях ходила версия о замерзании теплоносителя в проложенных по улице трубах и утечке этиленгликоля. Если верить ей, служба эксплуатации не смогла из-за длительных праздников оперативно получить 30 тонн хладоносителя и выкручивалась с использованием подручных средств, организовав импровизированный фрикулинг с нарушением правил эксплуатации системы. Сильные холода усугубили проблему — в январе в России внезапно случилась зима, хотя никто ее не ждал. В итоге персоналу пришлось обесточить часть серверных стоек, из-за чего некоторые сервисы оператора были недоступны в течение двух дней.

Наверное, здесь можно говорить и о погодной аномалии, но такие морозы не являются для столичного региона чем-то необычным. Температура зимой в Подмосковье может опускаться и до более низких отметок, поэтому дата-центры строят в расчете на устойчивую работу при −42°С. Чаще всего системы охлаждения на морозе отказывают из-за недостаточно высокой концентрации гликолей и избытка воды в растворе теплоносителя. Бывают проблемы и с монтажом труб или с просчетами в проектировании и тестировании системы, связанными в основном с желанием сэкономить. В итоге на ровном месте случается серьезная авария, которую вполне можно было бы не допустить.
Природные катаклизмы
Чаще всего грозы и/или ураганы нарушают работу инженерной инфраструктуры дата-центра, что приводит к остановке сервисов и/или к физическому повреждению оборудования. Спровоцированные плохой погодой инциденты происходят довольно часто. В 2012 году по западному побережью США прокатился ураган Сэнди с сильным ливнем. Расположенный в высотном здании на Нижнем Манхэттене дата-центр Peer 1 , после того как соленая морская вода залила подвалы. Аварийные генераторы объекта были размещены на 18-м этаже, и запас топлива для них был ограничен — введенные в Нью-Йорке после терактов 9/11 правила запрещают хранить большое количество горючего на верхних этажах.
Топливный насос также вышел из строя, потому персонал несколько дней таскал дизель для генераторов вручную. Героизм команды спас дата-центр от серьезной аварии, но был ли он так необходим? Мы живем на планете с азотно-кислородной атмосферой и большим количеством воды. Грозы и ураганы здесь — обычное дело (особенно в приморских районах). Проектировщикам, вероятно, стоило бы учесть связанные с ними риски и построить соответствующую систему бесперебойного электроснабжения. Или хотя бы выбрать для центра обработки данных более подходящее место, чем высотка на острове.
Все прочее
В эту категорию Uptime Institute выделяет разнообразные инциденты, среди которых сложно выбрать типичный. Кражи медных кабелей, врезающиеся в ЦОД, опоры ЛЭП и трансформаторные подстанции автомобили, пожары, портящие оптику экскаваторщики, грызуны (крысы, кролики и даже вомбаты, которые вообще-то относятся к сумчатым), а также любители попрактиковаться в стрельбе по проводам — меню обширно. Сбои в электропитании может вызвать даже электроэнергию нелегальная плантация марихуаны. В большинстве случаев виновниками инцидента становятся конкретные люди, т. е. мы снова имеем дело с человеческим фактором, когда у проблемы есть имя и фамилия. Даже если на первый взгляд авария связана с технической неисправностью или с природными катаклизмами, ее можно избежать при условии грамотного проектирования объекта и правильной его эксплуатации. Исключения составляют разве что случаи критического повреждения инфраструктуры ЦОД или разрушения зданий и сооружений из-за природной катастрофы. Это действительно форс-мажорные обстоятельства, а все остальные проблемы вызваны прокладкой между компьютером и креслом — пожалуй, это самая ненадежная часть любой сложной системы.
Источник: habr.com
